|
|
5 months ago | |
|---|---|---|
| .. | ||
| README.md | 5 months ago | |
| assignment.md | 5 months ago | |
README.md
کلاؤڈ میں ڈیٹا سائنس: "کم کوڈ/بغیر کوڈ" طریقہ
 |
|---|
| کلاؤڈ میں ڈیٹا سائنس: کم کوڈ - @nitya کی اسکیچ نوٹ |
فہرستِ مضامین:
- کلاؤڈ میں ڈیٹا سائنس: "کم کوڈ/بغیر کوڈ" طریقہ
لیکچر سے پہلے کا کوئز
1. تعارف
1.1 Azure Machine Learning کیا ہے؟
Azure کلاؤڈ پلیٹ فارم 200 سے زیادہ پروڈکٹس اور کلاؤڈ سروسز پر مشتمل ہے جو آپ کو نئی حل تخلیق کرنے میں مدد فراہم کرتی ہیں۔ ڈیٹا سائنسدان ڈیٹا کو دریافت کرنے، اس کی پروسیسنگ کرنے، اور مختلف ماڈل تربیتی الگورتھمز آزمانے میں بہت محنت کرتے ہیں تاکہ درست ماڈلز تیار کیے جا سکیں۔ یہ کام وقت طلب ہوتے ہیں اور اکثر مہنگے کمپیوٹ ہارڈویئر کا غیر مؤثر استعمال کرتے ہیں۔
Azure ML Azure میں مشین لرننگ حل بنانے اور چلانے کے لیے ایک کلاؤڈ پر مبنی پلیٹ فارم ہے۔ اس میں ڈیٹا تیار کرنے، ماڈلز کی تربیت، پیش گوئی کی خدمات شائع کرنے، اور ان کے استعمال کی نگرانی کرنے کے لیے وسیع خصوصیات اور صلاحیتیں شامل ہیں۔ سب سے اہم بات یہ ہے کہ یہ ڈیٹا سائنسدانوں کو ماڈلز کی تربیت سے متعلق وقت طلب کاموں کو خودکار بنا کر ان کی کارکردگی بڑھانے میں مدد فراہم کرتا ہے؛ اور یہ انہیں کلاؤڈ پر مبنی کمپیوٹ وسائل استعمال کرنے کی اجازت دیتا ہے جو مؤثر طریقے سے بڑے ڈیٹا کے حجم کو سنبھال سکتے ہیں، اور صرف استعمال کے وقت ہی اخراجات اٹھاتے ہیں۔
Azure ML ڈیولپرز اور ڈیٹا سائنسدانوں کو ان کے مشین لرننگ ورک فلو کے لیے تمام ضروری ٹولز فراہم کرتا ہے۔ ان میں شامل ہیں:
- Azure Machine Learning Studio: یہ Azure Machine Learning میں ایک ویب پورٹل ہے جو ماڈل کی تربیت، تعیناتی، خودکاری، ٹریکنگ اور اثاثہ جات کے انتظام کے لیے کم کوڈ اور بغیر کوڈ کے اختیارات فراہم کرتا ہے۔ اسٹوڈیو Azure Machine Learning SDK کے ساتھ مربوط ہے تاکہ ایک ہموار تجربہ فراہم کیا جا سکے۔
- Jupyter Notebooks: مشین لرننگ ماڈلز کو جلدی پروٹوٹائپ اور ٹیسٹ کرنے کے لیے۔
- Azure Machine Learning Designer: ماڈیولز کو ڈریگ اینڈ ڈراپ کرنے کی اجازت دیتا ہے تاکہ تجربات بنائے جا سکیں اور پھر کم کوڈ ماحول میں پائپ لائنز تعینات کی جا سکیں۔
- Automated machine learning UI (AutoML): مشین لرننگ ماڈل کی ترقی کے تکراری کاموں کو خودکار بناتا ہے، جس سے بڑے پیمانے پر، مؤثر اور پیداواری ماڈلز بنائے جا سکتے ہیں، اور ماڈل کے معیار کو برقرار رکھا جا سکتا ہے۔
- Data Labelling: ڈیٹا کو خودکار طور پر لیبل کرنے کے لیے ایک معاون مشین لرننگ ٹول۔
- Machine learning extension for Visual Studio Code: مشین لرننگ پروجیکٹس بنانے اور ان کا انتظام کرنے کے لیے مکمل خصوصیات والا ترقیاتی ماحول فراہم کرتا ہے۔
- Machine learning CLI: کمانڈ لائن سے Azure ML وسائل کا انتظام کرنے کے لیے کمانڈز فراہم کرتا ہے۔
- اوپن سورس فریم ورک کے ساتھ انضمام جیسے PyTorch، TensorFlow، Scikit-learn اور دیگر، تربیت، تعیناتی، اور مشین لرننگ کے اختتام سے اختتام تک کے عمل کا انتظام کرنے کے لیے۔
