|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 3 weeks ago | |
README.md
Memvisualkan Peratusan
 |
|---|
| Memvisualkan Peratusan - Sketchnote oleh @nitya |
Dalam pelajaran ini, anda akan menggunakan dataset yang berfokuskan alam semula jadi untuk memvisualkan peratusan, seperti berapa banyak jenis kulat yang terdapat dalam dataset tentang cendawan. Mari kita terokai kulat yang menarik ini menggunakan dataset yang diperoleh daripada Audubon yang menyenaraikan butiran tentang 23 spesies cendawan berinsang dalam keluarga Agaricus dan Lepiota. Anda akan bereksperimen dengan visualisasi yang menarik seperti:
- Carta pai 🥧
- Carta donat 🍩
- Carta waffle 🧇
💡 Satu projek yang sangat menarik dipanggil Charticulator oleh Microsoft Research menawarkan antara muka seret dan lepas percuma untuk visualisasi data. Dalam salah satu tutorial mereka, mereka juga menggunakan dataset cendawan ini! Jadi anda boleh meneroka data dan belajar perpustakaan ini pada masa yang sama: Tutorial Charticulator.
Kuiz pra-pelajaran
Kenali cendawan anda 🍄
Cendawan sangat menarik. Mari kita import dataset untuk mengkajinya:
mushrooms = read.csv('../../data/mushrooms.csv')
head(mushrooms)
Sebuah jadual dicetak dengan beberapa data yang hebat untuk dianalisis:
| kelas | bentuk-tudung | permukaan-tudung | warna-tudung | lebam | bau | lampiran-insang | jarak-insang | saiz-insang | warna-insang | bentuk-batang | akar-batang | permukaan-batang-atas-cincin | permukaan-batang-bawah-cincin | warna-batang-atas-cincin | warna-batang-bawah-cincin | jenis-tudung | warna-tudung | bilangan-cincin | jenis-cincin | warna-cetakan-spora | populasi | habitat |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Beracun | Cembung | Licin | Coklat | Lebam | Tajam | Bebas | Rapat | Sempit | Hitam | Membesar | Sama | Licin | Licin | Putih | Putih | Sebahagian | Putih | Satu | Gantung | Hitam | Berselerak | Bandar |
| Boleh Dimakan | Cembung | Licin | Kuning | Lebam | Badam | Bebas | Rapat | Lebar | Hitam | Membesar | Kelab | Licin | Licin | Putih | Putih | Sebahagian | Putih | Satu | Gantung | Coklat | Banyak | Rumput |
| Boleh Dimakan | Loceng | Licin | Putih | Lebam | Anis | Bebas | Rapat | Lebar | Coklat | Membesar | Kelab | Licin | Licin | Putih | Putih | Sebahagian | Putih | Satu | Gantung | Coklat | Banyak | Padang |
| Beracun | Cembung | Bersisik | Putih | Lebam | Tajam | Bebas | Rapat | Sempit | Coklat | Membesar | Sama | Licin | Licin | Putih | Putih | Sebahagian | Putih | Satu | Gantung | Hitam | Berselerak | Bandar |
| Boleh Dimakan | Cembung | Licin | Hijau | Tiada Lebam | Tiada | Bebas | Padat | Lebar | Hitam | Tirus | Sama | Licin | Licin | Putih | Putih | Sebahagian | Putih | Satu | Pudar | Coklat | Banyak | Rumput |
