|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
क्लाउड में डेटा साइंस: "लो कोड/नो कोड" तरीका
 |
|---|
| क्लाउड में डेटा साइंस: लो कोड - @nitya द्वारा स्केच नोट |
सामग्री की तालिका:
- क्लाउड में डेटा साइंस: "लो कोड/नो कोड" तरीका
प्री-लेक्चर क्विज़
1. परिचय
1.1 Azure Machine Learning क्या है?
Azure क्लाउड प्लेटफ़ॉर्म 200 से अधिक उत्पादों और क्लाउड सेवाओं का संग्रह है, जो आपको नई समाधान बनाने में मदद करता है। डेटा वैज्ञानिक अक्सर डेटा का विश्लेषण और पूर्व-प्रसंस्करण करने, और विभिन्न प्रकार के मॉडल-ट्रेनिंग एल्गोरिदम का परीक्षण करने में बहुत समय लगाते हैं ताकि सटीक मॉडल तैयार किए जा सकें। ये कार्य समय लेने वाले होते हैं और महंगे कंप्यूट हार्डवेयर का अप्रभावी उपयोग करते हैं।
Azure ML एक क्लाउड-आधारित प्लेटफ़ॉर्म है जो Azure में मशीन लर्निंग समाधान बनाने और संचालित करने के लिए उपयोग किया जाता है। इसमें डेटा तैयार करने, मॉडल ट्रेनिंग, प्रेडिक्टिव सेवाओं को प्रकाशित करने और उनके उपयोग की निगरानी करने के लिए कई सुविधाएँ और क्षमताएँ शामिल हैं। सबसे महत्वपूर्ण बात, यह मॉडल ट्रेनिंग से जुड़े समय लेने वाले कार्यों को स्वचालित करके डेटा वैज्ञानिकों की दक्षता बढ़ाने में मदद करता है; और यह बड़े डेटा वॉल्यूम को संभालने के लिए प्रभावी रूप से स्केल करने वाले क्लाउड-आधारित कंप्यूट संसाधनों का उपयोग करने में सक्षम बनाता है, जिससे केवल उपयोग के समय ही लागत लगती है।
Azure ML निम्नलिखित टूल्स प्रदान करता है जो डेवलपर्स और डेटा वैज्ञानिकों को उनके मशीन लर्निंग वर्कफ़्लो के लिए आवश्यक हैं:
- Azure Machine Learning Studio: यह मॉडल ट्रेनिंग, डिप्लॉयमेंट, ऑटोमेशन, ट्रैकिंग और एसेट मैनेजमेंट के लिए लो-कोड और नो-कोड विकल्पों के साथ एक वेब पोर्टल है। यह Azure Machine Learning SDK के साथ एक सहज अनुभव प्रदान करता है।
- Jupyter Notebooks: ML मॉडल को जल्दी प्रोटोटाइप और परीक्षण करने के लिए।
- Azure Machine Learning Designer: लो-कोड वातावरण में मॉड्यूल को ड्रैग-एन-ड्रॉप करके प्रयोग बनाने और पाइपलाइनों को डिप्लॉय करने की अनुमति देता है।
- Automated machine learning UI (AutoML): मशीन लर्निंग मॉडल विकास के पुनरावृत्त कार्यों को स्वचालित करता है, जिससे उच्च स्केल, दक्षता और उत्पादकता के साथ ML मॉडल बनाए जा सकते हैं, और मॉडल की गुणवत्ता बनाए रखी जा सकती है।
- Data Labelling: डेटा को स्वचालित रूप से लेबल करने के लिए एक सहायक ML टूल।
- Visual Studio Code के लिए मशीन लर्निंग एक्सटेंशन: ML प्रोजेक्ट्स बनाने और प्रबंधित करने के लिए एक पूर्ण-विशेषता वाला विकास वातावरण प्रदान करता है।
- Machine learning CLI: कमांड लाइन से Azure ML संसाधनों को प्रबंधित करने के लिए कमांड प्रदान करता है।
- PyTorch, TensorFlow, Scikit-learn जैसे ओपन-सोर्स फ्रेमवर्क के साथ इंटीग्रेशन: ट्रेनिंग, डिप्लॉयमेंट और एंड-टू-एंड मशीन लर्निंग प्रक्रिया को प्रबंधित करने के लिए।
- MLflow: यह आपके मशीन लर्निंग प्रयोगों के जीवन चक्र को प्रबंधित करने के लिए एक ओपन-सोर्स लाइब्रेरी है। MLFlow Tracking MLflow का एक घटक है जो आपके ट्रेनिंग रन मेट्रिक्स और मॉडल आर्टिफैक्ट्स को लॉग और ट्रैक करता है, चाहे आपका प्रयोग का वातावरण कुछ भी हो।
1.2 हार्ट फेल्योर प्रेडिक्शन प्रोजेक्ट:
कोई भी प्रोजेक्ट बनाना और उसे विकसित करना आपके कौशल और ज्ञान को परखने का सबसे अच्छा तरीका है। इस पाठ में, हम Azure ML Studio में हार्ट फेल्योर अटैक की भविष्यवाणी के लिए डेटा साइंस प्रोजेक्ट बनाने के दो अलग-अलग तरीकों का पता लगाएंगे: लो कोड/नो कोड और Azure ML SDK के माध्यम से, जैसा कि निम्नलिखित स्कीमा में दिखाया गया है:
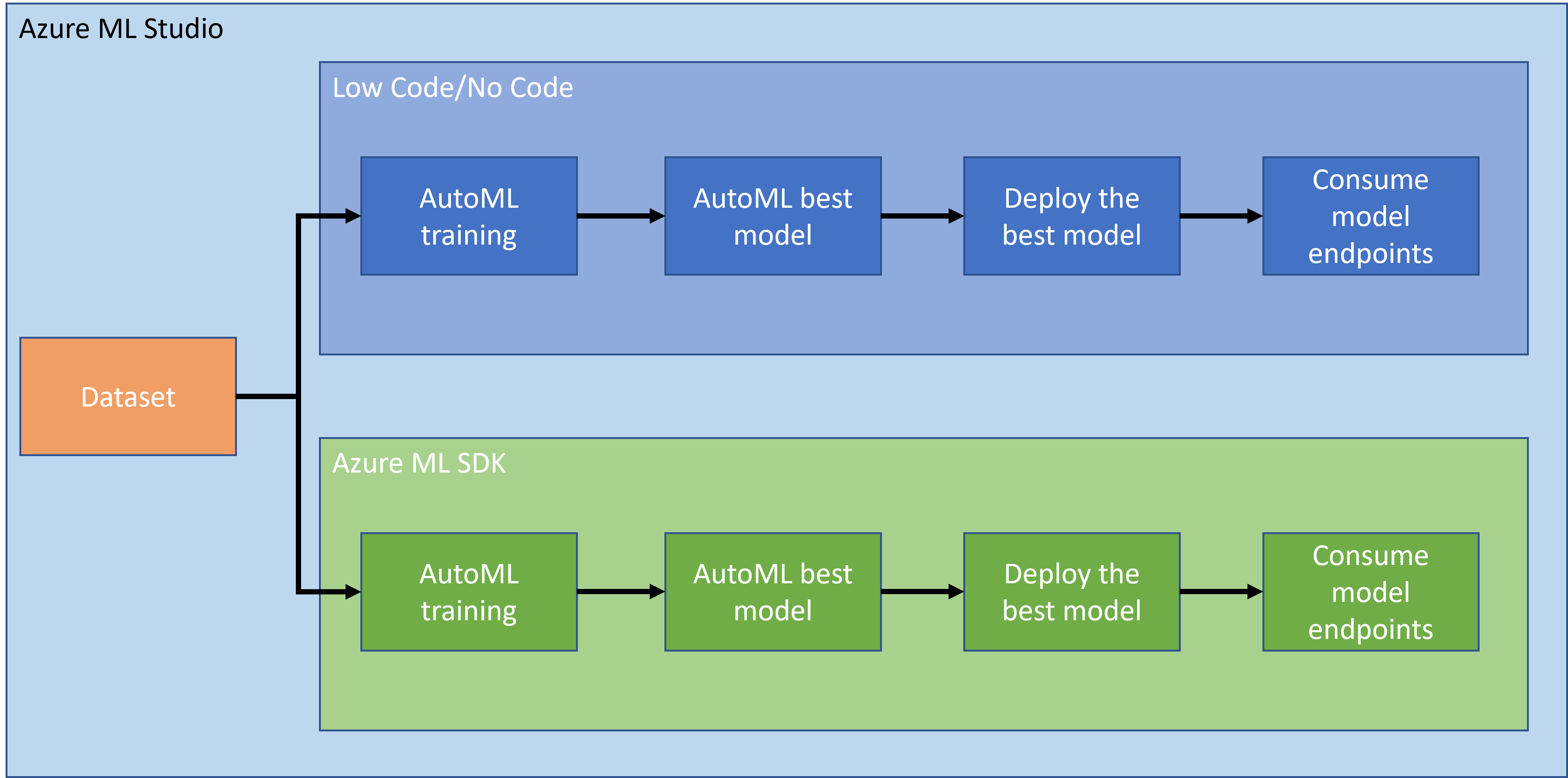
प्रत्येक तरीका अपने फायदे और नुकसान के साथ आता है। लो कोड/नो कोड तरीका शुरू करने के लिए आसान है क्योंकि इसमें GUI (ग्राफिकल यूजर इंटरफेस) के साथ इंटरैक्ट करना शामिल है, और कोड का कोई पूर्व ज्ञान आवश्यक नहीं है। यह प्रोजेक्ट की व्यवहार्यता का त्वरित परीक्षण करने और POC (प्रूफ ऑफ कॉन्सेप्ट) बनाने में सक्षम बनाता है। हालांकि, जैसे-जैसे प्रोजेक्ट बढ़ता है और चीजों को प्रोडक्शन के लिए तैयार करना होता है, GUI के माध्यम से संसाधन बनाना व्यावहारिक नहीं होता। हमें प्रोग्रामेटिक रूप से सब कुछ स्वचालित करना होगा, संसाधन निर्माण से लेकर मॉडल डिप्लॉयमेंट तक। यही वह जगह है जहां Azure ML SDK का उपयोग करना महत्वपूर्ण हो जाता है।
| लो कोड/नो कोड | Azure ML SDK | |
|---|---|---|