- MLflow: یہ مشین لرننگ تجربات کے زندگی کے دورانیے کا انتظام کرنے کے لیے ایک اوپن سورس لائبریری ہے۔ MLFlow Tracking MLflow کا ایک جزو ہے جو آپ کے تربیتی رن میٹرکس اور ماڈل آرٹیفیکٹس کو لاگ اور ٹریک کرتا ہے، چاہے آپ کے تجربے کا ماحول کچھ بھی ہو۔
1.2 دل کی ناکامی کی پیشن گوئی کا منصوبہ:
یہ بات واضح ہے کہ منصوبے بنانا اور ان پر کام کرنا آپ کی مہارت اور علم کو آزمانے کا بہترین طریقہ ہے۔ اس سبق میں، ہم Azure ML Studio میں دل کی ناکامی کے حملوں کی پیشن گوئی کے لیے ڈیٹا سائنس پروجیکٹ بنانے کے دو مختلف طریقے دریافت کریں گے، کم کوڈ/بغیر کوڈ اور Azure ML SDK کے ذریعے، جیسا کہ درج ذیل اسکیمہ میں دکھایا گیا ہے:
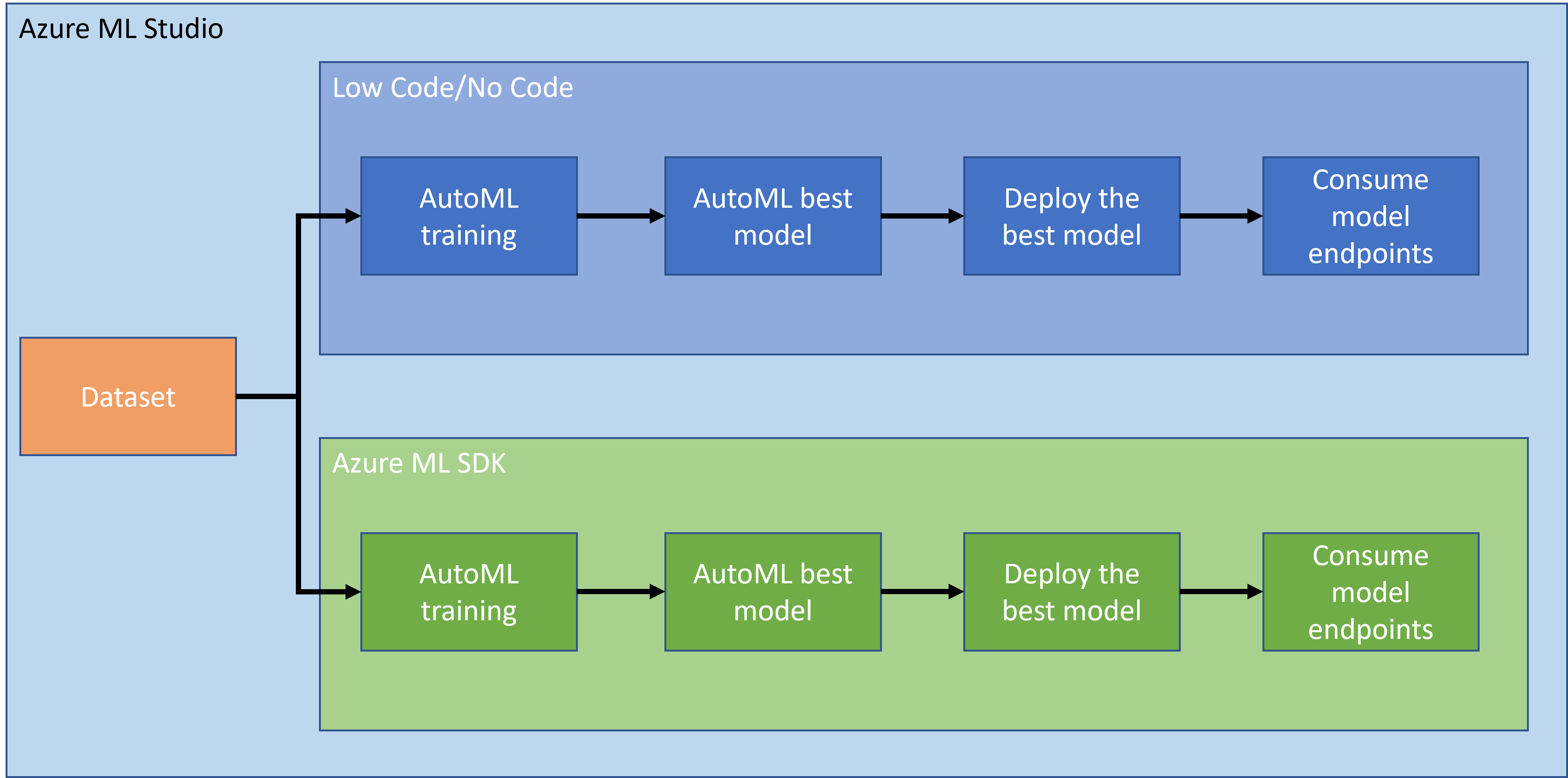
ہر طریقے کے اپنے فوائد اور نقصانات ہیں۔ کم کوڈ/بغیر کوڈ طریقہ شروع کرنے میں آسان ہے کیونکہ اس میں GUI (گرافیکل یوزر انٹرفیس) کے ساتھ تعامل شامل ہے، اور کوڈ کا کوئی پیشگی علم درکار نہیں ہوتا۔ یہ طریقہ پروجیکٹ کی عملیت کو جلدی جانچنے اور POC (پروف آف کانسیپٹ) بنانے کی اجازت دیتا ہے۔ تاہم، جیسے جیسے پروجیکٹ بڑھتا ہے اور چیزوں کو پروڈکشن کے لیے تیار کرنے کی ضرورت ہوتی ہے، GUI کے ذریعے وسائل بنانا ممکن نہیں ہوتا۔ ہمیں پروگرام کے ذریعے ہر چیز کو خودکار بنانا پڑتا ہے، وسائل کی تخلیق سے لے کر ماڈل کی تعیناتی تک۔ یہی وہ جگہ ہے جہاں Azure ML SDK کا استعمال جاننا ضروری ہو جاتا ہے۔
| کم کوڈ/بغیر کوڈ | Azure ML SDK | |
|---|---|---|
| کوڈ کی مہارت | ضروری نہیں | ضروری |
| ترقی کا وقت | تیز اور آسان | کوڈ کی مہارت پر منحصر |
| پروڈکشن کے لیے تیار | نہیں | ہاں |
1.3 دل کی ناکامی کا ڈیٹا سیٹ:
دل کی بیماریوں (CVDs) دنیا بھر میں موت کی سب سے بڑی وجہ ہیں، جو عالمی سطح پر تمام اموات کا 31% حصہ ہیں۔ ماحولیاتی اور رویے کے خطرے کے عوامل جیسے تمباکو کا استعمال، غیر صحت مند غذا اور موٹاپا، جسمانی غیر فعالیت اور شراب کا نقصان دہ استعمال تخمینی ماڈلز کے لیے خصوصیات کے طور پر استعمال کیے جا سکتے ہیں۔ CVD کے ترقی کے امکان کا اندازہ لگانا خطرے والے افراد میں حملوں کو روکنے کے لیے بہت مفید ہو سکتا ہے۔
Kaggle نے ایک دل کی ناکامی کا ڈیٹا سیٹ عوامی طور پر دستیاب کیا ہے، جسے ہم اس پروجیکٹ کے لیے استعمال کریں گے۔ آپ ابھی ڈیٹا سیٹ ڈاؤن لوڈ کر سکتے ہیں۔ یہ ایک ٹیبلر ڈیٹا سیٹ ہے جس میں 13 کالم (12 خصوصیات اور 1 ہدف متغیر) اور 299 قطاریں ہیں۔
| متغیر کا نام | قسم | وضاحت | مثال | |
|---|---|---|---|---|
| 1 | عمر | عددی | مریض کی عمر | 25 |
| 2 | خون کی کمی | بولین | خون کے سرخ خلیوں یا ہیموگلوبن کی کمی | 0 یا 1 |
| 3 | کریٹینین فاسفوکائنیز | عددی | خون میں CPK انزائم کی سطح | 542 |
| 4 | ذیابیطس | بولین | اگر مریض کو ذیابیطس ہے | 0 یا 1 |
| 5 | ایجیکشن فریکشن | عددی | دل کے ہر سکڑاؤ پر خون کے نکلنے کا فیصد | 45 |
| 6 | ہائی بلڈ پریشر | بولین | اگر مریض کو ہائی بلڈ پریشر ہے | 0 یا 1 |
| 7 | پلیٹلیٹس | عددی | خون میں پلیٹلیٹس | 149000 |
| 8 | سیرم کریٹینین | عددی | خون میں سیرم کریٹینین کی سطح | 0.5 |
| 9 | سیرم سوڈیم | عددی | خون میں سیرم سوڈیم کی سطح | jun |
| 10 | جنس | بولین | عورت یا مرد | 0 یا 1 |
| 11 | سگریٹ نوشی | بولین | اگر مریض سگریٹ نوشی کرتا ہے | 0 یا 1 |
| 12 | وقت | عددی | فالو اپ مدت (دن) | 4 |
| ---- | --------------------------- | ----------------- | --------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [ہدف] | بولین | اگر مریض فالو اپ مدت کے دوران فوت ہو جائے | 0 یا 1 |
ڈیٹا سیٹ حاصل کرنے کے بعد، ہم Azure میں پروجیکٹ شروع کر سکتے ہیں۔
2. Azure ML Studio میں کم کوڈ/بغیر کوڈ ماڈل کی تربیت
2.1 Azure ML ورک اسپیس بنائیں
Azure ML میں ماڈل کی تربیت کے لیے آپ کو پہلے Azure ML ورک اسپیس بنانا ہوگا۔ ورک اسپیس Azure Machine Learning کے لیے اعلیٰ سطحی وسائل ہے، جو آپ کے بنائے گئے تمام آرٹیفیکٹس کے ساتھ کام کرنے کے لیے ایک مرکزی جگہ فراہم کرتا ہے۔ ورک اسپیس تربیتی رنز کی تاریخ رکھتا ہے، جس میں لاگز، میٹرکس، آؤٹ پٹ، اور آپ کی اسکرپٹس کا اسنیپ شاٹ شامل ہوتا ہے۔ آپ اس معلومات کا استعمال یہ تعین کرنے کے لیے کرتے ہیں کہ کون سا تربیتی رن بہترین ماڈل تیار کرتا ہے۔ مزید جانیں
یہ تجویز کیا جاتا ہے کہ آپ اپنے آپریٹنگ سسٹم کے ساتھ مطابقت رکھنے والے سب سے زیادہ اپ ڈیٹ شدہ براؤزر کا استعمال کریں۔ درج ذیل براؤزرز کی حمایت کی جاتی ہے:
- Microsoft Edge (نیا Microsoft Edge، تازہ ترین ورژن۔ Microsoft Edge لیگیسی نہیں)
- Safari (تازہ ترین ورژن، صرف Mac)
- Chrome (تازہ ترین ورژن)
- Firefox (تازہ ترین ورژن)
Azure Machine Learning استعمال کرنے کے لیے، اپنے Azure سبسکرپشن میں ایک ورک اسپیس بنائیں۔ آپ پھر اس ورک اسپیس کو ڈیٹا، کمپیوٹ وسائل، کوڈ، ماڈلز، اور مشین لرننگ ورک لوڈز سے متعلق دیگر آرٹیفیکٹس کا انتظام کرنے کے لیے استعمال کر سکتے ہیں۔
نوٹ: آپ کے Azure سبسکرپشن سے وابستہ Azure Machine Learning ورک اسپیس کے موجود رہنے تک ڈیٹا اسٹوریج کے لیے آپ کے Azure سبسکرپشن پر تھوڑا سا چارج لگے گا، لہذا ہم تجویز کرتے ہیں کہ جب آپ اسے مزید استعمال نہ کریں تو Azure Machine Learning ورک اسپیس کو حذف کر دیں۔
-
Azure پورٹل میں Microsoft کی اسناد کے ساتھ سائن ان کریں جو آپ کے Azure سبسکرپشن سے وابستہ ہیں۔
-
+Create a resource منتخب کریں
مشین لرننگ تلاش کریں اور مشین لرننگ ٹائل منتخب کریں
تخلیق کے بٹن پر کلک کریں
ترتیبات کو درج ذیل کے مطابق پُر کریں:
- سبسکرپشن: آپ کا Azure سبسکرپشن
- وسائل کا گروپ: ایک وسائل کا گروپ بنائیں یا منتخب کریں
- ورک اسپیس کا نام: اپنے ورک اسپیس کے لیے ایک منفرد نام درج کریں
- علاقہ: اپنے قریب ترین جغرافیائی علاقہ منتخب کریں
- اسٹوریج اکاؤنٹ: نئے اسٹوریج اکاؤنٹ کا نوٹ کریں جو آپ کے ورک اسپیس کے لیے بنایا جائے گا
- کلیدی والٹ: نئے کلیدی والٹ کا نوٹ کریں جو آپ کے ورک اسپیس کے لیے بنایا جائے گا
- ایپلیکیشن انسائٹس: نئے ایپلیکیشن انسائٹس وسائل کا نوٹ کریں جو آپ کے ورک اسپیس کے لیے بنایا جائے گا
- کنٹینر رجسٹری: کوئی نہیں (ایک خود بخود بنایا جائے گا جب آپ پہلی بار ماڈل کو کنٹینر میں تعینات کریں گے)
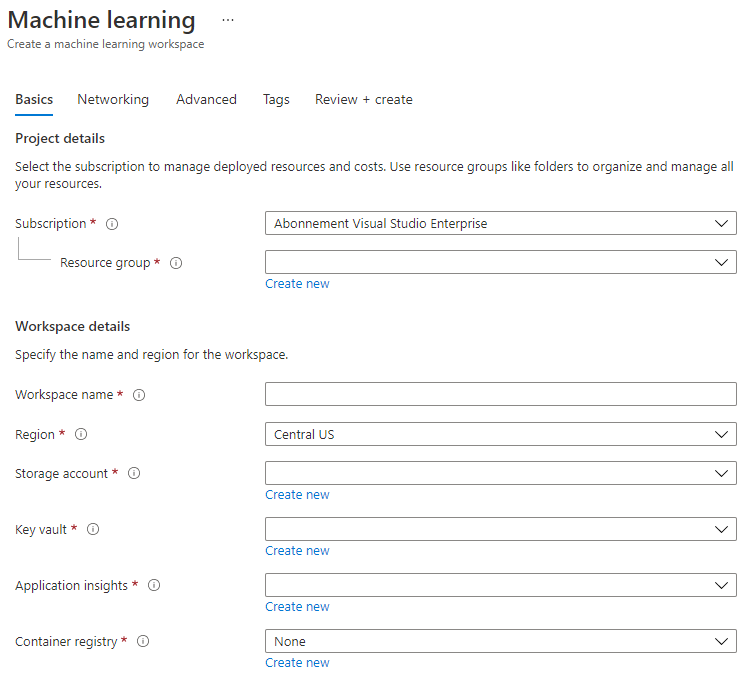
- تخلیق + جائزہ پر کلک کریں اور پھر تخلیق کے بٹن پر کلک کریں
-
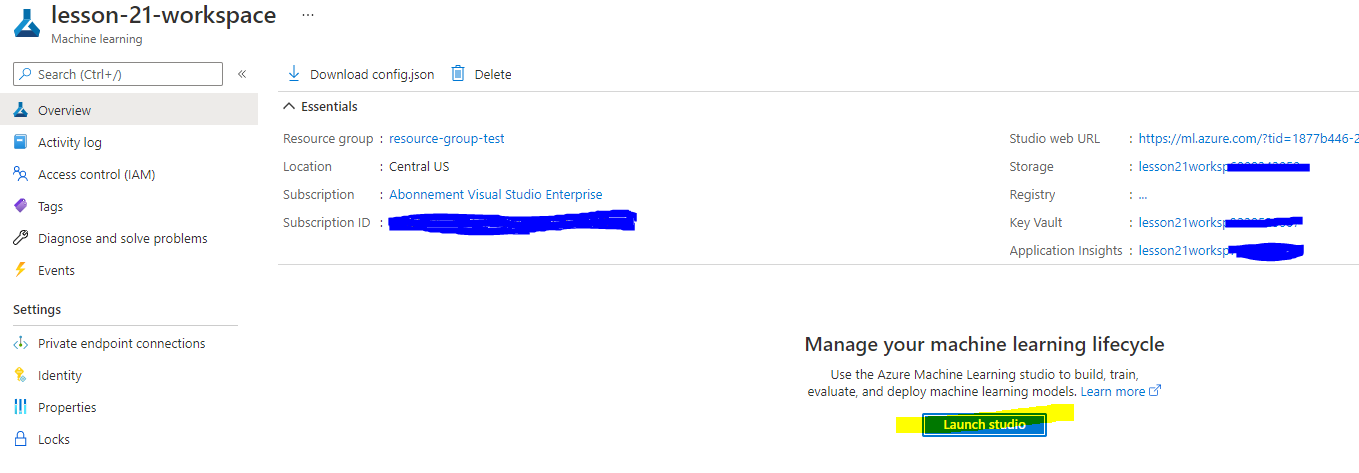
اپنے ورک اسپیس کے بننے کا انتظار کریں (یہ چند منٹ لگ سکتے ہیں)۔ پھر پورٹل میں جائیں۔ آپ اسے مشین لرننگ Azure سروس کے ذریعے تلاش کر سکتے ہیں۔
