|
|
6 months ago | |
|---|---|---|
| .. | ||
| solution | 11 months ago | |
| README.md | 6 months ago | |
| assignment.md | 6 months ago | |
| notebook.ipynb | 11 months ago | |
README.md
La Science des Données dans le Cloud : La méthode "Azure ML SDK"
 |
|---|
| La Science des Données dans le Cloud : Azure ML SDK - Sketchnote par @nitya |
Table des matières :
- La Science des Données dans le Cloud : La méthode "Azure ML SDK"
Quiz avant le cours
1. Introduction
1.1 Qu'est-ce que l'Azure ML SDK ?
Les data scientists et les développeurs en intelligence artificielle utilisent le SDK Azure Machine Learning pour créer et exécuter des workflows de machine learning avec le service Azure Machine Learning. Vous pouvez interagir avec le service dans n'importe quel environnement Python, y compris Jupyter Notebooks, Visual Studio Code ou votre IDE Python préféré.
Les principales fonctionnalités du SDK incluent :
- Explorer, préparer et gérer le cycle de vie de vos jeux de données utilisés dans les expériences de machine learning.
- Gérer les ressources cloud pour surveiller, enregistrer et organiser vos expériences de machine learning.
- Entraîner des modèles localement ou en utilisant des ressources cloud, y compris l'entraînement accéléré par GPU.
- Utiliser le machine learning automatisé, qui accepte des paramètres de configuration et des données d'entraînement. Il itère automatiquement sur les algorithmes et les réglages des hyperparamètres pour trouver le meilleur modèle pour effectuer des prédictions.
- Déployer des services web pour transformer vos modèles entraînés en services RESTful consommables dans n'importe quelle application.
En savoir plus sur le SDK Azure Machine Learning
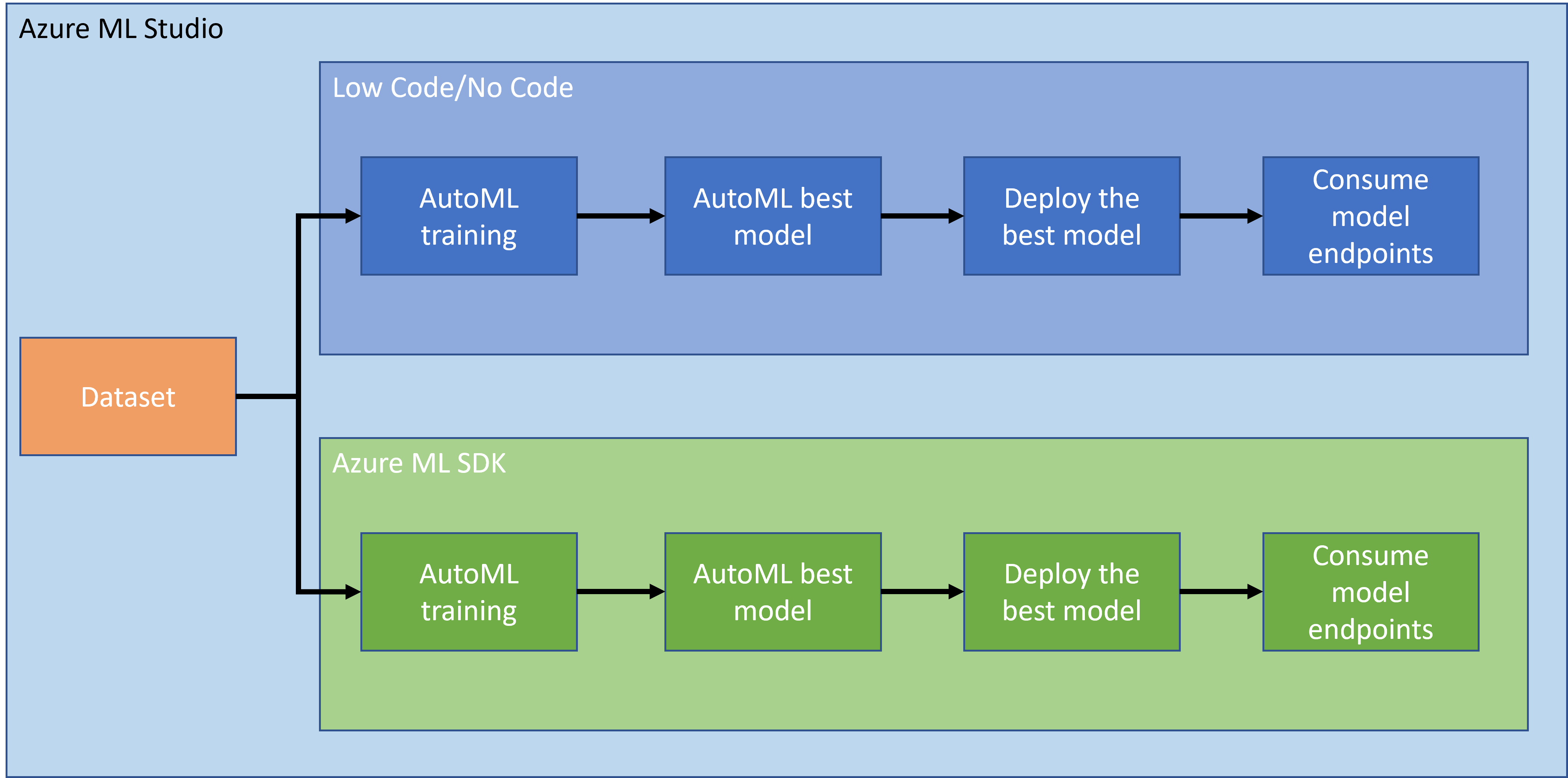
