|
|
3 years ago | |
|---|---|---|
| .. | ||
| README.es.md | 3 years ago | |
| README.ko.md | 3 years ago | |
README.ko.md
<<<<<<< HEAD
데이터 과학의 생애주기 소개
 |
|---|
| 데이터 과학의 생애주기 소개 - @nitya의 이미지 |
강의 시작 전 퀴즈
이 시점에서 여러분은 아마 데이터 과학이 하나의 프로세스라는 것을 깨달았을 것입니다. 이 프로세스는 다음과 같이 5단계로 나눌 수 있습니다:
- 데이터 포획
- 데이터 처리
- 데이터 분석
- 소통
- 유지보수
이번 강의에서는 생애 주기의 세 부분 : 데이터 포획, 데이터 처리 그리고 유지에 집중합니다.

데이터 포획
생애 주기의 첫 번째 단계는 다음 단계의 의존도가 높기 때문에 아주 중요합니다. 이것은 사실상 두 단계가 합해진 것이라고 볼 수 있습니다 : 데이터 수집과 해결해야 하는 문제들 및 목적 정의. 프로젝트의 목표를 정의하려면 문제나 질문에 대해서 더 깊은 맥락을 필요로 할 것입니다. 첫째, 우리는 문제 해결이 필요한 사람들을 찾아내고 영입해야 한다. 그들은 사업의 이해관계자이거나 프로젝트의 후원자일 수도 있으며, 그들은 누가 이 프로젝트를 통해 이익을 얻을 수 있는지, 무엇을 왜 필요로 하는지를 식별하는데에 도움을 줄 수 있습니다. 잘 정의된 목표는 납득할만한 결과를 정의하기 위해 계량(측정)과 수량화가 가능해야만 한다.
데이터 과학자가 할 수도 있는 질문들 :
- 이 문제에 접근한 적이 있습니까? 무엇이 발견되었습니까?
- 관련되어 있는 모든 사람들이 목적과 목표를 이해하고 있습니까?
- 모호성은 어디에서 확인할 수 있으며 어떻게 줄일 수 있겠습니까?
- 제약이 되는 것들은 무엇입니까?
- 최종 결과는 잠재적으로 어떻게 될 것 같습니까?
- 사용 가능한 자원들 (시간, 인력, 컴퓨터 이용) 이 얼마나 됩니까?
다음은 이 정의된 목표들을 달성하는 데 필요한 데이터를 식별하고, 수집하고, 마지막으로 탐색하는 것입니다. 이 획득 단계에서, 데이터 과학자들은 데이터의 양과 질또한 평가해야만 합니다. 얻은 것이 원하는 결과에 도달하는데 도움이 될 지 확인하기 위해서는 약간의 데이터 탐색이 요구됩니다.
데이터 과학자가 데이터에 대해 물어볼 수 있는 질문들 :
- 어떤 데이터가 이미 제가 사용이 가능합니까?
- 이 데이터의 소유자는 누구입니까?
- 개인 정보 보호 문제는 무엇입니까?
- 내가 이 문제를 해결할만큼 충분합니까?
- 이 문제에 대해 허용 가능한 품질의 데이터 입니까?
- 만약 내가 이 데이터를 통해 추가적인 정보를 발견한다면, 목표를 바꾸거나 정의를 다시 내려야 합니까?
데이터 처리
생애 주기의 데이터 처리단계는 모델링뿐만 아니라 데이터에서 패턴을 발견하는 데 초점을 맞춥니다. 데이터 처리 단계에서 사용되는 몇몇 기술들은 패턴을 파악하기 위한 통계정 방식을 필요로 합니다. 일반적으로, 이것이 사람에게는 대규모 데이터 세트로 수행하는 지루한 작업일것이고, 데이터 처리의 속도를 높이기 위해 무거운 작업을 컴퓨터들에게 시키며 의존하게 됩니다. 이 단계는 또한 데이터 과학과 기계학습이 교차하는 단계입니다. 첫 번째 수업에서 배웠듯이, 기계학습은 데이터를 이해하기 위한 모델을 구축하는 과정입니다. 모델은 데이터 내 변수간의 관계를 나타내는 것으로 결과들을 예측하는 데 도움이 됩니다.