| Boleh Dimakan | Cembung | Bersisik | Kuning | Lebam | Badam | Bebas | Rapat | Lebar | Coklat | Membesar | Kelab | Licin | Licin | Putih | Putih | Sebahagian | Putih | Satu | Gantung | Hitam | Banyak | Rumput |
Anda segera perasan bahawa semua data adalah berbentuk teks. Anda perlu menukar data ini supaya dapat digunakan dalam carta. Kebanyakan data, sebenarnya, diwakili sebagai objek:
names(mushrooms)
Hasilnya adalah:
[1] "class" "cap.shape"
[3] "cap.surface" "cap.color"
[5] "bruises" "odor"
[7] "gill.attachment" "gill.spacing"
[9] "gill.size" "gill.color"
[11] "stalk.shape" "stalk.root"
[13] "stalk.surface.above.ring" "stalk.surface.below.ring"
[15] "stalk.color.above.ring" "stalk.color.below.ring"
[17] "veil.type" "veil.color"
[19] "ring.number" "ring.type"
[21] "spore.print.color" "population"
[23] "habitat"
Ambil data ini dan tukarkan kolum 'kelas' kepada kategori:
library(dplyr)
grouped=mushrooms %>%
group_by(class) %>%
summarise(count=n())
Sekarang, jika anda mencetak data cendawan, anda dapat melihat bahawa ia telah dikelompokkan ke dalam kategori mengikut kelas beracun/boleh dimakan:
View(grouped)
| kelas | bilangan |
|---|---|
| Boleh Dimakan | 4208 |
| Beracun | 3916 |
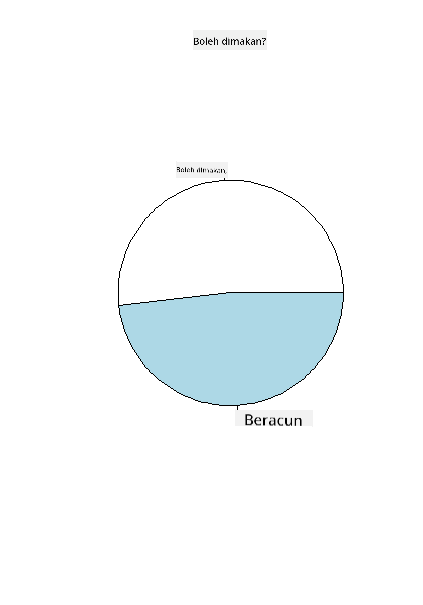
Jika anda mengikuti susunan yang disajikan dalam jadual ini untuk mencipta label kategori kelas anda, anda boleh membina carta pai.
Pai!
pie(grouped$count,grouped$class, main="Edible?")
Voila, sebuah carta pai yang menunjukkan peratusan data ini mengikut dua kelas cendawan ini. Sangat penting untuk mendapatkan susunan label dengan betul, terutamanya di sini, jadi pastikan anda mengesahkan susunan dengan cara array label dibina!
Donat!
Carta pai yang lebih menarik secara visual adalah carta donat, iaitu carta pai dengan lubang di tengah. Mari kita lihat data kita menggunakan kaedah ini.
Lihat pelbagai habitat di mana cendawan tumbuh:
library(dplyr)
habitat=mushrooms %>%
group_by(habitat) %>%
summarise(count=n())
View(habitat)
Hasilnya adalah:
| habitat | bilangan |
|---|---|
| Rumput | 2148 |
| Daun | 832 |
| Padang | 292 |
| Laluan | 1144 |
| Bandar | 368 |
| Sisa | 192 |
| Kayu | 3148 |
Di sini, anda mengelompokkan data anda mengikut habitat. Terdapat 7 yang disenaraikan, jadi gunakan itu sebagai label untuk carta donat anda:
library(ggplot2)
library(webr)
PieDonut(habitat, aes(habitat, count=count))
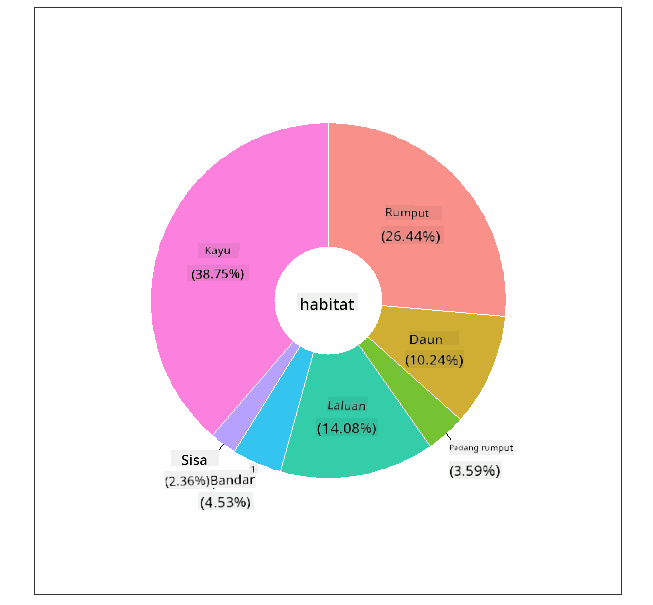
Kod ini menggunakan dua perpustakaan - ggplot2 dan webr. Dengan menggunakan fungsi PieDonut dari perpustakaan webr, kita boleh mencipta carta donat dengan mudah!
Carta donat dalam R juga boleh dibuat menggunakan hanya perpustakaan ggplot2. Anda boleh belajar lebih lanjut mengenainya di sini dan mencubanya sendiri.
Sekarang anda tahu cara mengelompokkan data anda dan kemudian memaparkannya sebagai pai atau donat, anda boleh meneroka jenis carta lain. Cuba carta waffle, yang hanya cara berbeza untuk meneroka kuantiti.
