|
|
6 months ago | |
|---|---|---|
| .. | ||
| solution | 11 months ago | |
| README.md | 6 months ago | |
| assignment.md | 6 months ago | |
| notebook.ipynb | 11 months ago | |
README.md
Tiedettä pilvessä: "Azure ML SDK" -lähestymistapa
 |
|---|
| Tiedettä pilvessä: Azure ML SDK - Sketchnote by @nitya |
Sisällysluettelo:
- Tiedettä pilvessä: "Azure ML SDK" -lähestymistapa
Esituntikoe
1. Johdanto
1.1 Mikä on Azure ML SDK?
Data-analyytikot ja tekoälykehittäjät käyttävät Azure Machine Learning SDK:ta koneoppimistyönkulkujen rakentamiseen ja suorittamiseen Azure Machine Learning -palvelun avulla. Palvelua voi käyttää missä tahansa Python-ympäristössä, kuten Jupyter Notebooksissa, Visual Studio Codessa tai omassa suosikkiohjelmointiympäristössäsi.
SDK:n keskeiset osa-alueet:
- Tutki, valmistele ja hallitse koneoppimiskokeissa käytettävien aineistojen elinkaarta.
- Hallitse pilviresursseja koneoppimiskokeiden valvontaa, lokitusta ja organisointia varten.
- Kouluta malleja joko paikallisesti tai pilviresursseja hyödyntäen, mukaan lukien GPU-kiihdytetty mallikoulutus.
- Käytä automaattista koneoppimista, joka hyväksyy konfiguraatioparametrit ja koulutusaineiston. Se käy automaattisesti läpi algoritmeja ja hyperparametrien asetuksia löytääkseen parhaan mallin ennusteiden suorittamiseen.
- Ota käyttöön verkkopalveluita, jotka muuttavat koulutetut mallisi RESTful-palveluiksi, joita voi käyttää missä tahansa sovelluksessa.
Lue lisää Azure Machine Learning SDK:sta
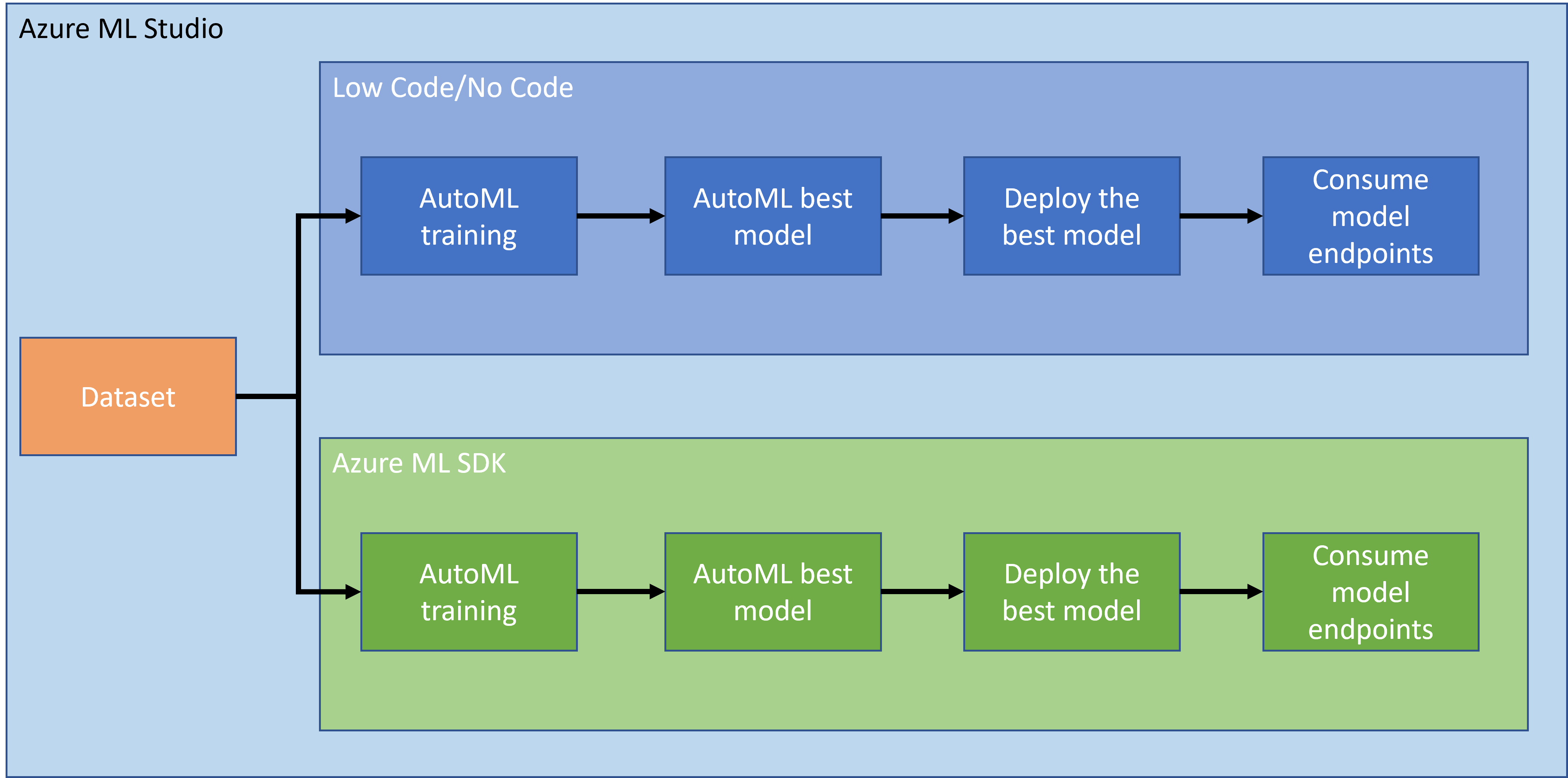