-
اپنے ورک اسپیس کے جائزہ صفحے پر، Azure Machine Learning اسٹوڈیو لانچ کریں (یا ایک نیا براؤزر ٹیب کھولیں اور https://ml.azure.com پر جائیں)، اور Azure Machine Learning اسٹوڈیو میں اپنے Microsoft اکاؤنٹ کے ساتھ سائن ان کریں۔ اگر کہا جائے تو، اپنا Azure ڈائریکٹری اور سبسکرپشن منتخب کریں، اور اپنا Azure Machine Learning ورک اسپیس منتخب کریں۔
- Azure Machine Learning اسٹوڈیو میں، اوپر بائیں جانب ☰ آئیکن کو ٹوگل کریں تاکہ انٹرفیس میں مختلف صفحات دیکھ سکیں۔ آپ ان صفحات کو اپنے ورک اسپیس میں وسائل کا انتظام کرنے کے لیے استعمال کر سکتے ہیں۔
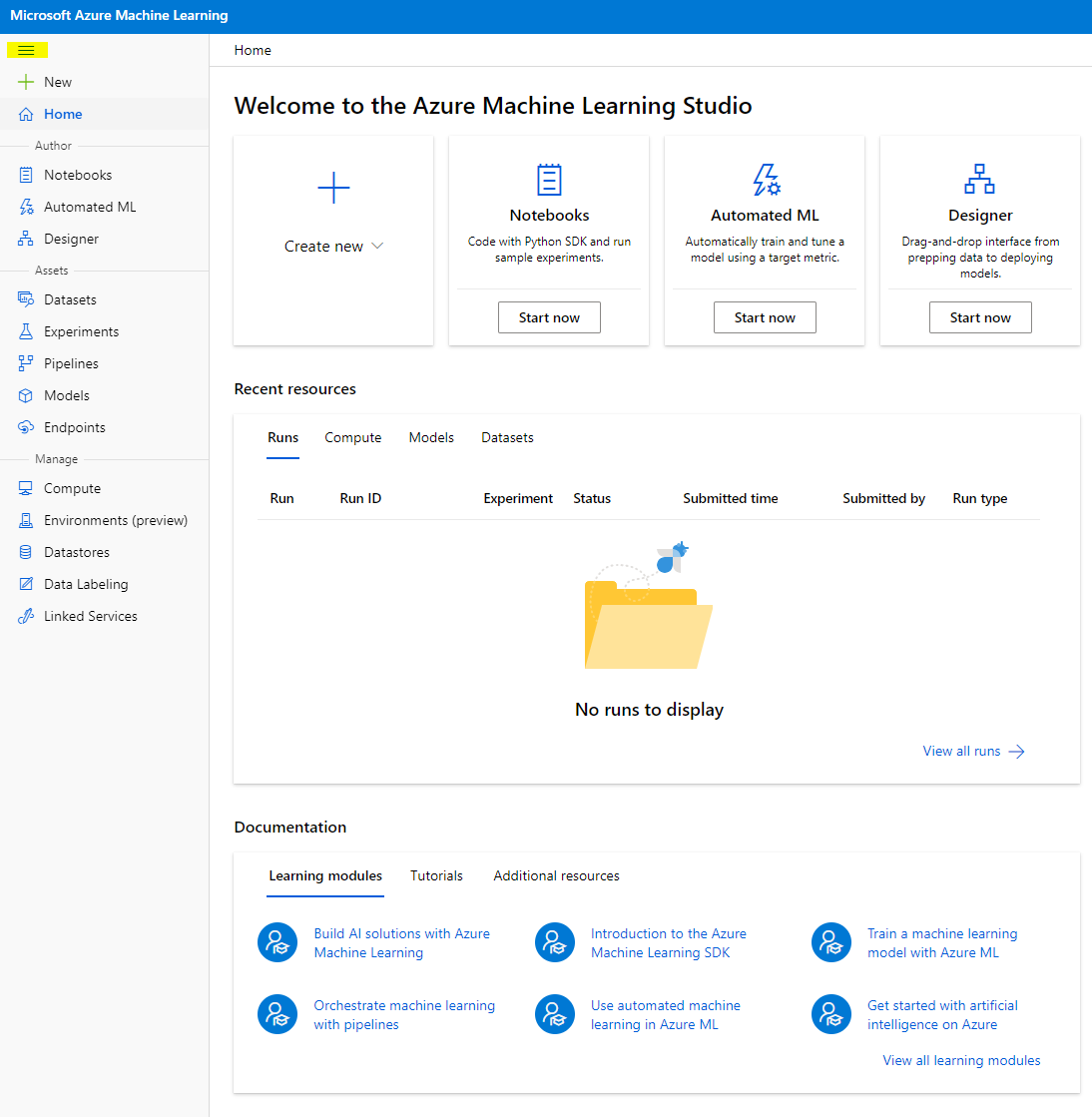
آپ اپنے ورک اسپیس کا انتظام Azure پورٹل کے ذریعے کر سکتے ہیں، لیکن ڈیٹا سائنسدانوں اور مشین لرننگ آپریشنز انجینئرز کے لیے، Azure Machine Learning اسٹوڈیو ورک اسپیس وسائل کا انتظام کرنے کے لیے زیادہ مرکوز یوزر انٹرفیس فراہم کرتا ہے۔
2.2 کمپیوٹ وسائل
کمپیوٹ وسائل کلاؤڈ پر مبنی وسائل ہیں جن پر آپ ماڈل کی تربیت اور ڈیٹا کی دریافت کے عمل چلا سکتے ہیں۔ آپ چار قسم کے کمپیوٹ وسائل بنا سکتے ہیں:
- کمپیوٹ انسٹینسز: ترقیاتی ورک اسٹیشنز جنہیں ڈیٹا سائنسدان ڈیٹا اور ماڈلز کے ساتھ کام کرنے کے لیے استعمال کر سکتے ہیں۔ اس میں ایک ورچوئل مشین (VM) بنانا اور نوٹ بک انسٹینس لانچ کرنا شامل ہے۔ آپ پھر نوٹ بک سے کمپیوٹ کلسٹر کو کال کرکے ماڈل کی تربیت کر سکتے ہیں۔
- کمپیوٹ کلسٹرز: تجرباتی کوڈ کے آن ڈیمانڈ پروسیسنگ کے لیے قابل توسیع VMs کے کلسٹرز۔ آپ کو ماڈل کی تربیت کے وقت اس کی ضرورت ہوگی۔ کمپیوٹ کلسٹرز خصوصی GPU یا CPU وسائل بھی استعمال کر سکتے ہیں۔
- انفرنس کلسٹرز: پیش گوئی کی خدمات کے لیے تعیناتی کے اہداف جو آپ کے تربیت یافتہ ماڈلز استعمال کرتے ہیں۔
- منسلک کمپیوٹ: موجودہ Azure کمپیوٹ وسائل جیسے ورچوئل مشینز یا Azure Databricks کلسٹرز سے لنک کرتا ہے۔
2.2.1 اپنے کمپیوٹ وسائل کے لیے صحیح اختیارات کا انتخاب
کمپیوٹ وسائل بناتے وقت کچھ اہم عوامل کو مدنظر رکھنا ضروری ہے، اور یہ انتخاب اہم فیصلے ہو سکتے ہیں۔
کیا آپ کو CPU یا GPU کی ضرورت ہے؟
CPU (سنٹرل پروسیسنگ یونٹ) ایک الیکٹرانک سرکٹ ہے جو کمپیوٹر پروگرام کے احکامات کو انجام دیتا ہے۔ GPU (گرافکس پروسیسنگ یونٹ) ایک خاص الیکٹرانک سرکٹ ہے جو گرافکس سے متعلق کوڈ کو بہت تیز رفتاری سے انجام دے سکتا ہے۔
CPU اور GPU کی ساخت میں بنیادی فرق یہ ہے کہ CPU کو وسیع پیمانے پر کاموں کو جلدی انجام دینے کے لیے ڈیزائن کیا گیا ہے (جسے CPU کلاک اسپیڈ سے ماپا جاتا ہے)، لیکن یہ بیک وقت چلنے والے کاموں کی تعداد میں محدود ہوتا ہے۔ GPUs کو متوازی کمپیوٹنگ کے لیے ڈیزائن کیا گیا ہے اور یہ گہرے سیکھنے کے کاموں کے لیے زیادہ بہتر ہیں۔
| CPU | GPU |
|---|---|
| کم مہنگا | زیادہ مہنگا |
| کم سطح کی ہم وقتی | زیادہ سطح کی ہم وقتی |
| گہرے سیکھنے کے ماڈلز کی تربیت میں سست | گہرے سیکھنے کے لیے بہترین |
کلسٹر کا سائز
بڑے کلسٹر زیادہ مہنگے ہوتے ہیں لیکن بہتر ردعمل فراہم کرتے ہیں۔ لہذا، اگر آپ کے پاس وقت ہے لیکن پیسے کم ہیں، تو آپ کو چھوٹے کلسٹر سے شروع کرنا چاہیے۔ اس کے برعکس، اگر آپ کے پاس پیسے ہیں لیکن وقت کم ہے، تو آپ کو بڑے کلسٹر سے شروع کرنا چاہیے۔