Dans la leçon précédente, nous avons vu comment entraîner, déployer et consommer un modèle de manière Low code/No code. Nous avons utilisé le jeu de données sur l'insuffisance cardiaque pour générer un modèle de prédiction. Dans cette leçon, nous allons faire exactement la même chose, mais en utilisant le SDK Azure Machine Learning.
1.2 Projet de prédiction d'insuffisance cardiaque et introduction au jeu de données
Consultez ici l'introduction au projet de prédiction d'insuffisance cardiaque et au jeu de données.
2. Entraîner un modèle avec l'Azure ML SDK
2.1 Créer un espace de travail Azure ML
Pour simplifier, nous allons travailler sur un notebook Jupyter. Cela suppose que vous avez déjà un espace de travail et une instance de calcul. Si vous avez déjà un espace de travail, vous pouvez directement passer à la section 2.3 Création de notebook.
Sinon, veuillez suivre les instructions de la section 2.1 Créer un espace de travail Azure ML dans la leçon précédente pour créer un espace de travail.
2.2 Créer une instance de calcul
Dans l'espace de travail Azure ML que nous avons créé précédemment, allez dans le menu de calcul et vous verrez les différentes ressources de calcul disponibles.

Créons une instance de calcul pour provisionner un notebook Jupyter.
- Cliquez sur le bouton + Nouveau.
- Donnez un nom à votre instance de calcul.
- Choisissez vos options : CPU ou GPU, taille de la VM et nombre de cœurs.
- Cliquez sur le bouton Créer.
Félicitations, vous venez de créer une instance de calcul ! Nous utiliserons cette instance de calcul pour créer un notebook dans la section Création de notebooks.
2.3 Charger le jeu de données
Consultez la leçon précédente dans la section 2.3 Charger le jeu de données si vous n'avez pas encore téléchargé le jeu de données.
2.4 Créer des notebooks
NOTE: Pour l'étape suivante, vous pouvez soit créer un nouveau notebook à partir de zéro, soit télécharger le notebook que nous avons créé dans votre Azure ML Studio. Pour le télécharger, cliquez simplement sur le menu "Notebook" et téléchargez le notebook.