Edellisessä oppitunnissa näimme, kuinka malli koulutetaan, otetaan käyttöön ja hyödynnetään Low code/No code -lähestymistavalla. Käytimme sydämen vajaatoiminnan aineistoa ennustemallin luomiseen. Tässä oppitunnissa teemme täsmälleen saman, mutta käytämme Azure Machine Learning SDK:ta.
1.2 Sydämen vajaatoiminnan ennustamisprojekti ja aineiston esittely
Katso täältä sydämen vajaatoiminnan ennustamisprojektin ja aineiston esittely.
2. Mallin kouluttaminen Azure ML SDK:lla
2.1 Azure ML -työtilan luominen
Yksinkertaisuuden vuoksi työskentelemme Jupyter-muistikirjassa. Tämä tarkoittaa, että sinulla on jo työtila ja laskentainstanssi. Jos sinulla on jo työtila, voit siirtyä suoraan kohtaan 2.3 Muistikirjan luominen.
Jos ei, seuraa ohjeita kohdassa 2.1 Azure ML -työtilan luominen edellisessä oppitunnissa luodaksesi työtilan.
2.2 Laskentainstanssin luominen
Azure ML -työtilassa, jonka loimme aiemmin, siirry Compute-valikkoon, ja näet käytettävissä olevat laskentaresurssit.

Luodaan laskentainstanssi Jupyter-muistikirjan käyttöä varten.
- Klikkaa + Uusi -painiketta.
- Anna laskentainstanssille nimi.
- Valitse vaihtoehdot: CPU tai GPU, virtuaalikoneen koko ja ytimien määrä.
- Klikkaa Luo-painiketta.
Onnittelut, olet juuri luonut laskentainstanssin! Käytämme tätä laskentainstanssia muistikirjan luomiseen kohdassa Muistikirjojen luominen.
2.3 Aineiston lataaminen
Jos et ole vielä ladannut aineistoa, katso ohjeet kohdasta 2.3 Aineiston lataaminen edellisessä oppitunnissa.
2.4 Muistikirjojen luominen
HUOM: Seuraavassa vaiheessa voit joko luoda uuden muistikirjan alusta alkaen tai ladata luomamme muistikirjan Azure ML Studioon. Lataaminen onnistuu klikkaamalla "Notebook"-valikkoa ja lataamalla muistikirjan.
