|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Práca s dátami: Nerelačné dáta
 |
|---|
| Práca s NoSQL dátami - Sketchnote od @nitya |
Kvíz pred prednáškou
Dáta nie sú obmedzené len na relačné databázy. Táto lekcia sa zameriava na nerelačné dáta a pokryje základy tabuľkových procesorov a NoSQL.
Tabuľkové procesory
Tabuľkové procesory sú populárnym spôsobom ukladania a skúmania dát, pretože ich nastavenie a používanie vyžaduje menej práce. V tejto lekcii sa naučíte základné komponenty tabuľkového procesora, ako aj vzorce a funkcie. Príklady budú ilustrované pomocou Microsoft Excel, ale väčšina častí a tém bude mať podobné názvy a kroky v porovnaní s iným softvérom na tabuľkové procesory.

Tabuľkový procesor je súbor, ktorý bude prístupný v súborovom systéme počítača, zariadenia alebo cloudového súborového systému. Samotný softvér môže byť založený na prehliadači alebo aplikácii, ktorú je potrebné nainštalovať na počítač alebo stiahnuť ako aplikáciu. V Exceli sú tieto súbory definované ako zošity a táto terminológia bude používaná v celej lekcii.
Zošit obsahuje jeden alebo viac pracovných listov, pričom každý pracovný list je označený záložkami. V rámci pracovného listu sú obdĺžniky nazývané bunky, ktoré obsahujú skutočné dáta. Bunka je priesečníkom riadku a stĺpca, pričom stĺpce sú označené abecednými znakmi a riadky číselne. Niektoré tabuľkové procesory obsahujú hlavičky v prvých niekoľkých riadkoch na popis dát v bunke.
S týmito základnými prvkami Excel zošita použijeme príklad z Microsoft Templates zameraný na inventár na prechod cez ďalšie časti tabuľkového procesora.
Správa inventára
