|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 3 weeks ago | |
README.md
ਰਿਸ਼ਤਿਆਂ ਦੀ ਦ੍ਰਿਸ਼ਟੀਕਰਨ: ਸ਼ਹਿਦ ਬਾਰੇ ਸਭ ਕੁਝ 🍯
| ਰਿਸ਼ਤਿਆਂ ਦੀ ਦ੍ਰਿਸ਼ਟੀਕਰਨ - @nitya ਦੁਆਰਾ ਸਕੈਚਨੋਟ |
ਸਾਡੇ ਖੋਜ ਦੇ ਕੁਦਰਤੀ ਧਿਆਨ ਨੂੰ ਜਾਰੀ ਰੱਖਦੇ ਹੋਏ, ਆਓ ਅਜਿਹੀਆਂ ਦ੍ਰਿਸ਼ਟੀਕਰਨਾਂ ਦੀ ਖੋਜ ਕਰੀਏ ਜੋ ਸ਼ਹਿਦ ਦੇ ਵੱਖ-ਵੱਖ ਕਿਸਮਾਂ ਦੇ ਰਿਸ਼ਤਿਆਂ ਨੂੰ ਦਰਸਾਉਂਦੀਆਂ ਹਨ। ਇਹ ਡਾਟਾਸੈੱਟ ਯੂਨਾਈਟਡ ਸਟੇਟਸ ਡਿਪਾਰਟਮੈਂਟ ਆਫ ਐਗਰੀਕਲਚਰ ਤੋਂ ਲਿਆ ਗਿਆ ਹੈ।
ਇਹ ਡਾਟਾਸੈੱਟ ਲਗਭਗ 600 ਆਈਟਮਾਂ ਦਾ ਹੈ ਜੋ ਕਈ ਅਮਰੀਕੀ ਰਾਜਾਂ ਵਿੱਚ ਸ਼ਹਿਦ ਦੇ ਉਤਪਾਦਨ ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ। ਉਦਾਹਰਣ ਲਈ, ਤੁਸੀਂ 1998-2012 ਦੇ ਸਮੇਂ ਵਿੱਚ ਕਿਸੇ ਦਿੱਤੇ ਗਏ ਰਾਜ ਵਿੱਚ ਸ਼ਹਿਦ ਦੇ ਉਤਪਾਦਨ ਦੀਆਂ ਕਾਲੋਨੀਆਂ ਦੀ ਗਿਣਤੀ, ਪ੍ਰਤੀ ਕਾਲੋਨੀ ਉਪਜ, ਕੁੱਲ ਉਤਪਾਦਨ, ਸਟਾਕ, ਪ੍ਰਤੀ ਪਾਉਂਡ ਕੀਮਤ ਅਤੇ ਸ਼ਹਿਦ ਦੀ ਕੀਮਤ ਦੇਖ ਸਕਦੇ ਹੋ। ਹਰ ਰਾਜ ਲਈ ਹਰ ਸਾਲ ਇੱਕ ਪੰਕਤੀ ਹੈ।
ਇਹ ਦ੍ਰਿਸ਼ਟੀਕਰਨ ਦਿਲਚਸਪ ਹੋਵੇਗਾ ਕਿ ਕਿਸੇ ਦਿੱਤੇ ਰਾਜ ਦੇ ਸਾਲਾਨਾ ਉਤਪਾਦਨ ਅਤੇ ਉਸ ਰਾਜ ਵਿੱਚ ਸ਼ਹਿਦ ਦੀ ਕੀਮਤ ਦੇ ਰਿਸ਼ਤੇ ਨੂੰ ਕਿਵੇਂ ਦਰਸਾਇਆ ਜਾ ਸਕਦਾ ਹੈ। ਇਸ ਤੋਂ ਇਲਾਵਾ, ਤੁਸੀਂ ਰਾਜਾਂ ਦੇ ਪ੍ਰਤੀ ਕਾਲੋਨੀ ਸ਼ਹਿਦ ਦੀ ਉਪਜ ਦੇ ਰਿਸ਼ਤੇ ਨੂੰ ਵੀ ਦ੍ਰਿਸ਼ਟੀਕਰਤ ਕਰ ਸਕਦੇ ਹੋ। ਇਹ ਸਾਲਾਂ ਦੀ ਰੇਂਜ 2006 ਵਿੱਚ ਪਹਿਲਾਂ ਵੱਖਰੀ 'ਕਾਲੋਨੀ ਕਾਲਾਪਸ ਡਿਸਆਰਡਰ' (http://npic.orst.edu/envir/ccd.html) ਦੇਖੀ ਗਈ ਨੂੰ ਕਵਰ ਕਰਦੀ ਹੈ, ਇਸ ਲਈ ਇਹ ਅਧਿਐਨ ਕਰਨ ਲਈ ਇੱਕ ਮਹੱਤਵਪੂਰਨ ਡਾਟਾਸੈੱਟ ਹੈ। 🐝
ਪ੍ਰੀ-ਲੈਕਚਰ ਕਵਿਜ਼
ਇਸ ਪਾਠ ਵਿੱਚ, ਤੁਸੀਂ ggplot2 ਵਰਤ ਸਕਦੇ ਹੋ, ਜਿਸ ਨੂੰ ਤੁਸੀਂ ਪਹਿਲਾਂ ਵਰਤ ਚੁੱਕੇ ਹੋ, ਜੋ ਵੈਰੀਏਬਲਾਂ ਦੇ ਰਿਸ਼ਤਿਆਂ ਨੂੰ ਦ੍ਰਿਸ਼ਟੀਕਰਤ ਕਰਨ ਲਈ ਇੱਕ ਵਧੀਆ ਲਾਇਬ੍ਰੇਰੀ ਹੈ। ਵਿਸ਼ੇਸ਼ ਤੌਰ 'ਤੇ ਦਿਲਚਸਪ ਹੈ ggplot2 ਦੇ geom_point ਅਤੇ qplot ਫੰਕਸ਼ਨ ਦੀ ਵਰਤੋਂ, ਜੋ ਸਕੈਟਰ ਪਲਾਟ ਅਤੇ ਲਾਈਨ ਪਲਾਟਾਂ ਨੂੰ 'ਸੰਖਿਆਕੀ ਰਿਸ਼ਤੇ' ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਦ੍ਰਿਸ਼ਟੀਕਰਤ ਕਰਨ ਦੀ ਆਗਿਆ ਦਿੰਦੇ ਹਨ, ਜੋ ਡਾਟਾ ਸਾਇੰਟਿਸਟ ਨੂੰ ਵੈਰੀਏਬਲਾਂ ਦੇ ਆਪਸੀ ਰਿਸ਼ਤਿਆਂ ਨੂੰ ਬਿਹਤਰ ਸਮਝਣ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ।
ਸਕੈਟਰਪਲਾਟ
ਸਕੈਟਰਪਲਾਟ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਦਰਸਾਓ ਕਿ ਸ਼ਹਿਦ ਦੀ ਕੀਮਤ ਸਾਲ ਦਰ ਸਾਲ, ਪ੍ਰਤੀ ਰਾਜ ਕਿਵੇਂ ਵਿਕਸਿਤ ਹੋਈ ਹੈ। ggplot2, ggplot ਅਤੇ geom_point ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋਏ, ਸਹੂਲਤ ਨਾਲ ਰਾਜਾਂ ਦੇ ਡਾਟਾ ਨੂੰ ਸਮੂਹਬੱਧ ਕਰਦਾ ਹੈ ਅਤੇ ਸ਼੍ਰੇਣੀਬੱਧ ਅਤੇ ਸੰਖਿਆਕੀ ਡਾਟਾ ਲਈ ਡਾਟਾ ਪੌਇੰਟ ਦਿਖਾਉਂਦਾ ਹੈ।
ਆਓ ਡਾਟਾ ਅਤੇ Seaborn ਨੂੰ ਇੰਪੋਰਟ ਕਰਕੇ ਸ਼ੁਰੂ ਕਰੀਏ:
honey=read.csv('../../data/honey.csv')
head(honey)
ਤੁਸੀਂ ਨੋਟ ਕਰਦੇ ਹੋ ਕਿ ਸ਼ਹਿਦ ਦੇ ਡਾਟਾ ਵਿੱਚ ਕਈ ਦਿਲਚਸਪ ਕਾਲਮ ਹਨ, ਜਿਵੇਂ ਕਿ ਸਾਲ ਅਤੇ ਪ੍ਰਤੀ ਪਾਉਂਡ ਕੀਮਤ। ਆਓ ਇਸ ਡਾਟਾ ਦੀ ਖੋਜ ਕਰੀਏ, ਜੋ ਅਮਰੀਕੀ ਰਾਜਾਂ ਦੁਆਰਾ ਸਮੂਹਬੱਧ ਹੈ:
| state | numcol | yieldpercol | totalprod | stocks | priceperlb | prodvalue | year |
|---|---|---|---|---|---|---|---|
| AL | 16000 | 71 | 1136000 | 159000 | 0.72 | 818000 | 1998 |
| AZ | 55000 | 60 | 3300000 | 1485000 | 0.64 | 2112000 | 1998 |
| AR | 53000 | 65 | 3445000 | 1688000 | 0.59 | 2033000 | 1998 |
| CA | 450000 | 83 | 37350000 | 12326000 | 0.62 | 23157000 | 1998 |
| CO | 27000 | 72 | 1944000 | 1594000 | 0.7 | 1361000 | 1998 |
| FL | 230000 | 98 | 22540000 | 4508000 | 0.64 | 14426000 | 1998 |
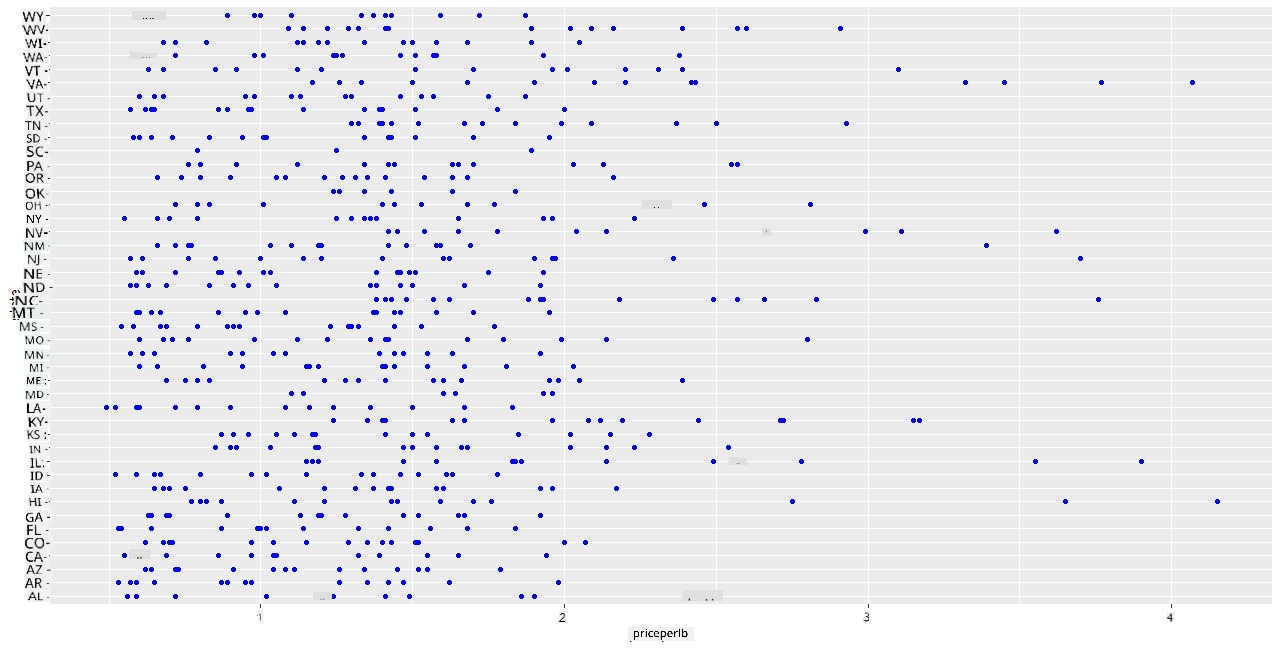