일반적으로 이 단계에서 이요되는 기술들은 ML for Beginners 커리큘럼에서 다룹니다. 링크를 따라가 그것들에 대해 더 알아보십시오 :
유지보수
생애주기 다이어그램에서, 유지보수는 데이터 포획단계와 데이터 처리단계의 사이에 있다는 것을 알 수 있습니다. 유지보수는 프로젝트 과정 전체에 걸쳐 데이터를 관리, 저장 및 보호하는 지속적인 과정이며 프로젝트 전체에 걸쳐 고려해야만 합니다.
데이터 저장
데이터가 어떻게, 어디로 저장되는지에 대한 고려사항들은 저장소 비용뿐만 아니라 데이터의 접근 속도에 영향을 미칠 수 있습니다. 이와 같은 결정들은 데이터 과학자가 단독으로 내리는 것은 아니지만, 데이터 저장 방식에 따라 데이터를 처리하는 방식을 스스로 선택할 수 있습니다.
이러한 선택들에 영향을 미칠 수 있는 최신 데이터 저장소 시스템의 몇 가지 측면들입니다:
전제 있음 vs 전제 없음 vs 공용 혹은 개인(자체) 클라우드 전제 있음은 데이터를 저장하는 하드 드라이브가 있는 서버를 소유하는 것과 같이 자체 장비에서 데이터를 관리하는 호스팅을 의미하는 반면, 전제 없음은 데이터 센터와 같이 소유하지 않은 장비에 의존합니다. 공용 클라우드는 데이터가 정확이 어디에 어떻게 저장되는지에 대한 지식이 필요하지 않은 데이터 저장에 인기있는 선택입니다. 여기서 공용이란 클라우드를 사용하는 모든 사용자가 공유하는 통합 기반 인프라를 의미합니다. 일부 조직들은 데이터가 호스팅되는 장비에 대하여 완전한 접근 권한을 요구하는 엄격한 보안정책이 있으며, 자체 클라우드 서비스를 제공하는 사설 클라우드에 의존합니다. 클라우드의 데이터에 대한 자세한 내용은 다음 강의 에서 더 배우게 될 것입니다.
Cold vs hot 데이터 모델을 훈련할 때, 더 많은 훈련데이터가 필요할 수 있습니다. 만약 당신이 당신의 모델에 만족을 한다면, 모델이 목적을 달성하도록 더 많은 데이터들이 제공될 것입니다. 어떠한 경우에도 데이터를 더 많이 축적할수록 데이터 저장 및 접근 비용은 증가합니다. 자주 접근하는 hot 데이터로부터, cold 데이터로 알려져 있는 자주 접근하지 않는 데이터를 분리하는 것은 하드웨어 혹은 소프트웨어 서비스를 통해 더 저렴한 데이터 저장 선택지가 될 수 있습니다. 만약 cold 데이터에 접근해야 하는 경우, hot 데이터에 비하여 검색하는데 시간이 좀 더 소요될 수 있습니다.
데이터 관리
데이터를 작업 하다보면 정확한 모델을 구축하기 위해 데이터 준비에 중점을 둔 강의에서 다룬 일부 기술을 사용하여 일부 데이터를 정리해야 한다는 것을 알 수 있습니다. 새로운 데이터가 제공되면, 품질의 일관성을 유지하기 위해서 동일한 애플리케이션의 일부를 필요로 합니다. 일부 프로젝트들에서는 데이터를 최종 위치로 이동하기 전에 정리, 집계 및 압축 작업을 위한 자동화된 도구의 사용이 포합됩니다. Azure Data Factory는 이러한 도구 중 하나의 예입니다.
데이터 보안
데이터 보안의 주요 목표 중 하나는 데이터를 작업하는 사람들이 수집 대상과 데이터가 사용되는 맥락을 제어할 수 있도록 하는 것입니다. 데이터 보안을 유지하려면 데이터를 필요로 하는 사람만 접근할 수 있도록 제한하고, 현지 법률 및 규정을 준수하며, 윤리 강의에서 다루는 윤리적 표준을 유지해야 합니다.
다음은 보안을 염두에 두고 팀에서 수행할 수 있는 몇 가지 사항입니다:
- 모든 데이터가 암호화 되는지 확인합니다.
- 그들의 데이터가 어떻게 이용되는지 고객들에게 정보를 제공합니다.