Súbor tabuľkového procesora s názvom "InventoryExample" je formátovaný tabuľkový procesor položiek v inventári, ktorý obsahuje tri pracovné listy, pričom záložky sú označené "Inventory List", "Inventory Pick List" a "Bin Lookup". Riadok 4 pracovného listu Inventory List je hlavička, ktorá popisuje hodnotu každej bunky v hlavičkovom stĺpci.
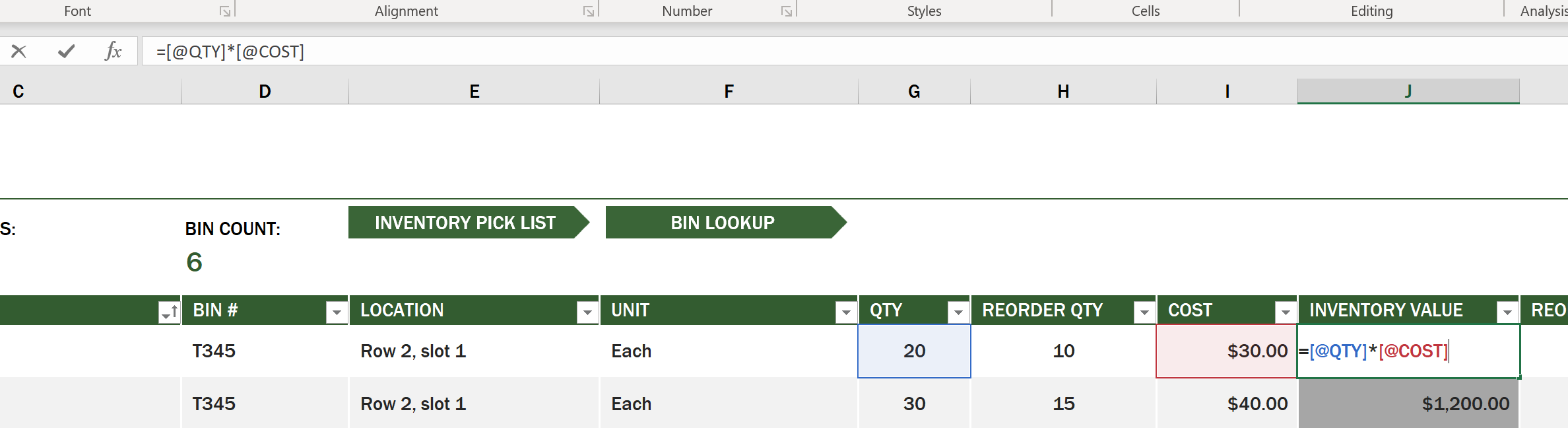
Existujú prípady, keď je hodnota bunky závislá na hodnotách iných buniek na generovanie svojej hodnoty. Tabuľkový procesor Inventory List sleduje náklady na každú položku v inventári, ale čo ak potrebujeme vedieť hodnotu všetkého v inventári? Vzorce vykonávajú operácie na dátach v bunkách a používajú sa na výpočet hodnoty inventára v tomto príklade. Tento tabuľkový procesor použil vzorec v stĺpci Inventory Value na výpočet hodnoty každej položky násobením množstva pod hlavičkou QTY a jej nákladov bunkami pod hlavičkou COST. Dvojité kliknutie alebo zvýraznenie bunky zobrazí vzorec. Všimnete si, že vzorce začínajú znamienkom rovnosti, po ktorom nasleduje výpočet alebo operácia.
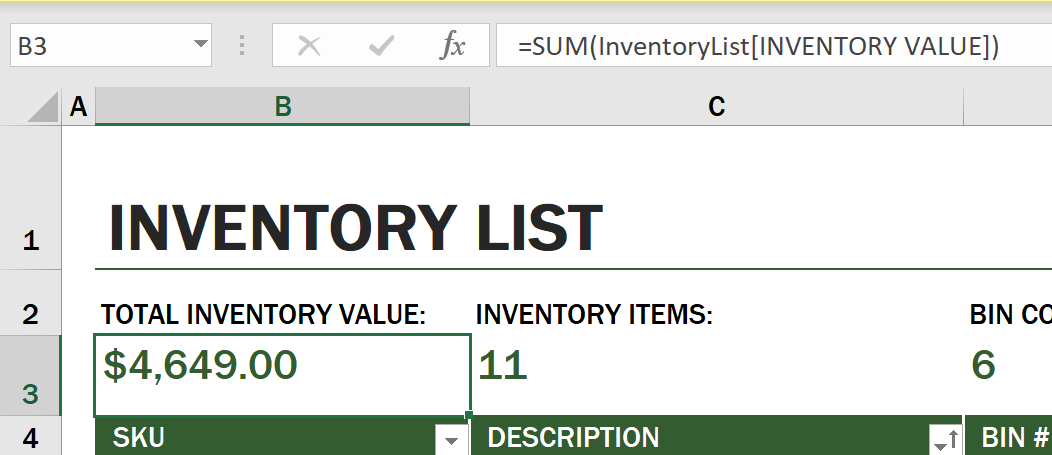
Môžeme použiť ďalší vzorec na sčítanie všetkých hodnôt stĺpca Inventory Value, aby sme získali jeho celkovú hodnotu. To by sa dalo vypočítať sčítaním každej bunky na generovanie súčtu, ale to môže byť zdĺhavá úloha. Excel má funkcie, alebo preddefinované vzorce na vykonávanie výpočtov na hodnotách buniek. Funkcie vyžadujú argumenty, ktoré sú potrebné hodnoty na vykonanie týchto výpočtov. Keď funkcie vyžadujú viac ako jeden argument, musia byť uvedené v konkrétnom poradí, inak funkcia nemusí vypočítať správnu hodnotu. Tento príklad používa funkciu SUM a používa hodnoty stĺpca Inventory Value ako argument na sčítanie, čím generuje celkovú hodnotu uvedenú pod riadkom 3, stĺpcom B (tiež označovaným ako B3).