ਸ਼ਹਿਦ ਦੀ ਕੀਮਤ ਅਤੇ ਉਸ ਦੇ ਅਮਰੀਕੀ ਰਾਜ ਦੇ ਮੂਲ ਦੇ ਰਿਸ਼ਤੇ ਨੂੰ ਦਰਸਾਉਣ ਲਈ ਇੱਕ ਬੁਨਿਆਦੀ ਸਕੈਟਰਪਲਾਟ ਬਣਾਓ। y ਧੁਰੇ ਨੂੰ ਇੰਨਾ ਲੰਮਾ ਬਣਾਓ ਕਿ ਸਾਰੇ ਰਾਜ ਦਿਖਾਈ ਦੇ ਸਕਣ:
library(ggplot2)
ggplot(honey, aes(x = priceperlb, y = state)) +
geom_point(colour = "blue")
ਹੁਣ, ਸਾਲਾਂ ਦੇ ਦੌਰਾਨ ਸ਼ਹਿਦ ਦੀ ਕੀਮਤ ਕਿਵੇਂ ਵਿਕਸਿਤ ਹੁੰਦੀ ਹੈ, ਇਹ ਦਰਸਾਉਣ ਲਈ ਸ਼ਹਿਦ ਦੇ ਰੰਗ ਦੀ ਸਕੀਮ ਨਾਲ ਉਹੀ ਡਾਟਾ ਦਿਖਾਓ। ਤੁਸੀਂ ਇਹ 'scale_color_gradientn' ਪੈਰਾਮੀਟਰ ਸ਼ਾਮਲ ਕਰਕੇ ਕਰ ਸਕਦੇ ਹੋ ਜੋ ਸਾਲ ਦਰ ਸਾਲ ਬਦਲਾਅ ਦਿਖਾਉਂਦਾ ਹੈ:
✅ scale_color_gradientn ਬਾਰੇ ਹੋਰ ਸਿੱਖੋ - ਇੱਕ ਸੁੰਦਰ ਰੇਂਬੋ ਰੰਗ ਸਕੀਮ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰੋ!
ggplot(honey, aes(x = priceperlb, y = state, color=year)) +
geom_point()+scale_color_gradientn(colours = colorspace::heat_hcl(7))
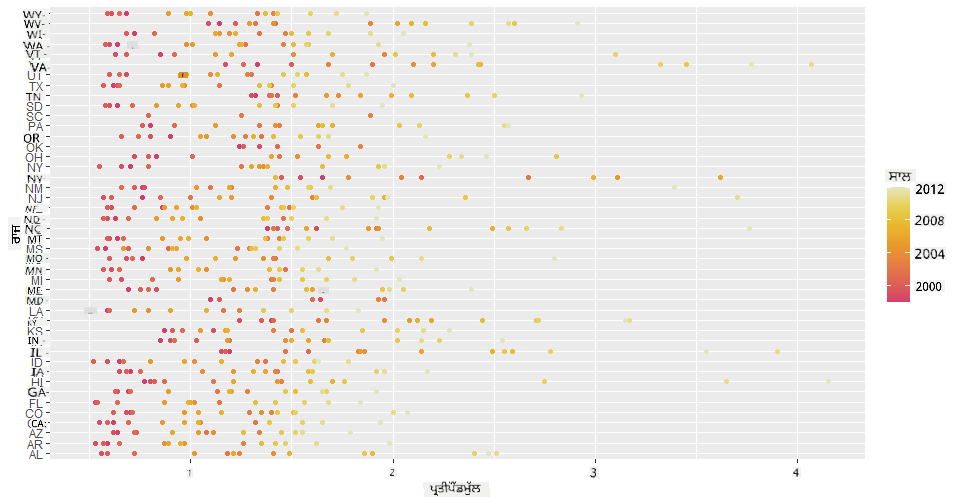
ਇਸ ਰੰਗ ਸਕੀਮ ਬਦਲਾਅ ਨਾਲ, ਤੁਸੀਂ ਦੇਖ ਸਕਦੇ ਹੋ ਕਿ ਸਾਲਾਂ ਦੇ ਦੌਰਾਨ ਸ਼ਹਿਦ ਦੀ ਕੀਮਤ ਪ੍ਰਤੀ ਪਾਉਂਡ ਵਿੱਚ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਇੱਕ ਮਜ਼ਬੂਤ ਤਰੱਕੀ ਹੈ। ਦਰਅਸਲ, ਜੇ ਤੁਸੀਂ ਡਾਟਾ ਵਿੱਚ ਇੱਕ ਨਮੂਨਾ ਸੈੱਟ ਦੀ ਜਾਂਚ ਕਰੋ (ਉਦਾਹਰਣ ਲਈ, ਅਰੀਜ਼ੋਨਾ ਨੂੰ ਚੁਣੋ) ਤਾਂ ਤੁਸੀਂ ਸਾਲ ਦਰ ਸਾਲ ਕੀਮਤ ਵਿੱਚ ਵਾਧੇ ਦਾ ਪੈਟਰਨ ਦੇਖ ਸਕਦੇ ਹੋ, ਕੁਝ ਛੋਟ ਦੇ ਨਾਲ:
| state | numcol | yieldpercol | totalprod | stocks | priceperlb | prodvalue | year |
|---|---|---|---|---|---|---|---|
| AZ | 55000 | 60 | 3300000 | 1485000 | 0.64 | 2112000 | 1998 |
| AZ | 52000 | 62 | 3224000 | 1548000 | 0.62 | 1999000 | 1999 |
| AZ | 40000 | 59 | 2360000 | 1322000 | 0.73 | 1723000 | 2000 |
