|
|
6 months ago | |
|---|---|---|
| .. | ||
| README.md | 6 months ago | |
| assignment.md | 6 months ago | |
README.md
Știința Datelor în Cloud: Metoda "Low code/No code"
 |
|---|
| Știința Datelor în Cloud: Low Code - Sketchnote de @nitya |
Cuprins:
- Știința Datelor în Cloud: Metoda "Low code/No code"
Chestionar înainte de lecție
1. Introducere
1.1 Ce este Azure Machine Learning?
Platforma cloud Azure include peste 200 de produse și servicii cloud concepute pentru a te ajuta să aduci la viață soluții noi. Specialiștii în știința datelor depun mult efort pentru a explora și pre-procesa datele, încercând diverse tipuri de algoritmi de antrenare a modelelor pentru a produce modele precise. Aceste sarcini consumă mult timp și deseori utilizează ineficient hardware-ul de calcul costisitor.
Azure ML este o platformă bazată pe cloud pentru construirea și operarea soluțiilor de învățare automată în Azure. Aceasta include o gamă largă de funcționalități care ajută specialiștii în știința datelor să pregătească datele, să antreneze modele, să publice servicii predictive și să monitorizeze utilizarea acestora. Cel mai important, îi ajută să își crească eficiența prin automatizarea multor sarcini consumatoare de timp asociate cu antrenarea modelelor; și le permite să utilizeze resurse de calcul bazate pe cloud care se scalează eficient, pentru a gestiona volume mari de date, suportând costuri doar atunci când sunt utilizate efectiv.
Azure ML oferă toate instrumentele de care au nevoie dezvoltatorii și specialiștii în știința datelor pentru fluxurile lor de lucru de învățare automată. Acestea includ:
- Azure Machine Learning Studio: un portal web în Azure Machine Learning pentru opțiuni low-code și no-code pentru antrenarea, implementarea, automatizarea, urmărirea și gestionarea activelor modelelor. Studio-ul se integrează cu SDK-ul Azure Machine Learning pentru o experiență fluidă.
- Jupyter Notebooks: prototipare rapidă și testare a modelelor ML.
- Azure Machine Learning Designer: permite construirea de experimente prin drag-and-drop și apoi implementarea de pipeline-uri într-un mediu low-code.
- Interfața AutoML: automatizează sarcinile iterative de dezvoltare a modelelor ML, permițând construirea de modele ML la scară mare, cu eficiență și productivitate, menținând în același timp calitatea modelului.
- Etichetarea datelor: un instrument ML asistat pentru etichetarea automată a datelor.
- Extensia de învățare automată pentru Visual Studio Code: oferă un mediu de dezvoltare complet pentru construirea și gestionarea proiectelor ML.
- CLI pentru învățare automată: oferă comenzi pentru gestionarea resurselor Azure ML din linia de comandă.
- Integrare cu framework-uri open-source precum PyTorch, TensorFlow, Scikit-learn și multe altele pentru antrenarea, implementarea și gestionarea procesului complet de învățare automată.
- MLflow: o bibliotecă open-source pentru gestionarea ciclului de viață al experimentelor de învățare automată. MLFlow Tracking este o componentă a MLflow care înregistrează și urmărește metricele de antrenare și artefactele modelului, indiferent de mediul experimentului.
1.2 Proiectul de Predicție a Insuficienței Cardiace:
Nu există nicio îndoială că realizarea și construirea de proiecte este cea mai bună modalitate de a-ți testa abilitățile și cunoștințele. În această lecție, vom explora două moduri diferite de a construi un proiect de știința datelor pentru predicția atacurilor de insuficiență cardiacă în Azure ML Studio, prin metodele Low code/No code și prin SDK-ul Azure ML, așa cum este ilustrat în schema următoare:
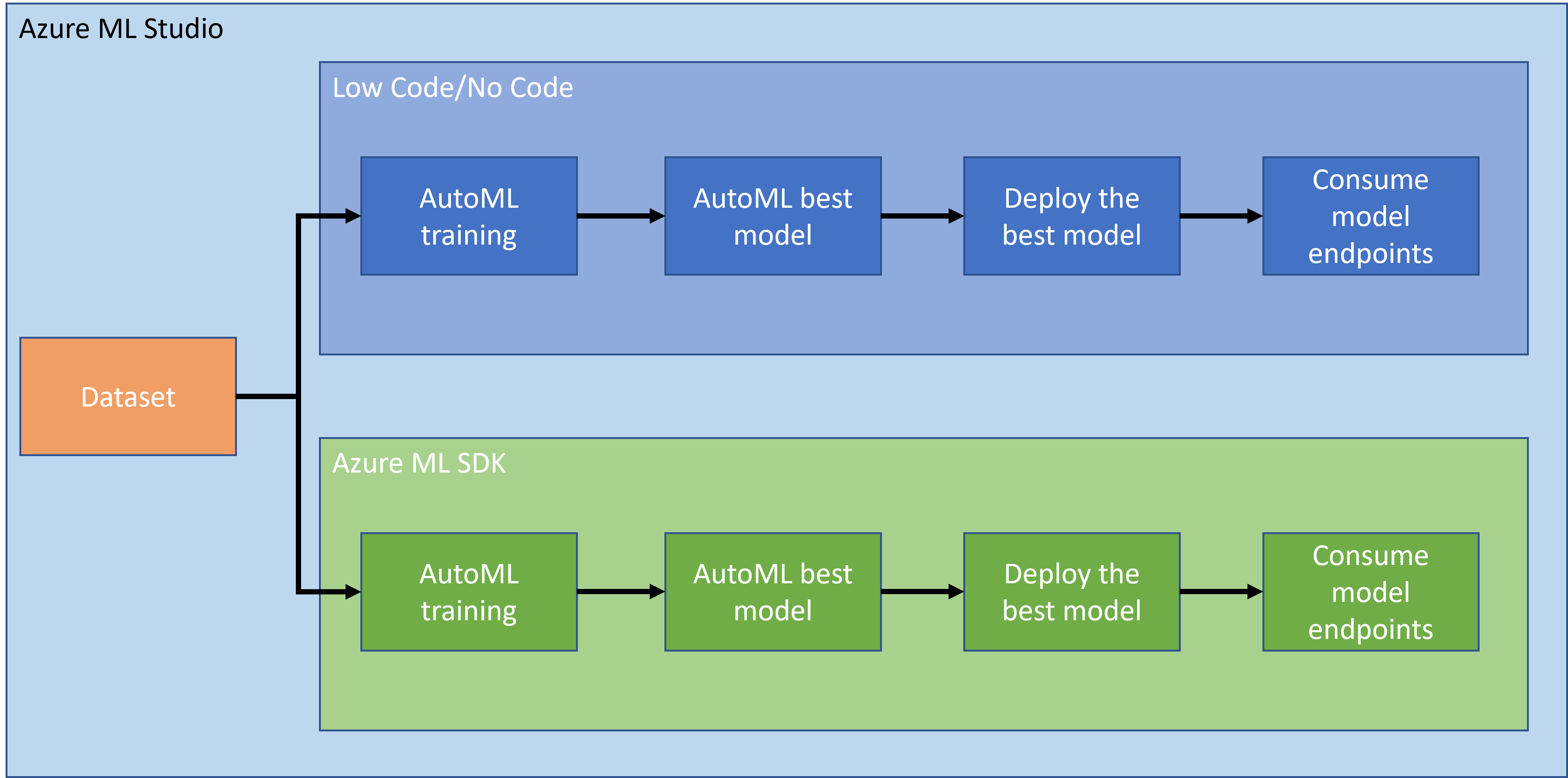
Fiecare metodă are propriile avantaje și dezavantaje. Metoda Low code/No code este mai ușor de început, deoarece implică interacțiunea cu o interfață grafică (GUI), fără a fi necesare cunoștințe anterioare de cod. Această metodă permite testarea rapidă a viabilității proiectului și crearea unui POC (Proof Of Concept). Totuși, pe măsură ce proiectul crește și trebuie să fie pregătit pentru producție, nu este fezabil să creezi resurse prin GUI. Este necesar să automatizezi programatic totul, de la crearea resurselor până la implementarea unui model. Aici devine esențială cunoașterea utilizării SDK-ului Azure ML.
| Low code/No code | SDK Azure ML | |
|---|---|---|
| Expertiză în cod | Nu este necesară | Este necesară |
| Timp de dezvoltare | Rapid și ușor | Depinde de expertiza în cod |
| Pregătit pentru producție | Nu | Da |
1.3 Setul de Date pentru Insuficiența Cardiacă:
Bolile cardiovasculare (CVD) sunt cauza numărul 1 de deces la nivel global, reprezentând 31% din toate decesele la nivel mondial. Factori de risc de mediu și comportamentali, precum utilizarea tutunului, dieta nesănătoasă și obezitatea, inactivitatea fizică și consumul nociv de alcool, ar putea fi utilizați ca caracteristici pentru modelele de estimare. Posibilitatea de a estima probabilitatea dezvoltării unei CVD ar putea fi de mare ajutor pentru prevenirea atacurilor la persoanele cu risc ridicat.