NoSQL
NoSQL je zastrešujúci termín pre rôzne spôsoby ukladania nerelačných dát a môže byť interpretovaný ako "non-SQL", "nerelačné" alebo "nielen SQL". Tieto typy databázových systémov môžu byť kategorizované do 4 typov.
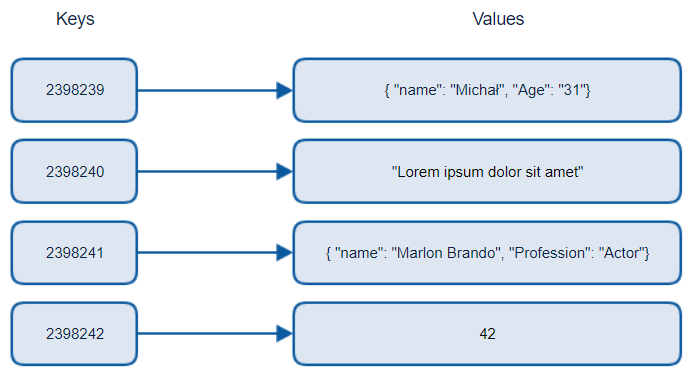
Zdroj z Michał Białecki Blog
Key-value databázy spájajú unikátne kľúče, ktoré sú jedinečným identifikátorom spojeným s hodnotou. Tieto páry sú uložené pomocou hash tabuľky s vhodnou hashovacou funkciou.
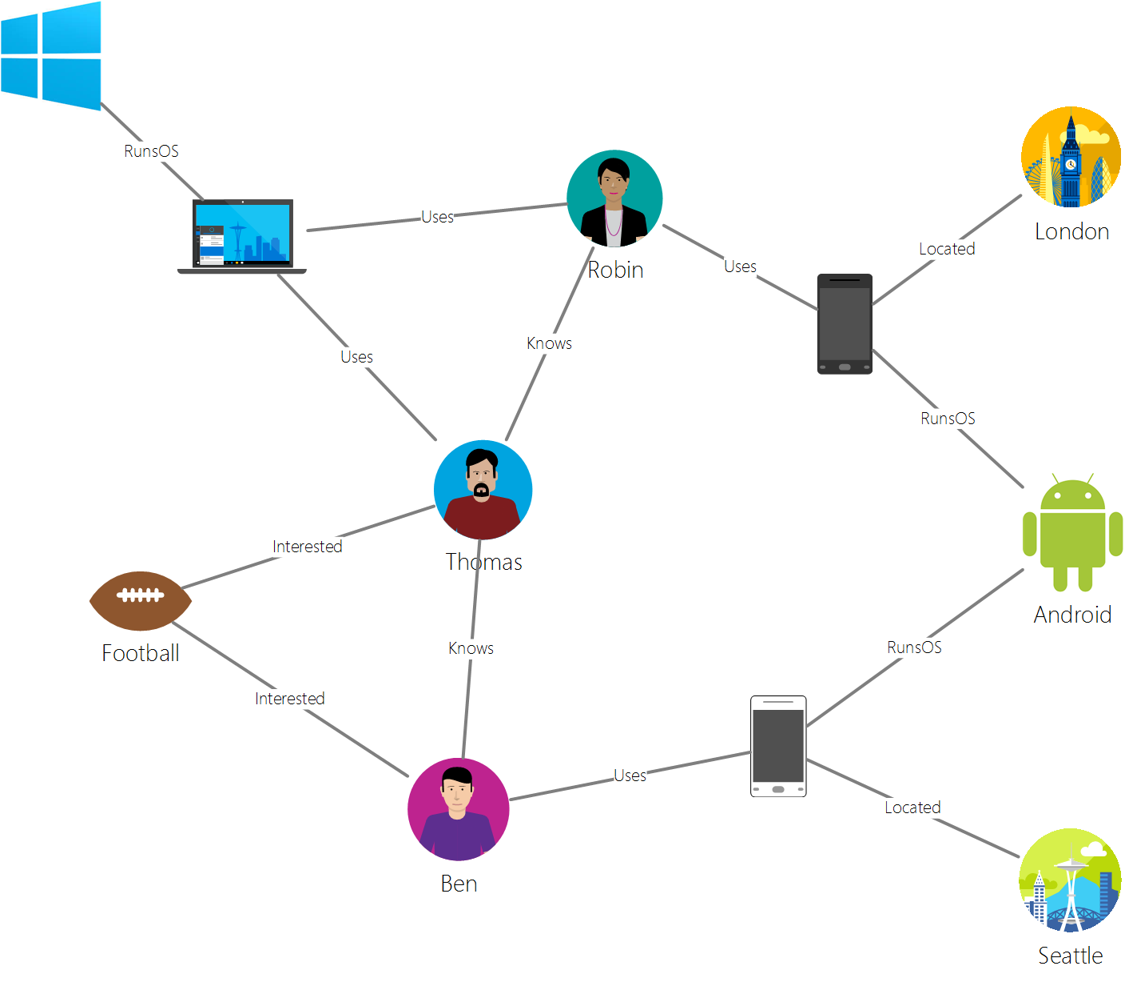
Zdroj z Microsoft
Graph databázy popisujú vzťahy v dátach a sú reprezentované ako kolekcia uzlov a hrán. Uzol predstavuje entitu, niečo, čo existuje v reálnom svete, ako napríklad študent alebo bankový výpis. Hrany predstavujú vzťah medzi dvoma entitami. Každý uzol a hrana majú vlastnosti, ktoré poskytujú dodatočné informácie o každom uzle a hrane.

Columnar úložiská dát organizujú dáta do stĺpcov a riadkov podobne ako relačná dátová štruktúra, ale každý stĺpec je rozdelený do skupín nazývaných rodina stĺpcov, kde všetky dáta pod jedným stĺpcom sú príbuzné a môžu byť získané a zmenené ako jedna jednotka.
Úložiská dokumentov s Azure Cosmos DB
Document úložiská dát stavajú na koncepte úložiska dát typu key-value a sú tvorené sériou polí a objektov. Táto sekcia preskúma databázy dokumentov s emulátorom Cosmos DB.