| कोड में विशेषज्ञता | आवश्यक नहीं | आवश्यक |
| विकास का समय | तेज और आसान | कोड विशेषज्ञता पर निर्भर |
| प्रोडक्शन रेडी | नहीं | हाँ |
1.3 हार्ट फेल्योर डेटासेट:
कार्डियोवैस्कुलर बीमारियाँ (CVDs) वैश्विक स्तर पर मृत्यु का नंबर 1 कारण हैं, जो दुनिया भर में सभी मौतों का 31% हिस्सा हैं। तंबाकू का उपयोग, अस्वास्थ्यकर आहार और मोटापा, शारीरिक निष्क्रियता और शराब का हानिकारक उपयोग जैसे पर्यावरणीय और व्यवहारिक जोखिम कारकों का उपयोग अनुमान मॉडल के लिए फीचर्स के रूप में किया जा सकता है। CVD के विकास की संभावना का अनुमान लगाने में सक्षम होना उच्च जोखिम वाले लोगों में हमले को रोकने के लिए बहुत उपयोगी हो सकता है।
Kaggle ने एक हार्ट फेल्योर डेटासेट सार्वजनिक रूप से उपलब्ध कराया है, जिसे हम इस प्रोजेक्ट के लिए उपयोग करने जा रहे हैं। आप अभी डेटासेट डाउनलोड कर सकते हैं। यह एक टेबलर डेटासेट है जिसमें 13 कॉलम (12 फीचर्स और 1 टारगेट वेरिएबल) और 299 पंक्तियाँ हैं।
| वेरिएबल नाम | प्रकार | विवरण | उदाहरण | |
|---|---|---|---|---|
| 1 | age | संख्यात्मक | मरीज की उम्र | 25 |
| 2 | anaemia | बूलियन | लाल रक्त कोशिकाओं या हीमोग्लोबिन की कमी | 0 या 1 |
| 3 | creatinine_phosphokinase | संख्यात्मक | रक्त में CPK एंजाइम का स्तर | 542 |
| 4 | diabetes | बूलियन | क्या मरीज को डायबिटीज है | 0 या 1 |
| 5 | ejection_fraction | संख्यात्मक | प्रत्येक संकुचन पर दिल से निकलने वाले रक्त का प्रतिशत | 45 |
| 6 | high_blood_pressure | बूलियन | क्या मरीज को उच्च रक्तचाप है | 0 या 1 |
| 7 | platelets | संख्यात्मक | रक्त में प्लेटलेट्स | 149000 |
| 8 | serum_creatinine | संख्यात्मक | रक्त में सीरम क्रिएटिनिन का स्तर | 0.5 |
| 9 | serum_sodium | संख्यात्मक | रक्त में सीरम सोडियम का स्तर | jun |
| 10 | sex | बूलियन | महिला या पुरुष | 0 या 1 |
| 11 | smoking | बूलियन | क्या मरीज धूम्रपान करता है | 0 या 1 |
| 12 | time | संख्यात्मक | फॉलो-अप अवधि (दिन) | 4 |
| ---- | --------------------------- | ------------------- | --------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [Target] | बूलियन | क्या मरीज फॉलो-अप अवधि के दौरान मरता है | 0 या 1 |
एक बार जब आपके पास डेटासेट हो, तो हम Azure में प्रोजेक्ट शुरू कर सकते हैं।
2. Azure ML Studio में लो कोड/नो कोड मॉडल ट्रेनिंग
2.1 Azure ML वर्कस्पेस बनाना
Azure ML में मॉडल ट्रेन करने के लिए आपको पहले Azure ML वर्कस्पेस बनाना होगा। वर्कस्पेस Azure Machine Learning के लिए शीर्ष-स्तरीय संसाधन है, जो आपके द्वारा Azure Machine Learning का उपयोग करते समय बनाए गए सभी आर्टिफैक्ट्स के साथ काम करने के लिए एक केंद्रीकृत स्थान प्रदान करता है। वर्कस्पेस सभी ट्रेनिंग रन का इतिहास रखता है, जिसमें लॉग्स, मेट्रिक्स, आउटपुट और आपके स्क्रिप्ट्स का स्नैपशॉट शामिल है। आप इस जानकारी का उपयोग यह निर्धारित करने के लिए करते हैं कि कौन सा ट्रेनिंग रन सबसे अच्छा मॉडल तैयार करता है। अधिक जानें
यह अनुशंसा की जाती है कि आप अपने ऑपरेटिंग सिस्टम के साथ संगत सबसे अद्यतन ब्राउज़र का उपयोग करें। निम्नलिखित ब्राउज़र समर्थित हैं:
- Microsoft Edge (नया Microsoft Edge, नवीनतम संस्करण। Microsoft Edge लिगेसी नहीं)
- Safari (नवीनतम संस्करण, केवल Mac)
- Chrome (नवीनतम संस्करण)
- Firefox (नवीनतम संस्करण)
Azure Machine Learning का उपयोग करने के लिए, अपने Azure सब्सक्रिप्शन में एक वर्कस्पेस बनाएं। आप इस वर्कस्पेस का उपयोग डेटा, कंप्यूट संसाधन, कोड, मॉडल और मशीन लर्निंग वर्कलोड्स से संबंधित अन्य आर्टिफैक्ट्स को प्रबंधित करने के लिए कर सकते हैं।
नोट: जब तक Azure Machine Learning वर्कस्पेस आपके सब्सक्रिप्शन में मौजूद है, आपके Azure सब्सक्रिप्शन से डेटा स्टोरेज के लिए थोड़ी राशि ली जाएगी। इसलिए हम अनुशंसा करते हैं कि जब आप इसका उपयोग न कर रहे हों तो Azure Machine Learning वर्कस्पेस को हटा दें।
-
Azure पोर्टल में Microsoft क्रेडेंशियल्स का उपयोग करके साइन इन करें जो आपके Azure सब्सक्रिप्शन से जुड़े हैं।
-
+Create a resource चुनें
Machine Learning खोजें और Machine Learning टाइल चुनें
Create बटन पर क्लिक करें
निम्नलिखित सेटिंग्स भरें:
- सब्सक्रिप्शन: आपका Azure सब्सक्रिप्शन
- रिसोर्स ग्रुप: एक रिसोर्स ग्रुप बनाएं या चुनें
- वर्कस्पेस नाम: अपने वर्कस्पेस के लिए एक अद्वितीय नाम दर्ज करें
- क्षेत्र: आपके निकटतम भौगोलिक क्षेत्र चुनें