Kaggle a pus la dispoziție un set de date pentru insuficiența cardiacă, pe care îl vom folosi pentru acest proiect. Poți descărca setul de date acum. Acesta este un set de date tabular cu 13 coloane (12 caracteristici și 1 variabilă țintă) și 299 rânduri.
| Nume variabilă | Tip | Descriere | Exemplu | |
|---|---|---|---|---|
| 1 | age | numeric | vârsta pacientului | 25 |
| 2 | anaemia | boolean | Scăderea celulelor roșii sau a hemoglobinei | 0 sau 1 |
| 3 | creatinine_phosphokinase | numeric | Nivelul enzimei CPK în sânge | 542 |
| 4 | diabetes | boolean | Dacă pacientul are diabet | 0 sau 1 |
| 5 | ejection_fraction | numeric | Procentul de sânge care părăsește inima la fiecare contracție | 45 |
| 6 | high_blood_pressure | boolean | Dacă pacientul are hipertensiune | 0 sau 1 |
| 7 | platelets | numeric | Trombocite în sânge | 149000 |
| 8 | serum_creatinine | numeric | Nivelul creatininei serice în sânge | 0.5 |
| 9 | serum_sodium | numeric | Nivelul sodiului seric în sânge | jun |
| 10 | sex | boolean | femeie sau bărbat | 0 sau 1 |
| 11 | smoking | boolean | Dacă pacientul fumează | 0 sau 1 |
| 12 | time | numeric | perioada de urmărire (zile) | 4 |
| ---- | --------------------------- | ------------------ | --------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [Țintă] | boolean | dacă pacientul moare în perioada de urmărire | 0 sau 1 |
După ce ai setul de date, putem începe proiectul în Azure.
2. Antrenarea unui model în Azure ML Studio folosind Low code/No code
2.1 Crearea unui spațiu de lucru Azure ML
Pentru a antrena un model în Azure ML, trebuie mai întâi să creezi un spațiu de lucru Azure ML. Spațiul de lucru este resursa de nivel superior pentru Azure Machine Learning, oferind un loc centralizat pentru a lucra cu toate artefactele pe care le creezi atunci când utilizezi Azure Machine Learning. Spațiul de lucru păstrează un istoric al tuturor rulărilor de antrenare, inclusiv jurnale, metrici, rezultate și o captură a scripturilor tale. Folosești aceste informații pentru a determina care rulare de antrenare produce cel mai bun model. Află mai multe
Se recomandă utilizarea celui mai actualizat browser compatibil cu sistemul tău de operare. Browserele suportate sunt:
- Microsoft Edge (Noua versiune Microsoft Edge, nu versiunea legacy)
- Safari (cea mai recentă versiune, doar pe Mac)
- Chrome (cea mai recentă versiune)
- Firefox (cea mai recentă versiune)
Pentru a utiliza Azure Machine Learning, creează un spațiu de lucru în abonamentul tău Azure. Poți folosi acest spațiu de lucru pentru a gestiona date, resurse de calcul, cod, modele și alte artefacte legate de sarcinile tale de învățare automată.
NOTĂ: Abonamentul tău Azure va fi taxat cu o sumă mică pentru stocarea datelor atât timp cât spațiul de lucru Azure Machine Learning există în abonamentul tău, așa că îți recomandăm să ștergi spațiul de lucru Azure Machine Learning atunci când nu îl mai folosești.
-
Autentifică-te în portalul Azure folosind acreditările Microsoft asociate cu abonamentul tău Azure.
-
Selectează +Creare resursă
Caută Machine Learning și selectează placa Machine Learning
Apasă butonul de creare
Completează setările astfel:
- Abonament: Abonamentul tău Azure
- Grup de resurse: Creează sau selectează un grup de resurse
- Nume spațiu de lucru: Introdu un nume unic pentru spațiul tău de lucru
- Regiune: Selectează regiunea geografică cea mai apropiată de tine
- Cont de stocare: Notează contul de stocare nou implicit care va fi creat pentru spațiul tău de lucru
- Key vault: Notează noul key vault implicit care va fi creat pentru spațiul tău de lucru
- Application insights: Notează noua resursă application insights implicită care va fi creată pentru spațiul tău de lucru
- Container registry: Niciunul (unul va fi creat automat prima dată când implementezi un model într-un container)
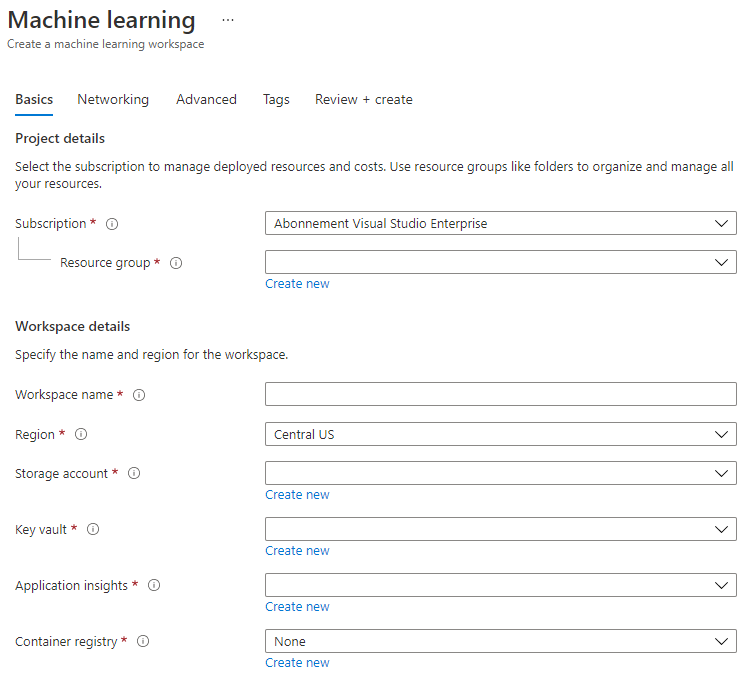
- Apasă pe butonul de creare + revizuire și apoi pe butonul de creare
-
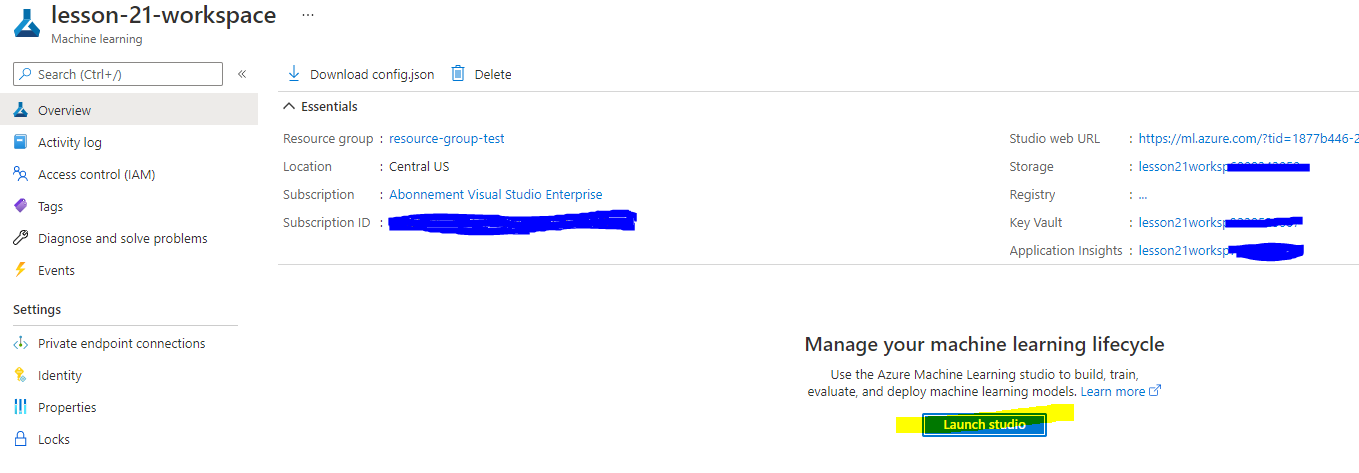
Așteaptă ca spațiul tău de lucru să fie creat (acest lucru poate dura câteva minute). Apoi accesează-l în portal. Îl poți găsi prin serviciul Azure Machine Learning.
-
Pe pagina de prezentare generală a spațiului tău de lucru, lansează Azure Machine Learning studio (sau deschide un nou tab în browser și navighează la https://ml.azure.com), și autentifică-te în Azure Machine Learning studio folosind contul tău Microsoft. Dacă ți se cere, selectează directorul și abonamentul Azure, precum și spațiul tău de lucru Azure Machine Learning.
- În Azure Machine Learning studio, comută pictograma ☰ din partea stângă sus pentru a vizualiza diferitele pagini din interfață. Poți folosi aceste pagini pentru a gestiona resursele din spațiul tău de lucru.