| AZ | 43000 | 59 | 2537000 | 1142000 | 0.72 | 1827000 | 2001 |
| AZ | 38000 | 63 | 2394000 | 1197000 | 1.08 | 2586000 | 2002 |
| AZ | 35000 | 72 | 2520000 | 983000 | 1.34 | 3377000 | 2003 |
| AZ | 32000 | 55 | 1760000 | 774000 | 1.11 | 1954000 | 2004 |
| AZ | 36000 | 50 | 1800000 | 720000 | 1.04 | 1872000 | 2005 |
| AZ | 30000 | 65 | 1950000 | 839000 | 0.91 | 1775000 | 2006 |
| AZ | 30000 | 64 | 1920000 | 902000 | 1.26 | 2419000 | 2007 |
| AZ | 25000 | 64 | 1600000 | 336000 | 1.26 | 2016000 | 2008 |
| AZ | 20000 | 52 | 1040000 | 562000 | 1.45 | 1508000 | 2009 |
| AZ | 24000 | 77 | 1848000 | 665000 | 1.52 | 2809000 | 2010 |
| AZ | 23000 | 53 | 1219000 | 427000 | 1.55 | 1889000 | 2011 |
| AZ | 22000 | 46 | 1012000 | 253000 | 1.79 | 1811000 | 2012 |
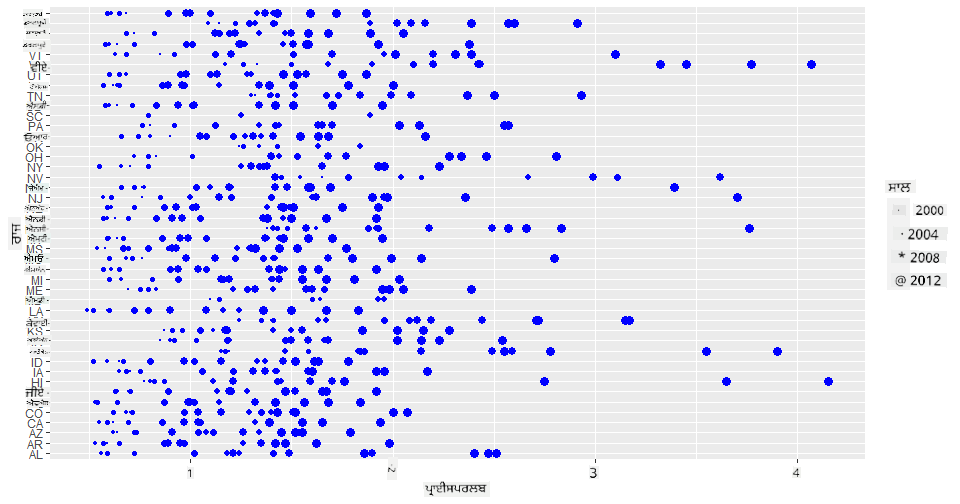
ਇਹ ਪ੍ਰਗਤੀ ਦ੍ਰਿਸ਼ਟੀਕਰਤ ਕਰਨ ਦਾ ਇੱਕ ਹੋਰ ਤਰੀਕਾ ਰੰਗ ਦੀ ਬਜਾਏ ਆਕਾਰ ਦੀ ਵਰਤੋਂ ਕਰਨਾ ਹੈ। ਰੰਗ-ਅੰਧੇ ਉਪਭੋਗਤਾਵਾਂ ਲਈ, ਇਹ ਇੱਕ ਬਿਹਤਰ ਵਿਕਲਪ ਹੋ ਸਕਦਾ ਹੈ। ਆਪਣੀ ਦ੍ਰਿਸ਼ਟੀਕਰਨ ਨੂੰ ਸੋਧੋ ਤਾਂ ਜੋ ਕੀਮਤ ਵਿੱਚ ਵਾਧੇ ਨੂੰ ਡਾਟ ਦੇ ਘੇਰੇ ਵਿੱਚ ਵਾਧੇ ਦੁਆਰਾ ਦਰਸਾਇਆ ਜਾ ਸਕੇ:
ggplot(honey, aes(x = priceperlb, y = state)) +
geom_point(aes(size = year),colour = "blue") +
scale_size_continuous(range = c(0.25, 3))
ਤੁਸੀਂ ਡਾਟ ਦੇ ਆਕਾਰ ਨੂੰ ਹੌਲੀ-ਹੌਲੀ ਵਧਦੇ ਹੋਏ ਦੇਖ ਸਕਦੇ ਹੋ।
ਕੀ ਇਹ ਸਪਲਾਈ ਅਤੇ ਡਿਮਾਂਡ ਦਾ ਸਧਾਰਨ ਮਾਮਲਾ ਹੈ? ਜਿਵੇਂ ਕਿ ਮੌਸਮ ਵਿੱਚ ਬਦਲਾਅ ਅਤੇ ਕਾਲੋਨੀ ਕਾਲਾਪਸ ਦੇ ਕਾਰਨ, ਕੀ ਸਾਲ ਦਰ ਸਾਲ ਖਰੀਦਣ ਲਈ ਘੱਟ ਸ਼ਹਿਦ ਉਪਲਬਧ ਹੈ, ਅਤੇ ਇਸ ਲਈ ਕੀਮਤ ਵਧਦੀ ਹੈ?