- 프로젝트에서 떠난 사람들의 데이터 접근을 금지합니다.
- 특정 프로젝트 구성원들만이 데이터를 변경할 수 있도록 허용합니다.
🚀 도전
데이터 과학의 생애주기에는 여러가지 버전이 있습니다. 여기서 각 단계는 이름과 단계 수가 다를 수 있지만 이 강의에서 언급한 것과 동일한 과정을 포합합니다.
Team Data Science Process lifecycle 와 Cross-industry standard process for data mining를 탐구 해보십시오. 이 둘 사이의 3가지 유사점과 차이점을 대보시오.
| Team Data Science Process (TDSP) | Cross-industry standard process for data mining (CRISP-DM) |
|---|---|
 |
 |
| Microsoft의 이미지 | Data Science Process Alliance의 이미지 |
이전 강의 퀴즈
복습 & 자기주도학습
데이터 과학의 생애주기를 적용하는 데는 여러 역할과 작업이 포함되며, 일부는 각 단계의 특정 부분에 집중할 수 있습니다. 팀 데이터 과학 프로세스는 프로젝트에서 누군가가 가질 수 있는 역할 및 작업 유형을 설명하는 몇 가지 리소스를 제공합니다.
과제
데이터 세트
데이터 과학의 생애주기 소개
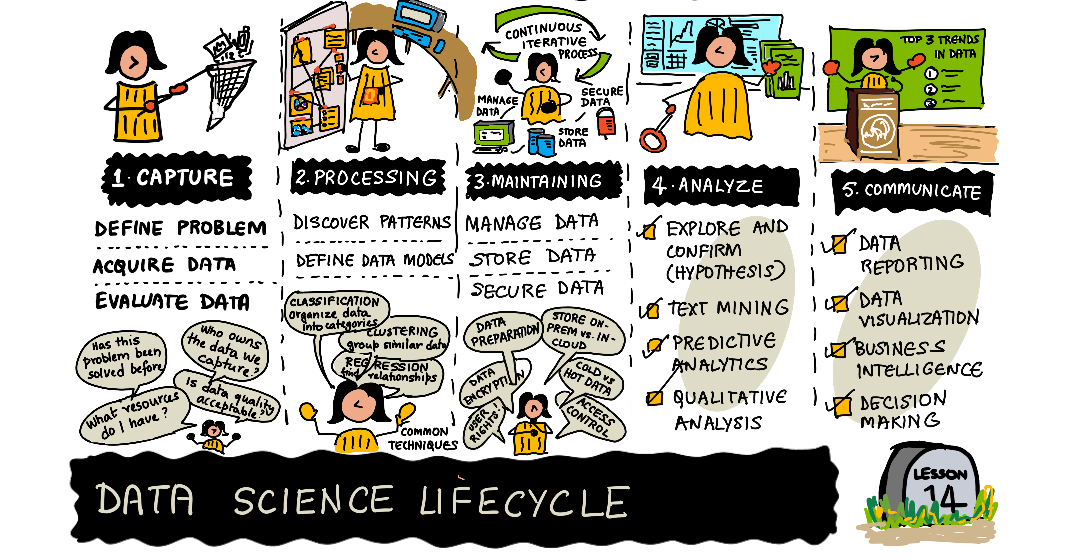 |
|---|
| 데이터 과학의 생애주기 소개 - @nitya의 이미지 |
강의 시작 전 퀴즈
이 시점에서 여러분은 아마 데이터 과학이 하나의 프로세스라는 것을 깨달았을 것입니다. 이 프로세스는 다음과 같이 5단계로 나눌 수 있습니다:
- 데이터 포획
- 데이터 처리
- 데이터 분석
- 소통
- 유지보수
이번 강의에서는 생애 주기의 세 부분 : 데이터 포획, 데이터 처리 그리고 유지에 집중합니다.