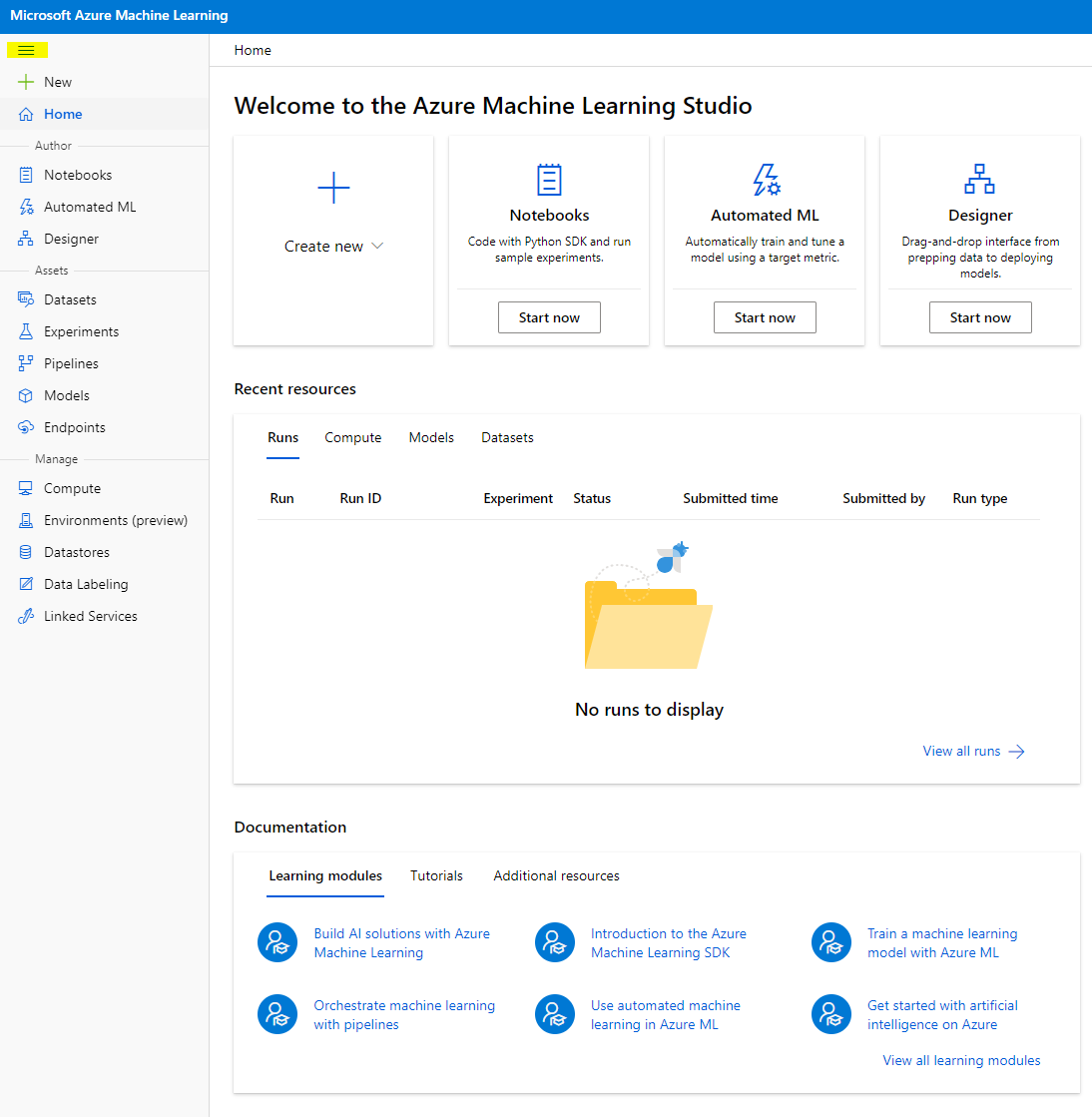
Poți gestiona spațiul tău de lucru folosind portalul Azure, dar pentru specialiștii în știința datelor și inginerii de operațiuni ML, Azure Machine Learning Studio oferă o interfață de utilizator mai concentrată pentru gestionarea resurselor spațiului de lucru.
2.2 Resurse de calcul
Resursele de calcul sunt resurse bazate pe cloud pe care le poți utiliza pentru a rula procese de antrenare a modelelor și explorare a datelor. Există patru tipuri de resurse de calcul pe care le poți crea:
- Compute Instances: Stații de lucru pentru dezvoltare pe care specialiștii în știința datelor le pot folosi pentru a lucra cu date și modele. Aceasta implică crearea unei mașini virtuale (VM) și lansarea unei instanțe de notebook. Poți apoi antrena un model apelând un cluster de calcul din notebook.
- Compute Clusters: Clustere scalabile de VM-uri pentru procesarea la cerere a codului experimentului. Vei avea nevoie de acestea pentru antrenarea unui model. Clusterele de calcul pot folosi, de asemenea, resurse GPU sau CPU specializate.
- Inference Clusters: Ținte de implementare pentru servicii predictive care utilizează modelele tale antrenate.
- Attached Compute: Legături către resurse de calcul Azure existente, cum ar fi mașini virtuale sau clustere Azure Databricks.
2.2.1 Alegerea opțiunilor potrivite pentru resursele de calcul
Există câțiva factori cheie de luat în considerare atunci când creați o resursă de calcul, iar aceste alegeri pot fi decizii critice.
Aveți nevoie de CPU sau GPU?
Un CPU (Unitate Centrală de Procesare) este circuitul electronic care execută instrucțiunile unui program de calculator. Un GPU (Unitate de Procesare Grafică) este un circuit electronic specializat care poate executa cod legat de grafică la o rată foarte mare.
Principala diferență între arhitectura CPU și GPU este că un CPU este proiectat să gestioneze rapid o gamă largă de sarcini (măsurată prin viteza ceasului CPU), dar este limitat în ceea ce privește concurența sarcinilor care pot fi executate simultan. GPU-urile sunt proiectate pentru calcul paralel și, prin urmare, sunt mult mai bune pentru sarcinile de învățare profundă.
| CPU | GPU |
|---|---|
| Mai puțin costisitor | Mai costisitor |
| Nivel mai scăzut de concurență | Nivel mai ridicat de concurență |
| Mai lent în antrenarea modelelor de învățare profundă | Optim pentru învățare profundă |
Dimensiunea clusterului
Clusterele mai mari sunt mai costisitoare, dar vor oferi o mai bună receptivitate. Prin urmare, dacă aveți timp, dar nu suficienți bani, ar trebui să începeți cu un cluster mic. În schimb, dacă aveți bani, dar nu prea mult timp, ar trebui să începeți cu un cluster mai mare.
Dimensiunea VM
În funcție de constrângerile de timp și buget, puteți varia dimensiunea RAM-ului, discului, numărul de nuclee și viteza ceasului. Creșterea tuturor acestor parametri va fi mai costisitoare, dar va duce la o performanță mai bună.
Instanțe dedicate sau cu prioritate scăzută?
O instanță cu prioritate scăzută înseamnă că este întreruptibilă: practic, Microsoft Azure poate prelua aceste resurse și le poate atribui unei alte sarcini, întrerupând astfel un job. O instanță dedicată, sau neîntreruptibilă, înseamnă că jobul nu va fi niciodată terminat fără permisiunea dvs. Aceasta este o altă considerație între timp și bani, deoarece instanțele întreruptibile sunt mai puțin costisitoare decât cele dedicate.
2.2.2 Crearea unui cluster de calcul
În workspace-ul Azure ML pe care l-am creat anterior, accesați secțiunea de calcul și veți putea vedea diferitele resurse de calcul pe care tocmai le-am discutat (adică instanțe de calcul, clustere de calcul, clustere de inferență și calcul atașat). Pentru acest proiect, vom avea nevoie de un cluster de calcul pentru antrenarea modelului. În Studio, faceți clic pe meniul "Compute", apoi pe fila "Compute cluster" și faceți clic pe butonul "+ New" pentru a crea un cluster de calcul.
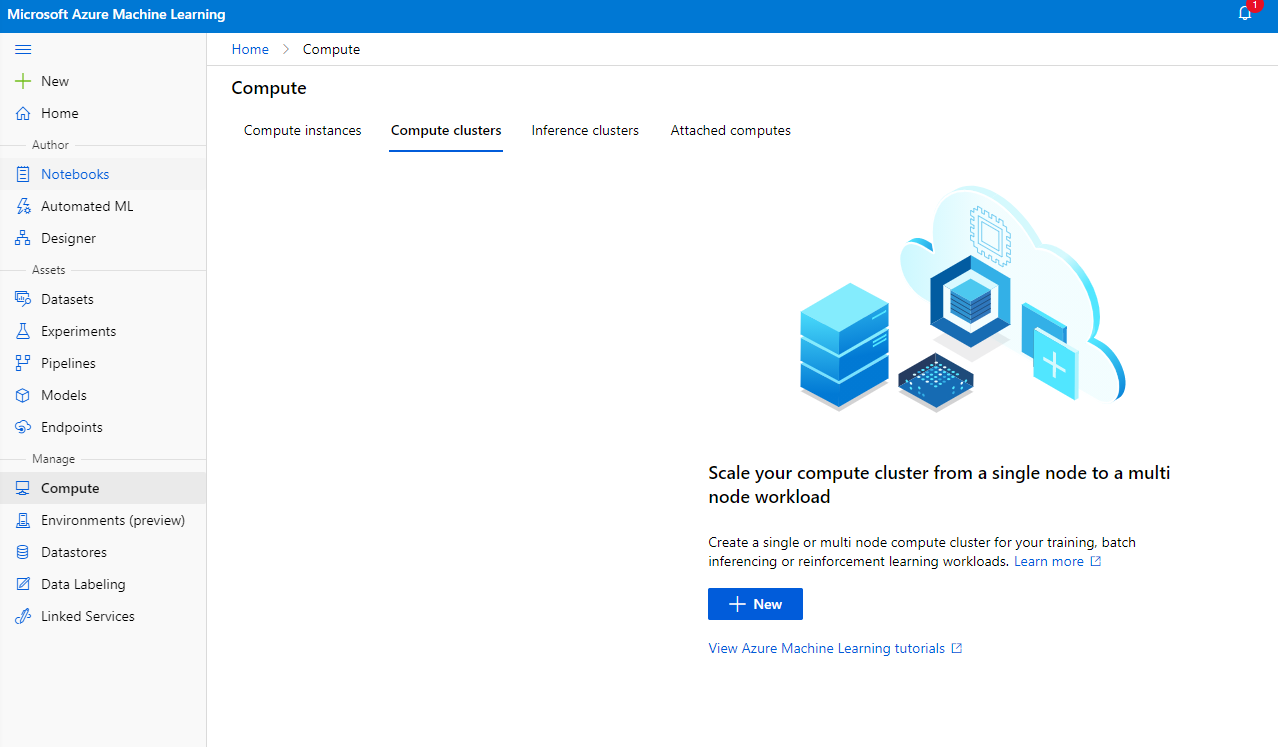
- Alegeți opțiunile: Dedicated vs Low priority, CPU sau GPU, dimensiunea VM și numărul de nuclee (puteți păstra setările implicite pentru acest proiect).