ਇਸ ਡਾਟਾਸੈੱਟ ਵਿੱਚ ਕੁਝ ਵੈਰੀਏਬਲਾਂ ਦੇ ਰਿਸ਼ਤੇ ਦੀ ਖੋਜ ਕਰਨ ਲਈ, ਆਓ ਕੁਝ ਲਾਈਨ ਚਾਰਟਾਂ ਦੀ ਖੋਜ ਕਰੀਏ।
ਲਾਈਨ ਚਾਰਟ
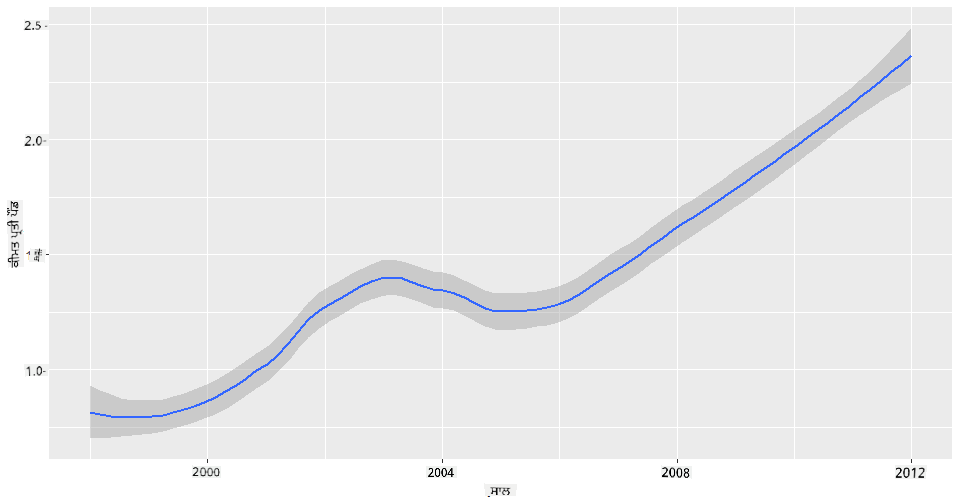
ਸਵਾਲ: ਕੀ ਸਾਲ ਦਰ ਸਾਲ ਸ਼ਹਿਦ ਦੀ ਕੀਮਤ ਵਿੱਚ ਸਪਸ਼ਟ ਵਾਧਾ ਹੈ? ਤੁਸੀਂ ਇਸ ਨੂੰ ਸਭ ਤੋਂ ਆਸਾਨੀ ਨਾਲ ਇੱਕ ਸਿੰਗਲ ਲਾਈਨ ਚਾਰਟ ਬਣਾਕੇ ਪਤਾ ਕਰ ਸਕਦੇ ਹੋ:
qplot(honey$year,honey$priceperlb, geom='smooth', span =0.5, xlab = "year",ylab = "priceperlb")
ਜਵਾਬ: ਹਾਂ, ਕੁਝ ਛੋਟਾਂ ਦੇ ਨਾਲ, 2003 ਦੇ ਆਸ-ਪਾਸ:
ਸਵਾਲ: ਖੈਰ, 2003 ਵਿੱਚ ਕੀ ਤੁਸੀਂ ਸ਼ਹਿਦ ਦੀ ਸਪਲਾਈ ਵਿੱਚ ਵੀ ਵਾਧਾ ਦੇਖ ਸਕਦੇ ਹੋ? ਜੇ ਤੁਸੀਂ ਸਾਲ ਦਰ ਸਾਲ ਕੁੱਲ ਉਤਪਾਦਨ ਨੂੰ ਦੇਖੋ ਤਾਂ ਕੀ ਹੋਵੇਗਾ?