VM کا سائز
اپنے وقت اور بجٹ کی حدود کے مطابق، آپ اپنی RAM، ڈسک، کورز کی تعداد اور کلاک اسپیڈ کے سائز کو مختلف کر سکتے ہیں۔ ان تمام پیرامیٹرز کو بڑھانا مہنگا ہوگا، لیکن کارکردگی بہتر ہوگی۔
وقف شدہ یا کم ترجیحی انسٹینسز؟
کم ترجیحی انسٹینس کا مطلب ہے کہ یہ مداخلت پذیر ہے: بنیادی طور پر، Microsoft Azure ان وسائل کو لے کر کسی دوسرے کام کو تفویض کر سکتا ہے، جس سے ایک کام میں خلل پڑ سکتا ہے۔ وقف شدہ انسٹینس، یا غیر مداخلت پذیر، کا مطلب ہے کہ کام آپ کی اجازت کے بغیر کبھی ختم نہیں ہوگا۔ یہ وقت بمقابلہ پیسے کا ایک اور غور ہے، کیونکہ مداخلت پذیر انسٹینسز وقف شدہ انسٹینسز سے کم مہنگے ہیں۔
2.2.2 کمپیوٹ کلسٹر بنانا
Azure ML ورک اسپیس میں جو ہم نے پہلے بنایا تھا، کمپیوٹ پر جائیں اور آپ ان مختلف کمپیوٹ وسائل کو دیکھ سکیں گے جن پر ہم نے ابھی بات کی (یعنی کمپیوٹ انسٹینسز، کمپیوٹ کلسٹرز، انفرینس کلسٹرز اور منسلک کمپیوٹ)۔ اس پروجیکٹ کے لیے، ہمیں ماڈل کی تربیت کے لیے کمپیوٹ کلسٹر کی ضرورت ہوگی۔ اسٹوڈیو میں، "کمپیوٹ" مینو پر کلک کریں، پھر "کمپیوٹ کلسٹر" ٹیب پر کلک کریں اور کمپیوٹ کلسٹر بنانے کے لیے "+ نیا" بٹن پر کلک کریں۔
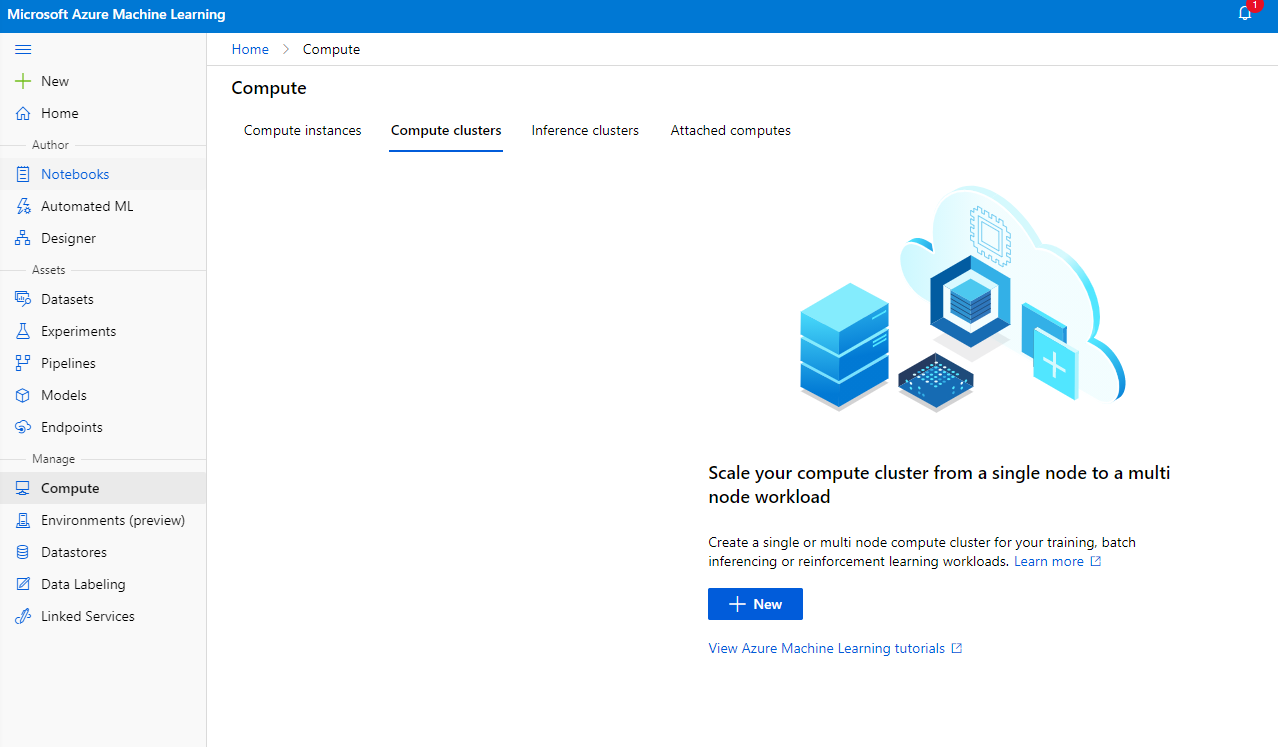
- اپنے اختیارات منتخب کریں: وقف شدہ بمقابلہ کم ترجیحی، CPU یا GPU، VM سائز اور کورز کی تعداد (آپ اس پروجیکٹ کے لیے ڈیفالٹ سیٹنگز رکھ سکتے ہیں)۔
- "اگلا" بٹن پر کلک کریں۔
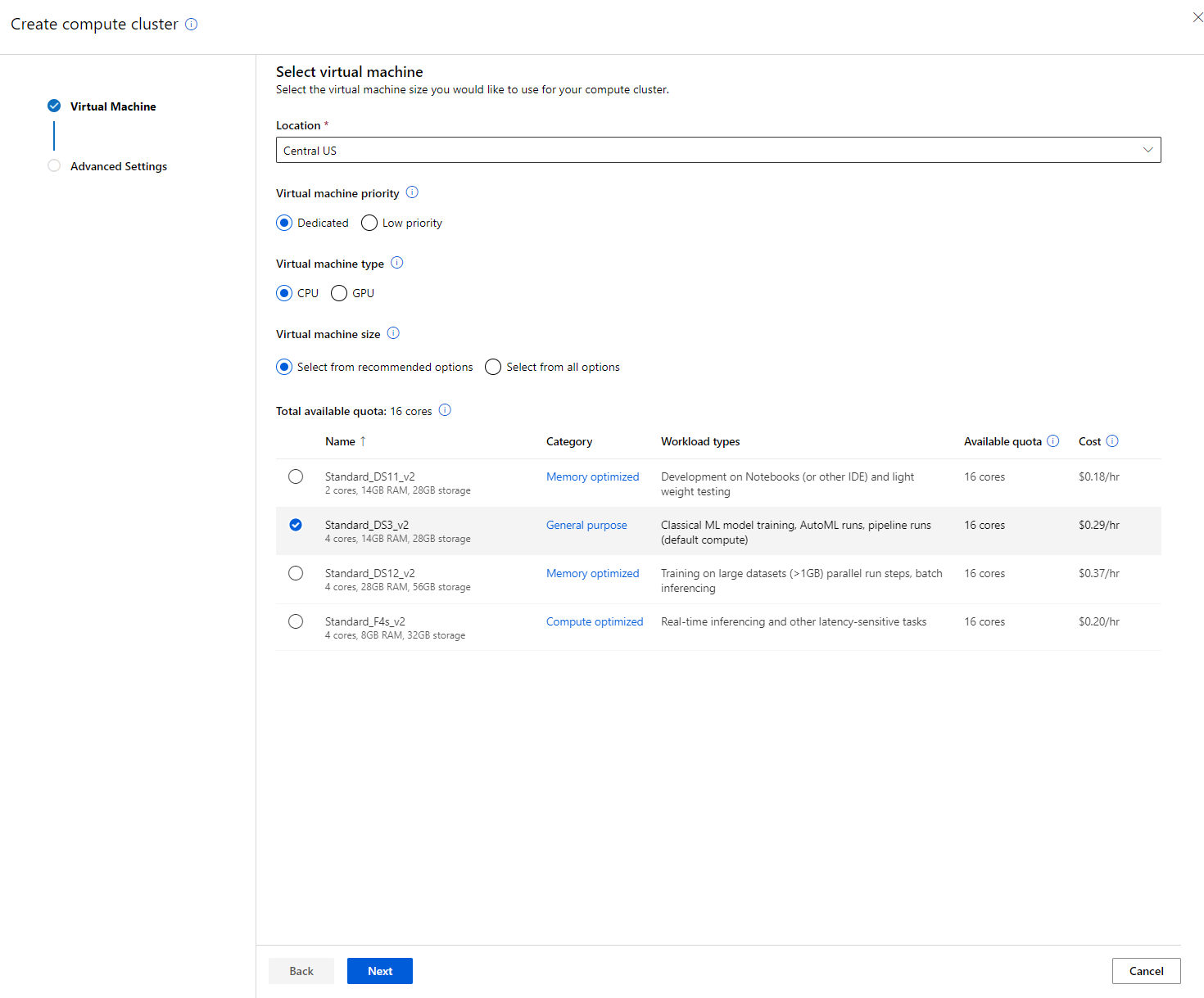
- کلسٹر کو ایک کمپیوٹ نام دیں۔
- اپنے اختیارات منتخب کریں: کم از کم/زیادہ سے زیادہ نوڈز کی تعداد، اسکیل ڈاؤن سے پہلے غیر فعال سیکنڈز، SSH رسائی۔ نوٹ کریں کہ اگر کم از کم نوڈز کی تعداد 0 ہے، تو آپ کلسٹر کے غیر فعال ہونے پر پیسے بچائیں گے۔ نوٹ کریں کہ زیادہ سے زیادہ نوڈز کی تعداد جتنی زیادہ ہوگی، تربیت اتنی ہی مختصر ہوگی۔ زیادہ سے زیادہ نوڈز کی تجویز کردہ تعداد 3 ہے۔
- "بنانا" بٹن پر کلک کریں۔ یہ مرحلہ چند منٹ لے سکتا ہے۔
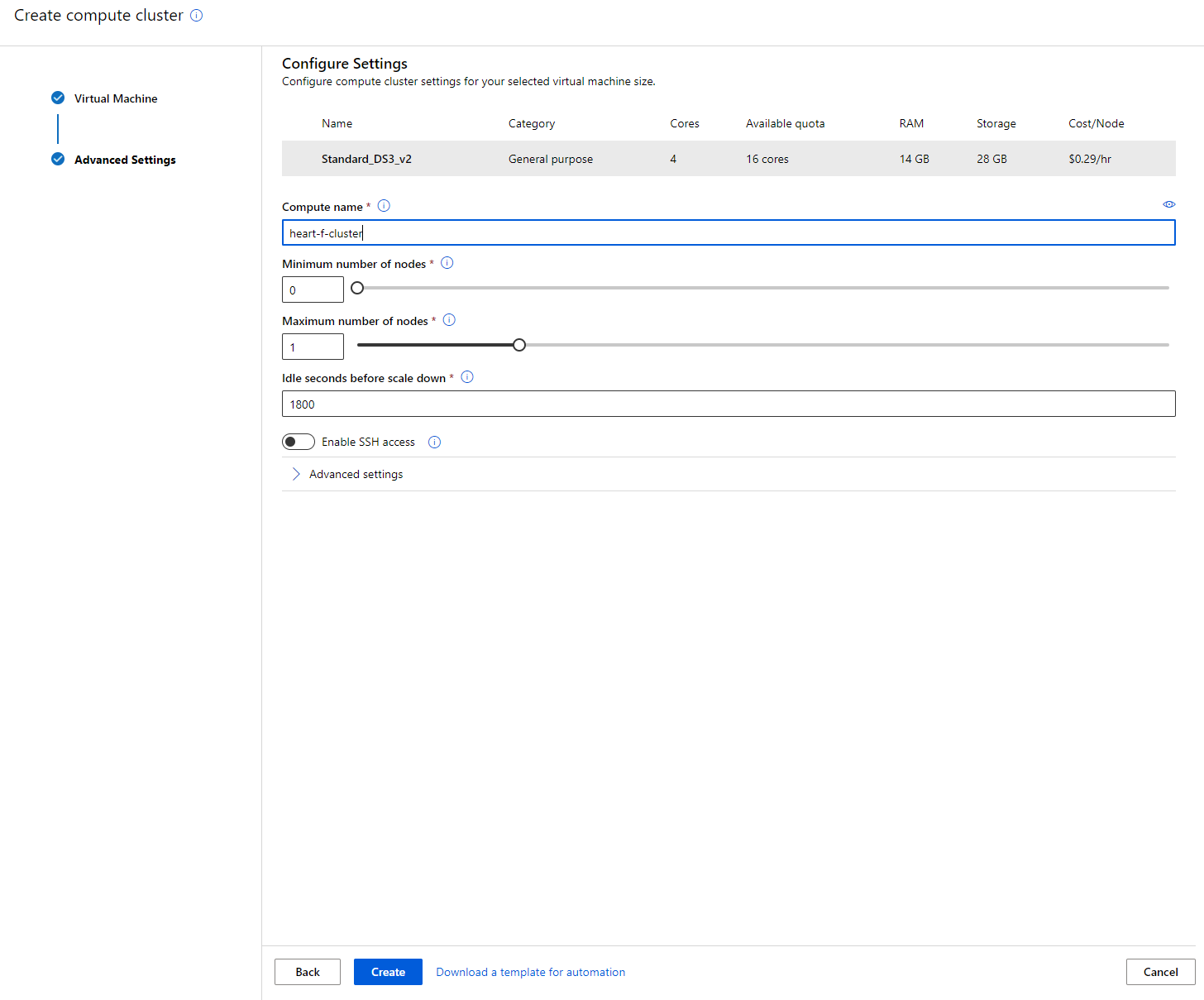
زبردست! اب جب کہ ہمارے پاس کمپیوٹ کلسٹر ہے، ہمیں ڈیٹا کو Azure ML اسٹوڈیو میں لوڈ کرنے کی ضرورت ہے۔
2.3 ڈیٹا سیٹ لوڈ کرنا
-
Azure ML ورک اسپیس میں جو ہم نے پہلے بنایا تھا، بائیں مینو میں "ڈیٹا سیٹس" پر کلک کریں اور ڈیٹا سیٹ بنانے کے لیے "+ ڈیٹا سیٹ بنائیں" بٹن پر کلک کریں۔ "مقامی فائلز سے" آپشن منتخب کریں اور وہ Kaggle ڈیٹا سیٹ منتخب کریں جو ہم نے پہلے ڈاؤن لوڈ کیا تھا۔
-
اپنے ڈیٹا سیٹ کو ایک نام، قسم اور وضاحت دیں۔ "اگلا" پر کلک کریں۔ فائلز سے ڈیٹا اپ لوڈ کریں۔ "اگلا" پر کلک کریں۔
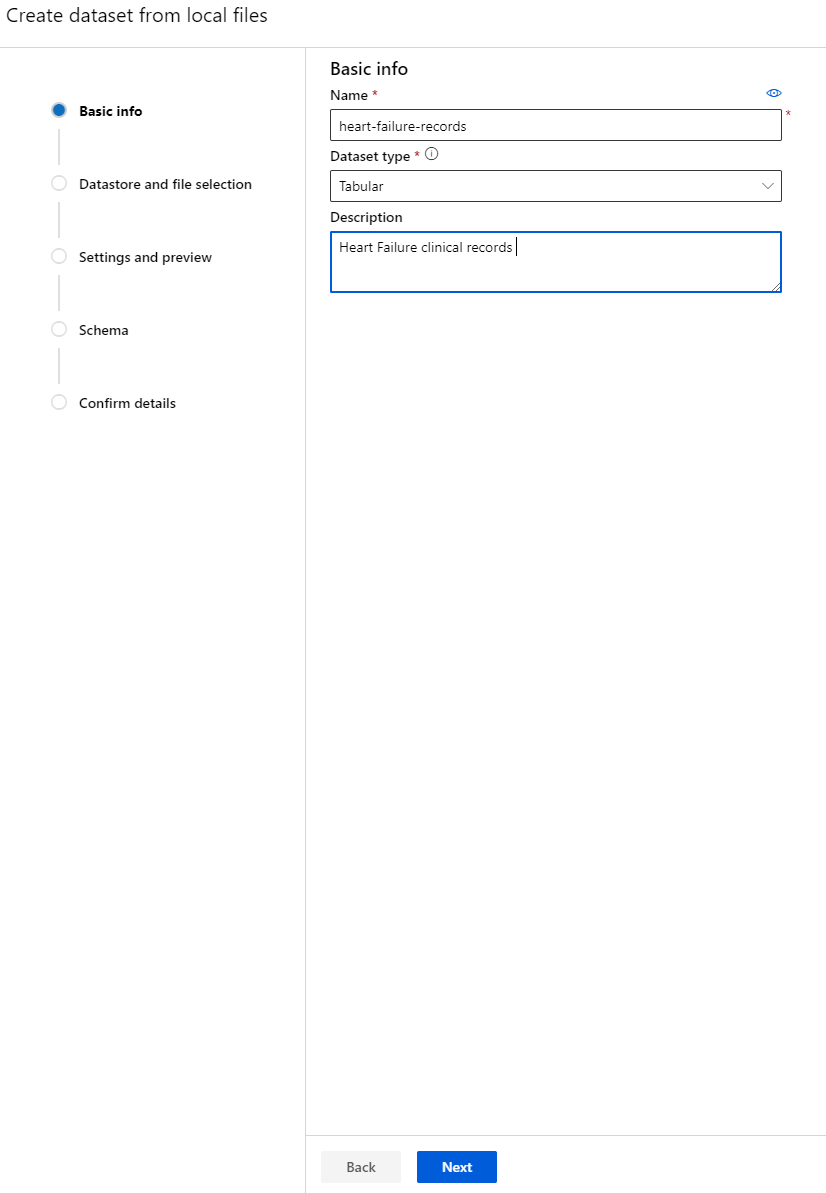
-
اسکیمہ میں، درج ذیل خصوصیات کے لیے ڈیٹا کی قسم کو Boolean میں تبدیل کریں: anaemia، diabetes، high blood pressure، sex، smoking، اور DEATH_EVENT۔ "اگلا" پر کلک کریں اور "بنانا" پر کلک کریں۔
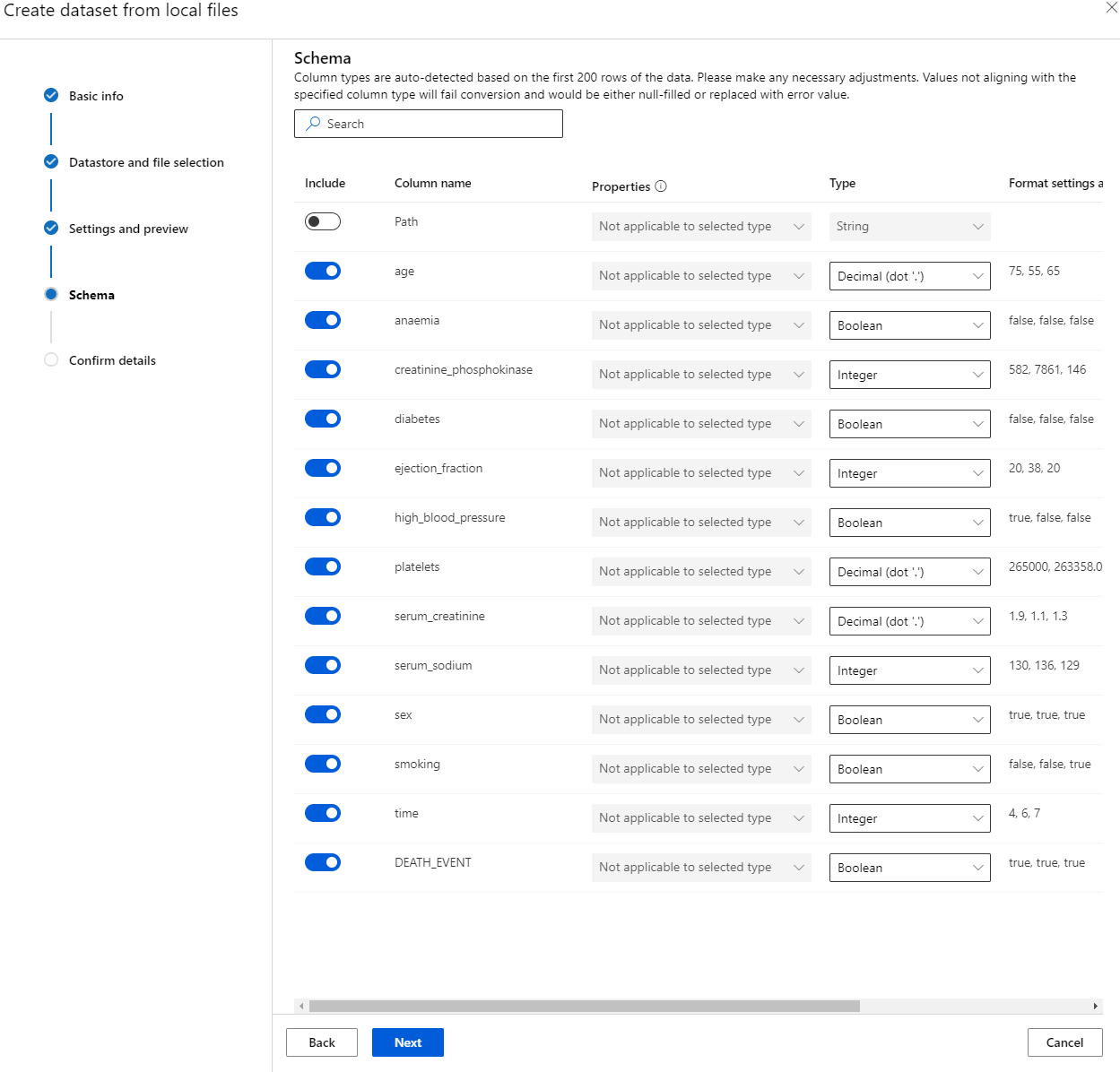
زبردست! اب جب کہ ڈیٹا سیٹ موجود ہے اور کمپیوٹ کلسٹر بنایا گیا ہے، ہم ماڈل کی تربیت شروع کر سکتے ہیں!