- Faceți clic pe butonul Next.
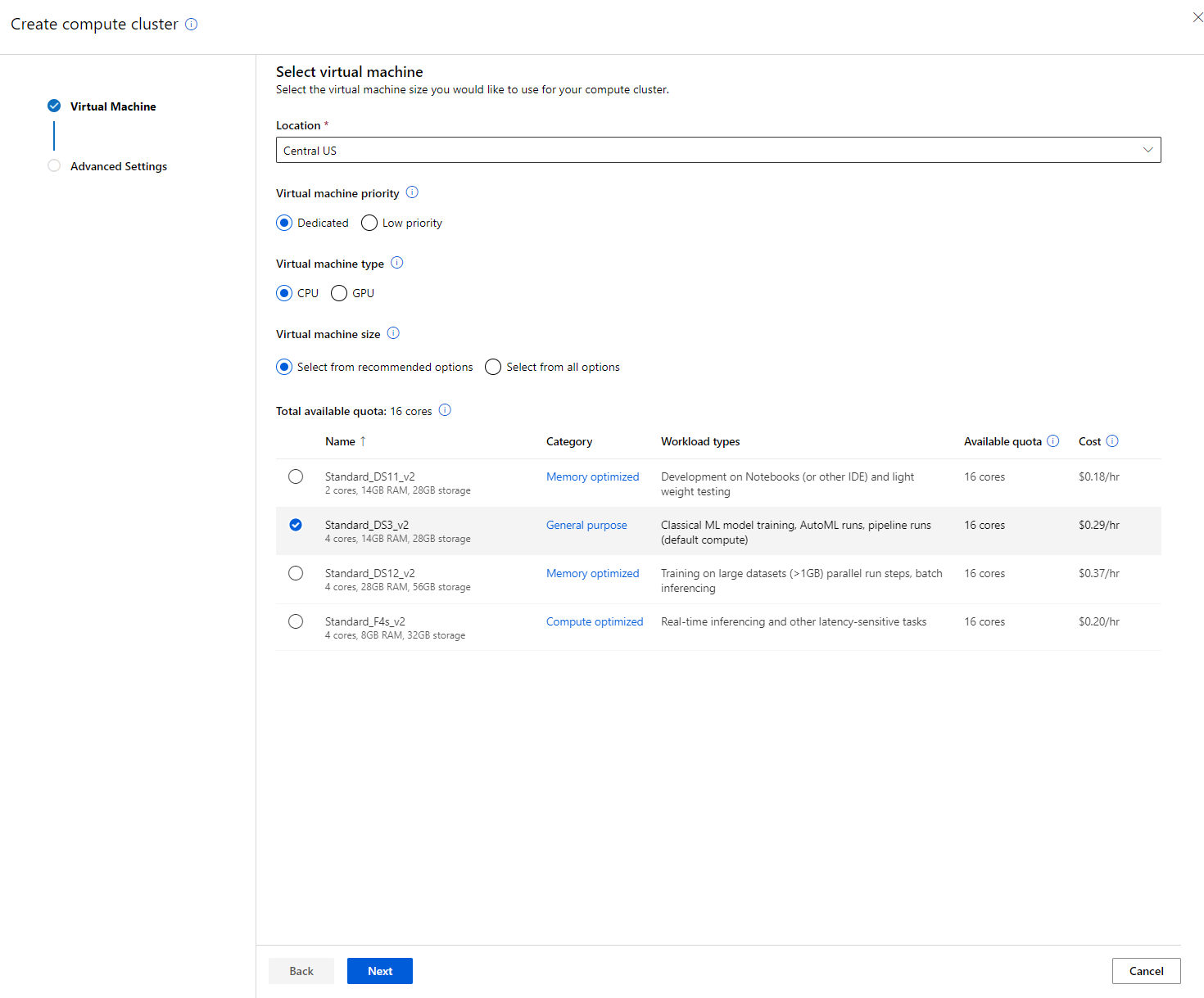
- Dați clusterului un nume de calcul.
- Alegeți opțiunile: Numărul minim/maxim de noduri, secunde de inactivitate înainte de reducere, acces SSH. Rețineți că, dacă numărul minim de noduri este 0, veți economisi bani atunci când clusterul este inactiv. Rețineți că, cu cât numărul maxim de noduri este mai mare, cu atât antrenamentul va fi mai scurt. Numărul maxim de noduri recomandat este 3.
- Faceți clic pe butonul "Create". Acest pas poate dura câteva minute.
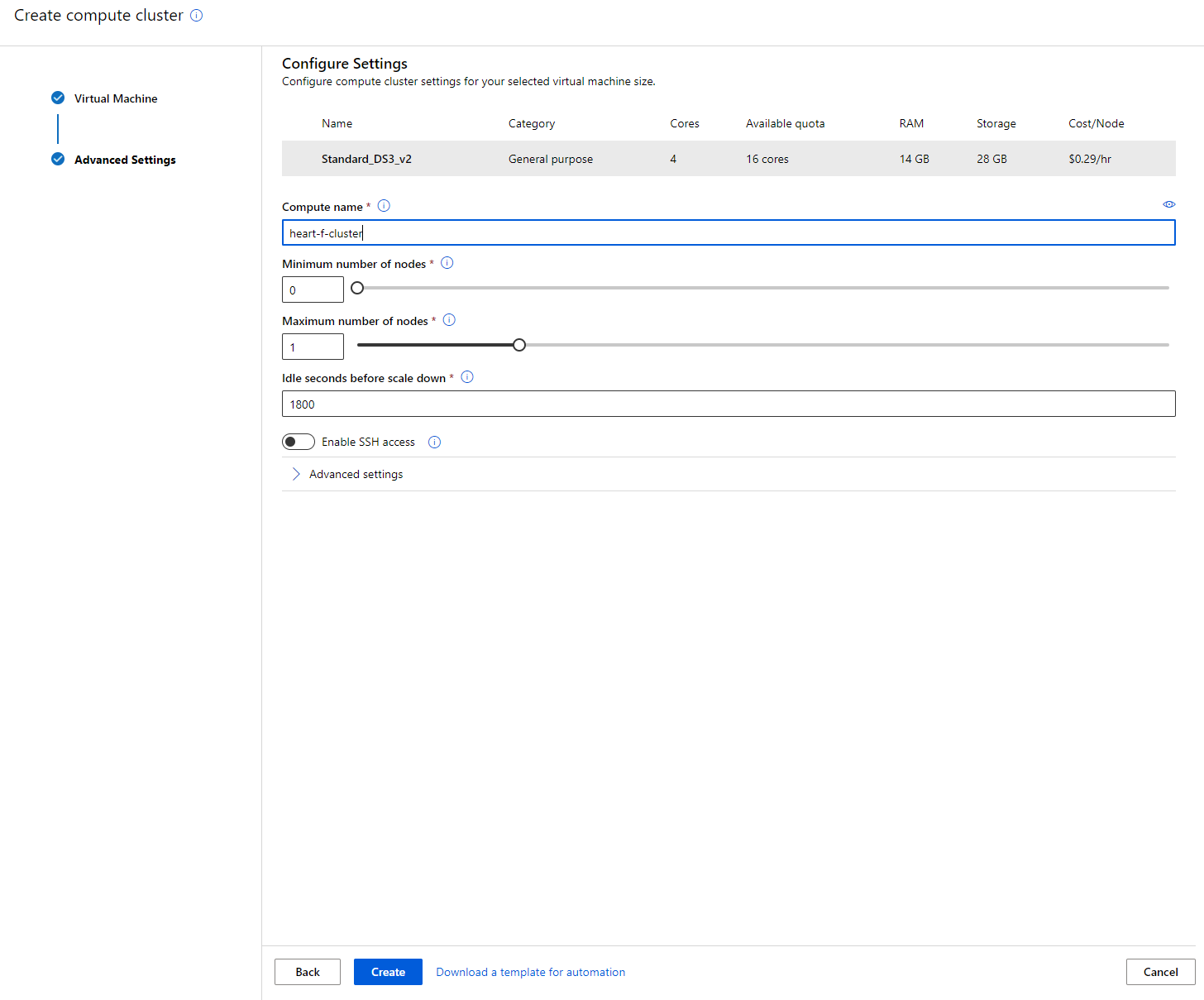
Super! Acum că avem un cluster de calcul, trebuie să încărcăm datele în Azure ML Studio.
2.3 Încărcarea setului de date
-
În workspace-ul Azure ML pe care l-am creat anterior, faceți clic pe "Datasets" în meniul din stânga și faceți clic pe butonul "+ Create dataset" pentru a crea un set de date. Alegeți opțiunea "From local files" și selectați setul de date Kaggle pe care l-am descărcat anterior.
