|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
ਕਲਾਉਡ ਵਿੱਚ ਡਾਟਾ ਸਾਇੰਸ: "ਲੋ ਕੋਡ/ਨੋ ਕੋਡ" ਤਰੀਕਾ
| ਕਲਾਉਡ ਵਿੱਚ ਡਾਟਾ ਸਾਇੰਸ: ਲੋ ਕੋਡ - @nitya ਦੁਆਰਾ ਬਣਾਈ ਗਈ ਸਕੈਚਨੋਟ |
ਸਮੱਗਰੀ ਦੀ ਸੂਚੀ:
- ਕਲਾਉਡ ਵਿੱਚ ਡਾਟਾ ਸਾਇੰਸ: "ਲੋ ਕੋਡ/ਨੋ ਕੋਡ" ਤਰੀਕਾ
ਪ੍ਰੀ-ਲੈਕਚਰ ਕਵਿਜ਼
1. ਪਰਿਚਯ
1.1 Azure Machine Learning ਕੀ ਹੈ?
Azure ਕਲਾਉਡ ਪਲੇਟਫਾਰਮ 200 ਤੋਂ ਵੱਧ ਉਤਪਾਦਾਂ ਅਤੇ ਕਲਾਉਡ ਸੇਵਾਵਾਂ ਦਾ ਸਮੂਹ ਹੈ ਜੋ ਤੁਹਾਨੂੰ ਨਵੀਆਂ ਹੱਲਾਂ ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ।
ਡਾਟਾ ਸਾਇੰਟਿਸਟ ਡਾਟਾ ਦੀ ਖੋਜ ਅਤੇ ਪ੍ਰੀ-ਪ੍ਰੋਸੈਸਿੰਗ, ਅਤੇ ਸਹੀ ਮਾਡਲ ਬਣਾਉਣ ਲਈ ਵੱਖ-ਵੱਖ ਮਾਡਲ-ਟ੍ਰੇਨਿੰਗ ਐਲਗੋਰਿਦਮ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਨ ਵਿੱਚ ਕਾਫ਼ੀ ਸਮਾਂ ਲਗਾਉਂਦੇ ਹਨ। ਇਹ ਕੰਮ ਸਮਾਂ-ਖਪਤ ਵਾਲੇ ਹਨ ਅਤੇ ਅਕਸਰ ਮਹਿੰਗੇ ਕੰਪਿਊਟ ਹਾਰਡਵੇਅਰ ਦੀ ਅਸਮਰਥ ਵਰਤੋਂ ਕਰਦੇ ਹਨ।
Azure ML Azure ਵਿੱਚ ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਹੱਲਾਂ ਬਣਾਉਣ ਅਤੇ ਚਲਾਉਣ ਲਈ ਇੱਕ ਕਲਾਉਡ-ਅਧਾਰਤ ਪਲੇਟਫਾਰਮ ਹੈ। ਇਸ ਵਿੱਚ ਡਾਟਾ ਸਾਇੰਟਿਸਟਾਂ ਨੂੰ ਡਾਟਾ ਤਿਆਰ ਕਰਨ, ਮਾਡਲ ਟ੍ਰੇਨ ਕਰਨ, ਪੇਸ਼ਗੋਈ ਸੇਵਾਵਾਂ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਨ ਅਤੇ ਉਨ੍ਹਾਂ ਦੀ ਵਰਤੋਂ ਦੀ ਨਿਗਰਾਨੀ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਨ ਲਈ ਵਿਸ਼ਾਲ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਅਤੇ ਸਮਰੱਥਾਵਾਂ ਸ਼ਾਮਲ ਹਨ। ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ ਗੱਲ ਇਹ ਹੈ ਕਿ ਇਹ ਮਾਡਲ ਟ੍ਰੇਨਿੰਗ ਨਾਲ ਜੁੜੇ ਕਈ ਸਮਾਂ-ਖਪਤ ਵਾਲੇ ਕੰਮਾਂ ਨੂੰ ਆਟੋਮੈਟਿਕ ਕਰਕੇ ਉਨ੍ਹਾਂ ਦੀ ਕੁਸ਼ਲਤਾ ਨੂੰ ਵਧਾਉਂਦਾ ਹੈ; ਅਤੇ ਇਹ ਉਨ੍ਹਾਂ ਨੂੰ ਕਲਾਉਡ-ਅਧਾਰਤ ਕੰਪਿਊਟ ਰਿਸੋਰਸਾਂ ਦੀ ਵਰਤੋਂ ਕਰਨ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ ਜੋ ਵੱਡੇ ਡਾਟਾ ਦੀ ਸੰਖਿਆ ਨੂੰ ਸੰਭਾਲਣ ਲਈ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਤਰੀਕੇ ਨਾਲ ਸਕੇਲ ਕਰਦੇ ਹਨ, ਅਤੇ ਸਿਰਫ਼ ਵਰਤੋਂ ਦੇ ਸਮੇਂ ਹੀ ਖਰਚ ਹੁੰਦੇ ਹਨ।
Azure ML ਡਿਵੈਲਪਰਾਂ ਅਤੇ ਡਾਟਾ ਸਾਇੰਟਿਸਟਾਂ ਨੂੰ ਉਨ੍ਹਾਂ ਦੇ ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਵਰਕਫਲੋਜ਼ ਲਈ ਸਾਰੇ ਟੂਲ ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ। ਇਹਨਾਂ ਵਿੱਚ ਸ਼ਾਮਲ ਹਨ:
- Azure Machine Learning Studio: ਮਾਡਲ ਟ੍ਰੇਨਿੰਗ, ਡਿਪਲੌਇਮੈਂਟ, ਆਟੋਮੇਸ਼ਨ, ਟ੍ਰੈਕਿੰਗ ਅਤੇ ਐਸੈਟ ਮੈਨੇਜਮੈਂਟ ਲਈ ਲੋ-ਕੋਡ ਅਤੇ ਨੋ-ਕੋਡ ਵਿਕਲਪਾਂ ਲਈ ਇੱਕ ਵੈੱਬ ਪੋਰਟਲ। ਇਹ ਸਟੂਡੀਓ Azure Machine Learning SDK ਨਾਲ ਇੱਕ ਸਹੀ ਅਨੁਭਵ ਲਈ ਇੰਟਿਗ੍ਰੇਟ ਕਰਦਾ ਹੈ।
- Jupyter Notebooks: ML ਮਾਡਲਾਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਪ੍ਰੋਟੋਟਾਈਪ ਅਤੇ ਟੈਸਟ ਕਰਨ ਲਈ।
- Azure Machine Learning Designer: ਮਾਡਿਊਲਾਂ ਨੂੰ ਡ੍ਰੈਗ-ਐਂਡ-ਡ੍ਰੌਪ ਕਰਨ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ ਤਾਂ ਜੋ ਪ੍ਰਯੋਗ ਬਣਾਏ ਜਾ ਸਕਣ ਅਤੇ ਫਿਰ ਲੋ-ਕੋਡ ਵਾਤਾਵਰਣ ਵਿੱਚ ਪਾਈਪਲਾਈਨ ਡਿਪਲੌਇ ਕੀਤੇ ਜਾ ਸਕਣ।
- Automated machine learning UI (AutoML): ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਮਾਡਲ ਵਿਕਾਸ ਦੇ ਦੁਹਰਾਏ ਜਾਣ ਵਾਲੇ ਕੰਮਾਂ ਨੂੰ ਆਟੋਮੈਟਿਕ ਕਰਦਾ ਹੈ, ਜਿਸ ਨਾਲ ML ਮਾਡਲਾਂ ਨੂੰ ਵੱਡੇ ਪੈਮਾਨੇ, ਕੁਸ਼ਲਤਾ ਅਤੇ ਉਤਪਾਦਕਤਾ ਨਾਲ ਬਣਾਉਣ ਦੀ ਆਗਿਆ ਮਿਲਦੀ ਹੈ, ਸਾਰੇ ਮਾਡਲ ਗੁਣਵੱਤਾ ਨੂੰ ਕਾਇਮ ਰੱਖਦੇ ਹੋਏ।
- Data Labelling: ਡਾਟਾ ਨੂੰ ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ ਲੇਬਲ ਕਰਨ ਲਈ ਇੱਕ ਸਹਾਇਕ ML ਟੂਲ।
- Machine learning extension for Visual Studio Code: ML ਪ੍ਰੋਜੈਕਟਾਂ ਨੂੰ ਬਣਾਉਣ ਅਤੇ ਪ੍ਰਬੰਧਿਤ ਕਰਨ ਲਈ ਇੱਕ ਪੂਰੀ-ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਵਾਲਾ ਵਿਕਾਸ ਵਾਤਾਵਰਣ ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ।
- Machine learning CLI: ਕਮਾਂਡ ਲਾਈਨ ਤੋਂ Azure ML ਰਿਸੋਰਸਾਂ ਨੂੰ ਪ੍ਰਬੰਧਿਤ ਕਰਨ ਲਈ ਕਮਾਂਡ ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ।