2.4 کم کوڈ/کوئی کوڈ تربیت AutoML کے ساتھ
روایتی مشین لرننگ ماڈل کی ترقی وسائل کا تقاضا کرتی ہے، اہم ڈومین علم اور وقت کی ضرورت ہوتی ہے تاکہ درجنوں ماڈلز تیار اور موازنہ کیے جا سکیں۔ خودکار مشین لرننگ (AutoML)، مشین لرننگ ماڈل کی ترقی کے وقت طلب، تکراری کاموں کو خودکار کرنے کا عمل ہے۔ یہ ڈیٹا سائنسدانوں، تجزیہ کاروں، اور ڈویلپرز کو اعلی پیمانے، کارکردگی، اور پیداواریت کے ساتھ ML ماڈلز بنانے کی اجازت دیتا ہے، جبکہ ماڈل کے معیار کو برقرار رکھتا ہے۔ یہ پروڈکشن کے لیے تیار ML ماڈلز حاصل کرنے میں وقت کو کم کرتا ہے، بڑی آسانی اور کارکردگی کے ساتھ۔ مزید جانیں
-
Azure ML ورک اسپیس میں جو ہم نے پہلے بنایا تھا، بائیں مینو میں "Automated ML" پر کلک کریں اور وہ ڈیٹا سیٹ منتخب کریں جو آپ نے ابھی اپ لوڈ کیا تھا۔ "اگلا" پر کلک کریں۔
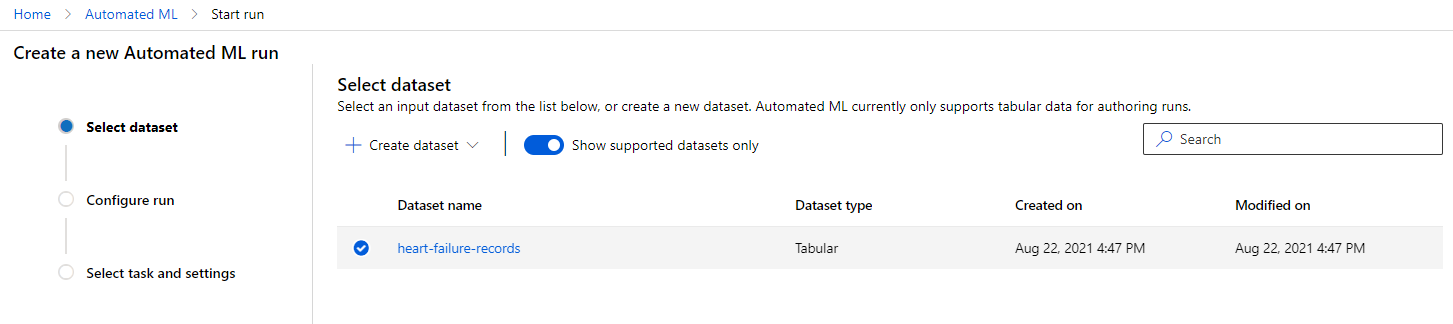
-
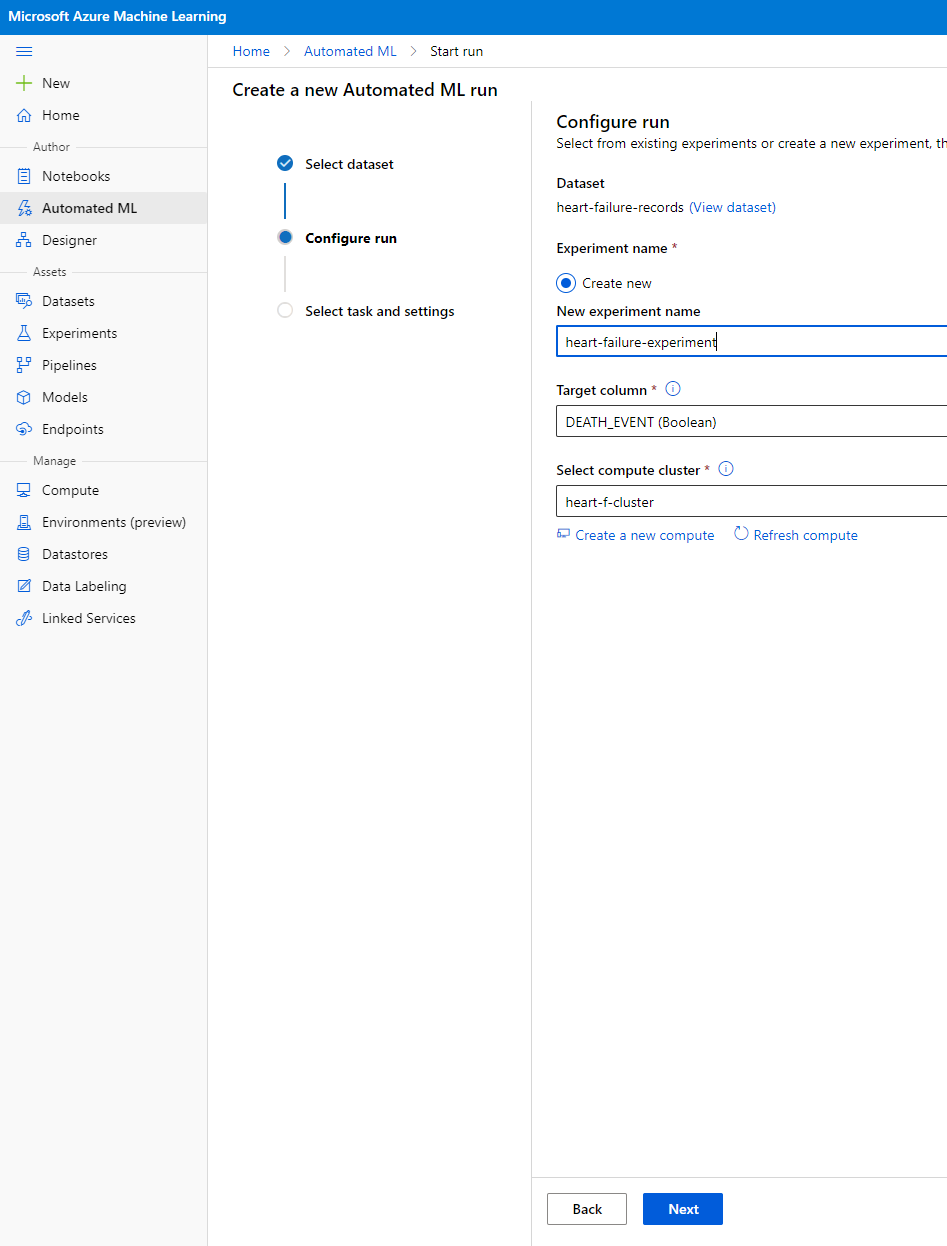
ایک نیا تجربہ نام، ہدف کالم (DEATH_EVENT) اور وہ کمپیوٹ کلسٹر درج کریں جو ہم نے بنایا تھا۔ "اگلا" پر کلک کریں۔
-
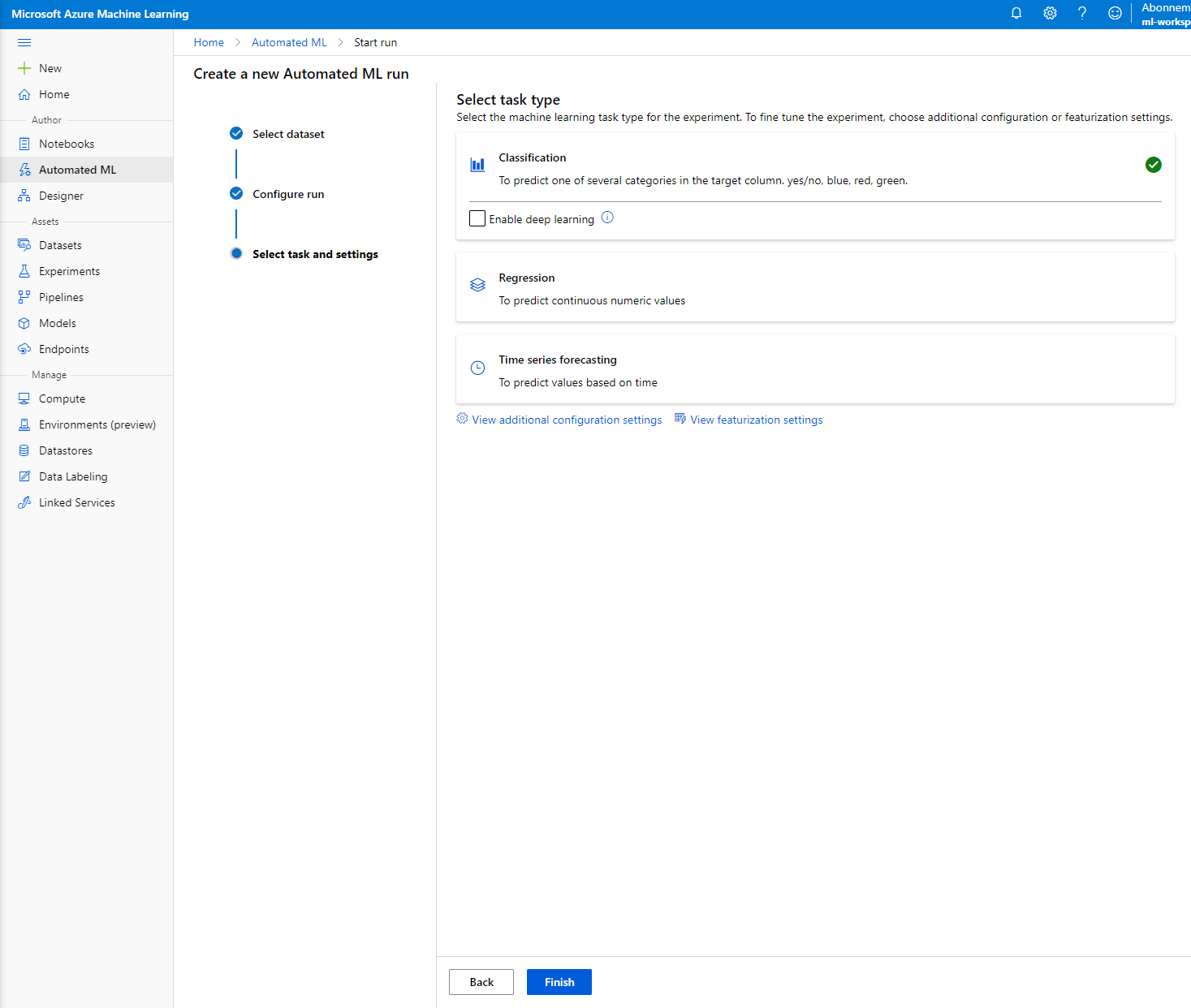
"Classification" منتخب کریں اور "ختم کریں" پر کلک کریں۔ یہ مرحلہ کمپیوٹ کلسٹر کے سائز پر منحصر ہے، 30 منٹ سے 1 گھنٹے تک لے سکتا ہے۔
-
جب رن مکمل ہو جائے، "Automated ML" ٹیب پر کلک کریں، اپنے رن پر کلک کریں، اور "Best model summary" کارڈ میں الگورتھم پر کلک کریں۔
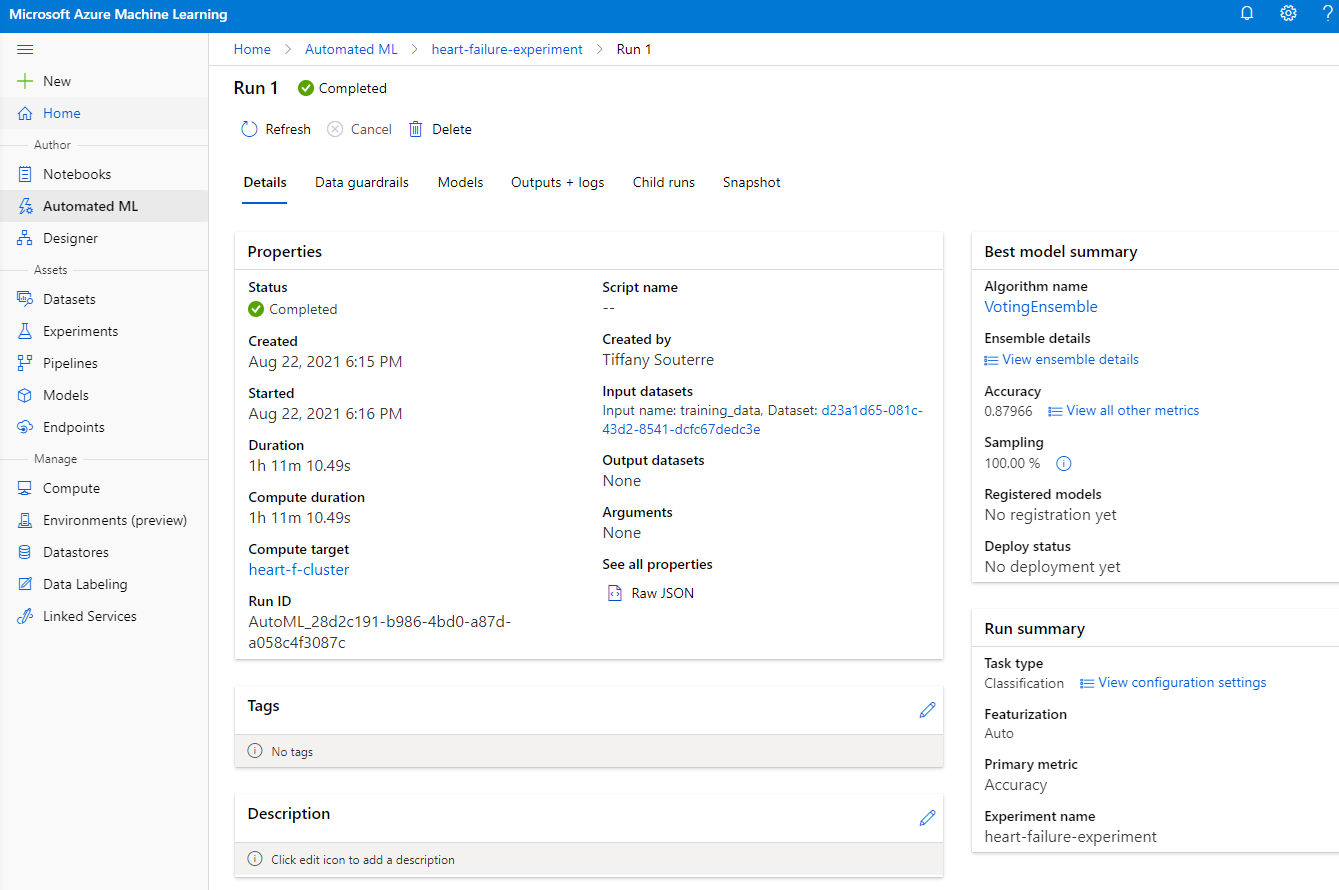
یہاں آپ AutoML کے ذریعے تیار کردہ بہترین ماڈل کی تفصیلی وضاحت دیکھ سکتے ہیں۔ آپ ماڈلز ٹیب میں دیگر ماڈلز کو بھی دریافت کر سکتے ہیں۔ چند منٹ لیں اور Explanations (preview button) میں ماڈلز کو دریافت کریں۔ جب آپ نے وہ ماڈل منتخب کر لیا ہو جسے آپ استعمال کرنا چاہتے ہیں (یہاں ہم AutoML کے منتخب کردہ بہترین ماڈل کو منتخب کریں گے)، ہم دیکھیں گے کہ اسے کیسے تعینات کیا جا سکتا ہے۔
3. کم کوڈ/کوئی کوڈ ماڈل کی تعیناتی اور اینڈ پوائنٹ کا استعمال
3.1 ماڈل کی تعیناتی