- स्टोरेज अकाउंट: आपके वर्कस्पेस के लिए बनाए जाने वाले नए स्टोरेज अकाउंट को नोट करें
- Key vault: आपके वर्कस्पेस के लिए बनाए जाने वाले नए Key vault को नोट करें
- Application insights: आपके वर्कस्पेस के लिए बनाए जाने वाले नए Application insights संसाधन को नोट करें
- Container registry: कोई नहीं (पहली बार जब आप किसी मॉडल को कंटेनर में डिप्लॉय करेंगे तो एक स्वचालित रूप से बनाया जाएगा)
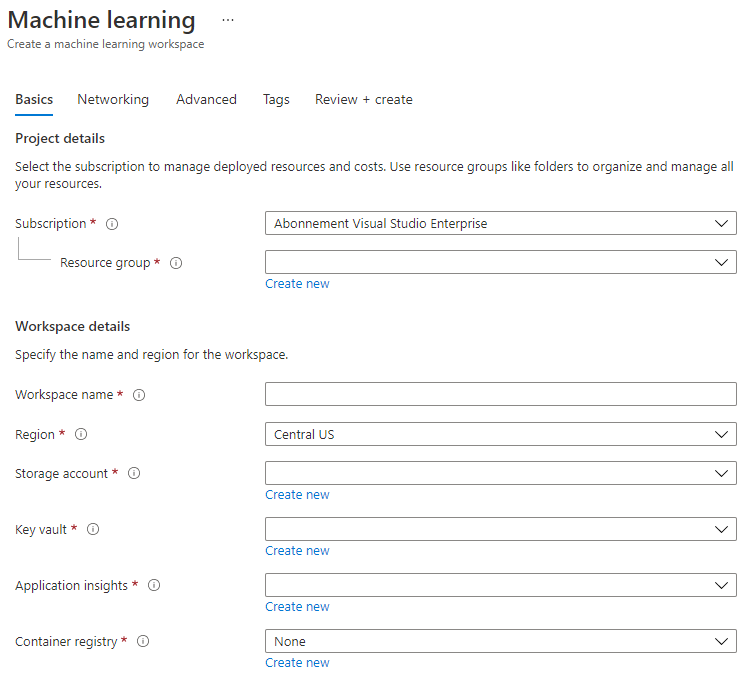
- Create + Review पर क्लिक करें और फिर Create बटन पर क्लिक करें
-
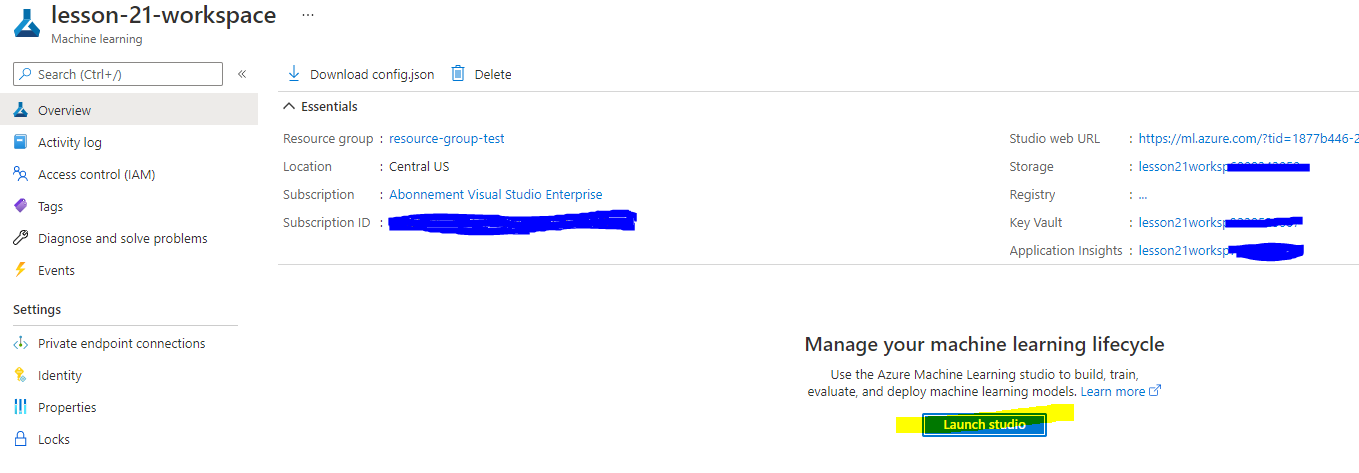
अपने वर्कस्पेस के बनने की प्रतीक्षा करें (इसमें कुछ मिनट लग सकते हैं)। फिर इसे पोर्टल में खोलें। आप इसे Machine Learning Azure सेवा के माध्यम से पा सकते हैं।
-
अपने वर्कस्पेस के Overview पेज पर, Azure Machine Learning Studio लॉन्च करें (या एक नया ब्राउज़र टैब खोलें और https://ml.azure.com पर जाएं), और Azure Machine Learning Studio में अपने Microsoft अकाउंट का उपयोग करके साइन इन करें। यदि संकेत दिया जाए, तो अपना Azure डायरेक्टरी और सब्सक्रिप्शन चुनें, और अपना Azure Machine Learning वर्कस्पेस चुनें।
- Azure Machine Learning Studio में, इंटरफ़ेस में विभिन्न पेज देखने के लिए ऊपर बाईं ओर ☰ आइकन पर टॉगल करें। आप इन पेजों का उपयोग अपने वर्कस्पेस में संसाधनों को प्रबंधित करने के लिए कर सकते हैं।
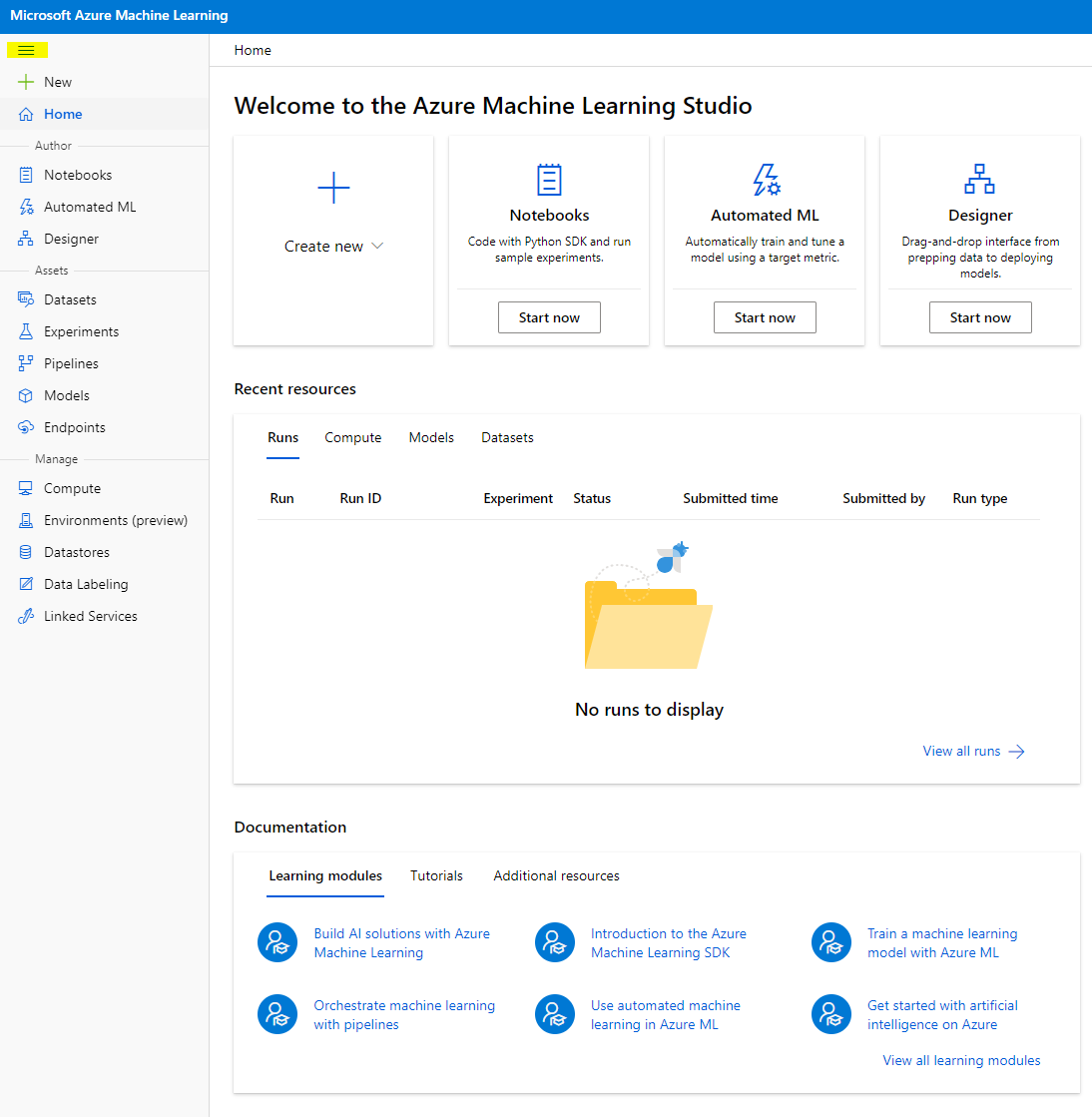
आप अपने वर्कस्पेस को Azure पोर्टल का उपयोग करके प्रबंधित कर सकते हैं, लेकिन डेटा वैज्ञानिकों और मशीन लर्निंग ऑपरेशंस इंजीनियरों के लिए, Azure Machine Learning Studio वर्कस्पेस संसाधनों को प्रबंधित करने के लिए एक अधिक केंद्रित उपयोगकर्ता इंटरफ़ेस प्रदान करता है।
2.2 कंप्यूट संसाधन
कंप्यूट संसाधन क्लाउड-आधारित संसाधन हैं जिन पर आप मॉडल ट्रेनिंग और डेटा एक्सप्लोरेशन प्रक्रियाएँ चला सकते हैं। आप चार प्रकार के कंप्यूट संसाधन बना सकते हैं:
- Compute Instances: विकास कार्यस्थल जिन्हें डेटा वैज्ञानिक डेटा और मॉडल के साथ काम करने के लिए उपयोग कर सकते हैं। इसमें एक वर्चुअल मशीन (VM) बनाना और एक नोटबुक इंस्टेंस लॉन्च करना शामिल है। आप फिर नोटबुक से कंप्यूट क्लस्टर को कॉल करके मॉडल ट्रेन कर सकते हैं।
- Compute Clusters: VMs के स्केलेबल क्लस्टर जो प्रयोग कोड के ऑन-डिमांड प्रोसेसिंग के लिए उपयोग किए जाते हैं। आपको मॉडल ट्रेनिंग के समय इसकी आवश्यकता होगी। Compute Clusters विशेष GPU या CPU संसाधनों का भी उपयोग कर सकते हैं।
- Inference Clusters: आपके प्रशिक्षित मॉडल का उपयोग करने वाली प्रेडिक्टिव सेवाओं के लिए डिप्लॉयमेंट लक्ष्य।
- अटैच्ड कंप्यूट: मौजूदा Azure कंप्यूट संसाधनों से लिंक करता है, जैसे वर्चुअल मशीन या Azure Databricks क्लस्टर।
2.2.1 अपने कंप्यूट संसाधनों के लिए सही विकल्प चुनना
कंप्यूट संसाधन बनाते समय कुछ महत्वपूर्ण कारकों पर विचार करना चाहिए, और ये विकल्प महत्वपूर्ण निर्णय हो सकते हैं।
क्या आपको CPU या GPU की आवश्यकता है?
CPU (सेंट्रल प्रोसेसिंग यूनिट) एक इलेक्ट्रॉनिक सर्किट्री है जो कंप्यूटर प्रोग्राम के निर्देशों को निष्पादित करता है। GPU (ग्राफिक्स प्रोसेसिंग यूनिट) एक विशेषीकृत इलेक्ट्रॉनिक सर्किट है जो ग्राफिक्स से संबंधित कोड को बहुत तेज़ी से निष्पादित कर सकता है।
CPU और GPU आर्किटेक्चर के बीच मुख्य अंतर यह है कि CPU को विभिन्न प्रकार के कार्यों को तेज़ी से संभालने के लिए डिज़ाइन किया गया है (जैसा कि CPU क्लॉक स्पीड द्वारा मापा जाता है), लेकिन यह एक समय में चलने वाले कार्यों की समानांतरता में सीमित है। GPU समानांतर कंप्यूटिंग के लिए डिज़ाइन किए गए हैं और इसलिए गहन शिक्षण (डीप लर्निंग) कार्यों के लिए अधिक उपयुक्त हैं।
| CPU | GPU |
|---|---|
| कम महंगा | अधिक महंगा |
| कम समानांतरता स्तर | उच्च समानांतरता स्तर |
| गहन शिक्षण मॉडल को प्रशिक्षित करने में धीमा | गहन शिक्षण के लिए इष्टतम |
क्लस्टर का आकार
बड़े क्लस्टर अधिक महंगे होते हैं लेकिन बेहतर प्रतिक्रिया समय प्रदान करते हैं। इसलिए, यदि आपके पास समय है लेकिन बजट कम है, तो आपको छोटे क्लस्टर से शुरुआत करनी चाहिए। इसके विपरीत, यदि आपके पास बजट है लेकिन समय कम है, तो आपको बड़े क्लस्टर से शुरुआत करनी चाहिए।
VM का आकार
आपके समय और बजट की बाधाओं के आधार पर, आप अपने RAM, डिस्क, कोर की संख्या और क्लॉक स्पीड का आकार बदल सकते हैं। इन सभी पैरामीटरों को बढ़ाने से लागत बढ़ेगी, लेकिन प्रदर्शन बेहतर होगा।
डेडिकेटेड या लो-प्रायोरिटी इंस्टेंस?