Databáza Cosmos DB spĺňa definíciu "Nielen SQL", kde dokumentová databáza Cosmos DB sa spolieha na SQL na dotazovanie dát. Predchádzajúca lekcia o SQL pokrýva základy jazyka a budeme schopní aplikovať niektoré z rovnakých dotazov na dokumentovú databázu tu. Budeme používať emulátor Cosmos DB, ktorý nám umožňuje vytvárať a skúmať dokumentovú databázu lokálne na počítači. Viac o emulátore si môžete prečítať tu.
Dokument je kolekcia polí a objektových hodnôt, kde polia popisujú, čo objektová hodnota predstavuje. Nižšie je príklad dokumentu.
{
"firstname": "Eva",
"age": 44,
"id": "8c74a315-aebf-4a16-bb38-2430a9896ce5",
"_rid": "bHwDAPQz8s0BAAAAAAAAAA==",
"_self": "dbs/bHwDAA==/colls/bHwDAPQz8s0=/docs/bHwDAPQz8s0BAAAAAAAAAA==/",
"_etag": "\"00000000-0000-0000-9f95-010a691e01d7\"",
"_attachments": "attachments/",
"_ts": 1630544034
}
Polia záujmu v tomto dokumente sú: firstname, id a age. Zvyšné polia s podčiarkovníkmi boli generované Cosmos DB.
Skúmanie dát s emulátorom Cosmos DB
Emulátor si môžete stiahnuť a nainštalovať pre Windows tu. Pozrite si túto dokumentáciu pre možnosti, ako spustiť emulátor na macOS a Linux.
Emulátor spustí okno prehliadača, kde pohľad Explorer umožňuje skúmať dokumenty.