خودکار مشین لرننگ انٹرفیس آپ کو بہترین ماڈل کو چند مراحل میں ویب سروس کے طور پر تعینات کرنے کی اجازت دیتا ہے۔ تعیناتی ماڈل کا انضمام ہے تاکہ یہ نئے ڈیٹا کی بنیاد پر پیش گوئیاں کر سکے اور ممکنہ مواقع کے علاقوں کی نشاندہی کر سکے۔ اس پروجیکٹ کے لیے، ویب سروس پر تعیناتی کا مطلب یہ ہے کہ طبی ایپلیکیشنز ماڈل کو استعمال کر سکیں گی تاکہ اپنے مریضوں کے دل کے دورے کے خطرے کی لائیو پیش گوئی کر سکیں۔
بہترین ماڈل کی وضاحت میں، "Deploy" بٹن پر کلک کریں۔
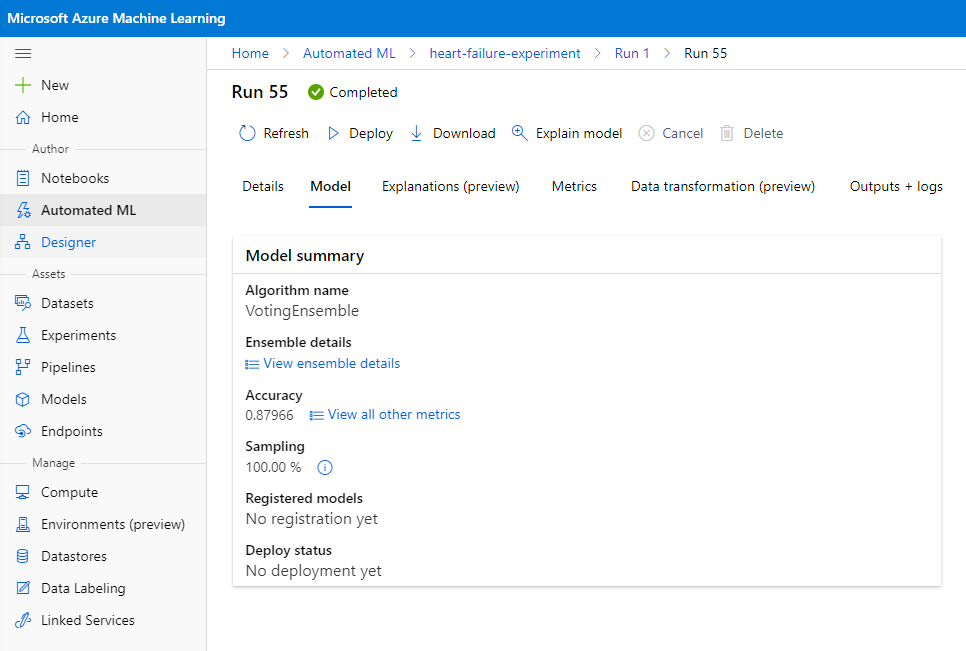
- اسے ایک نام، وضاحت، کمپیوٹ قسم (Azure Container Instance)، تصدیق کو فعال کریں اور "Deploy" پر کلک کریں۔ یہ مرحلہ مکمل ہونے میں تقریباً 20 منٹ لگ سکتا ہے۔ تعیناتی کے عمل میں کئی مراحل شامل ہیں، بشمول ماڈل کو رجسٹر کرنا، وسائل تیار کرنا، اور انہیں ویب سروس کے لیے ترتیب دینا۔ Deploy status کے تحت ایک اسٹیٹس پیغام ظاہر ہوتا ہے۔ تعیناتی کی حیثیت کو چیک کرنے کے لیے وقتاً فوقتاً Refresh منتخب کریں۔ جب اسٹیٹس "Healthy" ہو تو یہ تعینات اور چل رہا ہوتا ہے۔
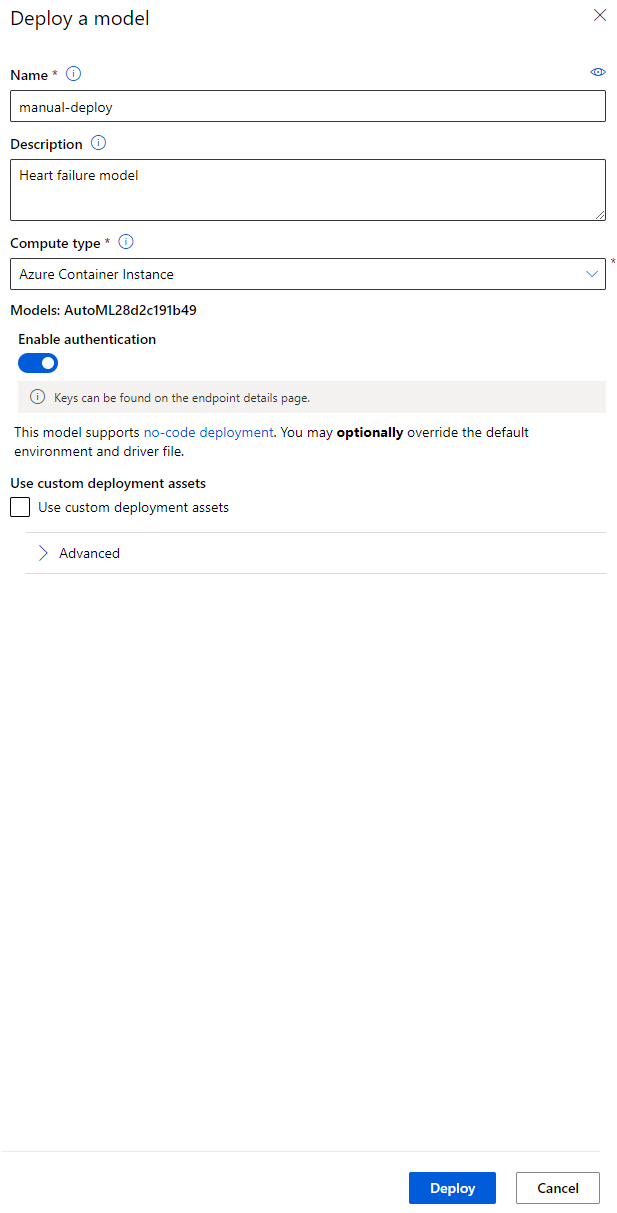
- جب یہ تعینات ہو جائے، "Endpoint" ٹیب پر کلک کریں اور اس اینڈ پوائنٹ پر کلک کریں جو آپ نے ابھی تعینات کیا ہے۔ یہاں آپ اینڈ پوائنٹ کے بارے میں تمام تفصیلات حاصل کر سکتے ہیں۔
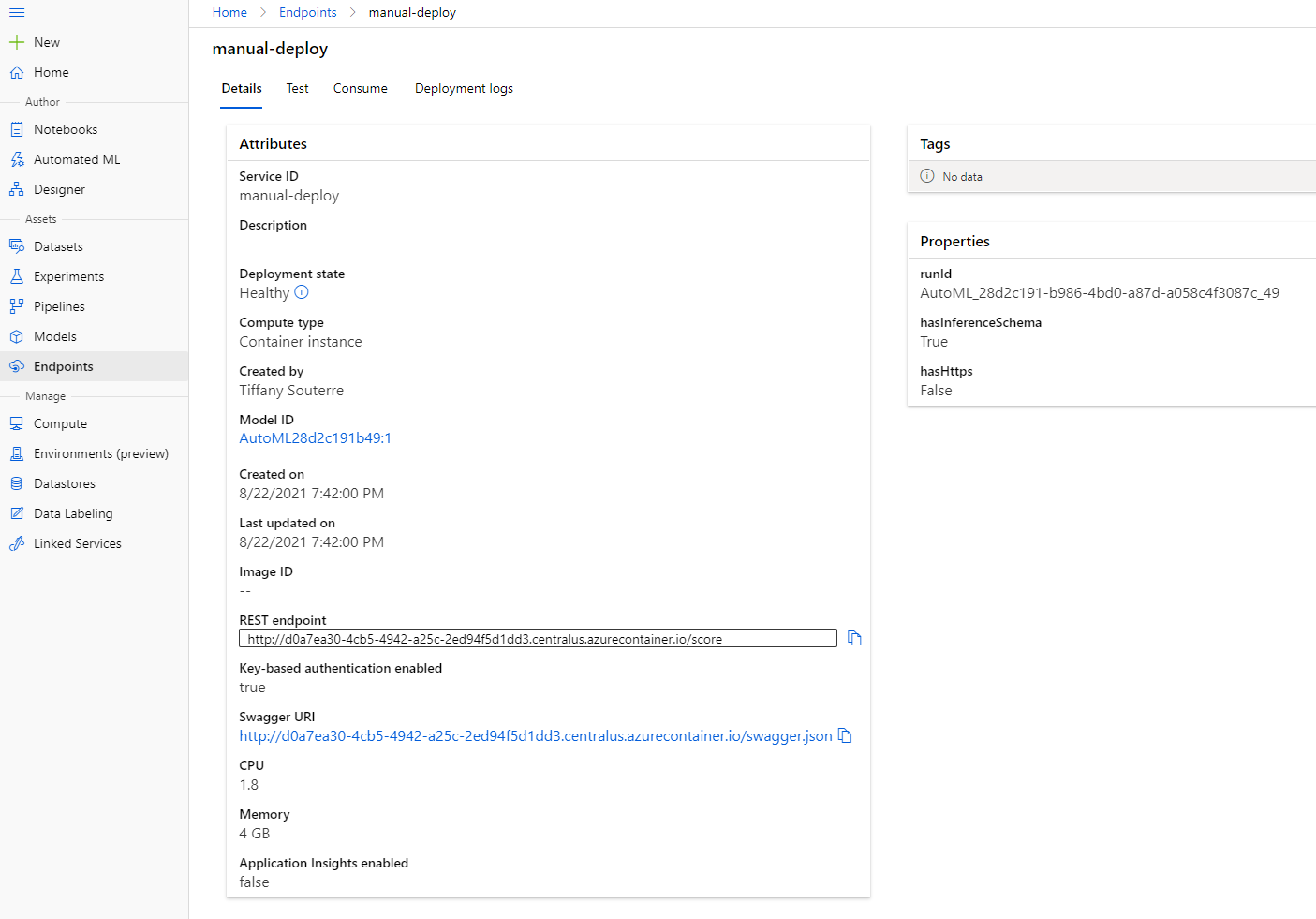
زبردست! اب جب کہ ہمارے پاس ماڈل تعینات ہو گیا ہے، ہم اینڈ پوائنٹ کا استعمال شروع کر سکتے ہیں۔
3.2 اینڈ پوائنٹ کا استعمال
"Consume" ٹیب پر کلک کریں۔ یہاں آپ کو REST اینڈ پوائنٹ اور استعمال کے آپشن میں ایک پائتھن اسکرپٹ ملے گا۔ پائتھن کوڈ کو پڑھنے کے لیے کچھ وقت لیں۔
یہ اسکرپٹ براہ راست آپ کی مقامی مشین سے چلایا جا سکتا ہے اور آپ کے اینڈ پوائنٹ کو استعمال کرے گا۔
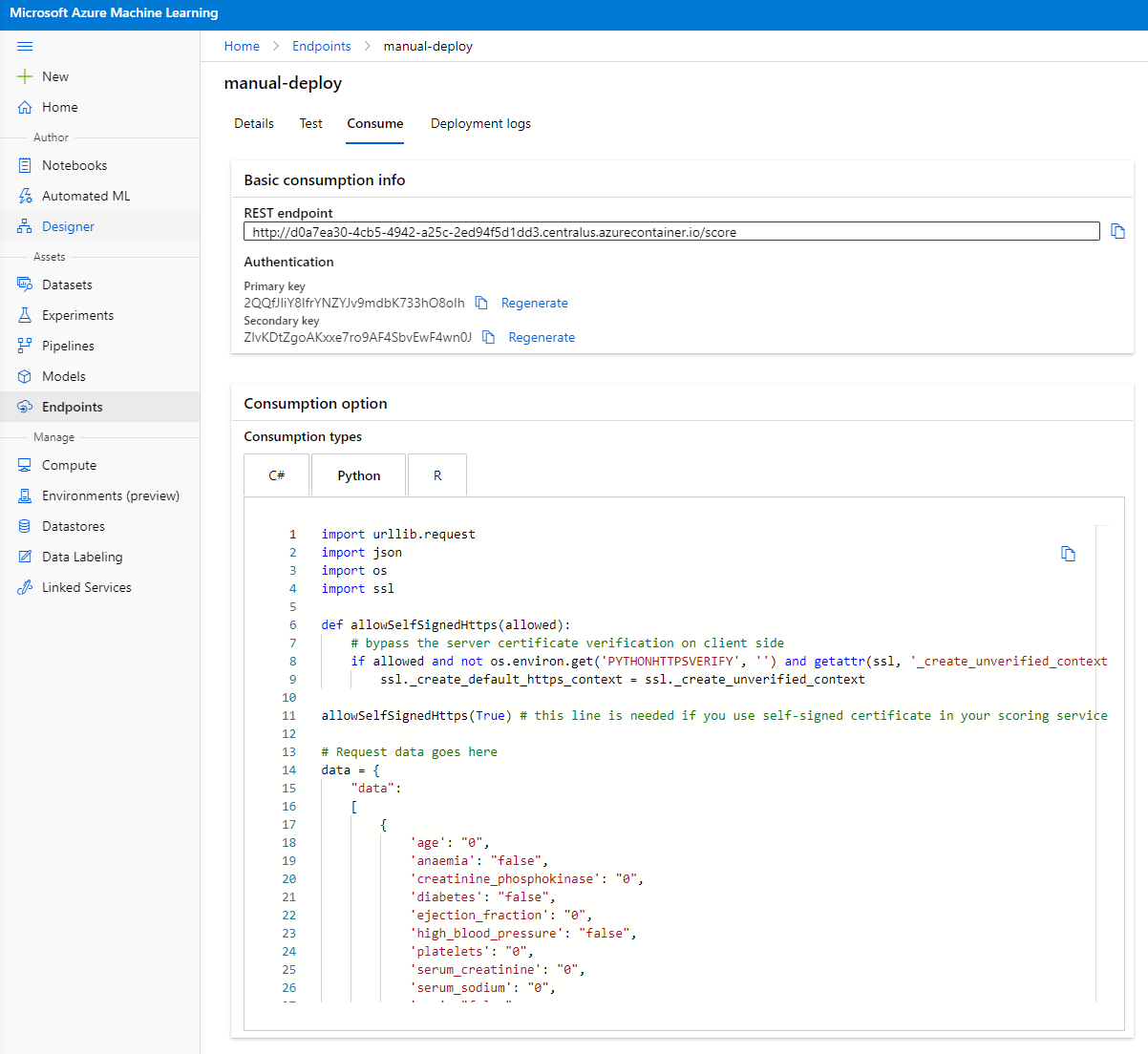
ان دو لائنز کو چیک کرنے کے لیے ایک لمحہ لیں:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
url متغیر Consume ٹیب میں پایا جانے والا REST اینڈ پوائنٹ ہے اور api_key متغیر Consume ٹیب میں پایا جانے والا پرائمری کلید ہے (صرف اس صورت میں جب آپ نے تصدیق کو فعال کیا ہو)۔ یہی طریقہ ہے جس سے اسکرپٹ اینڈ پوائنٹ کو استعمال کر سکتا ہے۔