लो-प्रायोरिटी इंस्टेंस का मतलब है कि यह बाधित हो सकता है: मूल रूप से, Microsoft Azure इन संसाधनों को ले सकता है और उन्हें किसी अन्य कार्य को सौंप सकता है, जिससे एक जॉब बाधित हो सकती है। एक डेडिकेटेड इंस्टेंस, या गैर-बाधित, का मतलब है कि जॉब आपकी अनुमति के बिना कभी समाप्त नहीं होगी। यह समय बनाम पैसे का एक और विचार है, क्योंकि बाधित होने वाले इंस्टेंस डेडिकेटेड इंस्टेंस की तुलना में सस्ते होते हैं।
2.2.2 कंप्यूट क्लस्टर बनाना
Azure ML वर्कस्पेस में, जिसे हमने पहले बनाया था, "कंप्यूट" पर जाएं और आप उन विभिन्न कंप्यूट संसाधनों को देख पाएंगे जिन पर हमने चर्चा की (जैसे कंप्यूट इंस्टेंस, कंप्यूट क्लस्टर, इंफरेंस क्लस्टर और अटैच्ड कंप्यूट)। इस प्रोजेक्ट के लिए, हमें मॉडल प्रशिक्षण के लिए एक कंप्यूट क्लस्टर की आवश्यकता होगी। स्टूडियो में, "कंप्यूट" मेनू पर क्लिक करें, फिर "कंप्यूट क्लस्टर" टैब पर जाएं और "+ New" बटन पर क्लिक करें।
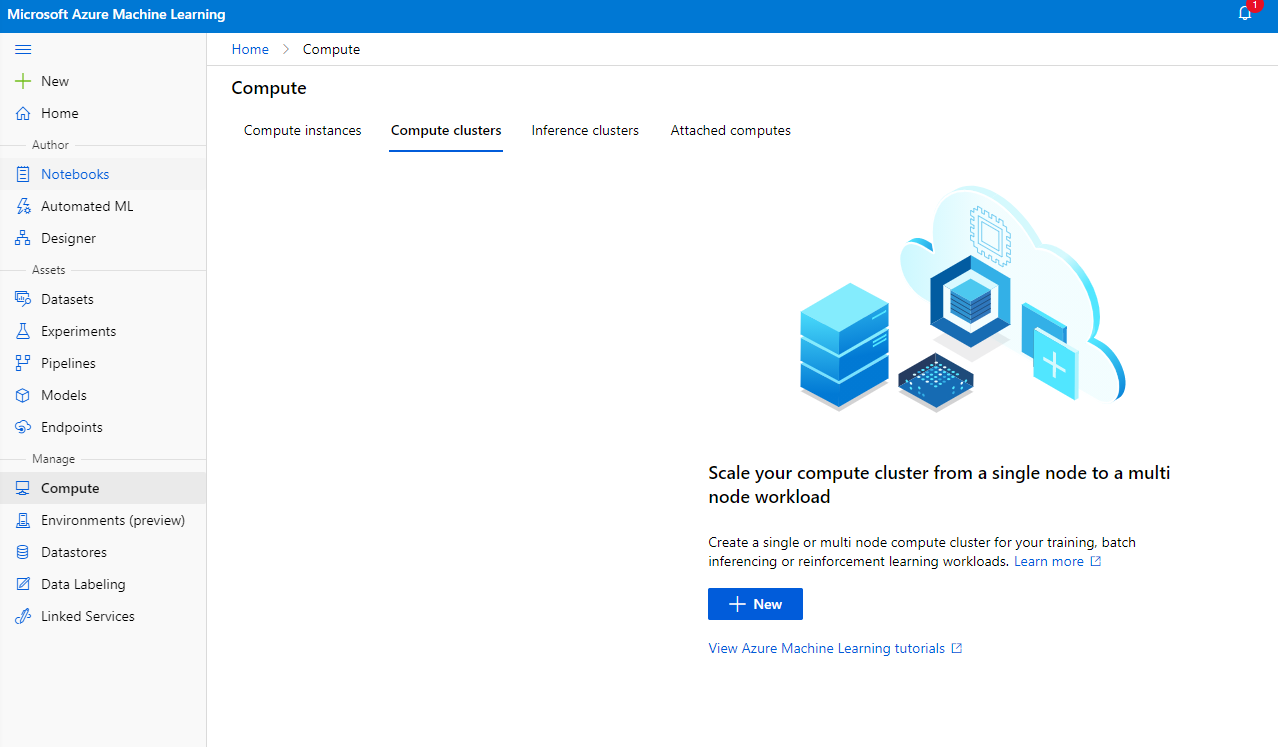
- अपने विकल्प चुनें: डेडिकेटेड बनाम लो-प्रायोरिटी, CPU या GPU, VM का आकार और कोर की संख्या (आप इस प्रोजेक्ट के लिए डिफ़ॉल्ट सेटिंग्स रख सकते हैं)।
- "Next" बटन पर क्लिक करें।
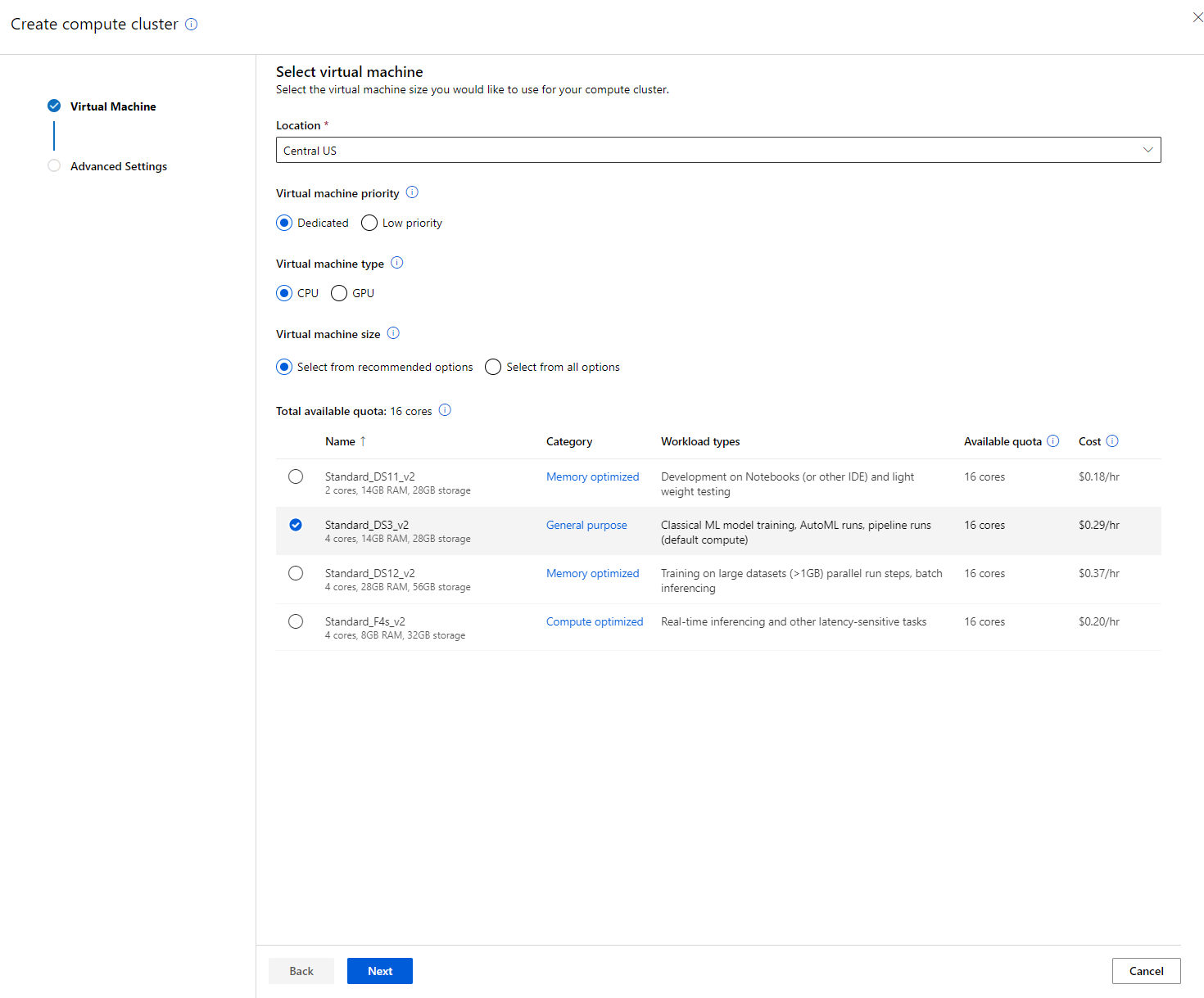
- क्लस्टर को एक नाम दें।