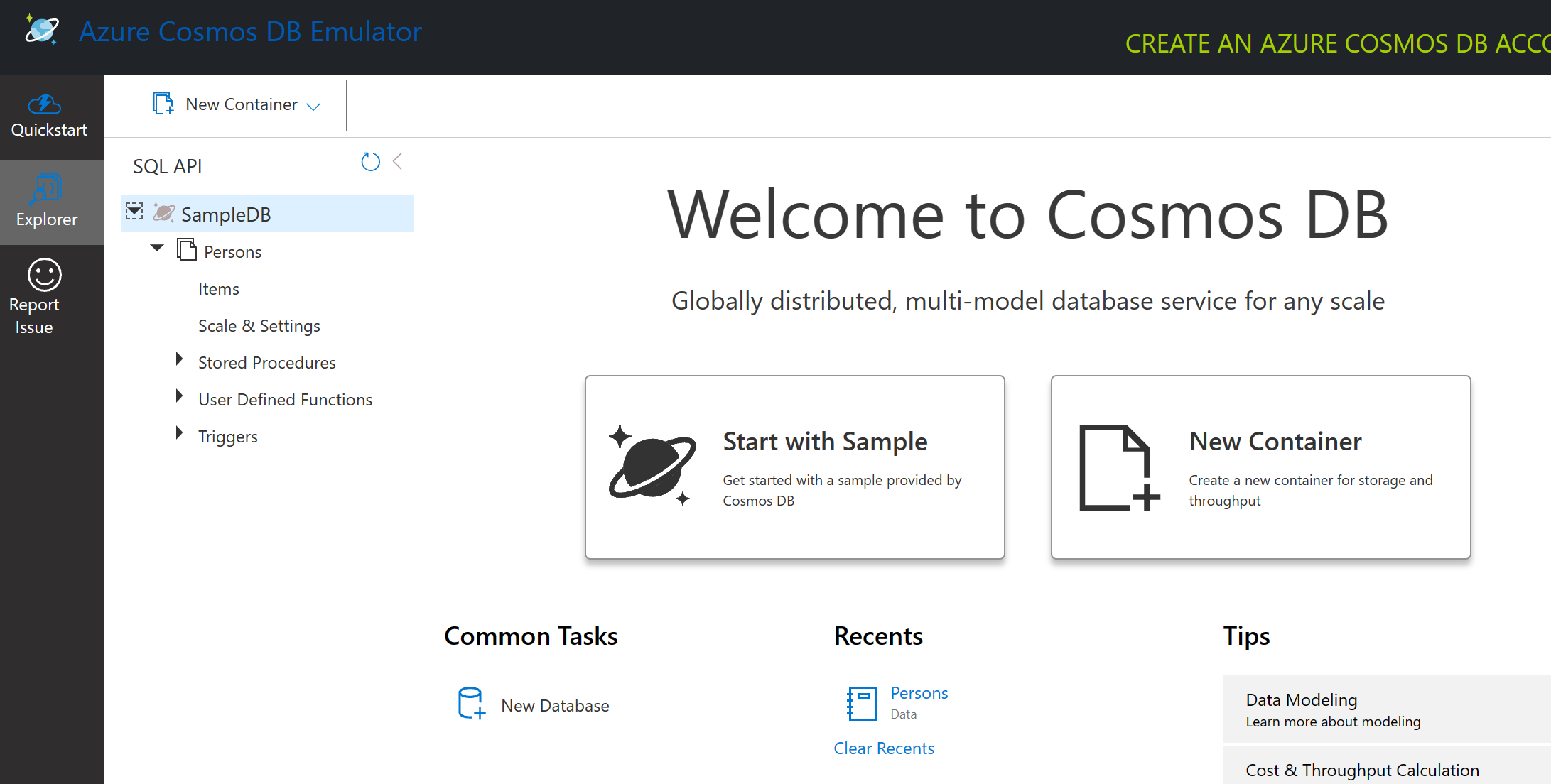
Ak postupujete podľa pokynov, kliknite na "Start with Sample" na generovanie vzorovej databázy s názvom SampleDB. Ak rozbalíte SampleDB kliknutím na šípku, nájdete kontajner s názvom Persons. Kontajner obsahuje kolekciu položiek, ktoré sú dokumentmi v kontajneri. Môžete preskúmať štyri jednotlivé dokumenty pod Items.