Waffle!
Carta jenis 'waffle' adalah cara berbeza untuk memvisualkan kuantiti sebagai array 2D kotak. Cuba visualkan kuantiti warna tudung cendawan yang berbeza dalam dataset ini. Untuk melakukan ini, anda perlu memasang perpustakaan pembantu yang dipanggil waffle dan menggunakannya untuk menghasilkan visualisasi anda:
install.packages("waffle", repos = "https://cinc.rud.is")
Pilih segmen data anda untuk dikelompokkan:
library(dplyr)
cap_color=mushrooms %>%
group_by(cap.color) %>%
summarise(count=n())
View(cap_color)
Cipta carta waffle dengan mencipta label dan kemudian mengelompokkan data anda:
library(waffle)
names(cap_color$count) = paste0(cap_color$cap.color)
waffle((cap_color$count/10), rows = 7, title = "Waffle Chart")+scale_fill_manual(values=c("brown", "#F0DC82", "#D2691E", "green",
"pink", "purple", "red", "grey",
"yellow","white"))
Menggunakan carta waffle, anda dapat melihat dengan jelas peratusan warna tudung dalam dataset cendawan ini. Menariknya, terdapat banyak cendawan bertudung hijau!
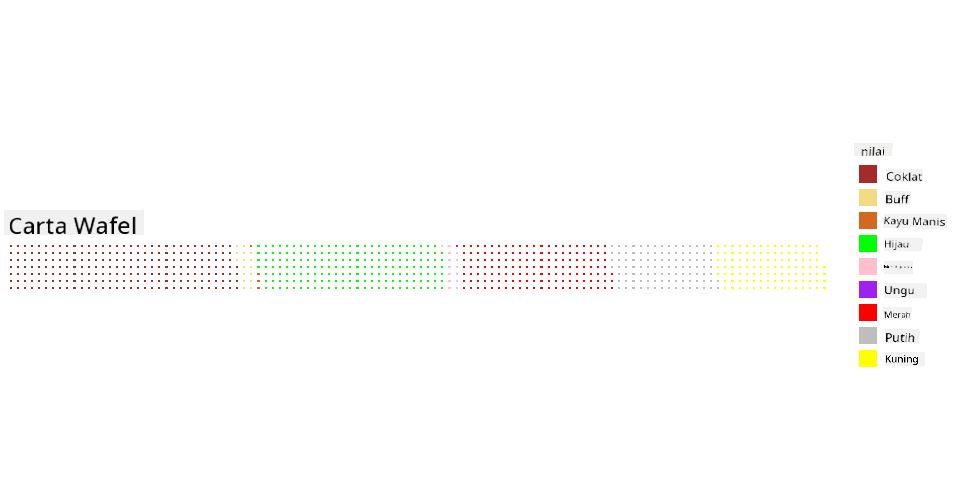
Dalam pelajaran ini, anda belajar tiga cara untuk memvisualkan peratusan. Pertama, anda perlu mengelompokkan data anda ke dalam kategori dan kemudian memutuskan cara terbaik untuk memaparkan data - pai, donat, atau waffle. Semua ini menarik dan memberikan pengguna gambaran segera tentang dataset.
🚀 Cabaran
Cuba cipta semula carta-carta menarik ini dalam Charticulator.
Kuiz pasca-pelajaran
Ulasan & Kajian Kendiri
Kadang-kadang tidak jelas bila untuk menggunakan carta pai, donat, atau waffle. Berikut adalah beberapa artikel untuk dibaca mengenai topik ini:
https://www.beautiful.ai/blog/battle-of-the-charts-pie-chart-vs-donut-chart
https://medium.com/@hypsypops/pie-chart-vs-donut-chart-showdown-in-the-ring-5d24fd86a9ce
https://www.mit.edu/~mbarker/formula1/f1help/11-ch-c6.htm
Lakukan penyelidikan untuk mencari lebih banyak maklumat mengenai keputusan yang sukar ini.
Tugasan
Penafian:
Dokumen ini telah diterjemahkan menggunakan perkhidmatan terjemahan AI Co-op Translator. Walaupun kami berusaha untuk memastikan ketepatan, sila ambil perhatian bahawa terjemahan automatik mungkin mengandungi kesilapan atau ketidaktepatan. Dokumen asal dalam bahasa asalnya harus dianggap sebagai sumber yang berwibawa. Untuk maklumat penting, terjemahan manusia profesional adalah disyorkan. Kami tidak bertanggungjawab atas sebarang salah faham atau salah tafsir yang timbul daripada penggunaan terjemahan ini.