- अपने विकल्प चुनें: न्यूनतम/अधिकतम नोड्स की संख्या, स्केल डाउन से पहले निष्क्रिय सेकंड, SSH एक्सेस। ध्यान दें कि यदि न्यूनतम नोड्स की संख्या 0 है, तो क्लस्टर के निष्क्रिय होने पर आप पैसे बचा सकते हैं। ध्यान दें कि अधिकतम नोड्स की संख्या जितनी अधिक होगी, प्रशिक्षण उतना ही तेज़ होगा। अधिकतम 3 नोड्स की सिफारिश की जाती है।
- "Create" बटन पर क्लिक करें। इस चरण में कुछ मिनट लग सकते हैं।
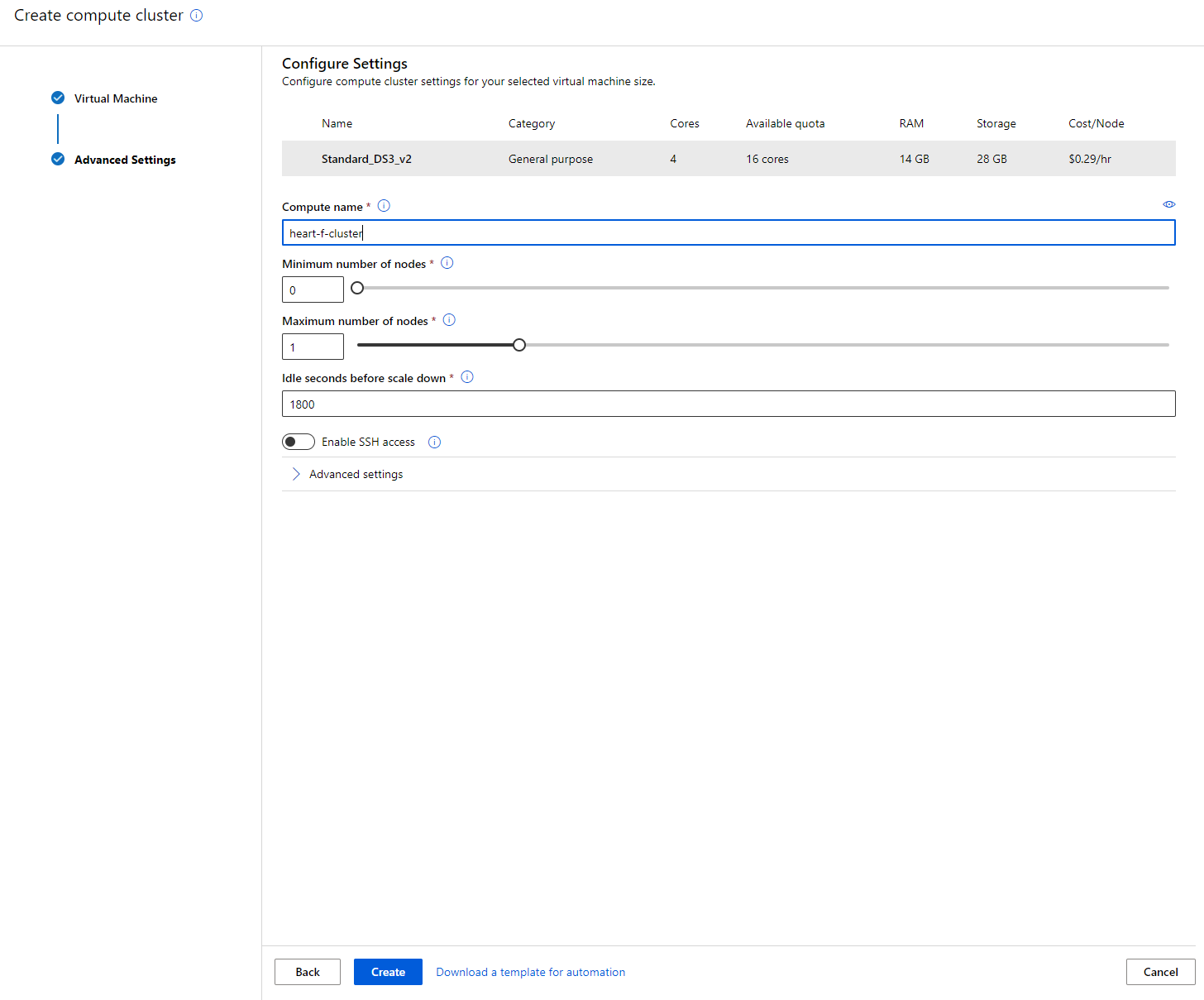
शानदार! अब जब हमारे पास एक कंप्यूट क्लस्टर है, तो हमें डेटा को Azure ML स्टूडियो में लोड करना होगा।
2.3 डेटासेट लोड करना
-
Azure ML वर्कस्पेस में, जिसे हमने पहले बनाया था, "Datasets" पर क्लिक करें और "+ Create dataset" बटन पर क्लिक करें। "From local files" विकल्प चुनें और पहले डाउनलोड किए गए Kaggle डेटासेट का चयन करें।
-
अपने डेटासेट को एक नाम, प्रकार और विवरण दें। "Next" पर क्लिक करें। फाइलों से डेटा अपलोड करें। "Next" पर क्लिक करें।
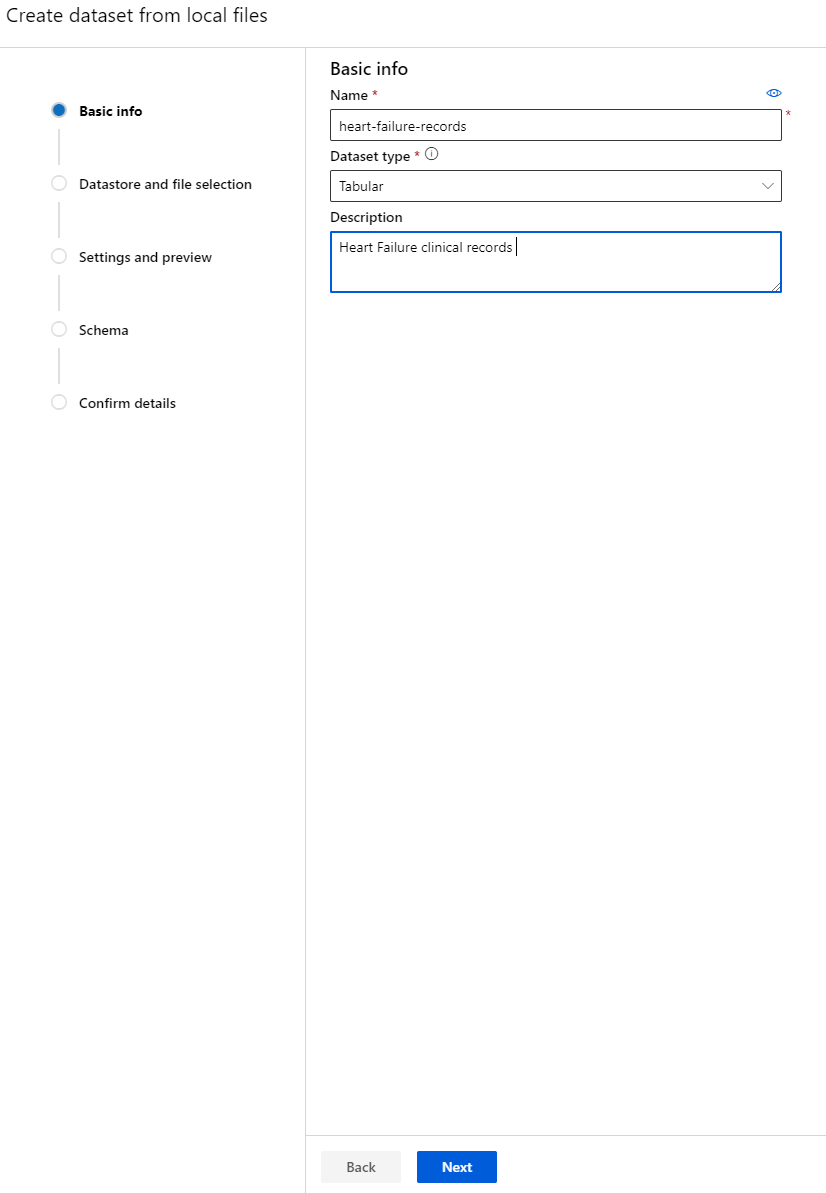
-
"Schema" में, निम्नलिखित विशेषताओं के लिए डेटा प्रकार को Boolean में बदलें: anaemia, diabetes, high blood pressure, sex, smoking, और DEATH_EVENT। "Next" पर क्लिक करें और "Create" पर क्लिक करें।
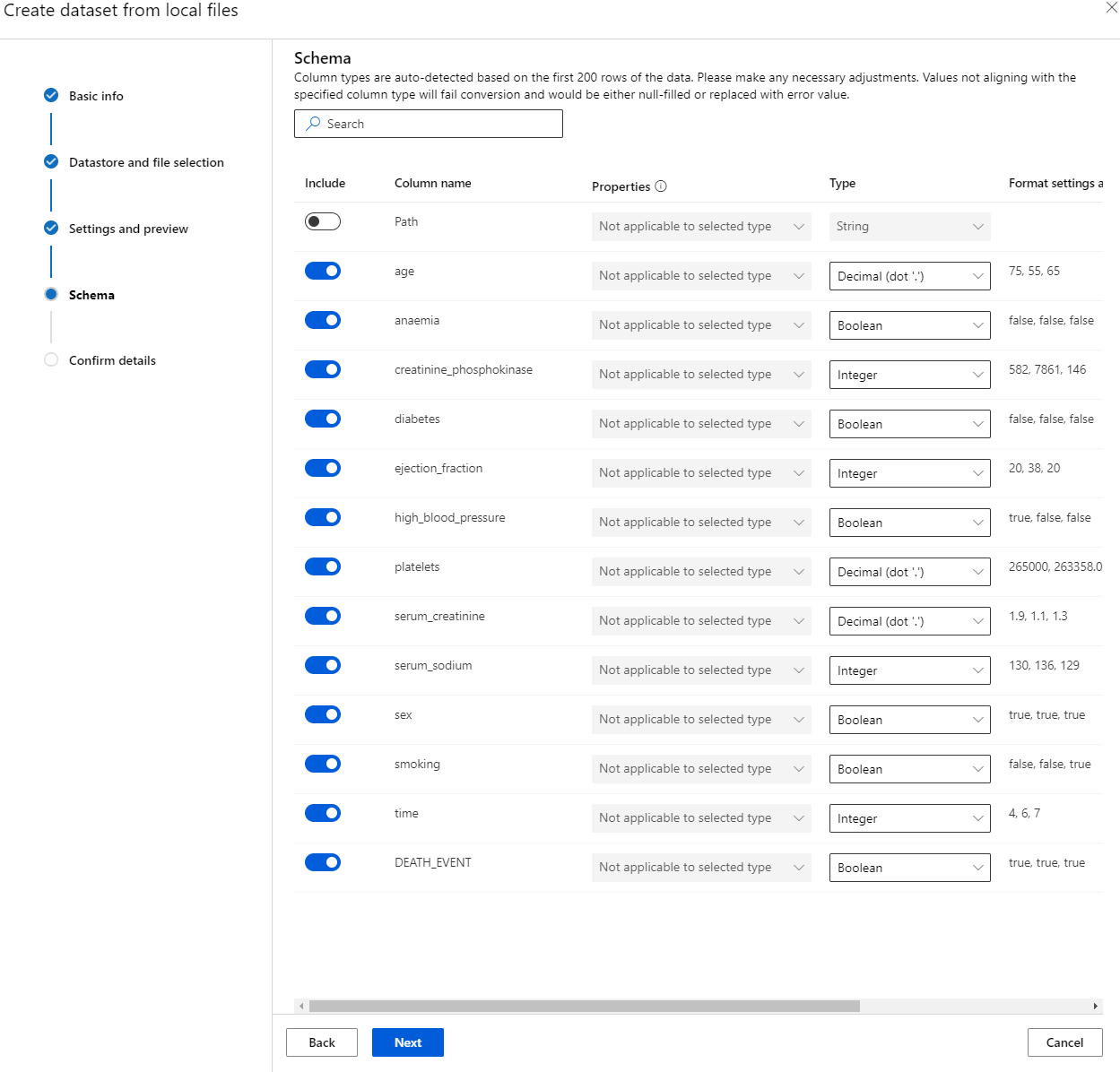
शानदार! अब जब डेटासेट तैयार है और कंप्यूट क्लस्टर बनाया गया है, तो हम मॉडल का प्रशिक्षण शुरू कर सकते हैं!