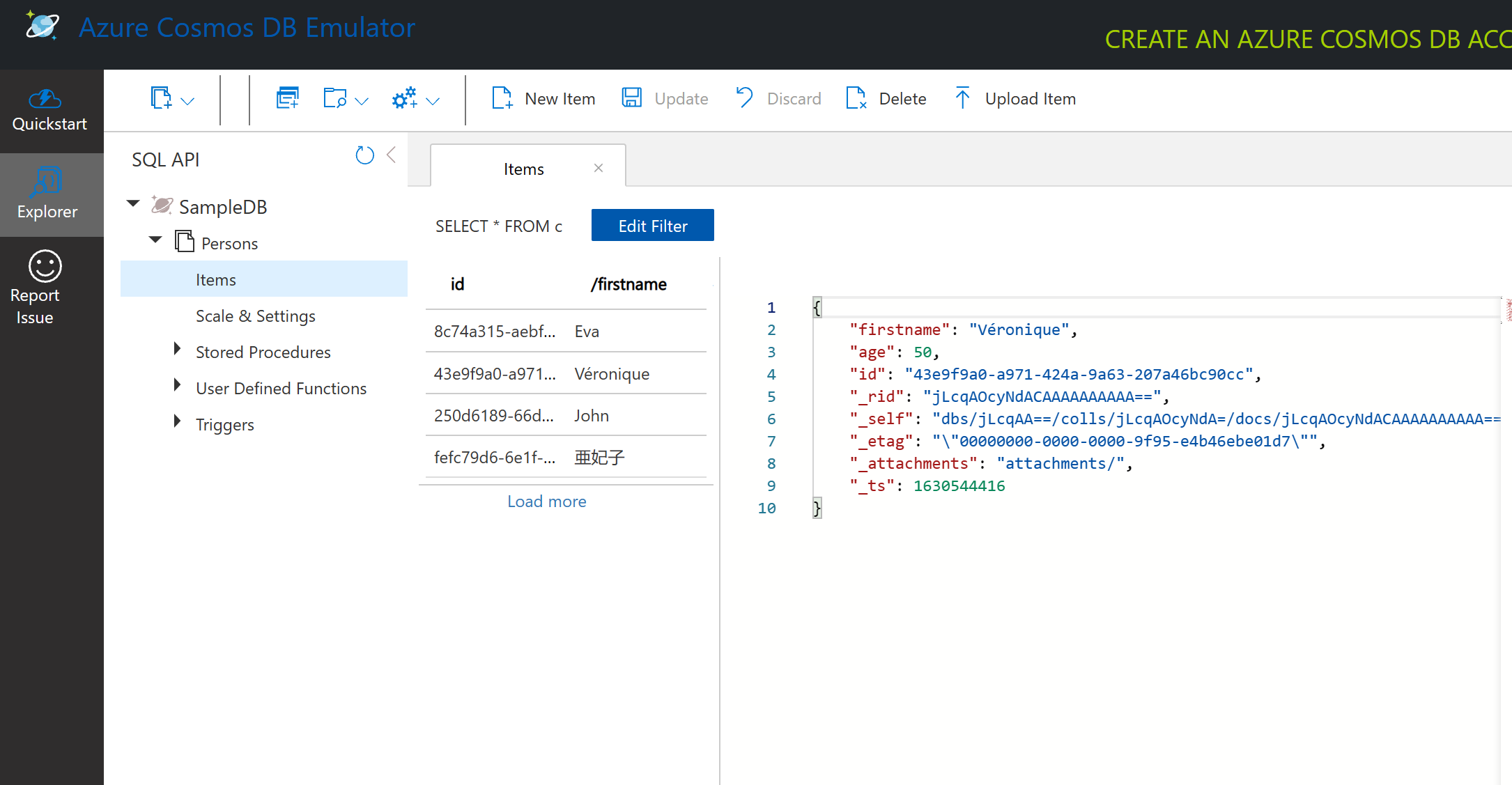
Dotazovanie dokumentových dát s emulátorom Cosmos DB
Môžeme tiež dotazovať vzorové dáta kliknutím na tlačidlo new SQL Query (druhé tlačidlo zľava).