- ਖੁੱਲ੍ਹੇ-ਸਰੋਤ ਫਰੇਮਵਰਕਾਂ ਨਾਲ ਇੰਟਿਗ੍ਰੇਸ਼ਨ ਜਿਵੇਂ ਕਿ PyTorch, TensorFlow, Scikit-learn ਅਤੇ ਹੋਰ ਬਹੁਤ ਕੁਝ, ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਪ੍ਰਕਿਰਿਆ ਦੇ ਅੰਤ-ਤੱਕ ਪ੍ਰਬੰਧਨ ਲਈ।
- MLflow: ਇਹ ਤੁਹਾਡੇ ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਪ੍ਰਯੋਗਾਂ ਦੇ ਜੀਵਨ ਚੱਕਰ ਨੂੰ ਪ੍ਰਬੰਧਿਤ ਕਰਨ ਲਈ ਇੱਕ ਖੁੱਲ੍ਹਾ-ਸਰੋਤ ਲਾਇਬ੍ਰੇਰੀ ਹੈ। MLFlow Tracking MLflow ਦਾ ਇੱਕ ਘਟਕ ਹੈ ਜੋ ਤੁਹਾਡੇ ਟ੍ਰੇਨਿੰਗ ਰਨ ਮੈਟ੍ਰਿਕਸ ਅਤੇ ਮਾਡਲ ਆਰਟੀਫੈਕਟਾਂ ਨੂੰ ਲੌਗ ਅਤੇ ਟ੍ਰੈਕ ਕਰਦਾ ਹੈ, ਭਾਵੇਂ ਤੁਹਾਡੇ ਪ੍ਰਯੋਗ ਦਾ ਵਾਤਾਵਰਣ ਜੋ ਵੀ ਹੋਵੇ।
1.2 ਦਿਲ ਦੇ ਦੌਰੇ ਦੀ ਪੇਸ਼ਗੋਈ ਪ੍ਰੋਜੈਕਟ:
ਪ੍ਰੋਜੈਕਟ ਬਣਾਉਣਾ ਅਤੇ ਉਸ ਨੂੰ ਬਣਾਉਣਾ ਤੁਹਾਡੇ ਹੁਨਰ ਅਤੇ ਗਿਆਨ ਦੀ ਜਾਂਚ ਕਰਨ ਦਾ ਸਭ ਤੋਂ ਵਧੀਆ ਤਰੀਕਾ ਹੈ। ਇਸ ਪਾਠ ਵਿੱਚ, ਅਸੀਂ ਦਿਲ ਦੇ ਦੌਰੇ ਦੀ ਪੇਸ਼ਗੋਈ ਕਰਨ ਵਾਲੇ ਡਾਟਾ ਸਾਇੰਸ ਪ੍ਰੋਜੈਕਟ ਨੂੰ ਬਣਾਉਣ ਦੇ ਦੋ ਵੱਖ-ਵੱਖ ਤਰੀਕੇ ਖੋਜਣ ਜਾ ਰਹੇ ਹਾਂ: Azure ML Studio ਵਿੱਚ ਲੋ ਕੋਡ/ਨੋ ਕੋਡ ਅਤੇ Azure ML SDK ਦੁਆਰਾ, ਜਿਵੇਂ ਕਿ ਹੇਠਾਂ ਦਿੱਤੇ ਸਕੀਮਾ ਵਿੱਚ ਦਿਖਾਇਆ ਗਿਆ ਹੈ:
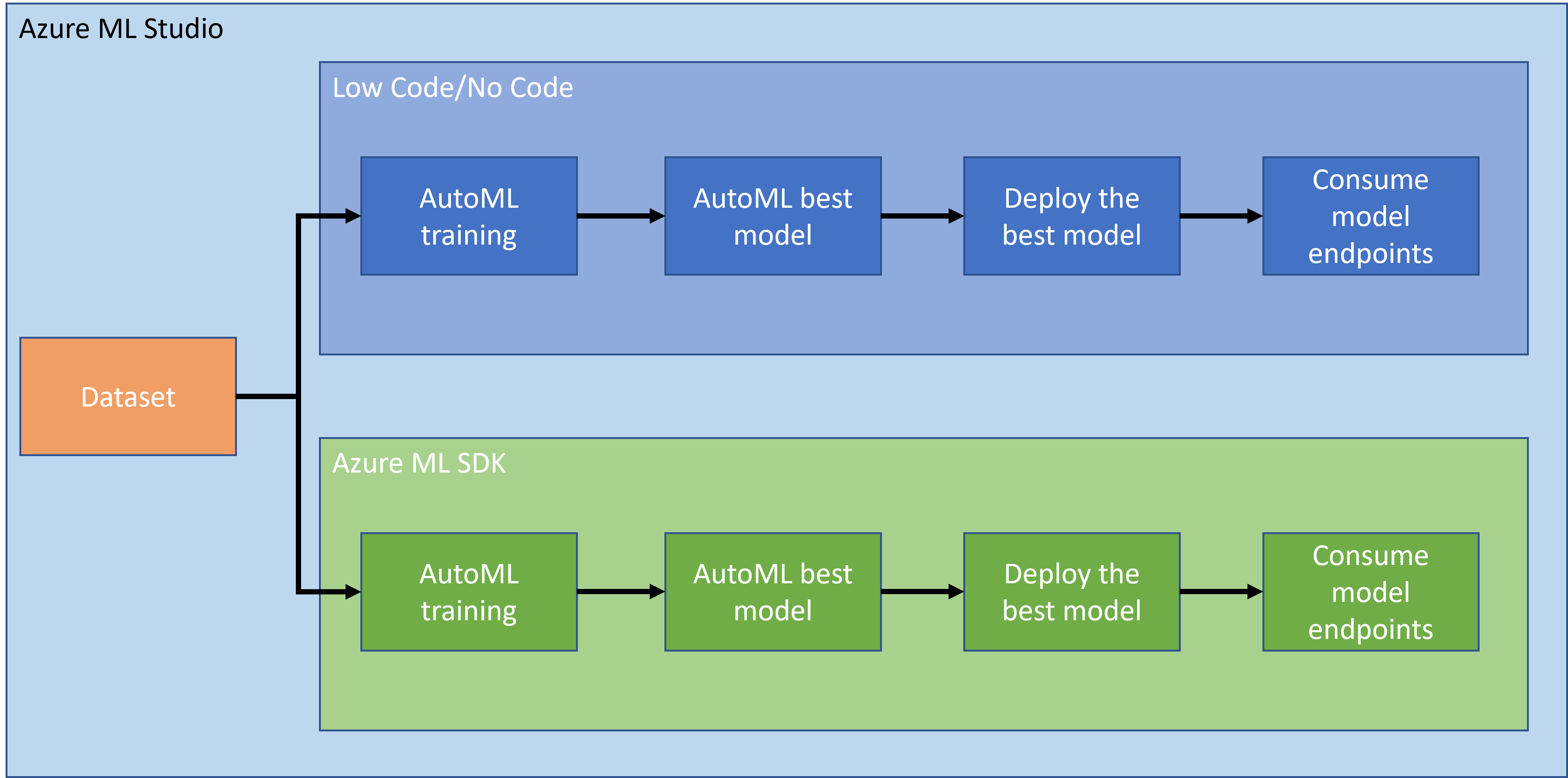
ਹਰ ਤਰੀਕੇ ਦੇ ਆਪਣੇ ਫਾਇਦੇ ਅਤੇ ਨੁਕਸਾਨ ਹਨ। ਲੋ ਕੋਡ/ਨੋ ਕੋਡ ਤਰੀਕਾ ਸ਼ੁਰੂ ਕਰਨ ਲਈ ਆਸਾਨ ਹੈ ਕਿਉਂਕਿ ਇਸ ਵਿੱਚ GUI (ਗ੍ਰਾਫਿਕਲ ਯੂਜ਼ਰ ਇੰਟਰਫੇਸ) ਨਾਲ ਸੰਚਾਰ ਕਰਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ, ਜਿਸ ਲਈ ਕੋਡ ਦਾ ਕੋਈ ਪੂਰਵ-ਗਿਆਨ ਨਹੀਂ ਚਾਹੀਦਾ। ਇਹ ਤਰੀਕਾ ਪ੍ਰੋਜੈਕਟ ਦੀ ਯੋਗਤਾ ਦੀ ਤੇਜ਼ੀ ਨਾਲ ਜਾਂਚ ਕਰਨ ਅਤੇ POC (ਪ੍ਰੂਫ ਆਫ ਕਾਨਸੈਪਟ) ਬਣਾਉਣ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ। ਹਾਲਾਂਕਿ, ਜਦੋਂ ਪ੍ਰੋਜੈਕਟ ਵਧਦਾ ਹੈ ਅਤੇ ਚੀਜ਼ਾਂ ਨੂੰ ਉਤਪਾਦਨ ਲਈ ਤਿਆਰ ਕਰਨ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ, ਤਾਂ GUI ਦੁਆਰਾ ਰਿਸੋਰਸ ਬਣਾਉਣਾ ਸੰਭਵ ਨਹੀਂ ਹੁੰਦਾ। ਸਾਨੂੰ ਪ੍ਰੋਗਰਾਮਿੰਗ ਰਾਹੀਂ ਸਾਰਾ ਕੁਝ ਆਟੋਮੈਟਿਕ ਕਰਨਾ ਪੈਂਦਾ ਹੈ, ਰਿਸੋਰਸ ਬਣਾਉਣ ਤੋਂ ਲੈ ਕੇ ਮਾਡਲ ਡਿਪਲੌਇਮੈਂਟ ਤੱਕ। ਇਹ ਜਿੱਥੇ Azure ML SDK ਦੀ ਵਰਤੋਂ ਕਰਨ ਦਾ ਗਿਆਨ ਮਹੱਤਵਪੂਰਨ ਬਣ ਜਾਂਦਾ ਹੈ।
| ਲੋ ਕੋਡ/ਨੋ ਕੋਡ | Azure ML SDK | |
|---|---|---|
| ਕੋਡ ਵਿੱਚ ਮਾਹਰਤਾ | ਲੋੜੀਂ ਨਹੀਂ | ਲੋੜੀਂ ਹੈ |
| ਵਿਕਾਸ ਲਈ ਸਮਾਂ | ਤੇਜ਼ ਅਤੇ ਆਸਾਨ | ਕੋਡ ਮਾਹਰਤਾ 'ਤੇ ਨਿਰਭਰ |
| ਉਤਪਾਦਨ ਲਈ ਤਿਆਰ | ਨਹੀਂ | ਹਾਂ |
1.3 ਦਿਲ ਦੇ ਦੌਰੇ ਦਾ ਡਾਟਾਸੈੱਟ:
ਕਾਰਡੀਓਵੈਸਕੁਲਰ ਬਿਮਾਰੀਆਂ (CVDs) ਦੁਨੀਆ ਭਰ ਵਿੱਚ ਮੌਤ ਦਾ ਨੰਬਰ 1 ਕਾਰਨ ਹਨ, ਜੋ ਦੁਨੀਆ ਭਰ ਵਿੱਚ 31% ਮੌਤਾਂ ਲਈ ਜ਼ਿੰਮੇਵਾਰ ਹਨ। ਤੰਤਰਕ ਅਤੇ ਵਿਹਾਰਕ ਖਤਰੇ ਦੇ ਕਾਰਕ ਜਿਵੇਂ ਕਿ ਤਮਾਕੂ ਦੀ ਵਰਤੋਂ, ਅਣਹੈਲਥੀ ਡਾਇਟ ਅਤੇ ਮੋਟਾਪਾ, ਸ਼ਾਰਿਰਕ ਗਤੀਵਿਧੀ ਦੀ ਘਾਟ ਅਤੇ ਸ਼ਰਾਬ ਦੀ ਹਾਨਿਕਾਰਕ ਵਰਤੋਂ ਅੰਦਾਜ਼ਾ ਮਾਡਲਾਂ ਲਈ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਵਜੋਂ ਵਰਤੇ ਜਾ ਸਕਦੇ ਹਨ। CVD ਦੇ ਵਿਕਾਸ ਦੀ ਸੰਭਾਵਨਾ ਦਾ ਅੰਦਾਜ਼ਾ ਲਗਾਉਣ ਦੇ ਯੋਗ ਹੋਣਾ ਉੱਚ-ਖਤਰੇ ਵਾਲੇ ਲੋਕਾਂ ਵਿੱਚ ਦੌਰਿਆਂ ਨੂੰ ਰੋਕਣ ਲਈ ਬਹੁਤ ਲਾਭਦਾਇਕ ਹੋ ਸਕਦਾ ਹੈ।
Kaggle ਨੇ ਇੱਕ ਦਿਲ ਦੇ ਦੌਰੇ ਦਾ ਡਾਟਾਸੈੱਟ ਜਨਤਕ ਤੌਰ 'ਤੇ ਉਪਲਬਧ ਕੀਤਾ ਹੈ, ਜਿਸ ਨੂੰ ਅਸੀਂ ਇਸ ਪ੍ਰੋਜੈਕਟ ਲਈ ਵਰਤਣ ਜਾ ਰਹੇ ਹਾਂ। ਤੁਸੀਂ ਹੁਣ ਡਾਟਾਸੈੱਟ ਡਾਊਨਲੋਡ ਕਰ ਸਕਦੇ ਹੋ। ਇਹ ਇੱਕ ਟੇਬੂਲਰ ਡਾਟਾਸੈੱਟ ਹੈ ਜਿਸ ਵਿੱਚ 13 ਕਾਲਮ (12 ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਅਤੇ 1 ਟਾਰਗਟ ਵੈਰੀਏਬਲ) ਅਤੇ 299 ਪੰਕਤੀਆਂ ਹਨ।
| ਵੈਰੀਏਬਲ ਦਾ ਨਾਮ | ਕਿਸਮ | ਵੇਰਵਾ | ਉਦਾਹਰਨ | |
|---|---|---|---|---|
| 1 | ਉਮਰ | ਸੰਖਿਆਤਮਕ | ਮਰੀਜ਼ ਦੀ ਉਮਰ | 25 |
| 2 | ਅਨੀਮੀਆ | ਬੂਲੀਅਨ | ਲਾਲ ਖੂਨ ਦੇ ਸੈਲਾਂ ਜਾਂ ਹਿਮੋਗਲੋਬਿਨ ਦੀ ਘਾਟ | 0 ਜਾਂ 1 |
| 3 | creatinine_phosphokinase | ਸੰਖਿਆਤਮਕ | ਖੂਨ ਵਿੱਚ CPK ਐਂਜ਼ਾਈਮ ਦੀ ਪੱਧਰ | 542 |
| 4 | ਡਾਇਬਟੀਜ਼ | ਬੂਲੀਅਨ | ਜੇ ਮਰੀਜ਼ ਨੂੰ ਡਾਇਬਟੀਜ਼ ਹੈ | 0 ਜਾਂ 1 |
| 5 | ejection_fraction | ਸੰਖਿਆਤਮਕ | ਹਰ ਸੰਕੋਚਨ 'ਤੇ ਦਿਲ ਤੋਂ ਨਿਕਲਣ ਵਾਲੇ ਖੂਨ ਦੀ ਪ੍ਰਤੀਸ਼ਤ | 45 |
| 6 | high_blood_pressure | ਬੂਲੀਅਨ | ਜੇ ਮਰੀਜ਼ ਨੂੰ ਹਾਈਪਰਟੈਂਸ਼ਨ ਹੈ | 0 ਜਾਂ 1 |
| 7 | platelets | ਸੰਖਿਆਤਮਕ | ਖੂਨ ਵਿੱਚ ਪਲੇਟਲੈਟਸ | 149000 |