2.4 लो कोड/नो कोड प्रशिक्षण AutoML के साथ
पारंपरिक मशीन लर्निंग मॉडल विकास संसाधन-गहन होता है, जिसमें महत्वपूर्ण डोमेन ज्ञान और दर्जनों मॉडलों को बनाने और तुलना करने के लिए समय की आवश्यकता होती है।
ऑटोमेटेड मशीन लर्निंग (AutoML) मशीन लर्निंग मॉडल विकास के समय लेने वाले, पुनरावृत्त कार्यों को स्वचालित करने की प्रक्रिया है। यह डेटा वैज्ञानिकों, विश्लेषकों और डेवलपर्स को उच्च पैमाने, दक्षता और उत्पादकता के साथ ML मॉडल बनाने की अनुमति देता है, जबकि मॉडल की गुणवत्ता बनाए रखता है। यह उत्पादन-तैयार ML मॉडल प्राप्त करने में लगने वाले समय को कम करता है, वह भी बड़ी आसानी और दक्षता के साथ। अधिक जानें
-
Azure ML वर्कस्पेस में, जिसे हमने पहले बनाया था, "Automated ML" पर क्लिक करें और अभी-अभी अपलोड किए गए डेटासेट का चयन करें। "Next" पर क्लिक करें।
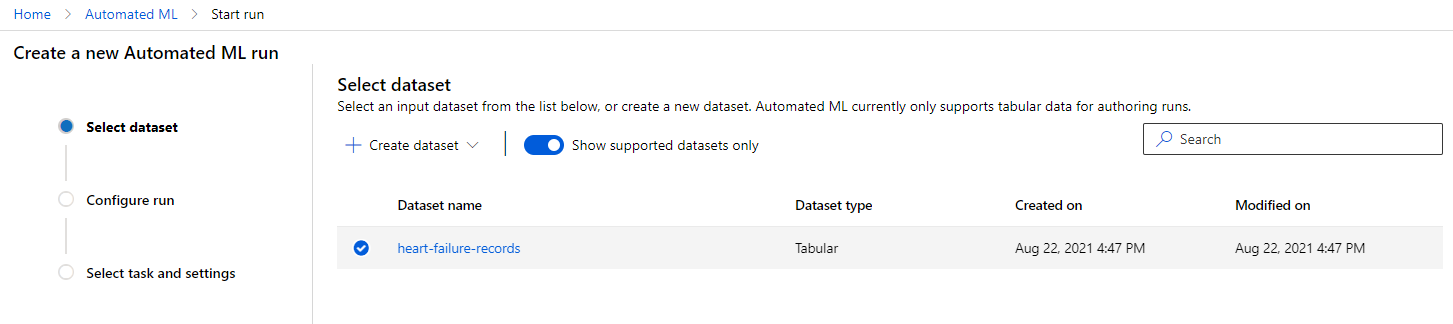
-
एक नया प्रयोग नाम, लक्ष्य कॉलम (DEATH_EVENT) और हमने जो कंप्यूट क्लस्टर बनाया था, उसे दर्ज करें। "Next" पर क्लिक करें।
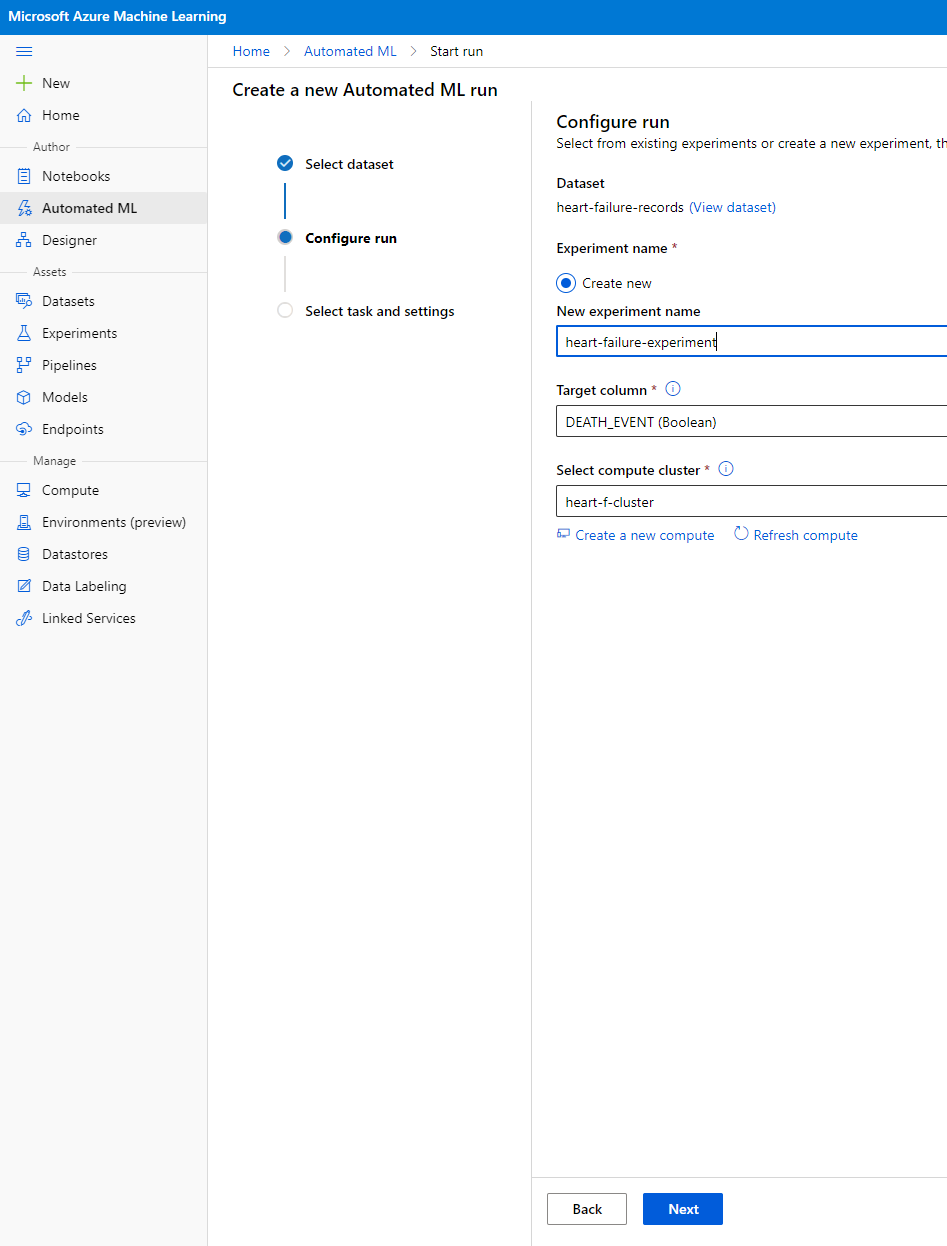
-
"Classification" चुनें और "Finish" पर क्लिक करें। इस चरण में 30 मिनट से 1 घंटे तक का समय लग सकता है, यह आपके कंप्यूट क्लस्टर के आकार पर निर्भर करता है।
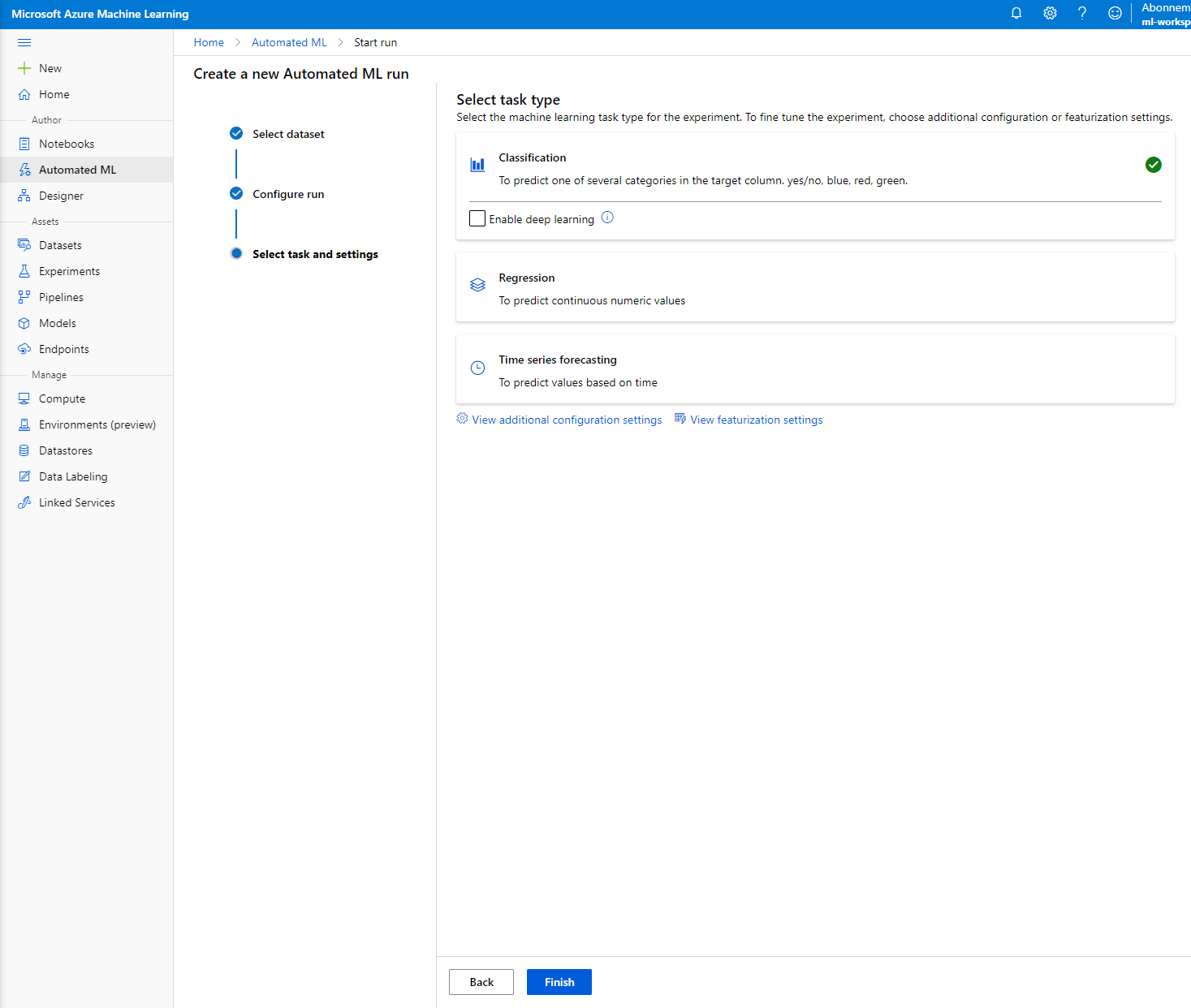
-
रन पूरा होने के बाद, "Automated ML" टैब पर क्लिक करें, अपने रन पर क्लिक करें, और "Best model summary" कार्ड में एल्गोरिदम पर क्लिक करें।
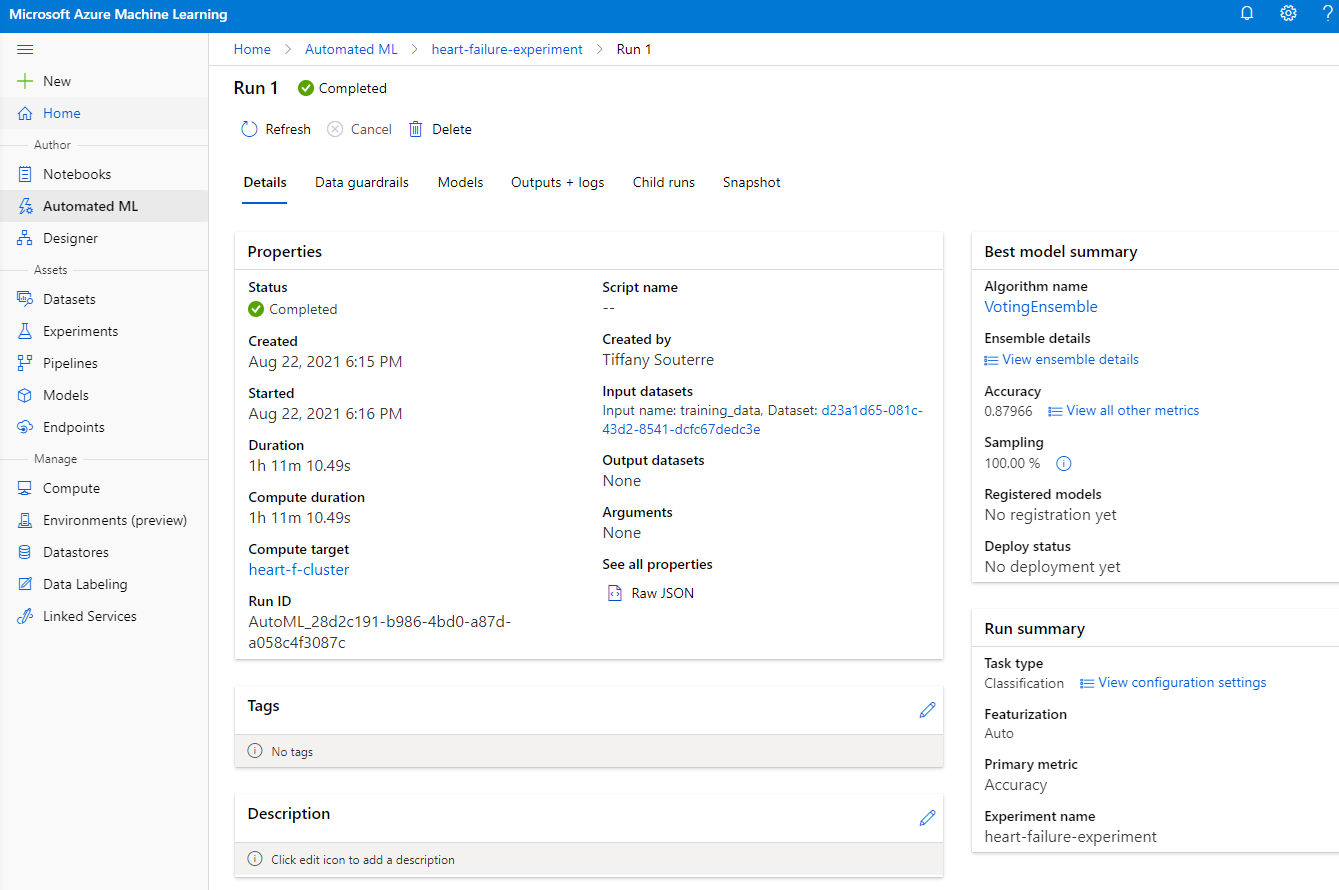
यहां आप AutoML द्वारा उत्पन्न किए गए सर्वश्रेष्ठ मॉडल का विस्तृत विवरण देख सकते हैं। आप "Models" टैब में अन्य मॉडल भी देख सकते हैं। कुछ मिनट लें और "Explanations (preview)" बटन में मॉडल का विश्लेषण करें। जब आप उस मॉडल को चुन लें जिसे आप उपयोग करना चाहते हैं (यहां हम AutoML द्वारा चुने गए सर्वश्रेष्ठ मॉडल का चयन करेंगे), तो हम इसे डिप्लॉय करने की प्रक्रिया देखेंगे।
3. लो कोड/नो कोड मॉडल डिप्लॉयमेंट और एंडपॉइंट उपभोग
3.1 मॉडल डिप्लॉयमेंट