SELECT * FROM c vráti všetky dokumenty v kontajneri. Pridajme klauzulu where a nájdime všetkých mladších ako 40 rokov.
SELECT * FROM c where c.age < 40
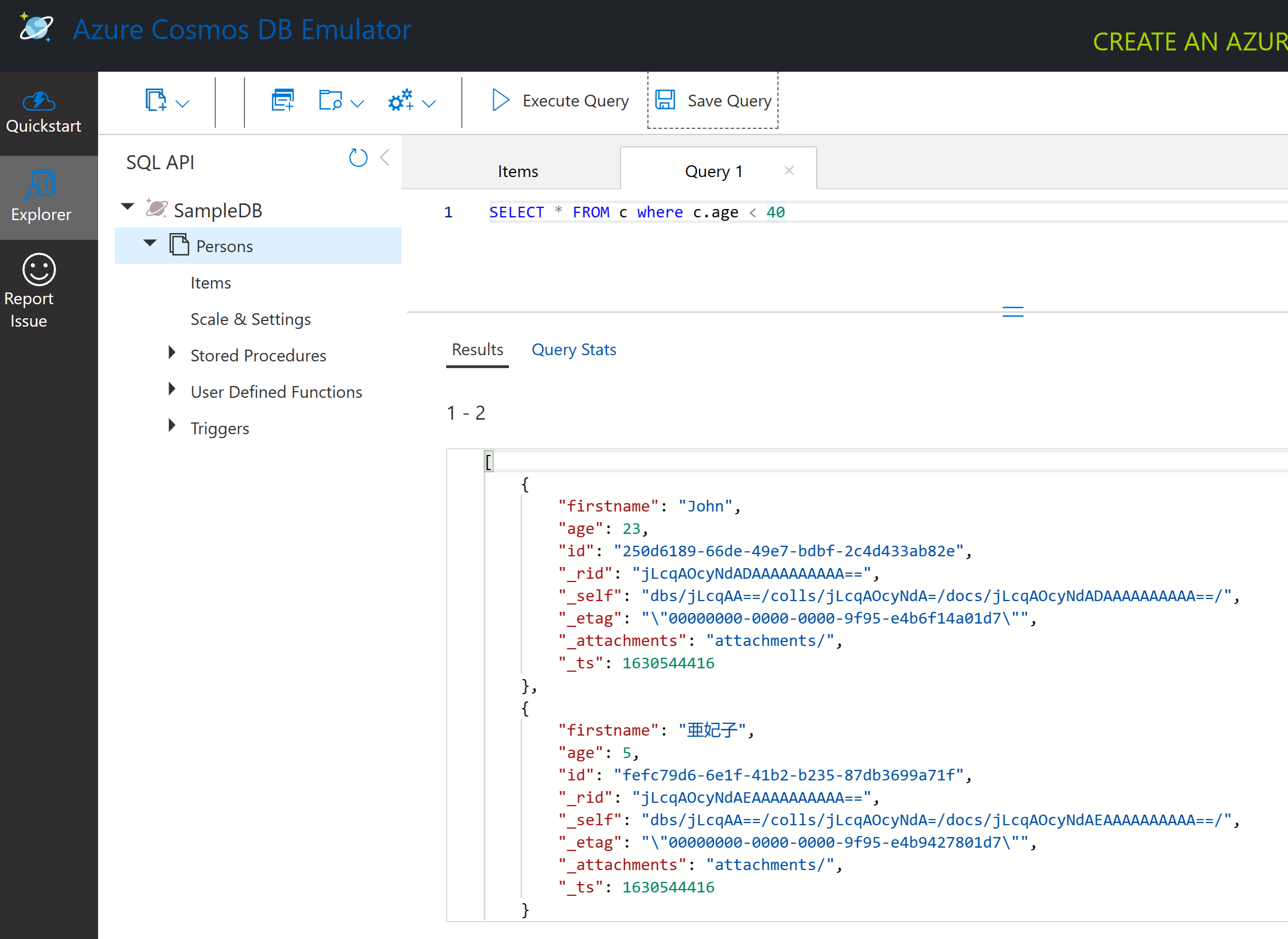
Dotaz vráti dva dokumenty, všimnite si, že hodnota age pre každý dokument je menšia ako 40.