데이터 포획
생애 주기의 첫 번째 단계는 다음 단계의 의존도가 높기 때문에 아주 중요합니다. 이것은 사실상 두 단계가 합해진 것이라고 볼 수 있습니다 : 데이터 수집과 해결해야 하는 문제들 및 목적 정의. 프로젝트의 목표를 정의하려면 문제나 질문에 대해서 더 깊은 맥락을 필요로 할 것입니다. 첫째, 우리는 문제 해결이 필요한 사람들을 찾아내고 영입해야 한다. 그들은 사업의 이해관계자이거나 프로젝트의 후원자일 수도 있으며, 그들은 누가 이 프로젝트를 통해 이익을 얻을 수 있는지, 무엇을 왜 필요로 하는지를 식별하는데에 도움을 줄 수 있습니다. 잘 정의된 목표는 납득할만한 결과를 정의하기 위해 계량(측정)과 수량화가 가능해야만 한다.
데이터 과학자가 할 수도 있는 질문들 :
- 이 문제에 접근한 적이 있습니까? 무엇이 발견되었습니까?
- 관련되어 있는 모든 사람들이 목적과 목표를 이해하고 있습니까?
- 모호성은 어디에서 확인할 수 있으며 어떻게 줄일 수 있겠습니까?
- 제약이 되는 것들은 무엇입니까?
- 최종 결과는 잠재적으로 어떻게 될 것 같습니까?
- 사용 가능한 자원들 (시간, 인력, 컴퓨터 이용) 이 얼마나 됩니까?
다음은 이 정의된 목표들을 달성하는 데 필요한 데이터를 식별하고, 수집하고, 마지막으로 탐색하는 것입니다. 이 획득 단계에서, 데이터 과학자들은 데이터의 양과 질또한 평가해야만 합니다. 얻은 것이 원하는 결과에 도달하는데 도움이 될 지 확인하기 위해서는 약간의 데이터 탐색이 요구됩니다.
데이터 과학자가 데이터에 대해 물어볼 수 있는 질문들 :
- 어떤 데이터가 이미 제가 사용이 가능합니까?
- 이 데이터의 소유자는 누구입니까?
- 개인 정보 보호 문제는 무엇입니까?
- 내가 이 문제를 해결할만큼 충분합니까?
- 이 문제에 대해 허용 가능한 품질의 데이터 입니까?
- 만약 내가 이 데이터를 통해 추가적인 정보를 발견한다면, 목표를 바꾸거나 정의를 다시 내려야 합니까?
데이터 처리
생애 주기의 데이터 처리단계는 모델링뿐만 아니라 데이터에서 패턴을 발견하는 데 초점을 맞춥니다. 데이터 처리 단계에서 사용되는 몇몇 기술들은 패턴을 파악하기 위한 통계정 방식을 필요로 합니다. 일반적으로, 이것이 사람에게는 대규모 데이터 세트로 수행하는 지루한 작업일것이고, 데이터 처리의 속도를 높이기 위해 무거운 작업을 컴퓨터들에게 시키며 의존하게 됩니다. 이 단계는 또한 데이터 과학과 기계학습이 교차하는 단계입니다. 첫 번째 수업에서 배웠듯이, 기계학습은 데이터를 이해하기 위한 모델을 구축하는 과정입니다. 모델은 데이터 내 변수간의 관계를 나타내는 것으로 결과들을 예측하는 데 도움이 됩니다.
일반적으로 이 단계에서 이요되는 기술들은 ML for Beginners 커리큘럼에서 다룹니다. 링크를 따라가 그것들에 대해 더 알아보십시오 :
유지보수
생애주기 다이어그램에서, 유지보수는 데이터 포획단계와 데이터 처리단계의 사이에 있다는 것을 알 수 있습니다. 유지보수는 프로젝트 과정 전체에 걸쳐 데이터를 관리, 저장 및 보호하는 지속적인 과정이며 프로젝트 전체에 걸쳐 고려해야만 합니다.
데이터 저장
데이터가 어떻게, 어디로 저장되는지에 대한 고려사항들은 저장소 비용뿐만 아니라 데이터의 접근 속도에 영향을 미칠 수 있습니다. 이와 같은 결정들은 데이터 과학자가 단독으로 내리는 것은 아니지만, 데이터 저장 방식에 따라 데이터를 처리하는 방식을 스스로 선택할 수 있습니다.