| 8 | serum_creatinine | ਸੰਖਿਆਤਮਕ | ਖੂਨ ਵਿੱਚ ਸਿਰਮ ਕ੍ਰੀਏਟਿਨਾਈਨ ਦੀ ਪੱਧਰ | 0.5 |
| 9 | serum_sodium | ਸੰਖਿਆਤਮਕ | ਖੂਨ ਵਿੱਚ ਸਿਰਮ ਸੋਡੀਅਮ ਦੀ ਪੱਧਰ | jun |
| 10 | ਲਿੰਗ | ਬੂਲੀਅਨ | ਔਰਤ ਜਾਂ ਮਰਦ | 0 ਜਾਂ 1 |
| 11 | ਧੂਮਰਪਾਨ | ਬੂਲੀਅਨ | ਜੇ ਮਰੀਜ਼ ਧੂਮਰਪਾਨ ਕਰਦਾ ਹੈ | 0 ਜਾਂ 1 |
| 12 | ਸਮਾਂ | ਸੰਖਿਆਤਮਕ | ਫਾਲੋਅਪ ਅਵਧੀ (ਦਿਨ) | 4 |
| ---- | --------------------------- | ----------------- | ----------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [Target] | ਬੂਲੀਅਨ | ਜੇ ਮਰੀਜ਼ ਫਾਲੋਅਪ ਅਵਧੀ ਦੌਰਾਨ ਮਰਦਾ ਹੈ | 0 ਜਾਂ 1 |
ਜਦੋਂ ਤੁਹਾਡੇ ਕੋਲ ਡਾਟਾਸੈੱਟ ਹੋਵੇ, ਅਸੀਂ Azure ਵਿੱਚ ਪ੍ਰੋਜੈਕਟ ਸ਼ੁਰੂ ਕਰ ਸਕਦੇ ਹਾਂ।
2. Azure ML Studio ਵਿੱਚ ਮਾਡਲ ਦੀ ਲੋ ਕੋਡ/ਨੋ ਕੋਡ ਟ੍ਰੇਨਿੰਗ
2.1 Azure ML ਵਰਕਸਪੇਸ ਬਣਾਉਣਾ
Azure ML ਵਿੱਚ ਮਾਡਲ ਟ੍ਰੇਨ ਕਰਨ ਲਈ ਤੁਹਾਨੂੰ ਪਹਿਲਾਂ Azure ML ਵਰਕਸਪੇਸ ਬਣਾਉਣ ਦੀ ਲੋੜ ਹੈ। ਵਰਕਸਪੇਸ Azure Machine Learning ਲਈ ਸਿਖਰ-ਪੱਧਰ ਦਾ ਸਰੋਤ ਹੈ, ਜੋ ਤੁਹਾਡੇ ਦੁਆਰਾ ਬਣਾਏ ਗਏ ਸਾਰੇ ਆਰਟੀਫੈਕਟਾਂ ਨਾਲ ਕੰਮ ਕਰਨ ਲਈ ਇੱਕ ਕੇਂਦਰੀ ਸਥਾਨ ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ। ਵਰਕਸਪੇਸ ਸਾਰੇ ਟ੍ਰੇਨਿੰਗ ਰਨ ਦਾ ਇਤਿਹਾਸ ਰੱਖਦਾ ਹੈ, ਜਿਸ ਵਿੱਚ ਲੌਗ, ਮੈਟ੍ਰਿਕਸ, ਆਉਟਪੁੱਟ ਅਤੇ ਤੁਹਾਡੇ ਸਕ੍ਰਿਪਟਾਂ ਦੀ ਸਨੈਪਸ਼ਾਟ ਸ਼ਾਮਲ ਹੈ। ਤੁਸੀਂ ਇਹ ਜਾਣਕਾਰੀ ਇਸ ਗੱਲ ਦਾ ਨਿਰਧਾਰਨ ਕਰਨ ਲਈ ਵਰਤਦੇ ਹੋ ਕਿ ਕਿਹੜਾ ਟ੍ਰੇਨਿੰਗ ਰਨ ਸਭ ਤੋਂ ਵਧੀਆ ਮਾਡਲ ਪੈਦਾ ਕਰਦਾ ਹੈ। ਹੋਰ ਜਾਣੋ
ਇਹ ਸਿਫਾਰਸ਼ ਕੀਤੀ ਜਾਂਦੀ ਹੈ ਕਿ ਆਪਣੇ ਆਪਰੇਟਿੰਗ ਸਿਸਟਮ ਨਾਲ ਅਨੁਕੂਲ ਸਭ ਤੋਂ ਅੱਪ-ਟੂ-ਡੇਟ ਬ੍ਰਾਊਜ਼ਰ ਦੀ ਵਰਤੋਂ ਕਰੋ। ਹੇਠਾਂ ਦਿੱਤੇ ਬ੍ਰਾਊਜ਼ਰ ਸਹਾਇਕ ਹਨ:
- Microsoft Edge (ਨਵਾਂ Microsoft Edge, ਤਾਜ਼ਾ ਵਰਜਨ। Microsoft Edge ਲੈਗੇਸੀ ਨਹੀਂ)
- Safari (ਤਾਜ਼ਾ ਵਰਜਨ, ਸਿਰਫ਼ Mac)
- Chrome (ਤਾਜ਼ਾ ਵਰਜਨ)
- Firefox (ਤਾਜ਼ਾ ਵਰਜਨ)
Azure Machine Learning ਦੀ ਵਰਤੋਂ ਕਰਨ ਲਈ, ਆਪਣੇ Azure ਸਬਸਕ੍ਰਿਪਸ਼ਨ ਵਿੱਚ ਇੱਕ ਵਰਕਸਪੇਸ
- ਜੁੜੇ ਹੋਏ ਕੰਪਿਊਟ: ਮੌਜੂਦਾ Azure ਕੰਪਿਊਟ ਸਰੋਤਾਂ ਨਾਲ ਲਿੰਕ ਕਰਦਾ ਹੈ, ਜਿਵੇਂ ਕਿ Virtual Machines ਜਾਂ Azure Databricks ਕਲੱਸਟਰ।
2.2.1 ਆਪਣੇ ਕੰਪਿਊਟ ਸਰੋਤਾਂ ਲਈ ਸਹੀ ਵਿਕਲਪ ਚੁਣਨਾ
ਕੰਪਿਊਟ ਸਰੋਤ ਬਣਾਉਣ ਸਮੇਂ ਕੁਝ ਮਹੱਤਵਪੂਰਨ ਗੱਲਾਂ ਦਾ ਧਿਆਨ ਰੱਖਣਾ ਚਾਹੀਦਾ ਹੈ, ਅਤੇ ਇਹ ਚੋਣਾਂ ਅਹਿਮ ਫੈਸਲੇ ਹੋ ਸਕਦੇ ਹਨ।
ਤੁਹਾਨੂੰ CPU ਜਾਂ GPU ਦੀ ਲੋੜ ਹੈ?
CPU (Central Processing Unit) ਇੱਕ ਇਲੈਕਟ੍ਰਾਨਿਕ ਸਰਕਟਰੀ ਹੈ ਜੋ ਕੰਪਿਊਟਰ ਪ੍ਰੋਗਰਾਮ ਦੇ ਹੁਕਮਾਂ ਨੂੰ ਅੰਜਾਮ ਦਿੰਦੀ ਹੈ। GPU (Graphics Processing Unit) ਇੱਕ ਵਿਸ਼ੇਸ਼ ਇਲੈਕਟ੍ਰਾਨਿਕ ਸਰਕਟ ਹੈ ਜੋ ਗ੍ਰਾਫਿਕਸ-ਸੰਬੰਧੀ ਕੋਡ ਨੂੰ ਬਹੁਤ ਤੇਜ਼ੀ ਨਾਲ ਚਲਾਉਣ ਦੇ ਯੋਗ ਹੈ।
CPU ਅਤੇ GPU ਦੇ ਆਰਕੀਟੈਕਚਰ ਵਿੱਚ ਮੁੱਖ ਅੰਤਰ ਇਹ ਹੈ ਕਿ CPU ਵਿਆਪਕ ਕੰਮਾਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਸੰਭਾਲਣ ਲਈ ਡਿਜ਼ਾਈਨ ਕੀਤਾ ਗਿਆ ਹੈ (ਜਿਵੇਂ ਕਿ CPU ਘੜੀ ਦੀ ਗਤੀ ਨਾਲ ਮਾਪਿਆ ਜਾਂਦਾ ਹੈ), ਪਰ ਇਹ ਕੰਮਾਂ ਦੀ ਸਮਕਾਲੀਤਾ ਵਿੱਚ ਸੀਮਿਤ ਹੁੰਦਾ ਹੈ। GPUs ਸਮਕਾਲੀ ਗਣਨਾ ਲਈ ਡਿਜ਼ਾਈਨ ਕੀਤੇ ਗਏ ਹਨ ਅਤੇ ਇਸ ਲਈ ਡੀਪ ਲਰਨਿੰਗ ਕੰਮਾਂ ਲਈ ਬਹੁਤ ਵਧੀਆ ਹਨ।
| CPU | GPU |
|---|---|
| ਘੱਟ ਮਹਿੰਗਾ | ਜ਼ਿਆਦਾ ਮਹਿੰਗਾ |
| ਘੱਟ ਸਮਕਾਲੀਤਾ | ਵਧੀਆ ਸਮਕਾਲੀਤਾ |
| ਡੀਪ ਲਰਨਿੰਗ ਮਾਡਲਾਂ ਨੂੰ ਸਲੋ ਟ੍ਰੇਨ ਕਰਦਾ ਹੈ | ਡੀਪ ਲਰਨਿੰਗ ਲਈ ਉਤਕ੍ਰਿਸ਼ਟ |
ਕਲੱਸਟਰ ਦਾ ਆਕਾਰ
ਵੱਡੇ ਕਲੱਸਟਰ ਮਹਿੰਗੇ ਹੁੰਦੇ ਹਨ ਪਰ ਇਹ ਬਿਹਤਰ ਪ੍ਰਤੀਕ੍ਰਿਆਸ਼ੀਲਤਾ ਦੇਣਗੇ। ਇਸ ਲਈ, ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਸਮਾਂ ਹੈ ਪਰ ਪੈਸੇ ਘੱਟ ਹਨ, ਤਾਂ ਤੁਹਾਨੂੰ ਛੋਟੇ ਕਲੱਸਟਰ ਨਾਲ ਸ਼ੁਰੂ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ। ਵਿਰੋਧੀ ਤੌਰ 'ਤੇ, ਜੇ ਤੁਹਾਡੇ ਕੋਲ ਪੈਸਾ ਹੈ ਪਰ ਸਮਾਂ ਘੱਟ ਹੈ, ਤਾਂ ਤੁਹਾਨੂੰ ਵੱਡੇ ਕਲੱਸਟਰ ਨਾਲ ਸ਼ੁਰੂ ਕਰਨਾ ਚਾਹੀਦਾ ਹੈ।
VM ਦਾ ਆਕਾਰ
ਤੁਹਾਡੇ ਸਮੇਂ ਅਤੇ ਬਜਟ ਦੀਆਂ ਪਾਬੰਦੀਆਂ ਦੇ ਅਧਾਰ 'ਤੇ, ਤੁਸੀਂ ਆਪਣੇ RAM, ਡਿਸਕ, ਕੋਰਾਂ ਦੀ ਗਿਣਤੀ ਅਤੇ ਘੜੀ ਦੀ ਗਤੀ ਦੇ ਆਕਾਰ ਨੂੰ ਵਧਾ ਸਕਦੇ ਹੋ। ਇਹ ਸਾਰੇ ਪੈਰਾਮੀਟਰ ਵਧਾਉਣਾ ਮਹਿੰਗਾ ਹੋਵੇਗਾ, ਪਰ ਇਹ ਬਿਹਤਰ ਪ੍ਰਦਰਸ਼ਨ ਦੇਵੇਗਾ।
Dedicated ਜਾਂ Low-Priority Instances?