JSON a dokumenty
Ak ste oboznámení s JavaScript Object Notation (JSON), všimnete si, že dokumenty vyzerajú podobne ako JSON. V tomto adresári sa nachádza súbor PersonsData.json s ďalšími dátami, ktoré môžete nahrať do kontajnera Persons v emulátore pomocou tlačidla Upload Item.
Vo väčšine prípadov môžu API, ktoré vracajú JSON dáta, byť priamo prenesené a uložené v dokumentových databázach. Nižšie je ďalší dokument, ktorý reprezentuje tweety z Twitter účtu Microsoft, získané pomocou Twitter API a následne vložené do Cosmos DB.
{
"created_at": "2021-08-31T19:03:01.000Z",
"id": "1432780985872142341",
"text": "Blank slate. Like this tweet if you’ve ever painted in Microsoft Paint before. https://t.co/cFeEs8eOPK",
"_rid": "dhAmAIUsA4oHAAAAAAAAAA==",
"_self": "dbs/dhAmAA==/colls/dhAmAIUsA4o=/docs/dhAmAIUsA4oHAAAAAAAAAA==/",
"_etag": "\"00000000-0000-0000-9f84-a0958ad901d7\"",
"_attachments": "attachments/",
"_ts": 1630537000
Polia záujmu v tomto dokumente sú: created_at, id a text.
🚀 Výzva
Existuje súbor TwitterData.json, ktorý môžete nahrať do databázy SampleDB. Odporúča sa, aby ste ho pridali do samostatného kontajnera. To môžete urobiť nasledovne:
- Kliknite na tlačidlo new container v pravom hornom rohu
- Vyberte existujúcu databázu (SampleDB), vytvorte id kontajnera pre kontajner
- Nastavte partition key na
/id - Kliknite na OK (ostatné informácie v tomto pohľade môžete ignorovať, pretože ide o malú dátovú sadu bežiacu lokálne na vašom počítači)
- Otvorte nový kontajner a nahrajte súbor Twitter Data pomocou tlačidla
Upload Item
Skúste spustiť niekoľko dotazov SELECT na nájdenie dokumentov, ktoré majú Microsoft v poli text. Tip: skúste použiť LIKE keyword
Kvíz po prednáške
Prehľad a samostatné štúdium
-
Existujú ďalšie formátovania a funkcie pridané do tohto tabuľkového procesora, ktoré táto lekcia nepokrýva. Microsoft má veľkú knižnicu dokumentácie a videí o Exceli, ak máte záujem dozvedieť sa viac.
-
Táto architektonická dokumentácia podrobne popisuje charakteristiky rôznych typov nerelačných dát: Nerelačné dáta a NoSQL
-
Cosmos DB je cloudová nerelačná databáza, ktorá môže tiež ukladať rôzne typy NoSQL spomenuté v tejto lekcii. Viac o týchto typoch sa dozviete v tomto Microsoft Learn Module o Cosmos DB
Zadanie
Upozornenie:
Tento dokument bol preložený pomocou služby AI prekladu Co-op Translator. Aj keď sa snažíme o presnosť, prosím, berte na vedomie, že automatizované preklady môžu obsahovať chyby alebo nepresnosti. Pôvodný dokument v jeho rodnom jazyku by mal byť považovaný za autoritatívny zdroj. Pre kritické informácie sa odporúča profesionálny ľudský preklad. Nenesieme zodpovednosť za akékoľvek nedorozumenia alebo nesprávne interpretácie vyplývajúce z použitia tohto prekladu.