- اسکرپٹ چلانے پر، آپ کو درج ذیل آؤٹ پٹ نظر آنا چاہیے:
b'"{\\"result\\": [true]}"'
اس کا مطلب ہے کہ دیے گئے ڈیٹا کے لیے دل کی ناکامی کی پیش گوئی درست ہے۔ یہ منطقی ہے کیونکہ اگر آپ اسکرپٹ میں خودکار طور پر تیار کردہ ڈیٹا کو قریب سے دیکھیں، تو سب کچھ ڈیفالٹ کے طور پر 0 اور غلط ہے۔ آپ درج ذیل ان پٹ نمونے کے ساتھ ڈیٹا کو تبدیل کر سکتے ہیں:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
اسکرپٹ کو یہ واپس کرنا چاہیے:
python b'"{\\"result\\": [true, false]}"'
مبارک ہو! آپ نے ماڈل کو تعینات کیا، اسے استعمال کیا اور Azure ML پر تربیت دی!
نوٹ: جب آپ پروجیکٹ مکمل کر لیں، تو تمام وسائل کو حذف کرنا نہ بھولیں۔
🚀 چیلنج
AutoML کے ذریعے تیار کردہ بہترین ماڈلز کے ماڈل وضاحتوں اور تفصیلات کو قریب سے دیکھیں۔ سمجھنے کی کوشش کریں کہ بہترین ماڈل دوسرے ماڈلز سے کیوں بہتر ہے۔ کون سے الگورتھم کا موازنہ کیا گیا؟ ان میں کیا فرق ہے؟ اس معاملے میں بہترین ماڈل کیوں بہتر کارکردگی دکھا رہا ہے؟
لیکچر کے بعد کوئز
جائزہ اور خود مطالعہ
اس سبق میں، آپ نے سیکھا کہ دل کی ناکامی کے خطرے کی پیش گوئی کے لیے ماڈل کو کلاؤڈ میں کم کوڈ/کوئی کوڈ انداز میں تربیت، تعینات اور استعمال کیسے کریں۔ اگر آپ نے ابھی تک ایسا نہیں کیا ہے، تو AutoML کے ذریعے تیار کردہ بہترین ماڈلز کے ماڈل وضاحتوں میں گہرائی سے جائیں اور سمجھنے کی کوشش کریں کہ بہترین ماڈل دوسرے ماڈلز سے کیوں بہتر ہے۔
آپ کم کوڈ/کوئی کوڈ AutoML کے بارے میں مزید جاننے کے لیے یہ دستاویز پڑھ سکتے ہیں۔
اسائنمنٹ
Azure ML پر کم کوڈ/کوئی کوڈ ڈیٹا سائنس پروجیکٹ
ڈسکلیمر:
یہ دستاویز AI ترجمہ سروس Co-op Translator کا استعمال کرتے ہوئے ترجمہ کی گئی ہے۔ ہم درستگی کے لیے کوشش کرتے ہیں، لیکن براہ کرم آگاہ رہیں کہ خودکار ترجمے میں غلطیاں یا غیر درستیاں ہو سکتی ہیں۔ اصل دستاویز کو اس کی اصل زبان میں مستند ذریعہ سمجھا جانا چاہیے۔ اہم معلومات کے لیے، پیشہ ور انسانی ترجمہ کی سفارش کی جاتی ہے۔ ہم اس ترجمے کے استعمال سے پیدا ہونے والی کسی بھی غلط فہمی یا غلط تشریح کے ذمہ دار نہیں ہیں۔