Low-priority instance ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਇਹ ਰੁਕਾਵਟ ਪੈਦਾ ਕਰ ਸਕਦੀ ਹੈ: ਮੂਲ ਤੌਰ 'ਤੇ, Microsoft Azure ਉਹ ਸਰੋਤ ਲੈ ਸਕਦਾ ਹੈ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਕਿਸੇ ਹੋਰ ਕੰਮ ਲਈ ਸੌਂਪ ਸਕਦਾ ਹੈ, ਇਸ ਤਰ੍ਹਾਂ ਇੱਕ ਜੌਬ ਨੂੰ ਰੋਕ ਸਕਦਾ ਹੈ। Dedicated instance, ਜਾਂ non-interruptible, ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਜੌਬ ਤੁਹਾਡੀ ਇਜਾਜ਼ਤ ਤੋਂ ਬਿਨਾਂ ਕਦੇ ਵੀ ਖਤਮ ਨਹੀਂ ਹੋਵੇਗੀ। ਇਹ ਸਮਾਂ ਅਤੇ ਪੈਸੇ ਦੇ ਵਿਚਾਰ ਦਾ ਇੱਕ ਹੋਰ ਪੱਖ ਹੈ, ਕਿਉਂਕਿ interruptible instances dedicated ones ਨਾਲੋਂ ਘੱਟ ਮਹਿੰਗੇ ਹੁੰਦੇ ਹਨ।
2.2.2 ਕੰਪਿਊਟ ਕਲੱਸਟਰ ਬਣਾਉਣਾ
Azure ML workspace ਵਿੱਚ ਜੋ ਅਸੀਂ ਪਹਿਲਾਂ ਬਣਾਇਆ ਸੀ, ਕੰਪਿਊਟ 'ਤੇ ਜਾਓ ਅਤੇ ਤੁਸੀਂ ਉਹਨਾਂ ਵੱਖ-ਵੱਖ ਕੰਪਿਊਟ ਸਰੋਤਾਂ ਨੂੰ ਦੇਖ ਸਕਦੇ ਹੋ ਜਿਨ੍ਹਾਂ ਬਾਰੇ ਅਸੀਂ ਹੁਣੇ ਚਰਚਾ ਕੀਤੀ (ਜਿਵੇਂ ਕਿ compute instances, compute clusters, inference clusters ਅਤੇ attached compute)। ਇਸ ਪ੍ਰੋਜੈਕਟ ਲਈ, ਸਾਨੂੰ ਮਾਡਲ ਟ੍ਰੇਨਿੰਗ ਲਈ ਇੱਕ ਕੰਪਿਊਟ ਕਲੱਸਟਰ ਦੀ ਲੋੜ ਹੋਵੇਗੀ। Studio ਵਿੱਚ, "Compute" ਮੀਨੂ 'ਤੇ ਕਲਿੱਕ ਕਰੋ, ਫਿਰ "Compute cluster" ਟੈਬ 'ਤੇ ਕਲਿੱਕ ਕਰੋ ਅਤੇ ਕੰਪਿਊਟ ਕਲੱਸਟਰ ਬਣਾਉਣ ਲਈ "+ New" ਬਟਨ 'ਤੇ ਕਲਿੱਕ ਕਰੋ।
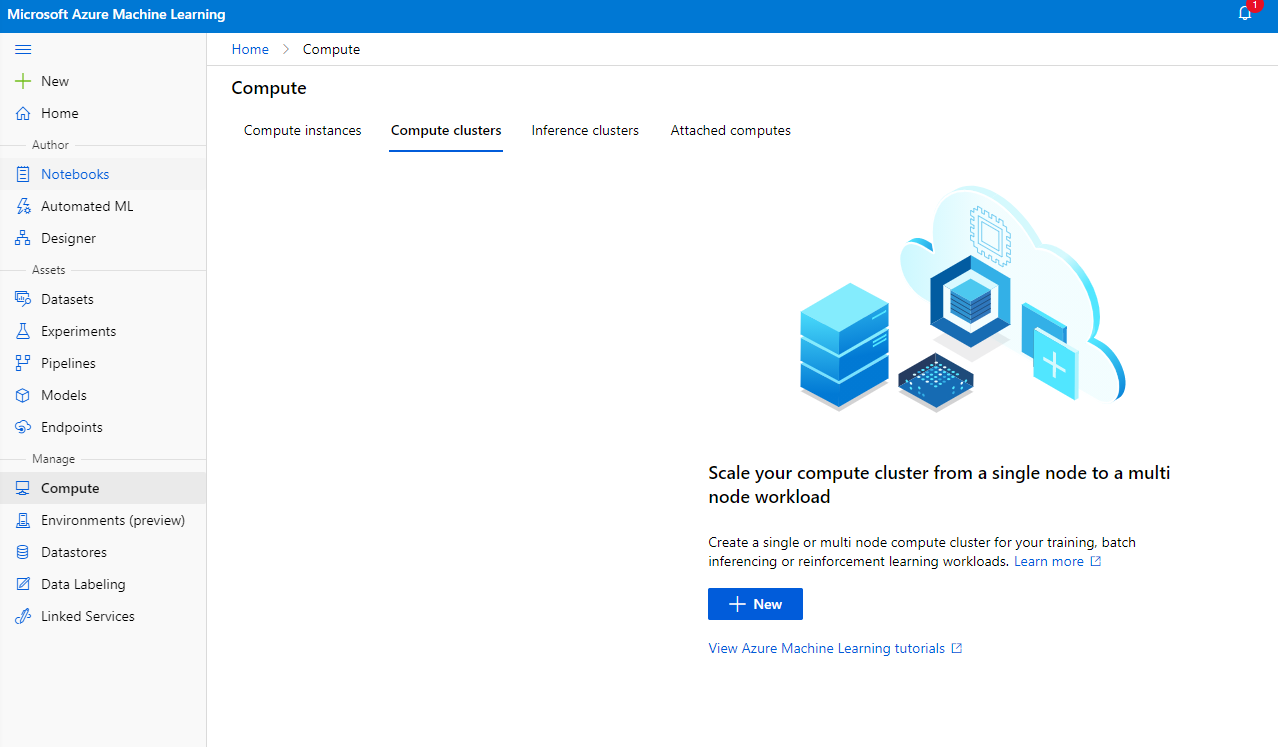
- ਆਪਣੇ ਵਿਕਲਪ ਚੁਣੋ: Dedicated vs Low priority, CPU ਜਾਂ GPU, VM size ਅਤੇ core number (ਤੁਸੀਂ ਇਸ ਪ੍ਰੋਜੈਕਟ ਲਈ ਡਿਫਾਲਟ ਸੈਟਿੰਗਾਂ ਰੱਖ ਸਕਦੇ ਹੋ)।
- Next ਬਟਨ 'ਤੇ ਕਲਿੱਕ ਕਰੋ।
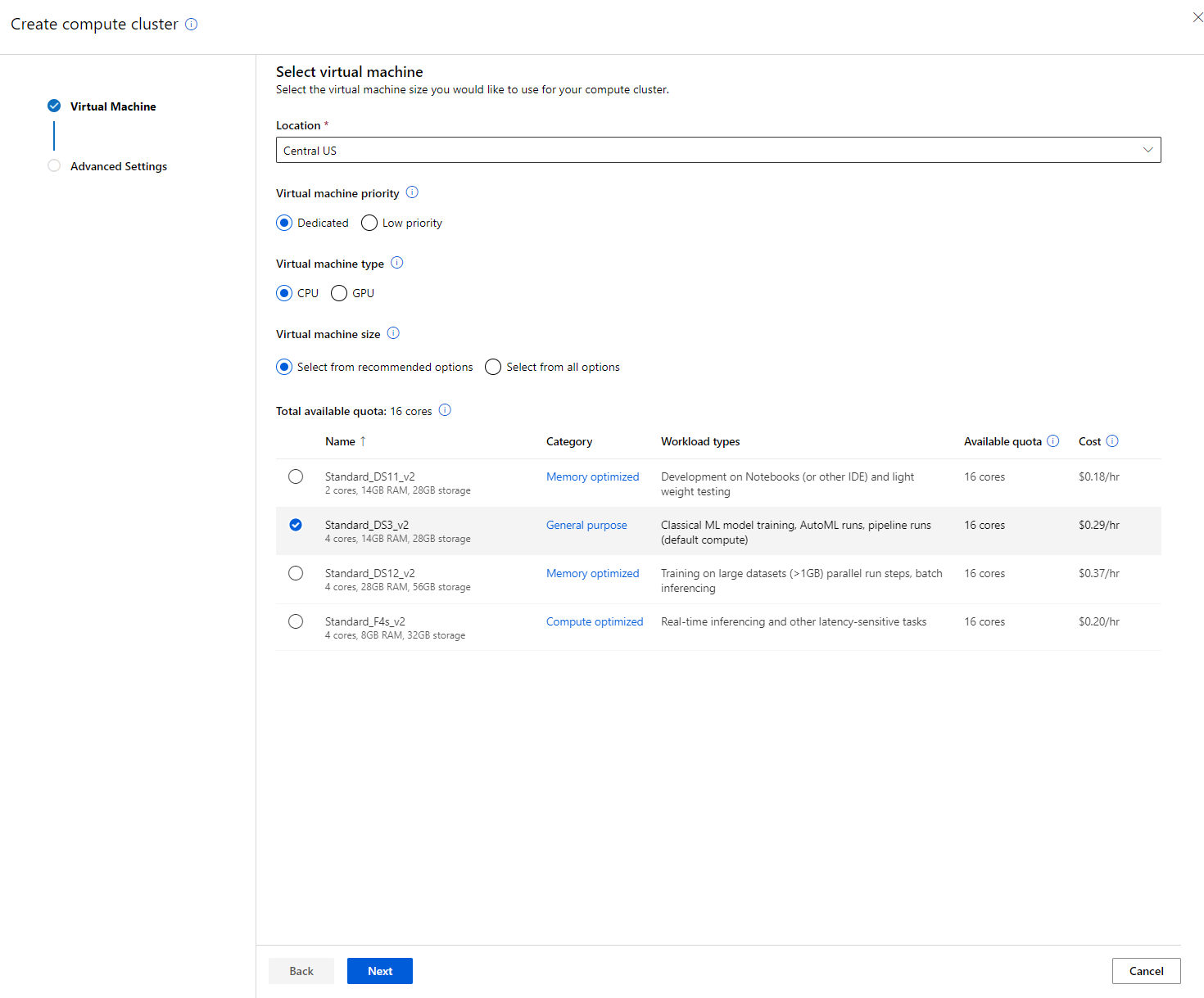
- ਕਲੱਸਟਰ ਨੂੰ ਇੱਕ compute name ਦਿਓ।
- ਆਪਣੇ ਵਿਕਲਪ ਚੁਣੋ: Minimum/Maximum nodes ਦੀ ਗਿਣਤੀ, Idle seconds before scale down, SSH access। ਧਿਆਨ ਦਿਓ ਕਿ ਜੇ nodes ਦੀ ਘੱਟੋ-ਘੱਟ ਗਿਣਤੀ 0 ਹੈ, ਤਾਂ ਤੁਸੀਂ ਕਲੱਸਟਰ idle ਹੋਣ 'ਤੇ ਪੈਸਾ ਬਚਾ ਸਕਦੇ ਹੋ। ਧਿਆਨ ਦਿਓ ਕਿ nodes ਦੀ ਵੱਧ ਤੋਂ ਵੱਧ ਗਿਣਤੀ ਜਿੰਨੀ ਉੱਚੀ ਹੋਵੇਗੀ, ਟ੍ਰੇਨਿੰਗ ਉਤਨੀ ਛੋਟੀ ਹੋਵੇਗੀ। ਵੱਧ ਤੋਂ ਵੱਧ nodes ਦੀ ਸਿਫਾਰਸ਼ੀ ਗਿਣਤੀ 3 ਹੈ।
- "Create" ਬਟਨ 'ਤੇ ਕਲਿੱਕ ਕਰੋ। ਇਹ ਕਦਮ ਕੁਝ ਮਿੰਟ ਲੈ ਸਕਦਾ ਹੈ।