qplot(honey$year,honey$totalprod, geom='smooth', span =0.5, xlab = "year",ylab = "totalprod")
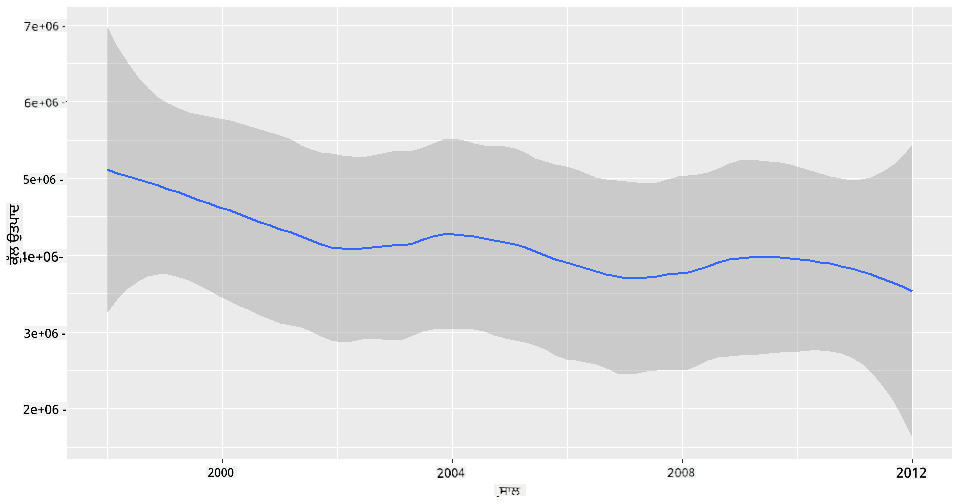
ਜਵਾਬ: ਸੱਚਮੁੱਚ ਨਹੀਂ। ਜੇ ਤੁਸੀਂ ਕੁੱਲ ਉਤਪਾਦਨ ਨੂੰ ਦੇਖੋ, ਤਾਂ ਇਹ ਵਿਸ਼ੇਸ਼ ਸਾਲ ਵਿੱਚ ਵਾਧਾ ਹੋਇਆ ਜਾਪਦਾ ਹੈ, ਹਾਲਾਂਕਿ ਆਮ ਤੌਰ 'ਤੇ ਸ਼ਹਿਦ ਦੇ ਉਤਪਾਦਨ ਦੀ ਮਾਤਰਾ ਇਨ੍ਹਾਂ ਸਾਲਾਂ ਦੌਰਾਨ ਘਟ ਰਹੀ ਹੈ।
ਸਵਾਲ: ਇਸ ਮਾਮਲੇ ਵਿੱਚ, 2003 ਦੇ ਆਸ-ਪਾਸ ਸ਼ਹਿਦ ਦੀ ਕੀਮਤ ਵਿੱਚ ਵਾਧੇ ਦਾ ਕਾਰਨ ਕੀ ਹੋ ਸਕਦਾ ਹੈ?
ਇਸ ਨੂੰ ਪਤਾ ਕਰਨ ਲਈ, ਤੁਸੀਂ ਇੱਕ ਫੈਸਿਟ ਗ੍ਰਿਡ ਦੀ ਖੋਜ ਕਰ ਸਕਦੇ ਹੋ।
ਫੈਸਿਟ ਗ੍ਰਿਡ
ਫੈਸਿਟ ਗ੍ਰਿਡ ਤੁਹਾਡੇ ਡਾਟਾਸੈੱਟ ਦੇ ਇੱਕ ਫੈਸਿਟ (ਸਾਡੇ ਮਾਮਲੇ ਵਿੱਚ, ਤੁਸੀਂ 'ਸਾਲ' ਚੁਣ ਸਕਦੇ ਹੋ ਤਾਂ ਕਿ ਬਹੁਤ ਜ਼ਿਆਦਾ ਫੈਸਿਟ ਨਾ ਬਣੇ) ਨੂੰ ਲੈਂਦਾ ਹੈ। Seaborn ਫਿਰ ਤੁਹਾਡੇ ਚੁਣੇ ਗਏ x ਅਤੇ y ਕੋਆਰਡੀਨੇਟਾਂ ਦੇ ਹਰ ਫੈਸਿਟ ਲਈ ਇੱਕ ਪਲਾਟ ਬਣਾਉਂਦਾ ਹੈ ਜੋ ਵਧੇਰੇ ਆਸਾਨ ਦ੍ਰਿਸ਼ਟੀਕਰਨ ਦੀ ਤੁਲਨਾ ਲਈ ਹੈ। ਕੀ 2003 ਇਸ ਕਿਸਮ ਦੀ ਤੁਲਨਾ ਵਿੱਚ ਖਾਸ ਦਿਖਾਈ ਦਿੰਦਾ ਹੈ?