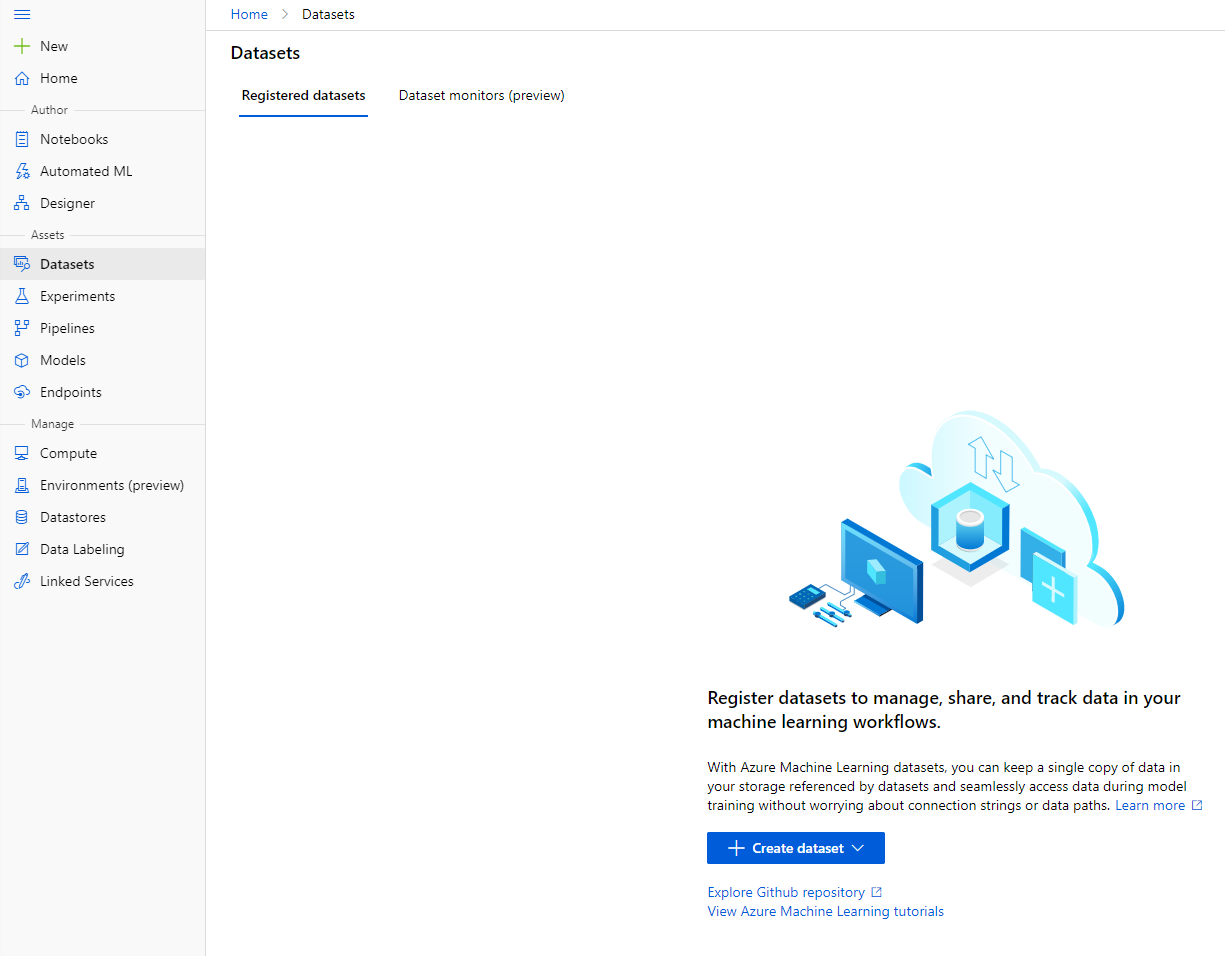
-
Dați setului de date un nume, un tip și o descriere. Faceți clic pe Next. Încărcați datele din fișiere. Faceți clic pe Next.
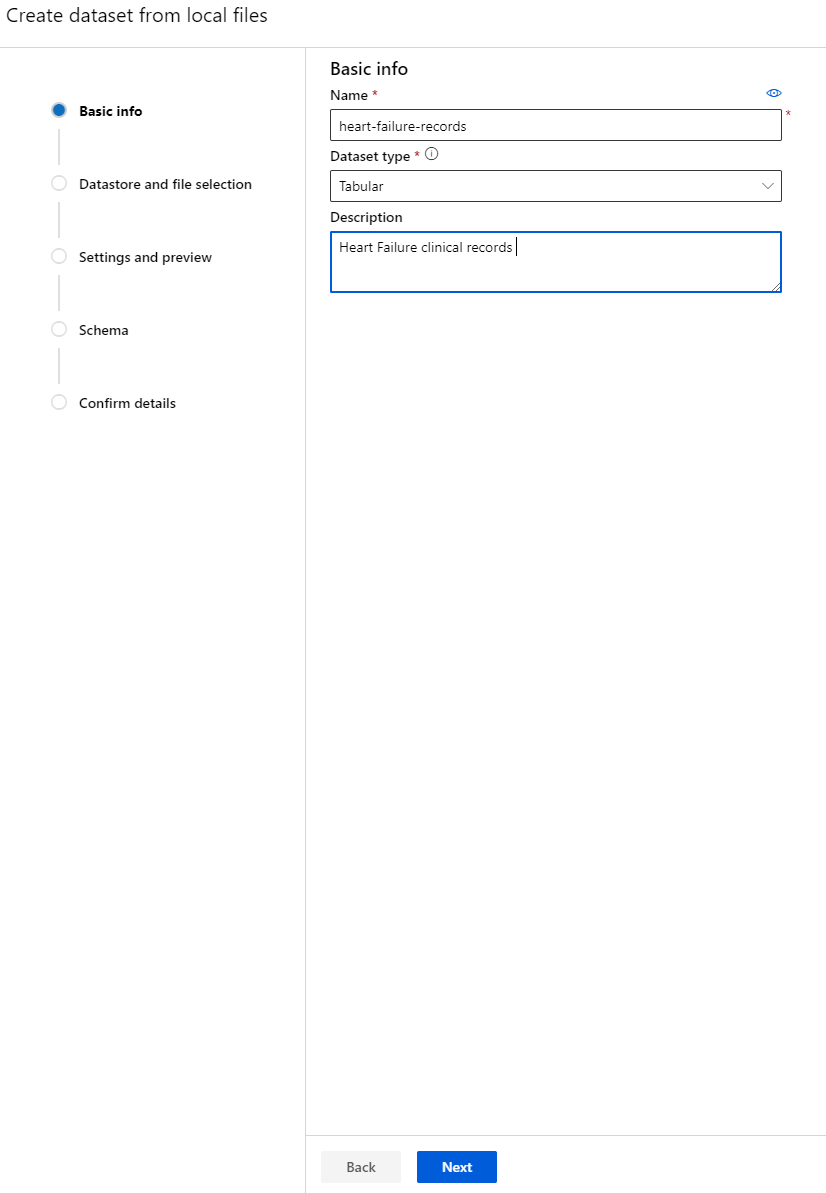
-
În Schema, schimbați tipul de date în Boolean pentru următoarele caracteristici: anaemia, diabetes, high blood pressure, sex, smoking și DEATH_EVENT. Faceți clic pe Next și apoi pe Create.
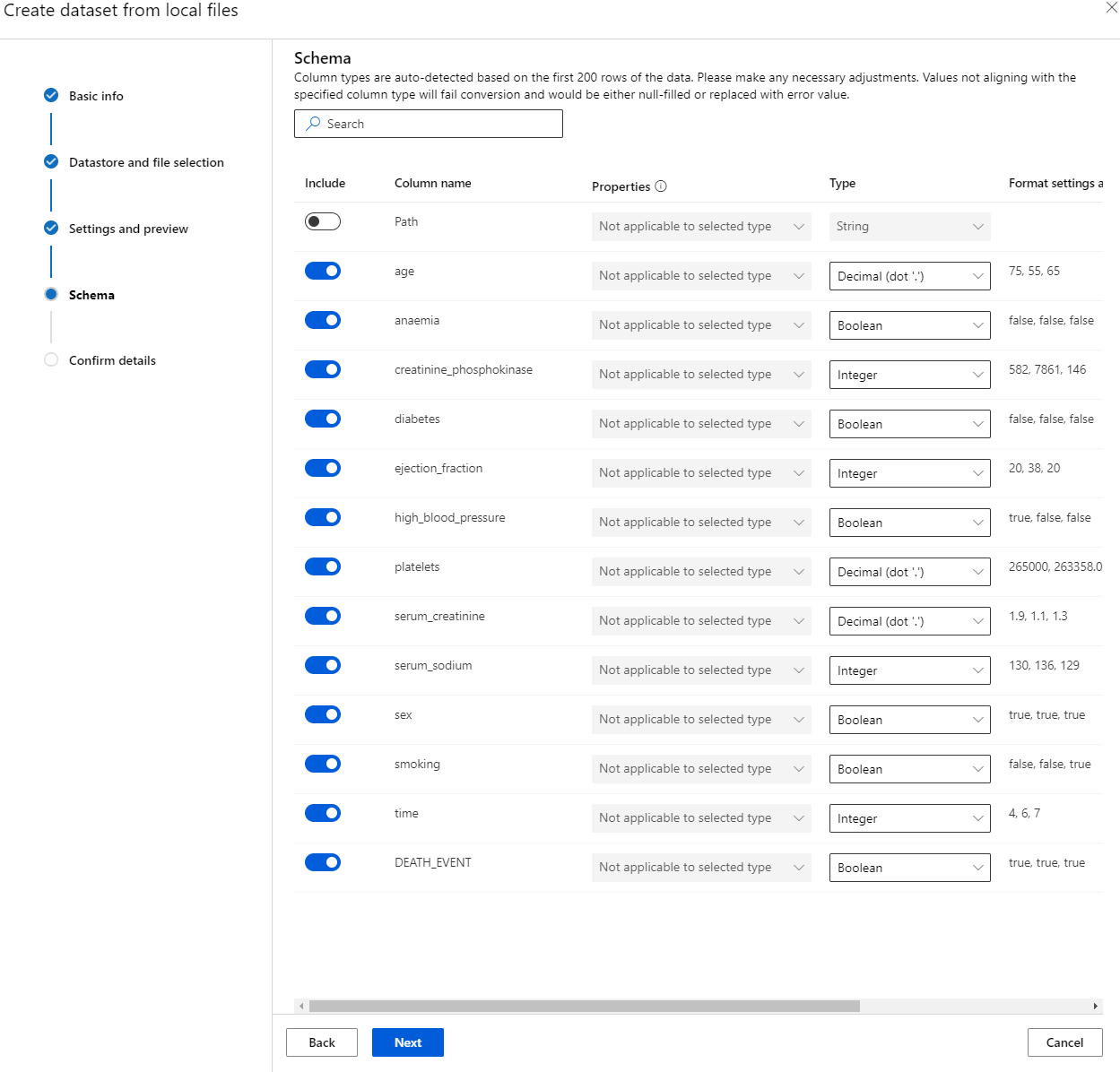
Grozaav! Acum că setul de date este în locul potrivit și clusterul de calcul este creat, putem începe antrenarea modelului!