ऑटोमेटेड मशीन लर्निंग इंटरफ़ेस आपको कुछ चरणों में सर्वश्रेष्ठ मॉडल को वेब सेवा के रूप में डिप्लॉय करने की अनुमति देता है। डिप्लॉयमेंट का मतलब है मॉडल का एकीकरण ताकि यह नए डेटा के आधार पर भविष्यवाणियां कर सके और संभावित अवसर क्षेत्रों की पहचान कर सके। इस प्रोजेक्ट के लिए, वेब सेवा पर डिप्लॉयमेंट का मतलब है कि मेडिकल एप्लिकेशन मॉडल का उपयोग कर सकें और अपने मरीजों के हार्ट अटैक के जोखिम की लाइव भविष्यवाणी कर सकें।
सर्वश्रेष्ठ मॉडल के विवरण में, "Deploy" बटन पर क्लिक करें।
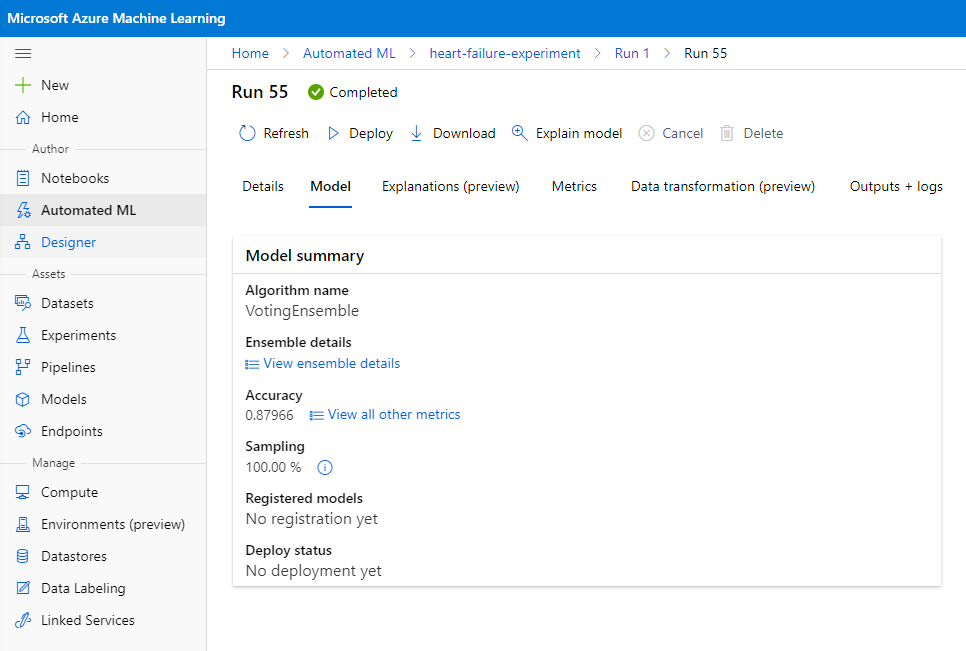
- इसे एक नाम, विवरण, कंप्यूट प्रकार (Azure Container Instance) दें, प्रमाणीकरण सक्षम करें और "Deploy" पर क्लिक करें। इस चरण में लगभग 20 मिनट लग सकते हैं। डिप्लॉयमेंट प्रक्रिया में मॉडल को पंजीकृत करना, संसाधन उत्पन्न करना, और उन्हें वेब सेवा के लिए कॉन्फ़िगर करना शामिल है। "Deploy status" के तहत एक स्थिति संदेश दिखाई देगा। स्थिति की जांच के लिए समय-समय पर "Refresh" पर क्लिक करें। जब स्थिति "Healthy" हो, तो इसका मतलब है कि यह डिप्लॉय और चल रहा है।
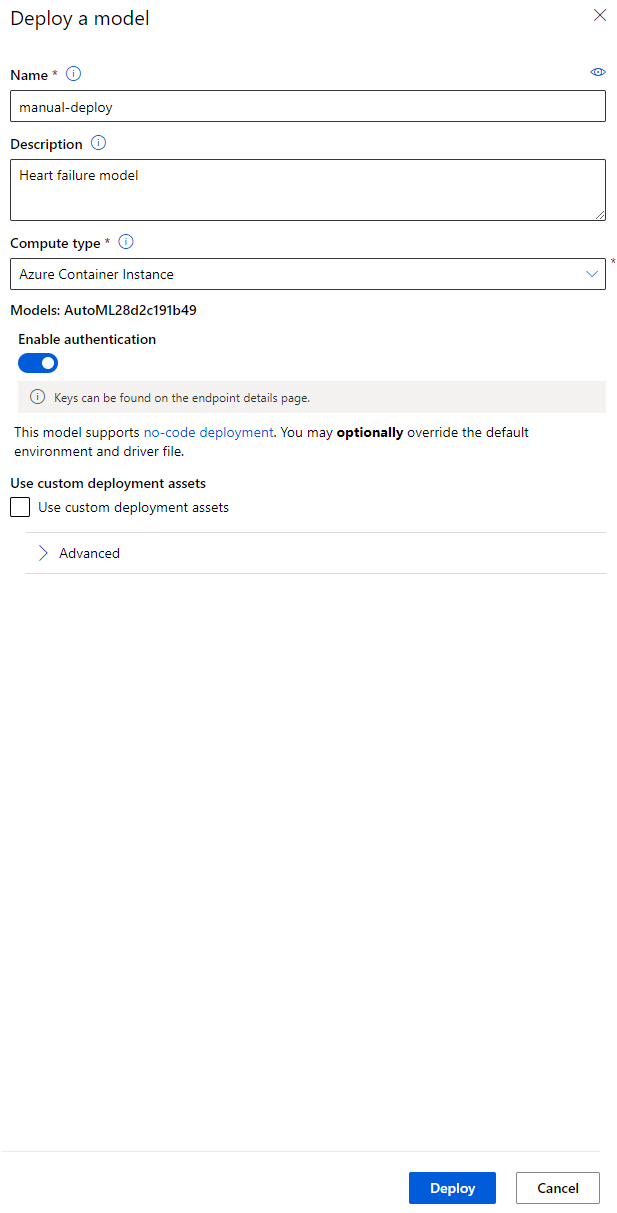
- डिप्लॉयमेंट के बाद, "Endpoint" टैब पर क्लिक करें और आपने जो एंडपॉइंट डिप्लॉय किया है, उस पर क्लिक करें। यहां आप एंडपॉइंट के बारे में सभी विवरण पा सकते हैं।
शानदार! अब जब हमारा मॉडल डिप्लॉय हो गया है, तो हम एंडपॉइंट का उपभोग शुरू कर सकते हैं।
3.2 एंडपॉइंट उपभोग
"Consume" टैब पर क्लिक करें। यहां आपको REST एंडपॉइंट और उपभोग विकल्प में एक पायथन स्क्रिप्ट मिलेगी। पायथन कोड को ध्यान से पढ़ें।
यह स्क्रिप्ट सीधे आपके लोकल मशीन से चलाई जा सकती है और आपके एंडपॉइंट का उपभोग करेगी।
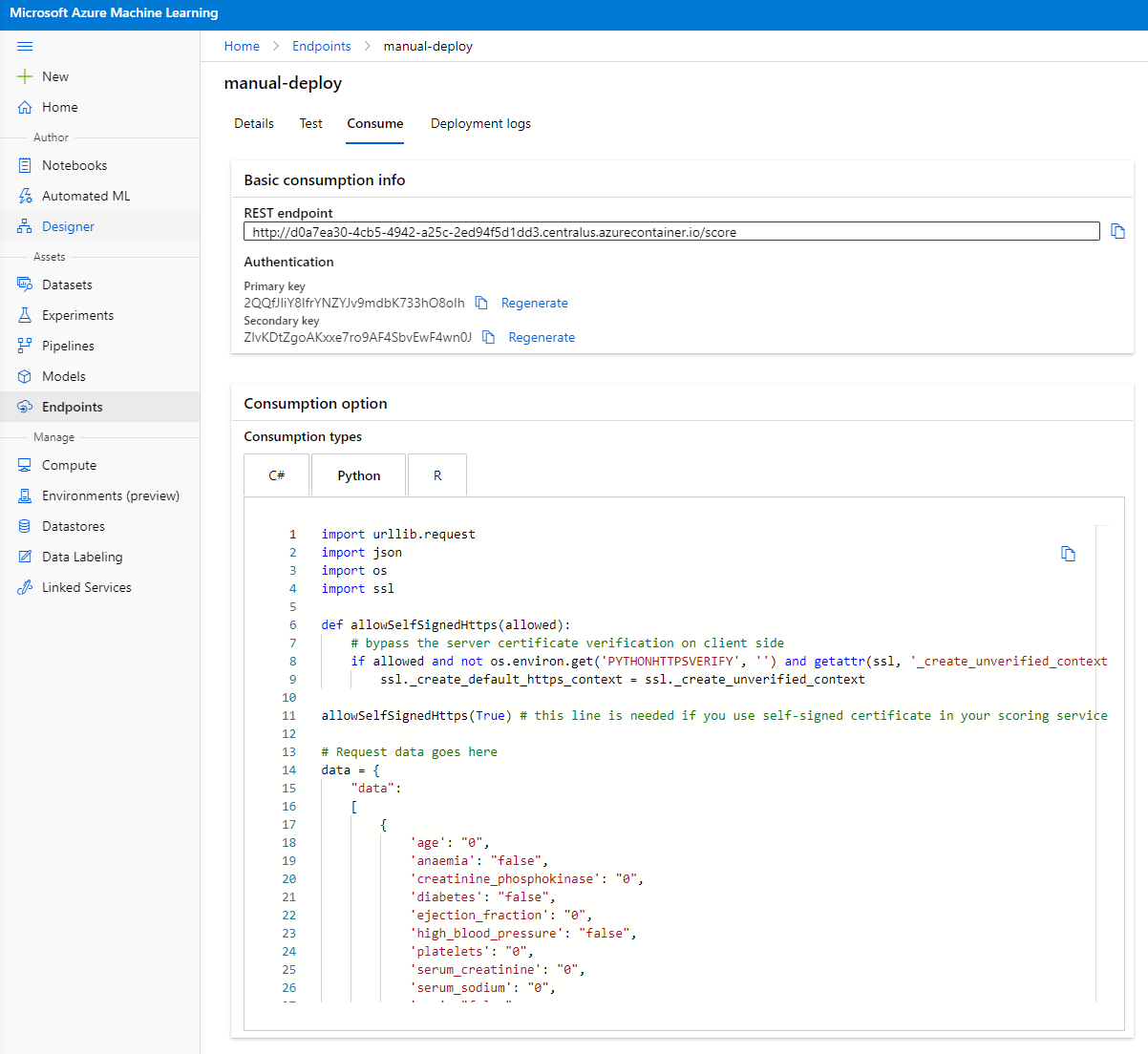
इन दो लाइनों को ध्यान से देखें:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
url वेरिएबल "Consume" टैब में पाया गया REST एंडपॉइंट है और api_key वेरिएबल प्राथमिक कुंजी है, जो "Consume" टैब में भी पाई जाती है (केवल तभी जब आपने प्रमाणीकरण सक्षम किया हो)। यही वह तरीका है जिससे स्क्रिप्ट एंडपॉइंट का उपभोग कर सकती है।
- स्क्रिप्ट चलाने पर, आपको निम्नलिखित आउटपुट दिखाई देना चाहिए:
b'"{\\"result\\": [true]}"'
इसका मतलब है कि दिए गए डेटा के लिए हार्ट फेल्योर की भविष्यवाणी सही है। यह समझ में आता है क्योंकि यदि आप स्क्रिप्ट में स्वचालित रूप से उत्पन्न डेटा को अधिक ध्यान से देखें, तो सब कुछ डिफ़ॉल्ट रूप से 0 और false है। आप निम्नलिखित इनपुट सैंपल के साथ डेटा बदल सकते हैं:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
स्क्रिप्ट को यह आउटपुट देना चाहिए:
python b'"{\\"result\\": [true, false]}"'
बधाई हो! आपने मॉडल को डिप्लॉय और उपभोग किया और इसे Azure ML पर प्रशिक्षित किया!
NOTE: प्रोजेक्ट समाप्त होने के बाद, सभी संसाधनों को हटाना न भूलें।
🚀 चुनौती
AutoML द्वारा उत्पन्न शीर्ष मॉडलों के विवरण और स्पष्टीकरण को ध्यान से देखें। यह समझने की कोशिश करें कि सर्वश्रेष्ठ मॉडल अन्य मॉडलों से बेहतर क्यों है। किन एल्गोरिदम की तुलना की गई? उनके बीच क्या अंतर हैं? इस मामले में सर्वश्रेष्ठ मॉडल बेहतर प्रदर्शन क्यों कर रहा है?
पोस्ट-लेक्चर क्विज़
समीक्षा और स्व-अध्ययन
इस पाठ में, आपने सीखा कि क्लाउड में लो कोड/नो कोड तरीके से हार्ट फेल्योर जोखिम की भविष्यवाणी करने के लिए एक मॉडल को प्रशिक्षित, डिप्लॉय और उपभोग कैसे करें। यदि आपने अभी तक ऐसा नहीं किया है, तो AutoML द्वारा उत्पन्न शीर्ष मॉडलों के स्पष्टीकरण में गहराई से जाएं और यह समझने की कोशिश करें कि सर्वश्रेष्ठ मॉडल अन्य मॉडलों से बेहतर क्यों है।
आप इस डॉक्यूमेंटेशन को पढ़कर लो कोड/नो कोड AutoML में और गहराई तक जा सकते हैं।
असाइनमेंट
Azure ML पर लो कोड/नो कोड डेटा साइंस प्रोजेक्ट
अस्वीकरण:
यह दस्तावेज़ AI अनुवाद सेवा Co-op Translator का उपयोग करके अनुवादित किया गया है। जबकि हम सटीकता सुनिश्चित करने का प्रयास करते हैं, कृपया ध्यान दें कि स्वचालित अनुवाद में त्रुटियां या अशुद्धियां हो सकती हैं। मूल भाषा में उपलब्ध मूल दस्तावेज़ को प्रामाणिक स्रोत माना जाना चाहिए। महत्वपूर्ण जानकारी के लिए, पेशेवर मानव अनुवाद की सिफारिश की जाती है। इस अनुवाद के उपयोग से उत्पन्न किसी भी गलतफहमी या गलत व्याख्या के लिए हम उत्तरदायी नहीं हैं।