ਸ਼ਾਨਦਾਰ! ਹੁਣ ਜਦੋਂ ਕਿ ਸਾਡੇ ਕੋਲ ਇੱਕ Compute cluster ਹੈ, ਸਾਨੂੰ ਡਾਟਾ ਨੂੰ Azure ML Studio ਵਿੱਚ ਲੋਡ ਕਰਨ ਦੀ ਲੋੜ ਹੈ।
2.3 ਡਾਟਾਸੈਟ ਲੋਡ ਕਰਨਾ
-
Azure ML workspace ਵਿੱਚ ਜੋ ਅਸੀਂ ਪਹਿਲਾਂ ਬਣਾਇਆ ਸੀ, "Datasets" 'ਤੇ ਕਲਿੱਕ ਕਰੋ ਅਤੇ "+ Create dataset" ਬਟਨ 'ਤੇ ਕਲਿੱਕ ਕਰਕੇ ਇੱਕ ਡਾਟਾਸੈਟ ਬਣਾਓ। "From local files" ਵਿਕਲਪ ਚੁਣੋ ਅਤੇ Kaggle ਡਾਟਾਸੈਟ ਨੂੰ ਚੁਣੋ ਜੋ ਅਸੀਂ ਪਹਿਲਾਂ ਡਾਊਨਲੋਡ ਕੀਤਾ ਸੀ।
-
ਆਪਣੇ ਡਾਟਾਸੈਟ ਨੂੰ ਇੱਕ name, type ਅਤੇ description ਦਿਓ। Next 'ਤੇ ਕਲਿੱਕ ਕਰੋ। ਫਾਈਲਾਂ ਤੋਂ ਡਾਟਾ ਅੱਪਲੋਡ ਕਰੋ। Next 'ਤੇ ਕਲਿੱਕ ਕਰੋ।
-
Schema ਵਿੱਚ, anaemia, diabetes, high blood pressure, sex, smoking, ਅਤੇ DEATH_EVENT ਲਈ ਡਾਟਾ type ਨੂੰ Boolean ਵਿੱਚ ਬਦਲੋ। Next 'ਤੇ ਕਲਿੱਕ ਕਰੋ ਅਤੇ Create 'ਤੇ ਕਲਿੱਕ ਕਰੋ।
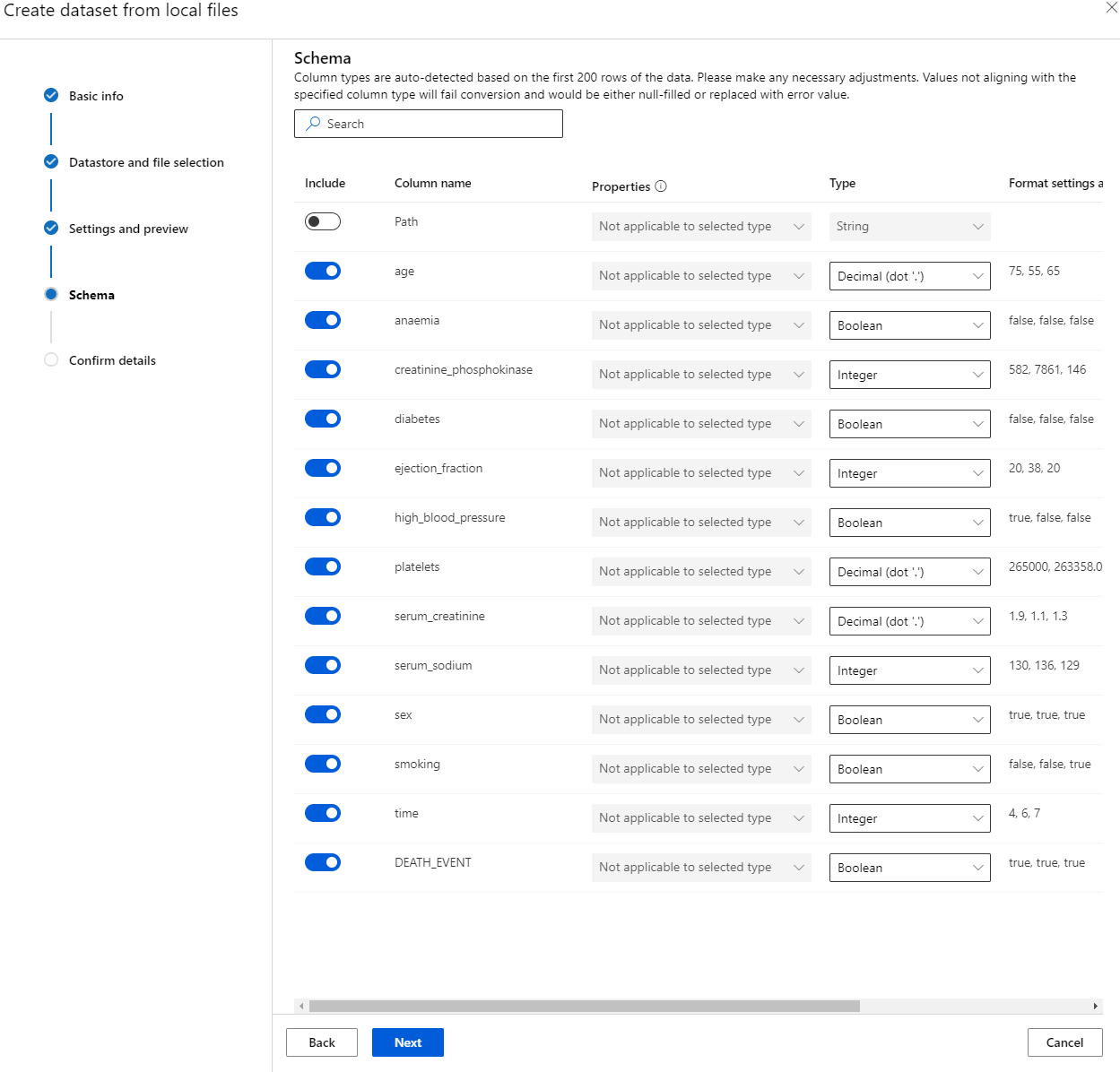
ਸ਼ਾਨਦਾਰ! ਹੁਣ ਜਦੋਂ ਕਿ ਡਾਟਾਸੈਟ ਜਗ੍ਹਾ 'ਤੇ ਹੈ ਅਤੇ ਕੰਪਿਊਟ ਕਲੱਸਟਰ ਬਣਾਇਆ ਗਿਆ ਹੈ, ਅਸੀਂ ਮਾਡਲ ਦੀ ਟ੍ਰੇਨਿੰਗ ਸ਼ੁਰੂ ਕਰ ਸਕਦੇ ਹਾਂ!
2.4 Low code/No Code ਟ੍ਰੇਨਿੰਗ AutoML ਨਾਲ
ਪ੍ਰੰਪਰਾਗਤ ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਮਾਡਲ ਵਿਕਾਸ ਸਰੋਤ-ਗਹਿਰਾ ਹੁੰਦਾ ਹੈ, ਜਿਸ ਵਿੱਚ ਕਈ ਮਾਡਲਾਂ ਨੂੰ ਤਿਆਰ ਕਰਨ ਅਤੇ ਤੁਲਨਾ ਕਰਨ ਲਈ ਮਹੱਤਵਪੂਰਨ ਡੋਮੇਨ ਗਿਆਨ ਅਤੇ ਸਮੇਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। Automated machine learning (AutoML) ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਮਾਡਲ ਵਿਕਾਸ ਦੇ ਸਮਾਂ-ਖਪਤ, ਦੁਹਰਾਏ ਜਾਣ ਵਾਲੇ ਕੰਮਾਂ ਨੂੰ ਆਟੋਮੈਟ ਕਰਨ ਦੀ ਪ੍ਰਕਿਰਿਆ ਹੈ। ਇਹ ਡਾਟਾ ਸਾਇੰਟਿਸਟਾਂ, ਵਿਸ਼ਲੇਸ਼ਕਾਂ ਅਤੇ ਡਿਵੈਲਪਰਾਂ ਨੂੰ ਉੱਚ ਪੈਮਾਨੇ, ਕੁਸ਼ਲਤਾ ਅਤੇ ਉਤਪਾਦਕਤਾ ਨਾਲ ML ਮਾਡਲ ਬਣਾਉਣ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ, ਸਾਰੇ ਮਾਡਲ ਗੁਣਵੱਤਾ ਨੂੰ ਕਾਇਮ ਰੱਖਦੇ ਹੋਏ। ਹੋਰ ਜਾਣੋ
-
Azure ML workspace ਵਿੱਚ ਜੋ ਅਸੀਂ ਪਹਿਲਾਂ ਬਣਾਇਆ ਸੀ, "Automated ML" 'ਤੇ ਕਲਿੱਕ ਕਰੋ ਅਤੇ ਉਹ ਡਾਟਾਸੈਟ ਚੁਣੋ ਜੋ ਤੁਸੀਂ ਹੁਣੇ ਅੱਪਲੋਡ ਕੀਤਾ ਸੀ। Next 'ਤੇ ਕਲਿੱਕ ਕਰੋ।
-
ਇੱਕ ਨਵਾਂ experiment name, target column (DEATH_EVENT) ਅਤੇ ਉਹ compute cluster ਦਾਖਲ ਕਰੋ ਜੋ ਅਸੀਂ ਬਣਾਇਆ ਸੀ। Next 'ਤੇ ਕਲਿੱਕ ਕਰੋ।
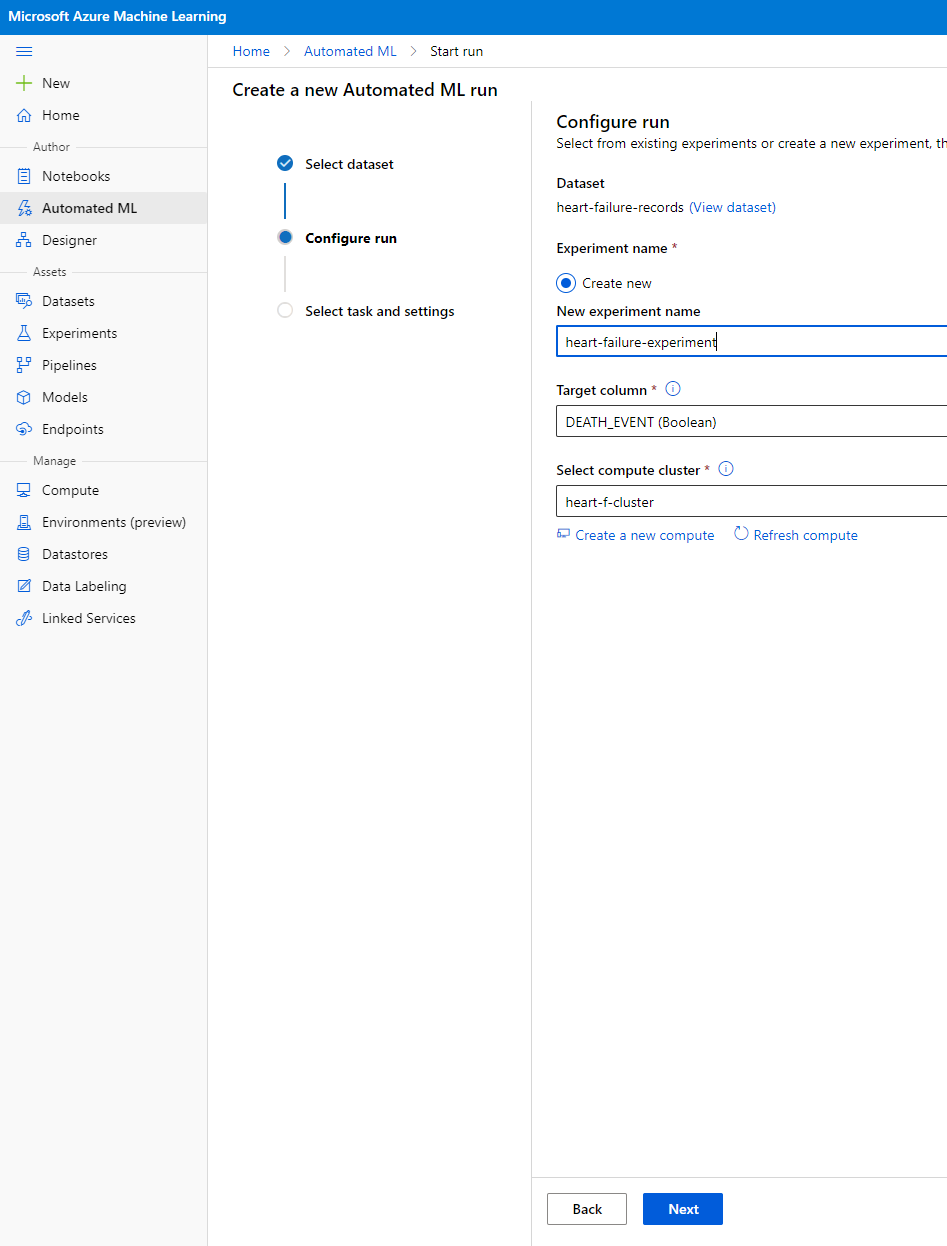
-