2.4 Antrenare cu cod redus/fără cod folosind AutoML
Dezvoltarea tradițională a modelelor de învățare automată consumă multe resurse, necesită cunoștințe semnificative de domeniu și timp pentru a produce și compara zeci de modele. Învățarea automată automată (AutoML) este procesul de automatizare a sarcinilor iterative și consumatoare de timp din dezvoltarea modelelor de învățare automată. Permite oamenilor de știință, analiștilor și dezvoltatorilor să construiască modele ML la scară mare, cu eficiență și productivitate, menținând în același timp calitatea modelului. Reduce timpul necesar pentru a obține modele ML gata de producție, cu ușurință și eficiență. Aflați mai multe
-
În workspace-ul Azure ML pe care l-am creat anterior, faceți clic pe "Automated ML" în meniul din stânga și selectați setul de date pe care tocmai l-ați încărcat. Faceți clic pe Next.
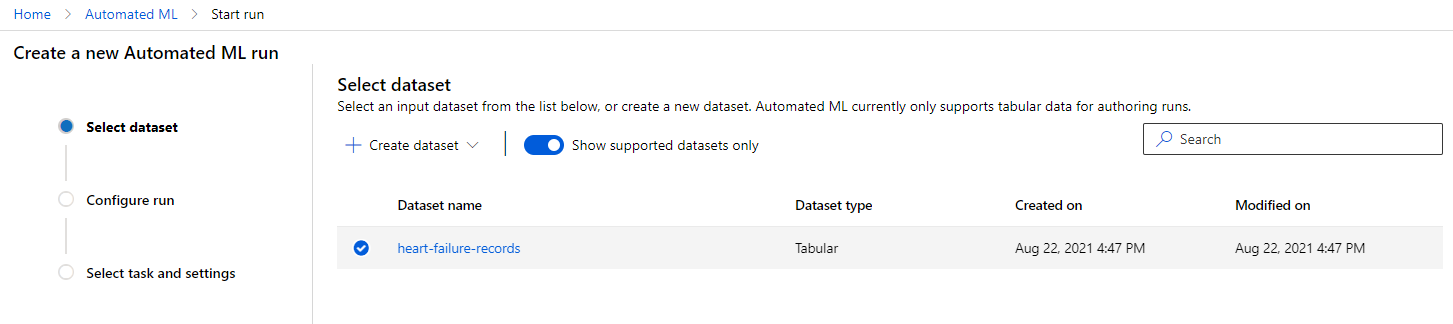
-
Introduceți un nume nou pentru experiment, coloana țintă (DEATH_EVENT) și clusterul de calcul pe care l-am creat. Faceți clic pe Next.
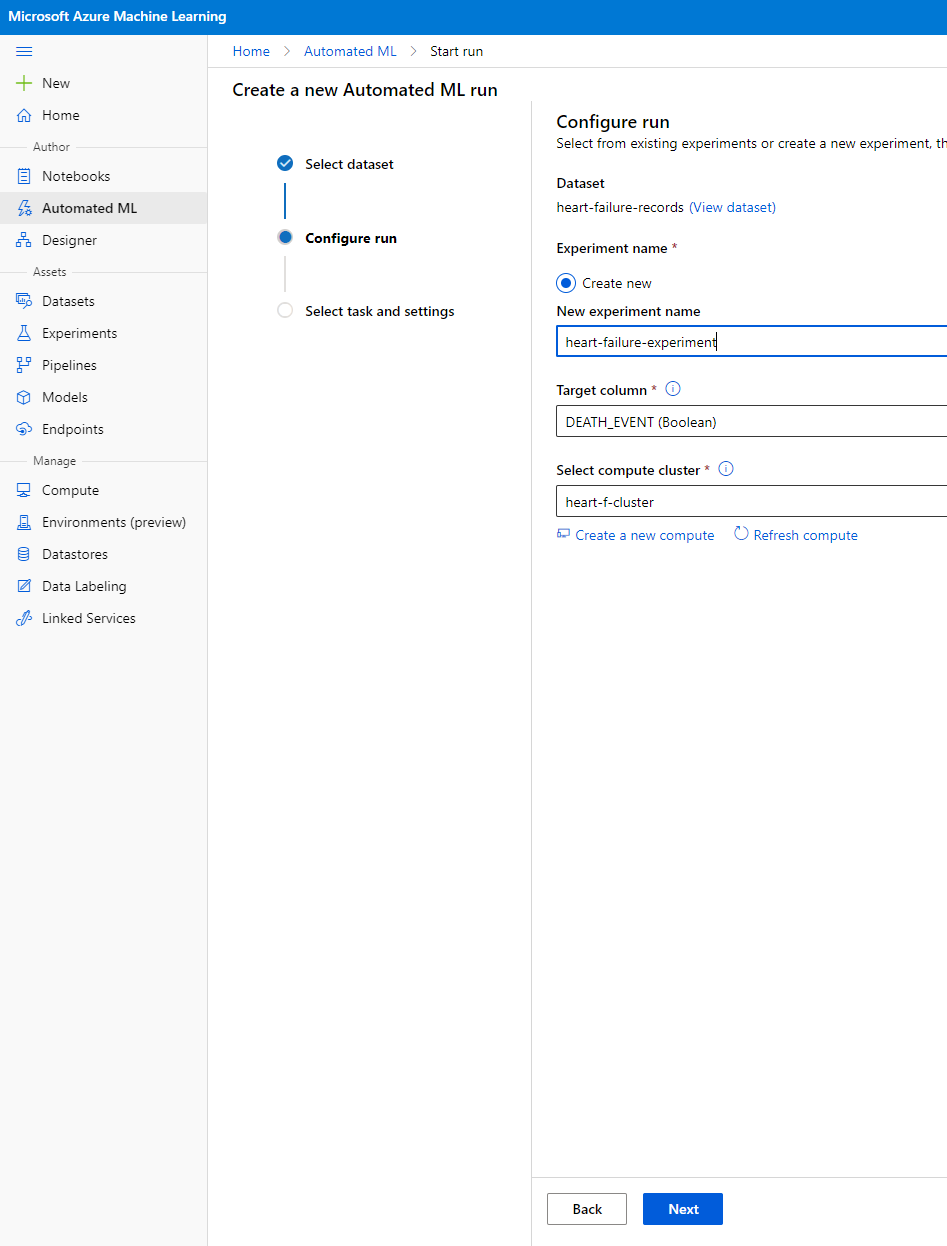
-
Alegeți "Classification" și faceți clic pe Finish. Acest pas poate dura între 30 de minute și 1 oră, în funcție de dimensiunea clusterului de calcul.