이러한 선택들에 영향을 미칠 수 있는 최신 데이터 저장소 시스템의 몇 가지 측면들입니다:
전제 있음 vs 전제 없음 vs 공용 혹은 개인(자체) 클라우드 전제 있음은 데이터를 저장하는 하드 드라이브가 있는 서버를 소유하는 것과 같이 자체 장비에서 데이터를 관리하는 호스팅을 의미하는 반면, 전제 없음은 데이터 센터와 같이 소유하지 않은 장비에 의존합니다. 공용 클라우드는 데이터가 정확이 어디에 어떻게 저장되는지에 대한 지식이 필요하지 않은 데이터 저장에 인기있는 선택입니다. 여기서 공용이란 클라우드를 사용하는 모든 사용자가 공유하는 통합 기반 인프라를 의미합니다. 일부 조직들은 데이터가 호스팅되는 장비에 대하여 완전한 접근 권한을 요구하는 엄격한 보안정책이 있으며, 자체 클라우드 서비스를 제공하는 사설 클라우드에 의존합니다. 클라우드의 데이터에 대한 자세한 내용은 다음 강의 에서 더 배우게 될 것입니다.
Cold vs hot 데이터 모델을 훈련할 때, 더 많은 훈련데이터가 필요할 수 있습니다. 만약 당신이 당신의 모델에 만족을 한다면, 모델이 목적을 달성하도록 더 많은 데이터들이 제공될 것입니다. 어떠한 경우에도 데이터를 더 많이 축적할수록 데이터 저장 및 접근 비용은 증가합니다. 자주 접근하는 hot 데이터로부터, cold 데이터로 알려져 있는 자주 접근하지 않는 데이터를 분리하는 것은 하드웨어 혹은 소프트웨어 서비스를 통해 더 저렴한 데이터 저장 선택지가 될 수 있습니다. 만약 cold 데이터에 접근해야 하는 경우, hot 데이터에 비하여 검색하는데 시간이 좀 더 소요될 수 있습니다.
데이터 관리
데이터를 작업 하다보면 정확한 모델을 구축하기 위해 데이터 준비에 중점을 둔 강의에서 다룬 일부 기술을 사용하여 일부 데이터를 정리해야 한다는 것을 알 수 있습니다. 새로운 데이터가 제공되면, 품질의 일관성을 유지하기 위해서 동일한 애플리케이션의 일부를 필요로 합니다. 일부 프로젝트들에서는 데이터를 최종 위치로 이동하기 전에 정리, 집계 및 압축 작업을 위한 자동화된 도구의 사용이 포합됩니다. Azure Data Factory는 이러한 도구 중 하나의 예입니다.
데이터 보안
데이터 보안의 주요 목표 중 하나는 데이터를 작업하는 사람들이 수집 대상과 데이터가 사용되는 맥락을 제어할 수 있도록 하는 것입니다. 데이터 보안을 유지하려면 데이터를 필요로 하는 사람만 접근할 수 있도록 제한하고, 현지 법률 및 규정을 준수하며, 윤리 강의에서 다루는 윤리적 표준을 유지해야 합니다.
다음은 보안을 염두에 두고 팀에서 수행할 수 있는 몇 가지 사항입니다:
- 모든 데이터가 암호화 되는지 확인합니다.
- 그들의 데이터가 어떻게 이용되는지 고객들에게 정보를 제공합니다.
- 프로젝트에서 떠난 사람들의 데이터 접근을 금지합니다.
- 특정 프로젝트 구성원들만이 데이터를 변경할 수 있도록 허용합니다.
🚀 도전
데이터 과학의 생애주기에는 여러가지 버전이 있습니다. 여기서 각 단계는 이름과 단계 수가 다를 수 있지만 이 강의에서 언급한 것과 동일한 과정을 포합합니다.
Team Data Science Process lifecycle 와 Cross-industry standard process for data mining를 탐구 해보십시오. 이 둘 사이의 3가지 유사점과 차이점을 대보시오.
| Team Data Science Process (TDSP) | Cross-industry standard process for data mining (CRISP-DM) |
|---|---|
 |
 |
| Microsoft의 이미지 | Data Science Process Alliance의 이미지 |
이전 강의 퀴즈
복습 & 자기주도학습
데이터 과학의 생애주기를 적용하는 데는 여러 역할과 작업이 포함되며, 일부는 각 단계의 특정 부분에 집중할 수 있습니다. 팀 데이터 과학 프로세스는 프로젝트에서 누군가가 가질 수 있는 역할 및 작업 유형을 설명하는 몇 가지 리소스를 제공합니다.