Les notebooks sont une partie très importante du processus de science des données. Ils peuvent être utilisés pour effectuer une analyse exploratoire des données (EDA), appeler un cluster de calcul pour entraîner un modèle, ou appeler un cluster d'inférence pour déployer un endpoint.
Pour créer un notebook, nous avons besoin d'un nœud de calcul qui sert l'instance de notebook Jupyter. Retournez à l'espace de travail Azure ML et cliquez sur Instances de calcul. Dans la liste des instances de calcul, vous devriez voir l'instance de calcul que nous avons créée précédemment.
- Dans la section Applications, cliquez sur l'option Jupyter.
- Cochez la case "Oui, je comprends" et cliquez sur le bouton Continuer.

- Cela devrait ouvrir un nouvel onglet de navigateur avec votre instance de notebook Jupyter comme suit. Cliquez sur le bouton "Nouveau" pour créer un notebook.

Maintenant que nous avons un notebook, nous pouvons commencer à entraîner le modèle avec Azure ML SDK.
2.5 Entraîner un modèle
Tout d'abord, si vous avez un doute, consultez la documentation Azure ML SDK. Elle contient toutes les informations nécessaires pour comprendre les modules que nous allons voir dans cette leçon.
2.5.1 Configurer l'espace de travail, l'expérience, le cluster de calcul et le jeu de données
Vous devez charger l'espace de travail à partir du fichier de configuration en utilisant le code suivant :
from azureml.core import Workspace
ws = Workspace.from_config()
Cela retourne un objet de type Workspace qui représente l'espace de travail. Ensuite, vous devez créer une expérience en utilisant le code suivant :
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
Pour obtenir ou créer une expérience à partir d'un espace de travail, vous demandez l'expérience en utilisant son nom. Le nom de l'expérience doit comporter entre 3 et 36 caractères, commencer par une lettre ou un chiffre, et ne contenir que des lettres, des chiffres, des underscores et des tirets. Si l'expérience n'est pas trouvée dans l'espace de travail, une nouvelle expérience est créée.
Maintenant, vous devez créer un cluster de calcul pour l'entraînement en utilisant le code suivant. Notez que cette étape peut prendre quelques minutes.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Vous pouvez obtenir le jeu de données à partir de l'espace de travail en utilisant le nom du jeu de données de la manière suivante :
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 Configuration AutoML et entraînement
Pour configurer AutoML, utilisez la classe AutoMLConfig.
Comme décrit dans la documentation, il existe de nombreux paramètres avec lesquels vous pouvez jouer. Pour ce projet, nous utiliserons les paramètres suivants :
experiment_timeout_minutes: Durée maximale (en minutes) pendant laquelle l'expérience est autorisée à s'exécuter avant d'être automatiquement arrêtée et que les résultats soient automatiquement disponibles.max_concurrent_iterations: Nombre maximal d'itérations d'entraînement simultanées autorisées pour l'expérience.primary_metric: La métrique principale utilisée pour déterminer l'état de l'expérience.compute_target: La cible de calcul Azure Machine Learning pour exécuter l'expérience de machine learning automatisé.task: Type de tâche à exécuter. Les valeurs peuvent être 'classification', 'regression' ou 'forecasting' selon le type de problème de machine learning automatisé à résoudre.training_data: Les données d'entraînement à utiliser dans l'expérience. Elles doivent contenir à la fois les caractéristiques d'entraînement et une colonne de labels (optionnellement une colonne de poids d'échantillon).label_column_name: Le nom de la colonne de labels.path: Le chemin complet vers le dossier du projet Azure Machine Learning.enable_early_stopping: Indique si l'arrêt anticipé doit être activé si le score ne s'améliore pas à court terme.featurization: Indicateur pour savoir si l'étape de featurisation doit être effectuée automatiquement ou non, ou si une featurisation personnalisée doit être utilisée.debug_log: Le fichier journal pour écrire les informations de débogage.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Maintenant que vous avez configuré votre configuration, vous pouvez entraîner le modèle en utilisant le code suivant. Cette étape peut prendre jusqu'à une heure selon la taille de votre cluster.