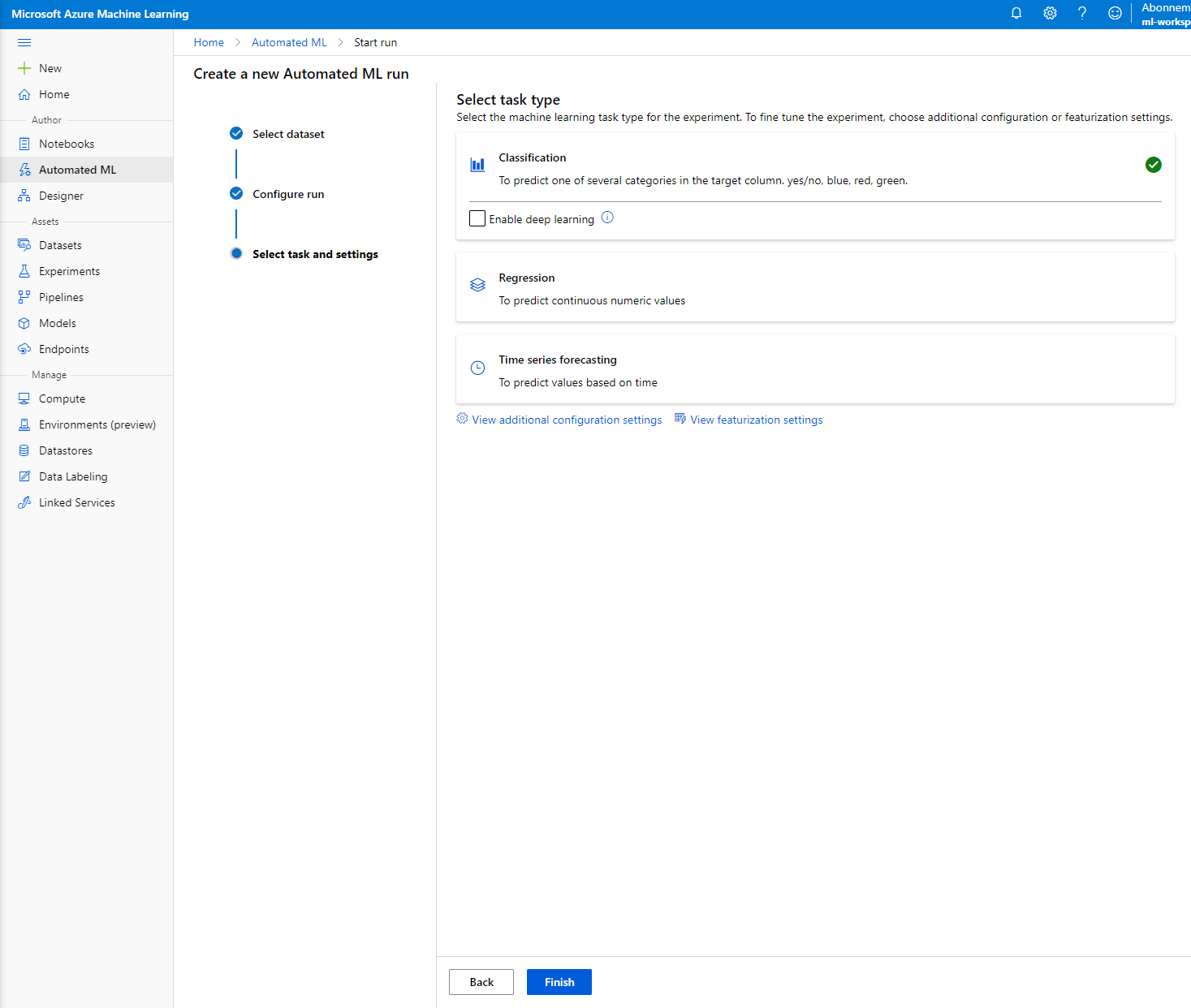
-
Odată ce rularea este completă, faceți clic pe fila "Automated ML", faceți clic pe rularea dvs. și apoi pe algoritmul din cardul "Best model summary".
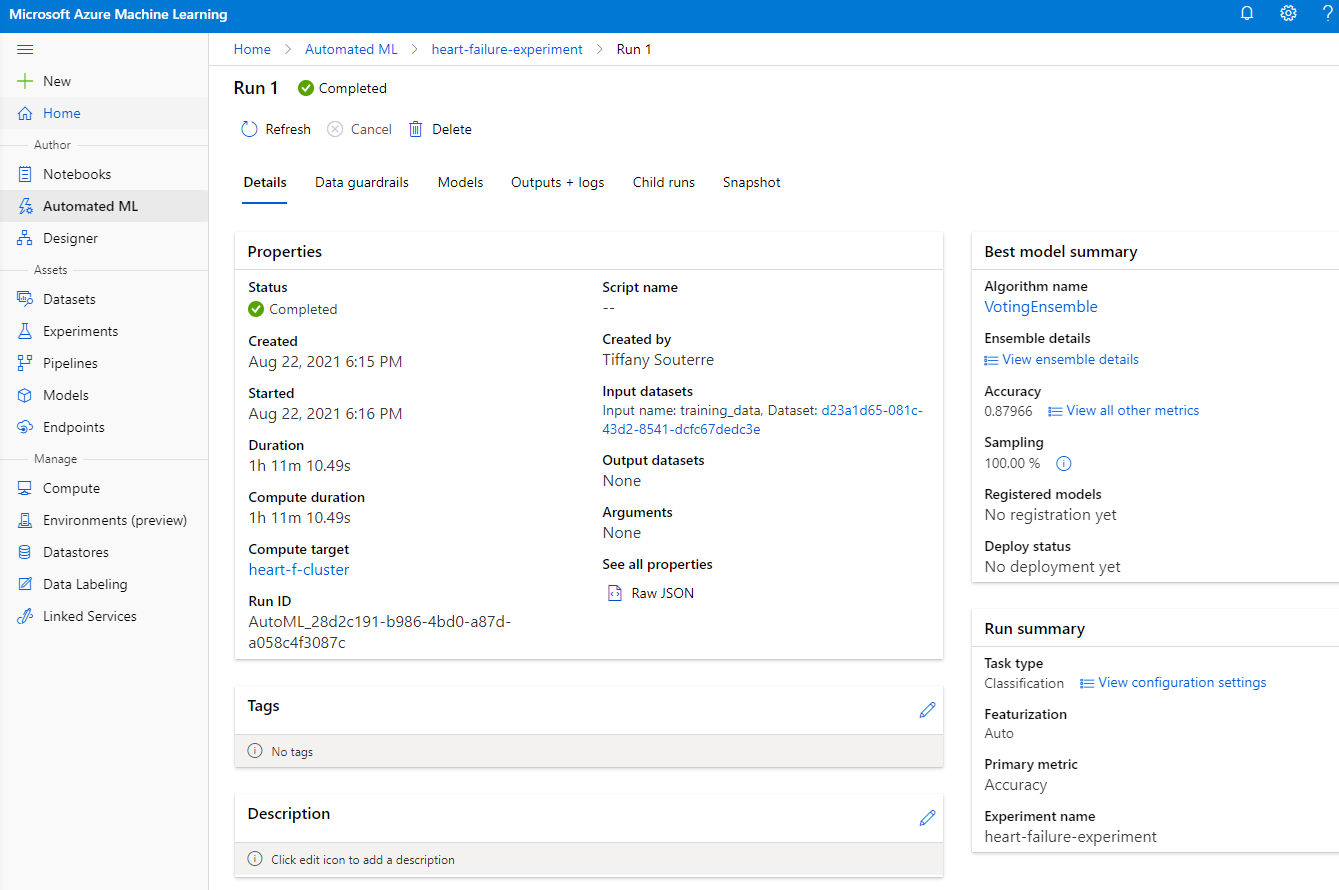
Aici puteți vedea o descriere detaliată a celui mai bun model generat de AutoML. De asemenea, puteți explora alte modele generate în fila Models. Petreceți câteva minute explorând modelele în butonul Explanations (preview). Odată ce ați ales modelul pe care doriți să-l utilizați (aici vom alege cel mai bun model selectat de AutoML), vom vedea cum îl putem implementa.
3. Implementarea modelului cu cod redus/fără cod și consumul endpoint-ului
3.1 Implementarea modelului
Interfața de învățare automată automată vă permite să implementați cel mai bun model ca serviciu web în câțiva pași. Implementarea este integrarea modelului astfel încât să poată face predicții bazate pe date noi și să identifice potențiale zone de oportunitate. Pentru acest proiect, implementarea ca serviciu web înseamnă că aplicațiile medicale vor putea consuma modelul pentru a face predicții live ale riscului pacienților de a suferi un atac de cord.
În descrierea celui mai bun model, faceți clic pe butonul "Deploy".
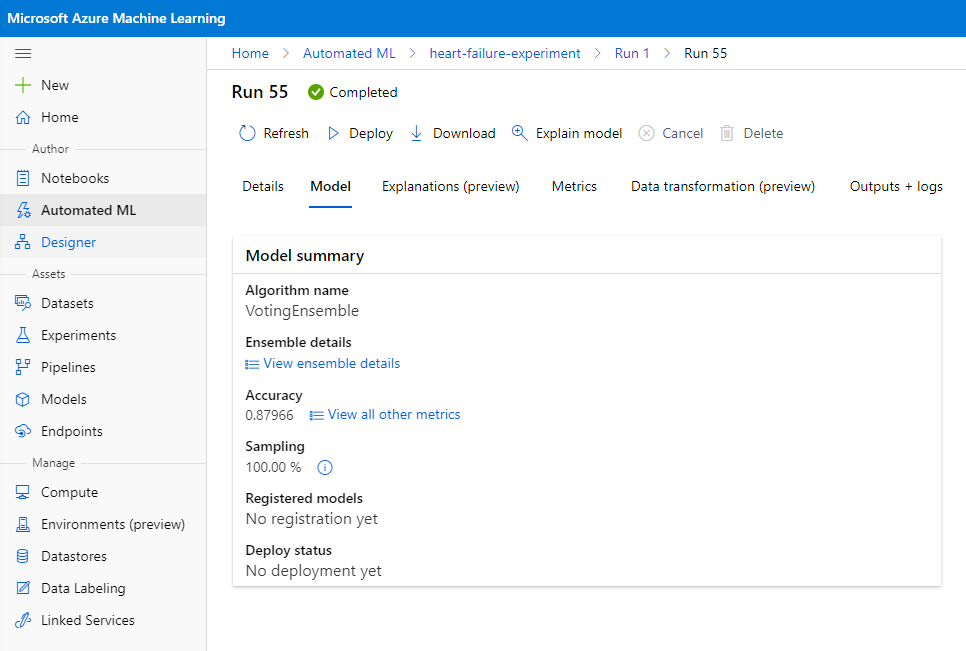
- Dați-i un nume, o descriere, tipul de calcul (Azure Container Instance), activați autentificarea și faceți clic pe Deploy. Acest pas poate dura aproximativ 20 de minute pentru a fi finalizat. Procesul de implementare implică mai mulți pași, inclusiv înregistrarea modelului, generarea resurselor și configurarea acestora pentru serviciul web. Un mesaj de stare apare sub Deploy status. Selectați Refresh periodic pentru a verifica starea implementării. Este implementat și funcțional atunci când starea este "Healthy".