"Classification" ਚੁਣੋ ਅਤੇ Finish 'ਤੇ ਕਲਿੱਕ ਕਰੋ। ਇਹ ਕਦਮ 30 ਮਿੰਟ ਤੋਂ 1 ਘੰਟੇ ਦੇ ਵਿਚਕਾਰ ਲੈ ਸਕਦਾ ਹੈ, ਤੁਹਾਡੇ compute cluster ਦੇ ਆਕਾਰ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ।
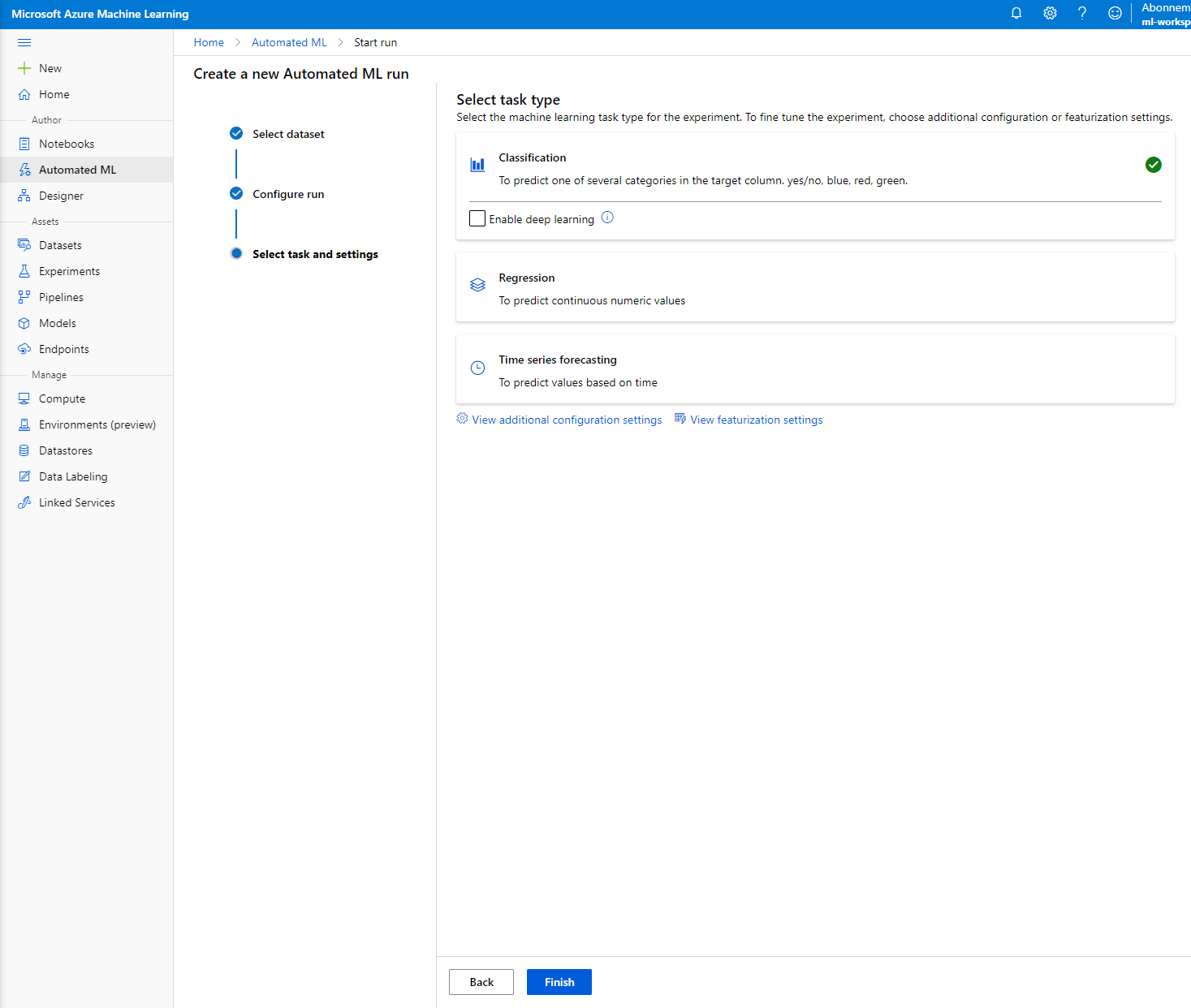
-
ਜਦੋਂ run ਪੂਰਾ ਹੋ ਜਾਂਦਾ ਹੈ, "Automated ML" ਟੈਬ 'ਤੇ ਕਲਿੱਕ ਕਰੋ, ਆਪਣੇ run 'ਤੇ ਕਲਿੱਕ ਕਰੋ, ਅਤੇ "Best model summary" ਕਾਰਡ ਵਿੱਚ Algorithm 'ਤੇ ਕਲਿੱਕ ਕਰੋ।
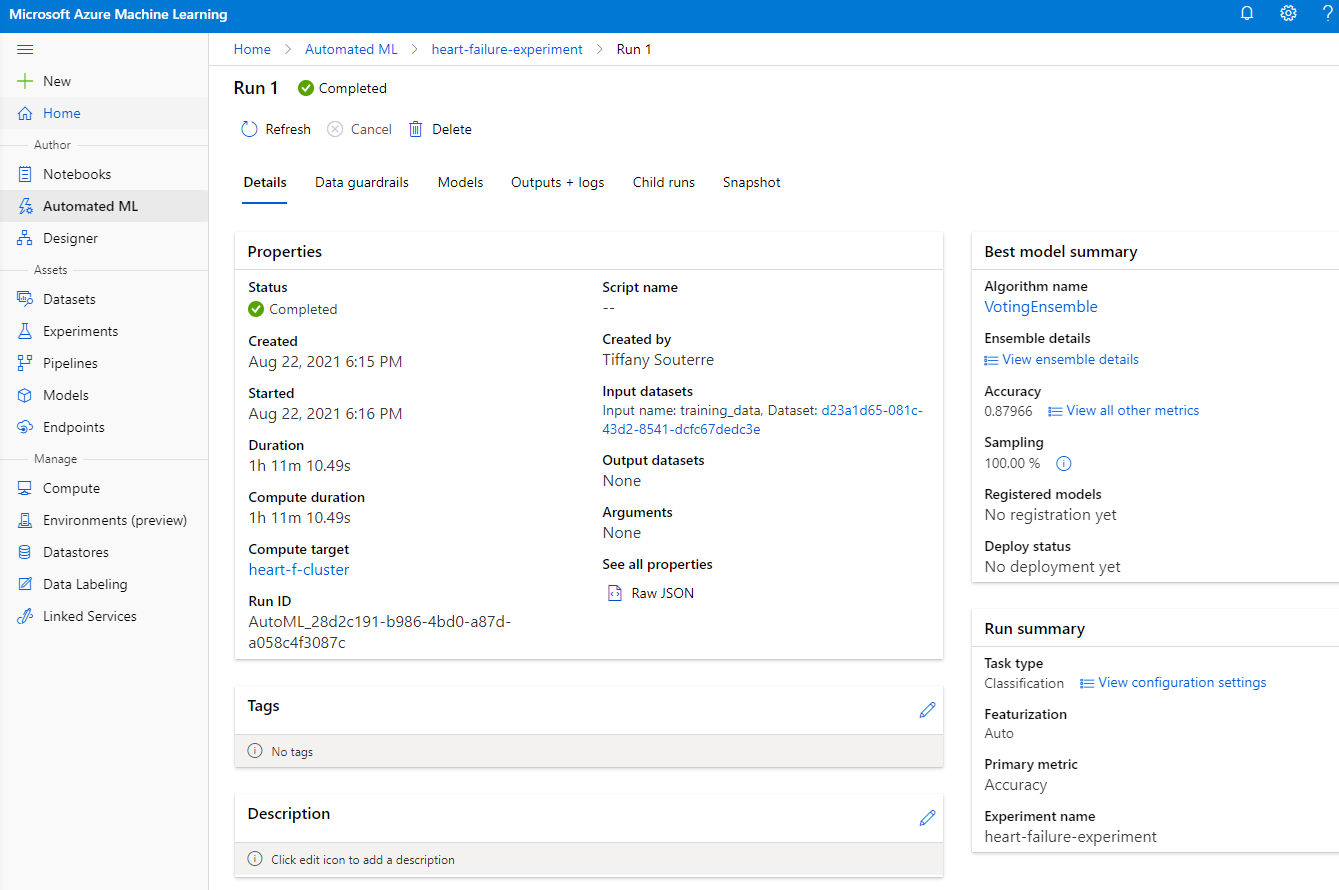
ਇੱਥੇ ਤੁਸੀਂ AutoML ਦੁਆਰਾ ਤਿਆਰ ਕੀਤੇ ਗਏ ਸਭ ਤੋਂ ਵਧੀਆ ਮਾਡਲ ਦਾ ਵਿਸਤ੍ਰਿਤ ਵੇਰਵਾ ਦੇਖ ਸਕਦੇ ਹੋ। ਤੁਸੀਂ Models ਟੈਬ ਵਿੱਚ ਹੋਰ ਮਾਡਲਾਂ ਦੀ ਵੀ ਖੋਜ ਕਰ ਸਕਦੇ ਹੋ। Explanations (preview button) ਵਿੱਚ ਮਾਡਲਾਂ ਦੀ ਖੋਜ ਕਰਨ ਲਈ ਕੁਝ ਮਿੰਟ ਲਓ। ਜਦੋਂ ਤੁਸੀਂ ਉਹ ਮਾਡਲ ਚੁਣ ਲੈਂਦੇ ਹੋ ਜੋ ਤੁਸੀਂ ਵਰਤਣਾ ਚਾਹੁੰਦੇ ਹੋ (ਇੱਥੇ ਅਸੀਂ AutoML ਦੁਆਰਾ ਚੁਣੇ ਗਏ ਸਭ ਤੋਂ ਵਧੀਆ ਮਾਡਲ ਨੂੰ ਚੁਣਾਂਗੇ), ਅਸੀਂ ਦੇਖਾਂਗੇ ਕਿ ਅਸੀਂ ਇਸਨੂੰ deploy ਕਿਵੇਂ ਕਰ ਸਕਦੇ ਹਾਂ।
3. Low code/No Code ਮਾਡਲ deployment ਅਤੇ endpoint consumption
3.1 ਮਾਡਲ deployment
Automated machine learning interface ਤੁਹਾਨੂੰ ਸਭ ਤੋਂ ਵਧੀਆ ਮਾਡਲ ਨੂੰ ਕੁਝ ਕਦਮਾਂ ਵਿੱਚ ਇੱਕ web service ਵਜੋਂ deploy ਕਰਨ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ। Deployment ਮਾਡਲ ਦੇ ਇੰਟੀਗ੍ਰੇਸ਼ਨ ਦਾ ਮਤਲਬ ਹੈ ਤਾਂ ਜੋ ਇਹ ਨਵੇਂ ਡਾਟਾ ਦੇ ਅਧਾਰ 'ਤੇ ਅਨੁਮਾਨ ਲਗਾ ਸਕੇ ਅਤੇ ਸੰਭਾਵਿਤ ਮੌਕਿਆਂ ਦੇ ਖੇਤਰਾਂ ਦੀ ਪਛਾਣ ਕਰ ਸਕੇ। ਇਸ ਪ੍ਰੋਜੈਕਟ ਲਈ, ਇੱਕ web service 'ਤੇ deployment ਦਾ ਮਤਲਬ ਹੈ ਕਿ ਮੈਡੀਕਲ ਐਪਲੀਕੇਸ਼ਨ ਮਾਡਲ ਨੂੰ ਵਰਤ ਸਕਣਗੇ ਤਾਂ ਜੋ ਆਪਣੇ ਮਰੀਜ਼ਾਂ ਦੇ ਦਿਲ ਦੇ ਦੌਰੇ ਦੇ ਖਤਰੇ ਦੀ live prediction ਕਰ ਸਕਣ।
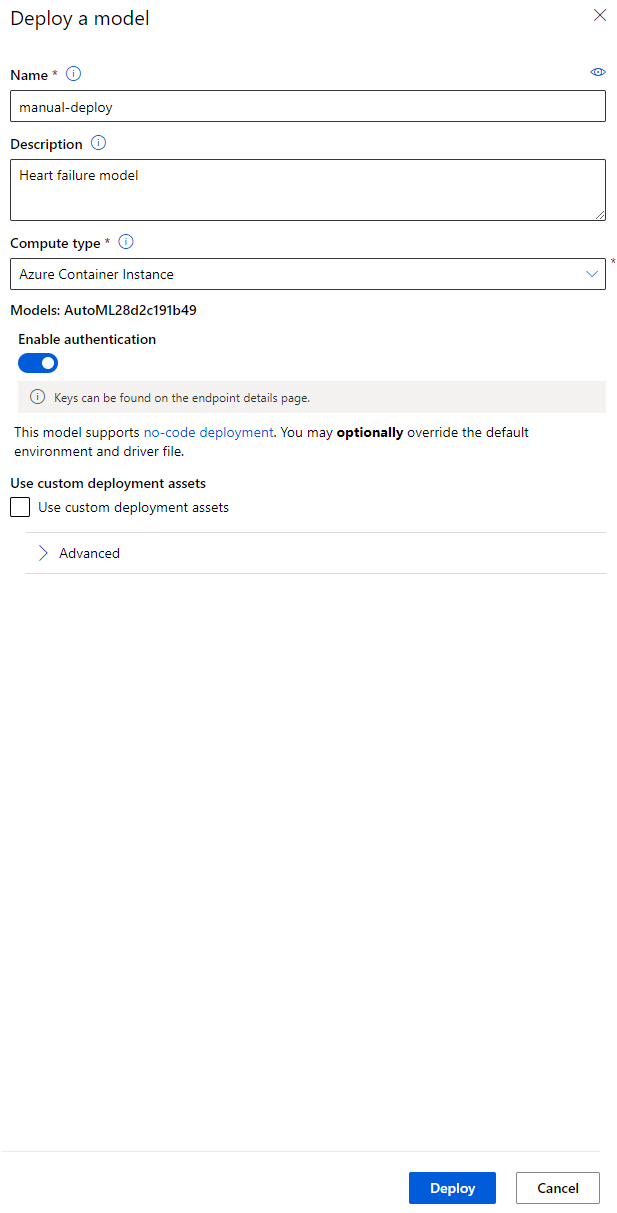
Best model description ਵਿੱਚ, "Deploy" ਬਟਨ 'ਤੇ ਕਲਿੱਕ ਕਰੋ।
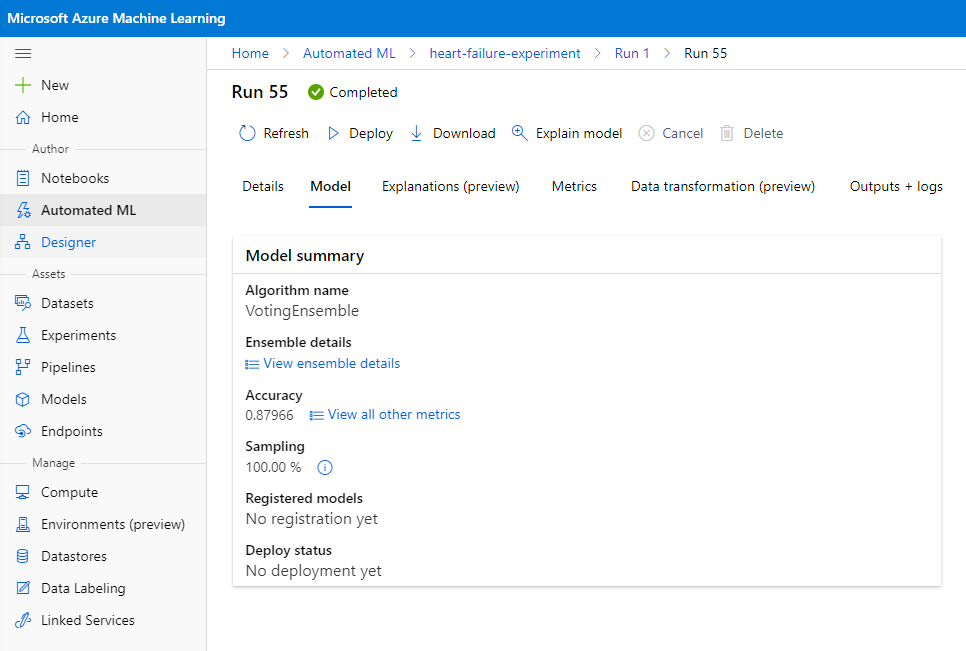