ggplot2 ਦੇ ਦਸਤਾਵੇਜ਼ ਦੁਆਰਾ ਸਿਫਾਰਸ਼ ਕੀਤੇ facet_wrap ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਇੱਕ ਫੈਸਿਟ ਗ੍ਰਿਡ ਬਣਾਓ।
ggplot(honey, aes(x=yieldpercol, y = numcol,group = 1)) +
geom_line() + facet_wrap(vars(year))
ਇਸ ਦ੍ਰਿਸ਼ਟੀਕਰਨ ਵਿੱਚ, ਤੁਸੀਂ ਸਾਲ ਦਰ ਸਾਲ ਅਤੇ ਰਾਜ ਦਰ ਰਾਜ ਕਾਲੋਨੀ ਦੀ ਉਪਜ ਅਤੇ ਕਾਲੋਨੀਆਂ ਦੀ ਗਿਣਤੀ ਦੀ ਤੁਲਨਾ ਕਰ ਸਕਦੇ ਹੋ, ਕਾਲਮਾਂ ਲਈ 3 'ਤੇ ਰੈਪ ਸੈਟ ਨਾਲ:
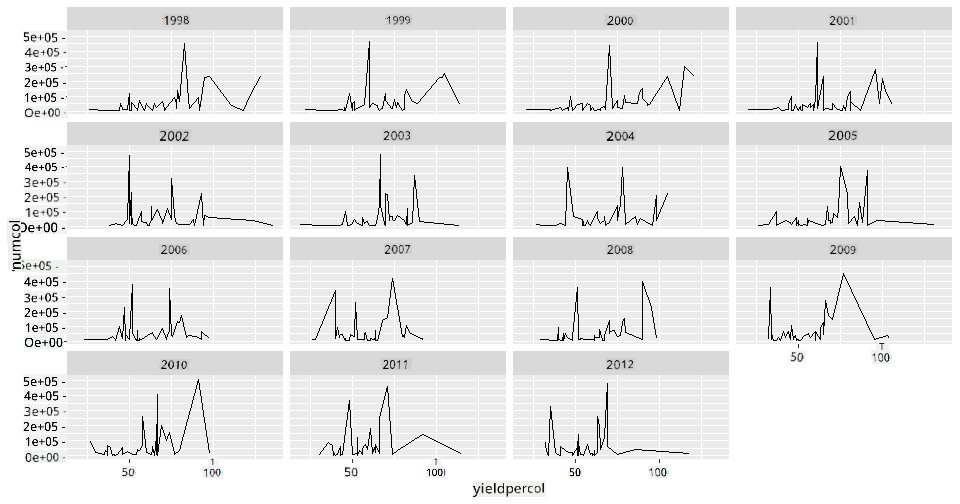
ਇਸ ਡਾਟਾਸੈੱਟ ਲਈ, ਸਾਲ ਦਰ ਸਾਲ ਅਤੇ ਰਾਜ ਦਰ ਰਾਜ ਕਾਲੋਨੀਆਂ ਦੀ ਗਿਣਤੀ ਅਤੇ ਉਨ੍ਹਾਂ ਦੀ ਉਪਜ ਦੇ ਸਬੰਧ ਵਿੱਚ ਕੁਝ ਖਾਸ ਦਿਖਾਈ ਨਹੀਂ ਦਿੰਦਾ। ਕੀ ਇਹ ਦੋ ਵੈਰੀਏਬਲਾਂ ਦੇ ਰਿਸ਼ਤੇ ਨੂੰ ਲੱਭਣ ਦਾ ਇੱਕ ਵੱਖਰਾ ਤਰੀਕਾ ਹੈ?
ਡੁਅਲ-ਲਾਈਨ ਪਲਾਟ
R ਦੇ par ਅਤੇ plot ਫੰਕਸ਼ਨ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਦੋ ਲਾਈਨਪਲਾਟਾਂ ਨੂੰ ਇੱਕ ਦੂਜੇ ਦੇ ਉੱਤੇ ਸਪਰਿੰਪੋਜ਼ ਕਰਕੇ ਇੱਕ ਮਲਟੀਲਾਈਨ ਪਲਾਟ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰੋ। ਅਸੀਂ x ਧੁਰੇ ਵਿੱਚ ਸਾਲ ਨੂੰ ਪਲਾਟ ਕਰ ਰਹੇ ਹੋਵਾਂਗੇ ਅਤੇ ਦੋ y ਧੁਰੇ ਦਿਖਾਵਾਂਗੇ। ਇਸ ਲਈ, ਕਾਲੋਨੀ ਦੀ ਉਪਜ ਅਤੇ ਕਾਲੋਨੀਆਂ ਦੀ ਗਿਣਤੀ ਦਿਖਾਓ:
par(mar = c(5, 4, 4, 4) + 0.3)
plot(honey$year, honey$numcol, pch = 16, col = 2,type="l")
par(new = TRUE)
plot(honey$year, honey$yieldpercol, pch = 17, col = 3,
axes = FALSE, xlab = "", ylab = "",type="l")
axis(side = 4, at = pretty(range(y2)))
mtext("colony yield", side = 4, line = 3)
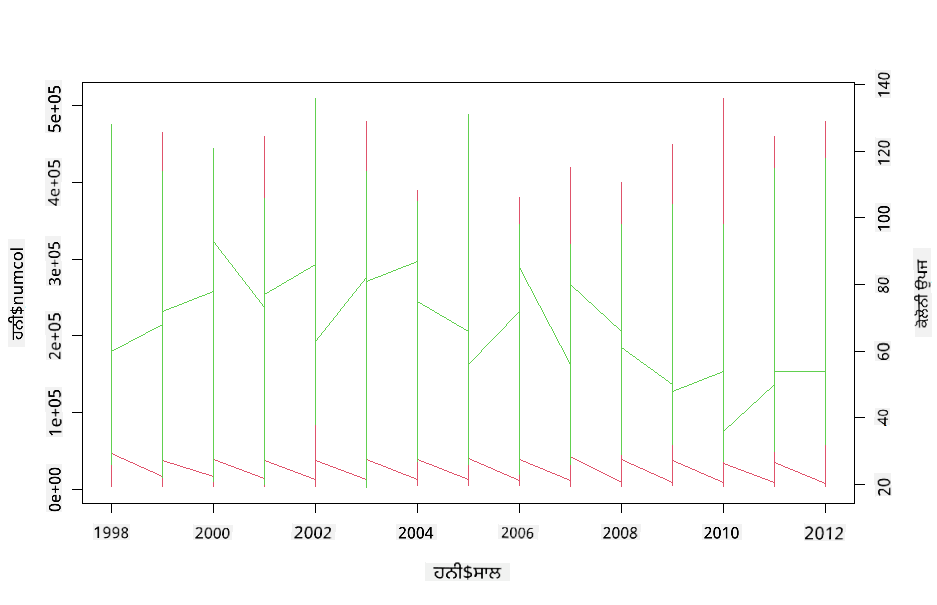
ਹਾਲਾਂਕਿ 2003 ਦੇ ਆਸ-ਪਾਸ ਕੁਝ ਵੀ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਦਿਖਾਈ ਨਹੀਂ ਦਿੰਦਾ, ਇਹ ਸਾਨੂੰ ਇਸ ਪਾਠ ਨੂੰ ਇੱਕ ਖੁਸ਼ੀਦਾਇਕ ਨੋਟ 'ਤੇ ਖਤਮ ਕਰਨ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ: ਹਾਲਾਂਕਿ ਕੁੱਲ ਕਾਲੋਨੀਆਂ ਦੀ ਗਿਣਤੀ ਘਟ ਰਹੀ ਹੈ, ਕਾਲੋਨੀਆਂ ਦੀ ਗਿਣਤੀ ਸਥਿਰ ਹੋ ਰਹੀ ਹੈ ਭਾਵੇਂ ਉਨ੍ਹਾਂ ਦੀ ਪ੍ਰਤੀ ਕਾਲੋਨੀ ਉਪਜ ਘਟ ਰਹੀ ਹੈ।
ਜਾਓ, ਮੱਖੀਆਂ, ਜਾਓ!