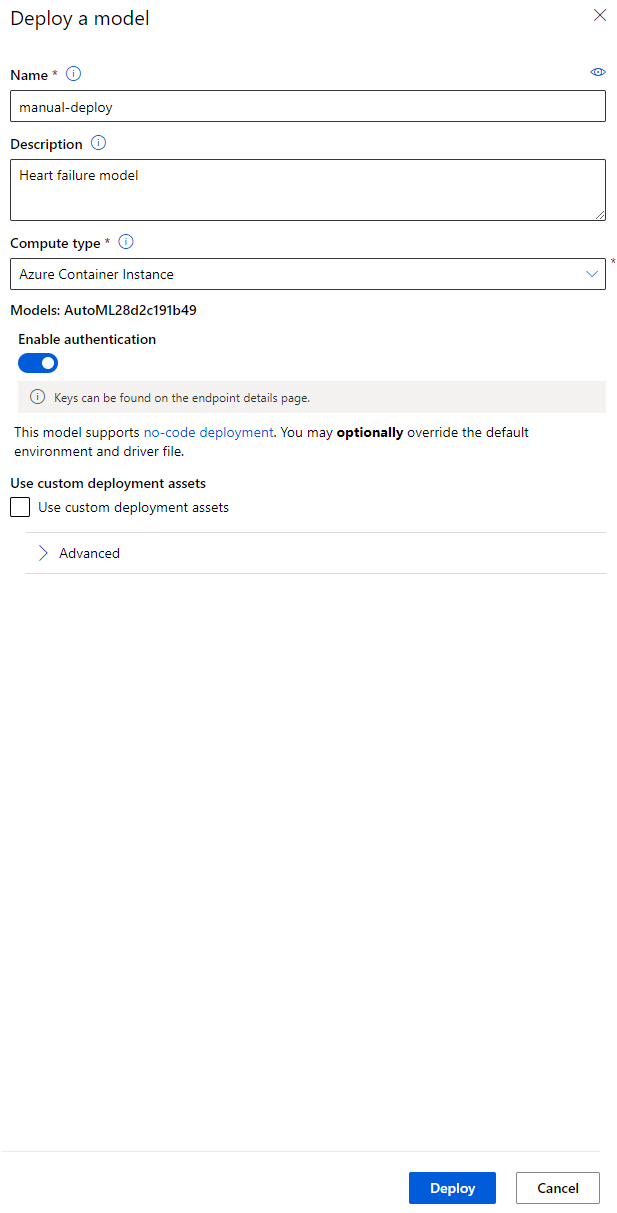
- Odată ce a fost implementat, faceți clic pe fila Endpoint și pe endpoint-ul pe care tocmai l-ați implementat. Aici puteți găsi toate detaliile pe care trebuie să le cunoașteți despre endpoint.
Minunat! Acum că avem un model implementat, putem începe consumul endpoint-ului.
3.2 Consumarea endpoint-ului
Faceți clic pe fila "Consume". Aici puteți găsi endpoint-ul REST și un script Python în opțiunea de consum. Petreceți puțin timp citind codul Python.
Acest script poate fi rulat direct de pe mașina dvs. locală și va consuma endpoint-ul.
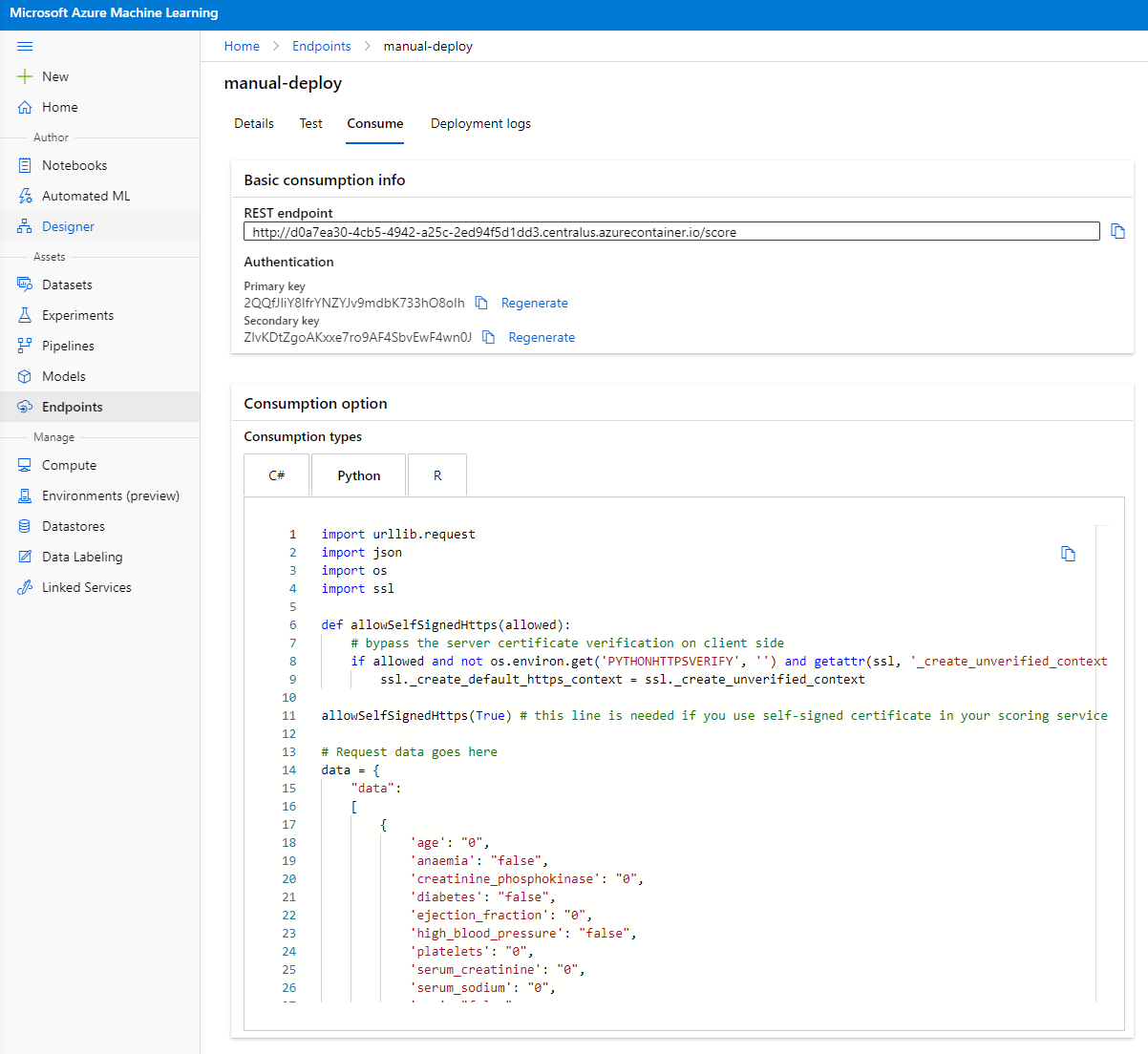
Petreceți un moment verificând aceste 2 linii de cod:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
Variabila url este endpoint-ul REST găsit în fila de consum, iar variabila api_key este cheia primară găsită tot în fila de consum (doar în cazul în care ați activat autentificarea). Acesta este modul în care scriptul poate consuma endpoint-ul.
- Rulând scriptul, ar trebui să vedeți următorul rezultat:
b'"{\\"result\\": [true]}"'
Aceasta înseamnă că predicția insuficienței cardiace pentru datele furnizate este adevărată. Acest lucru are sens, deoarece dacă priviți mai atent datele generate automat în script, totul este setat la 0 și fals implicit. Puteți schimba datele cu următorul exemplu de intrare:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
Scriptul ar trebui să returneze:
python b'"{\\"result\\": [true, false]}"'
Felicitări! Tocmai ați consumat modelul implementat și l-ați antrenat pe Azure ML!
NOTE: După ce ați terminat proiectul, nu uitați să ștergeți toate resursele.
🚀 Provocare
Analizați cu atenție explicațiile modelului și detaliile generate de AutoML pentru modelele de top. Încercați să înțelegeți de ce cel mai bun model este mai bun decât celelalte. Ce algoritmi au fost comparați? Care sunt diferențele dintre ele? De ce cel mai bun model are performanțe mai bune în acest caz?
Post-lecture quiz
Recapitulare și studiu individual
În această lecție, ați învățat cum să antrenați, să implementați și să consumați un model pentru a prezice riscul de insuficiență cardiacă într-un mod cu cod redus/fără cod în cloud. Dacă nu ați făcut-o încă, aprofundați explicațiile modelului generate de AutoML pentru modelele de top și încercați să înțelegeți de ce cel mai bun model este mai bun decât celelalte.
Puteți merge mai departe în AutoML cu cod redus/fără cod citind această documentație.
Temă
Proiect de știința datelor cu cod redus/fără cod pe Azure ML
Declinare de responsabilitate:
Acest document a fost tradus folosind serviciul de traducere AI Co-op Translator. Deși ne străduim să asigurăm acuratețea, vă rugăm să fiți conștienți că traducerile automate pot conține erori sau inexactități. Documentul original în limba sa natală ar trebui considerat sursa autoritară. Pentru informații critice, se recomandă traducerea profesională realizată de un specialist uman. Nu ne asumăm responsabilitatea pentru eventualele neînțelegeri sau interpretări greșite care pot apărea din utilizarea acestei traduceri.