- ਇਸਨੂੰ ਇੱਕ name, description, compute type (Azure Container Instance) ਦਿਓ, authentication enable ਕਰੋ ਅਤੇ Deploy 'ਤੇ ਕਲਿੱਕ ਕਰੋ। ਇਹ ਕਦਮ ਪੂਰਾ ਹੋਣ ਵਿੱਚ ਲਗਭਗ 20 ਮਿੰਟ ਲੈ ਸਕਦਾ ਹੈ। Deployment ਪ੍ਰਕਿਰਿਆ ਵਿੱਚ ਕਈ ਕਦਮ ਸ਼ਾਮਲ ਹਨ ਜਿਵੇਂ ਕਿ ਮਾਡਲ ਨੂੰ register ਕਰਨਾ, ਸਰੋਤਾਂ ਨੂੰ ਤਿਆਰ ਕਰਨਾ, ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ web service ਲਈ configure ਕਰਨਾ। Deploy status ਦੇ ਹੇਠਾਂ ਇੱਕ status message ਦਿਖਾਈ ਦਿੰਦੀ ਹੈ। Deployment status ਦੀ ਜਾਂਚ ਕਰਨ ਲਈ Refresh ਨੂੰ ਸਮਯਸਮਯ 'ਤੇ ਚੁਣੋ। ਜਦੋਂ status "Healthy" ਹੁੰਦਾ ਹੈ, ਤਾਂ ਇਹ deploy ਅਤੇ running ਹੁੰਦਾ ਹੈ।
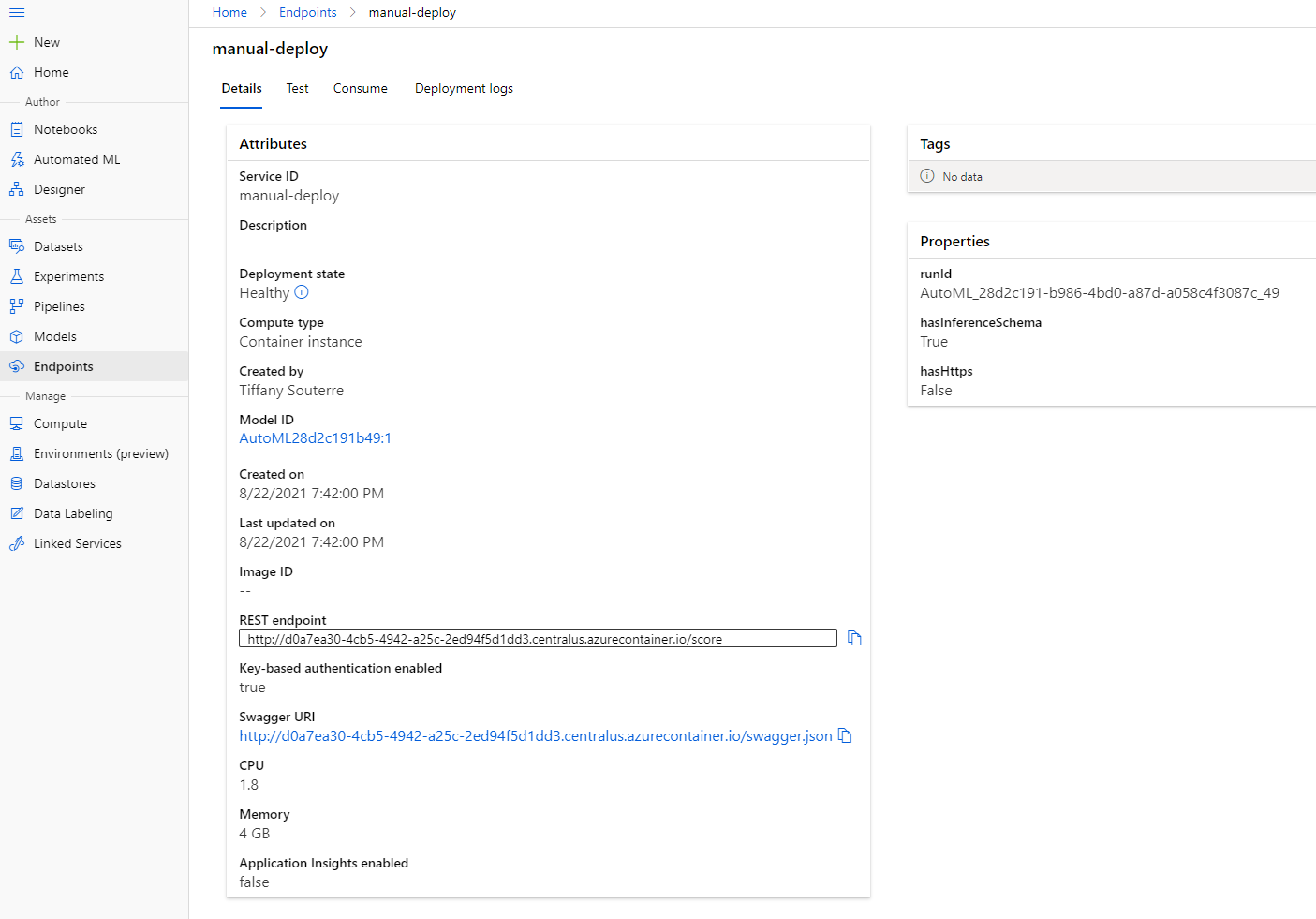
- ਜਦੋਂ ਇਹ deploy ਹੋ ਜਾਂਦਾ ਹੈ, Endpoint ਟੈਬ 'ਤੇ ਕਲਿੱਕ ਕਰੋ ਅਤੇ ਉਸ endpoint 'ਤੇ ਕਲਿੱਕ ਕਰੋ ਜੋ ਤੁਸੀਂ ਹੁਣੇ deploy ਕੀਤਾ ਸੀ। ਇੱਥੇ ਤੁਸੀਂ endpoint ਬਾਰੇ ਸਾਰੇ ਵੇਰਵੇ ਪਾ ਸਕਦੇ ਹੋ।
ਸ਼ਾਨਦਾਰ! ਹੁਣ ਜਦੋਂ ਕਿ ਸਾਡੇ ਕੋਲ ਇੱਕ ਮਾਡਲ deploy ਹੋ ਗਿਆ ਹੈ, ਅਸੀਂ endpoint ਦੀ consumption ਸ਼ੁਰੂ ਕਰ ਸਕਦੇ ਹਾਂ।
3.2 Endpoint consumption
"Consume" ਟੈਬ 'ਤੇ ਕਲਿੱਕ ਕਰੋ। ਇੱਥੇ ਤੁਸੀਂ REST endpoint ਅਤੇ consumption option ਵਿੱਚ ਇੱਕ python script ਪਾ ਸਕਦੇ ਹੋ। python code ਨੂੰ ਪੜ੍ਹਨ ਲਈ ਕੁਝ ਸਮਾਂ ਲਓ।
ਇਹ script ਸਿੱਧੇ ਤੁਹਾਡੇ local machine ਤੋਂ ਚਲਾਇਆ ਜਾ ਸਕਦਾ ਹੈ ਅਤੇ ਤੁਹਾਡੇ endpoint ਨੂੰ consume ਕਰੇਗਾ।
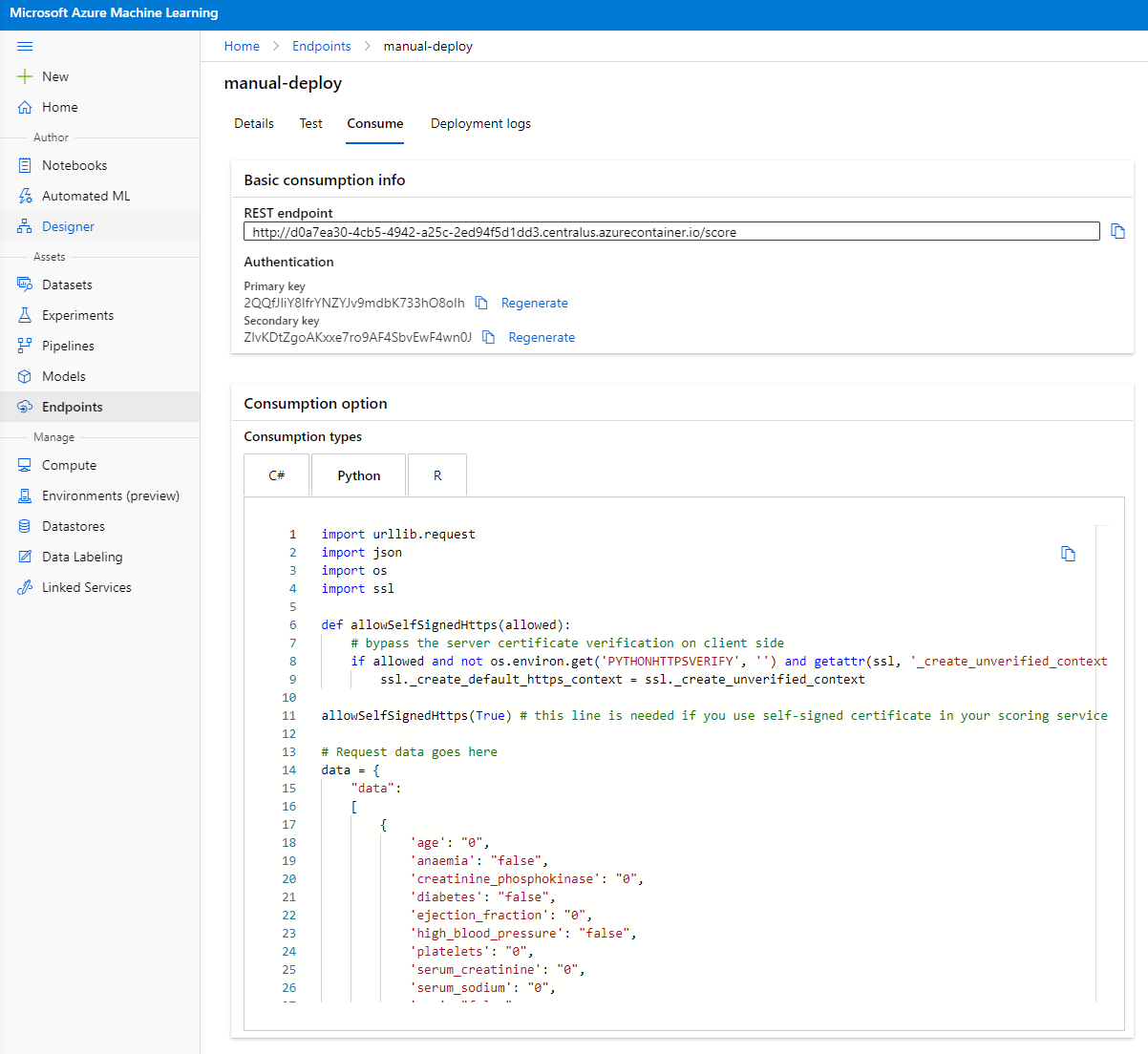
ਇਹ script ਦੇ ਇਹ 2 lines of code ਨੂੰ ਚੰਗੀ ਤਰ੍ਹਾਂ ਦੇਖੋ:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
url variable consume tab ਵਿੱਚ ਮਿਲੇ REST endpoint ਹੈ ਅਤੇ api_key variable consume tab ਵਿੱਚ ਮਿਲੀ primary key ਹੈ (ਸਿਰਫ ਉਸ ਸਥਿਤੀ ਵਿੱਚ ਜਦੋਂ ਤੁਸੀਂ authentication enable ਕੀਤਾ ਹੈ)। ਇਹ script endpoint ਨੂੰ consume ਕਰਨ ਦਾ ਤਰੀਕਾ ਹੈ।
- script ਚਲਾਉਣ 'ਤੇ, ਤੁਹਾਨੂੰ ਹੇਠਾਂ ਦਿੱਤਾ output ਦੇਖਣਾ ਚਾਹੀਦਾ ਹੈ:
b'"{\\"result\\": [true]}"'
ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਦਿੱਤੇ ਗਏ ਡਾਟਾ ਲਈ heart failure ਦੀ prediction ਸੱਚ ਹੈ। ਇਹ ਸਮਝਦਾਰ ਹੈ ਕਿਉਂਕਿ ਜੇ ਤੁਸੀਂ script ਵਿੱਚ ਆਟੋਮੈਟਿਕ ਤੌਰ 'ਤੇ ਜਨਰੇਟ ਕੀਤੇ ਡਾਟਾ ਨੂੰ ਧਿਆਨ ਨਾਲ ਦੇਖੋ, ਤਾਂ ਸਭ ਕੁਝ ਡਿਫਾਲਟ ਤੌਰ 'ਤੇ 0 ਅਤੇ false ਹੈ। ਤੁਸੀਂ ਹੇਠਾਂ ਦਿੱਤੇ input sample ਨਾਲ ਡਾਟਾ ਬਦਲ ਸਕਦੇ ਹੋ:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