remote_run = experiment.submit(automl_config)
Vous pouvez exécuter le widget RunDetails pour afficher les différentes expériences.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Déploiement du modèle et consommation de l'endpoint avec l'Azure ML SDK
3.1 Sauvegarder le meilleur modèle
Le remote_run est un objet de type AutoMLRun. Cet objet contient la méthode get_output() qui retourne la meilleure exécution et le modèle ajusté correspondant.
best_run, fitted_model = remote_run.get_output()
Vous pouvez voir les paramètres utilisés pour le meilleur modèle en imprimant simplement le fitted_model et voir les propriétés du meilleur modèle en utilisant la méthode get_properties().
best_run.get_properties()
Ensuite, enregistrez le modèle avec la méthode register_model.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Déploiement du modèle
Une fois le meilleur modèle sauvegardé, nous pouvons le déployer avec la classe InferenceConfig. InferenceConfig représente les paramètres de configuration pour un environnement personnalisé utilisé pour le déploiement. La classe AciWebservice représente un modèle de machine learning déployé en tant qu'endpoint de service web sur Azure Container Instances. Un service déployé est créé à partir d'un modèle, d'un script et de fichiers associés. Le service web résultant est un endpoint HTTP équilibré avec une API REST. Vous pouvez envoyer des données à cette API et recevoir la prédiction retournée par le modèle.
Le modèle est déployé en utilisant la méthode deploy.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
Cette étape devrait prendre quelques minutes.
3.3 Consommation de l'endpoint
Vous consommez votre endpoint en créant un exemple d'entrée :
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
Et ensuite, vous pouvez envoyer cette entrée à votre modèle pour obtenir une prédiction :
response = aci_service.run(input_data=test_sample)
response
Cela devrait produire '{"result": [false]}'. Cela signifie que les données du patient que nous avons envoyées au point de terminaison ont généré la prédiction false, ce qui indique que cette personne n'est probablement pas sujette à une crise cardiaque.
Félicitations ! Vous venez d'utiliser le modèle déployé et entraîné sur Azure ML avec le SDK Azure ML !
NOTE: Une fois le projet terminé, n'oubliez pas de supprimer toutes les ressources.
🚀 Défi
Il y a beaucoup d'autres choses que vous pouvez faire avec le SDK, malheureusement, nous ne pouvons pas toutes les aborder dans cette leçon. Mais bonne nouvelle, apprendre à parcourir la documentation du SDK peut vous mener loin par vous-même. Consultez la documentation du SDK Azure ML et trouvez la classe Pipeline qui vous permet de créer des pipelines. Un Pipeline est une collection d'étapes pouvant être exécutées comme un flux de travail.
INDICE : Rendez-vous sur la documentation du SDK et tapez des mots-clés dans la barre de recherche comme "Pipeline". Vous devriez voir la classe azureml.pipeline.core.Pipeline dans les résultats de recherche.
Quiz après la leçon
Révision & Étude personnelle
Dans cette leçon, vous avez appris à entraîner, déployer et utiliser un modèle pour prédire le risque d'insuffisance cardiaque avec le SDK Azure ML dans le cloud. Consultez cette documentation pour plus d'informations sur le SDK Azure ML. Essayez de créer votre propre modèle avec le SDK Azure ML.
Devoir
Projet Data Science avec le SDK Azure ML
Avertissement :
Ce document a été traduit à l'aide du service de traduction automatique Co-op Translator. Bien que nous nous efforcions d'assurer l'exactitude, veuillez noter que les traductions automatisées peuvent contenir des erreurs ou des inexactitudes. Le document original dans sa langue d'origine doit être considéré comme la source faisant autorité. Pour des informations critiques, il est recommandé de faire appel à une traduction humaine professionnelle. Nous déclinons toute responsabilité en cas de malentendus ou d'interprétations erronées résultant de l'utilisation de cette traduction.