🐝❤️
🚀 ਚੁਣੌਤੀ
ਇਸ ਪਾਠ ਵਿੱਚ, ਤੁਸੀਂ ਸਕੈਟਰਪਲਾਟ ਅਤੇ ਲਾਈਨ ਗ੍ਰਿਡਾਂ ਦੇ ਹੋਰ ਉਪਯੋਗਾਂ ਬਾਰੇ ਕੁਝ ਹੋਰ ਸਿੱਖਿਆ, ਜਿਸ ਵਿੱਚ ਫੈਸਿਟ ਗ੍ਰਿਡ ਸ਼ਾਮਲ ਹਨ। ਆਪਣੇ ਆਪ ਨੂੰ ਇੱਕ ਵੱਖਰੇ ਡਾਟਾਸੈੱਟ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਇੱਕ ਫੈਸਿਟ ਗ੍ਰਿਡ ਬਣਾਉਣ ਦੀ ਚੁਣੌਤੀ ਦਿਓ, ਸ਼ਾਇਦ ਉਹ ਜੋ ਤੁਸੀਂ ਇਨ੍ਹਾਂ ਪਾਠਾਂ ਤੋਂ ਪਹਿਲਾਂ ਵਰਤਿਆ ਸੀ। ਨੋਟ ਕਰੋ ਕਿ ਇਹ ਬਣਾਉਣ ਵਿੱਚ ਕਿੰਨਾ ਸਮਾਂ ਲੱਗਦਾ ਹੈ ਅਤੇ ਤੁਸੀਂ ਇਹਨਾਂ ਤਕਨੀਕਾਂ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋਏ ਕਿੰਨੀ ਗ੍ਰਿਡਾਂ ਬਣਾਉਣ ਦੀ ਸੰਭਾਲ ਕਰਦੇ ਹੋ।
ਪੋਸਟ-ਲੈਕਚਰ ਕਵਿਜ਼
ਸਮੀਖਿਆ ਅਤੇ ਸਵੈ ਅਧਿਐਨ
ਲਾਈਨ ਪਲਾਟ ਸਧਾਰਨ ਜਾਂ ਕਾਫ਼ੀ ਜਟਿਲ ਹੋ ਸਕਦੇ ਹਨ। [ggplot2 ਦਸਤਾਵੇਜ਼](https://gg
ਅਸਵੀਕਰਤੀ:
ਇਹ ਦਸਤਾਵੇਜ਼ AI ਅਨੁਵਾਦ ਸੇਵਾ Co-op Translator ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਅਨੁਵਾਦ ਕੀਤਾ ਗਿਆ ਹੈ। ਜਦੋਂ ਕਿ ਅਸੀਂ ਸਹੀ ਹੋਣ ਦਾ ਯਤਨ ਕਰਦੇ ਹਾਂ, ਕਿਰਪਾ ਕਰਕੇ ਧਿਆਨ ਦਿਓ ਕਿ ਸਵੈਚਾਲਿਤ ਅਨੁਵਾਦਾਂ ਵਿੱਚ ਗਲਤੀਆਂ ਜਾਂ ਅਸੁਣਭਵਤਾਵਾਂ ਹੋ ਸਕਦੀਆਂ ਹਨ। ਇਸ ਦੀ ਮੂਲ ਭਾਸ਼ਾ ਵਿੱਚ ਮੌਜੂਦ ਮੂਲ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਪ੍ਰਮਾਣਿਕ ਸਰੋਤ ਮੰਨਿਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ। ਮਹੱਤਵਪੂਰਨ ਜਾਣਕਾਰੀ ਲਈ, ਪੇਸ਼ੇਵਰ ਮਨੁੱਖੀ ਅਨੁਵਾਦ ਦੀ ਸਿਫਾਰਸ਼ ਕੀਤੀ ਜਾਂਦੀ ਹੈ। ਇਸ ਅਨੁਵਾਦ ਦੇ ਪ੍ਰਯੋਗ ਤੋਂ ਪੈਦਾ ਹੋਣ ਵਾਲੀਆਂ ਕਿਸੇ ਵੀ ਗਲਤਫਹਮੀਆਂ ਜਾਂ ਗਲਤ ਵਿਆਖਿਆਵਾਂ ਲਈ ਅਸੀਂ ਜ਼ਿੰਮੇਵਾਰ ਨਹੀਂ ਹਾਂ।