script ਇਹ return ਕਰੇਗਾ:
python b'"{\\"result\\": [true, false]}"'
ਮੁਬਾਰਕਾਂ! ਤੁਸੀਂ ਮਾਡਲ ਨੂੰ deploy ਕੀਤਾ, consume ਕੀਤਾ ਅਤੇ Azure ML 'ਤੇ train ਕੀਤਾ!
NOTE: ਜਦੋਂ ਤੁਸੀਂ ਪ੍ਰੋਜੈਕਟ ਪੂਰਾ ਕਰ ਲੈਂਦੇ ਹੋ, ਤਾਂ ਸਾਰੇ ਸਰੋਤਾਂ ਨੂੰ delete ਕਰਨਾ ਨਾ ਭੁੱਲੋ।
🚀 ਚੈਲੈਂਜ
AutoML ਦੁਆਰਾ ਜਨਰੇਟ ਕੀਤੇ top models ਲਈ ਮਾਡਲ explanations ਅਤੇ ਵੇਰਵਿਆਂ ਨੂੰ ਧਿਆਨ ਨਾਲ ਦੇਖੋ। ਸਮਝਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰੋ ਕਿ ਸਭ ਤੋਂ ਵਧੀਆ ਮਾਡਲ ਹੋਰਾਂ ਨਾਲੋਂ ਕਿਉਂ ਵਧੀਆ ਹੈ। ਕਿਹੜੇ algorithms ਦੀ ਤੁਲਨਾ ਕੀਤੀ ਗਈ? ਉਨ੍ਹਾਂ ਵਿੱਚ ਕੀ ਅੰਤਰ ਹਨ? ਇਸ ਮਾਮਲੇ ਵਿੱਚ ਸਭ ਤੋਂ ਵਧੀਆ ਮਾਡਲ ਕਿਉਂ ਵਧੀਆ ਪ੍ਰਦਰਸ਼ਨ ਕਰ ਰਿਹਾ ਹੈ?
Post-lecture quiz
Review & Self Study
ਇਸ ਪਾਠ ਵਿੱਚ, ਤੁਸੀਂ ਸਿੱਖਿਆ ਕਿ ਕਿਵੇਂ train, deploy ਅਤੇ consume ਕਰਨਾ ਹੈ ਇੱਕ ਮਾਡਲ ਨੂੰ ਦਿਲ ਦੇ ਦੌਰੇ ਦੇ ਖਤਰੇ ਦੀ prediction ਕਰਨ ਲਈ Low code/No code ਤਰੀਕੇ ਨਾਲ cloud ਵਿੱਚ। ਜੇ ਤੁਸੀਂ ਇਹ ਨਹੀਂ ਕੀਤਾ ਹੈ, ਤਾਂ AutoML ਦੁਆਰਾ ਜਨਰੇਟ ਕੀਤੇ top models ਲਈ ਮਾਡਲ explanations ਵਿੱਚ ਡੂੰਘਾਈ ਨਾਲ ਜਾਓ ਅਤੇ ਸਮਝਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰੋ ਕਿ ਸਭ ਤੋਂ ਵਧੀਆ ਮਾਡਲ ਹੋਰਾਂ ਨਾਲੋਂ ਕਿਉਂ ਵਧੀਆ ਹੈ।
ਤੁਸੀਂ Low code/No code AutoML ਵਿੱਚ ਹੋਰ ਅੱਗੇ ਜਾ ਸਕਦੇ ਹੋ ਇਸ documentation ਨੂੰ ਪੜ੍ਹ ਕੇ।
Assignment
Low code/No code Data Science project on Azure ML
ਅਸਵੀਕਤੀ:
ਇਹ ਦਸਤਾਵੇਜ਼ AI ਅਨੁਵਾਦ ਸੇਵਾ Co-op Translator ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਅਨੁਵਾਦ ਕੀਤਾ ਗਿਆ ਹੈ। ਜਦੋਂ ਕਿ ਅਸੀਂ ਸਹੀ ਹੋਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਾਂ, ਕਿਰਪਾ ਕਰਕੇ ਧਿਆਨ ਦਿਓ ਕਿ ਸਵੈਚਾਲਿਤ ਅਨੁਵਾਦਾਂ ਵਿੱਚ ਗਲਤੀਆਂ ਜਾਂ ਅਸੁਚਤਤਾਵਾਂ ਹੋ ਸਕਦੀਆਂ ਹਨ। ਮੂਲ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਇਸਦੀ ਮੂਲ ਭਾਸ਼ਾ ਵਿੱਚ ਅਧਿਕਾਰਤ ਸਰੋਤ ਮੰਨਿਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ। ਮਹੱਤਵਪੂਰਨ ਜਾਣਕਾਰੀ ਲਈ, ਪੇਸ਼ੇਵਰ ਮਨੁੱਖੀ ਅਨੁਵਾਦ ਦੀ ਸਿਫਾਰਸ਼ ਕੀਤੀ ਜਾਂਦੀ ਹੈ। ਇਸ ਅਨੁਵਾਦ ਦੀ ਵਰਤੋਂ ਤੋਂ ਪੈਦਾ ਹੋਣ ਵਾਲੇ ਕਿਸੇ ਵੀ ਗਲਤਫਹਿਮੀ ਜਾਂ ਗਲਤ ਵਿਆਖਿਆ ਲਈ ਅਸੀਂ ਜ਼ਿੰਮੇਵਾਰ ਨਹੀਂ ਹਾਂ।