Muistikirjat ovat erittäin tärkeä osa data-analytiikkaprosessia. Niitä voidaan käyttää esimerkiksi aineiston tutkimiseen, mallin kouluttamiseen laskentaklusterilla tai päätepisteen käyttöönottoon inferenssiklusterilla.
Muistikirjan luomiseen tarvitsemme laskentainstanssin, joka toimii Jupyter-muistikirjan palvelimena. Palaa Azure ML -työtilaan ja klikkaa Laskentainstanssit. Laskentainstanssien listasta löydät aiemmin luomamme laskentainstanssin.
- Sovellukset-osiossa klikkaa Jupyter-vaihtoehtoa.
- Valitse "Kyllä, ymmärrän" -ruutu ja klikkaa Jatka-painiketta.

- Tämä avaa uuden selainvälilehden, jossa näkyy Jupyter-muistikirjasi. Klikkaa "Uusi"-painiketta luodaksesi muistikirjan.

Nyt kun meillä on muistikirja, voimme aloittaa mallin kouluttamisen Azure ML SDK:lla.
2.5 Mallin kouluttaminen
Ensinnäkin, jos olet epävarma, katso Azure ML SDK -dokumentaatio. Se sisältää kaiken tarvittavan tiedon tämän oppitunnin moduuleista.
2.5.1 Työtilan, kokeen, laskentaklusterin ja aineiston määrittäminen
Lataa workspace konfiguraatiotiedostosta seuraavalla koodilla:
from azureml.core import Workspace
ws = Workspace.from_config()
Tämä palauttaa Workspace-tyyppisen objektin, joka edustaa työtilaa. Seuraavaksi luo experiment seuraavalla koodilla:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
Voit hakea tai luoda kokeen työtilasta pyytämällä kokeen nimen perusteella. Kokeen nimen tulee olla 3–36 merkkiä pitkä, alkaa kirjaimella tai numerolla ja sisältää vain kirjaimia, numeroita, alaviivoja ja viivoja. Jos koetta ei löydy työtilasta, luodaan uusi koe.
Seuraavaksi luo laskentaklusteri koulutusta varten seuraavalla koodilla. Huomaa, että tämä vaihe voi kestää muutaman minuutin.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Voit hakea aineiston työtilasta aineiston nimen perusteella seuraavasti:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 AutoML-konfiguraatio ja koulutus
AutoML-konfiguraation määrittämiseen käytetään AutoMLConfig-luokkaa.
Kuten dokumentaatiossa kuvataan, voit säätää monia parametreja. Tässä projektissa käytämme seuraavia parametreja:
experiment_timeout_minutes: Kokeen sallittu enimmäisaika (minuuteissa), jonka jälkeen se pysäytetään automaattisesti ja tulokset tehdään saataville.max_concurrent_iterations: Kokeen sallittu enimmäismäärä samanaikaisia koulutuskierroksia.primary_metric: Ensisijainen metriikka, jota käytetään kokeen tilan määrittämiseen.compute_target: Azure Machine Learning -laskentakohde, jossa automaattinen koneoppimiskoe suoritetaan.task: Suoritettavan tehtävän tyyppi. Arvot voivat olla 'classification', 'regression' tai 'forecasting' riippuen ratkaistavasta automaattisen koneoppimisen ongelmasta.training_data: Kokeessa käytettävä koulutusaineisto. Sen tulee sisältää sekä koulutusominaisuudet että luokittelusarakkeen (valinnaisesti myös painotussarakkeen).label_column_name: Luokittelusarakkeen nimi.path: Azure Machine Learning -projektikansion täydellinen polku.enable_early_stopping: Ota käyttöön varhainen pysäytys, jos tulos ei parane lyhyellä aikavälillä.featurization: Ilmaisin, tehdäänkö featurisointi automaattisesti, mukautetusti vai ei ollenkaan.debug_log: Lokitiedosto, johon kirjoitetaan virheenkorjaustiedot.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Kun konfiguraatio on määritetty, voit kouluttaa mallin seuraavalla koodilla. Tämä vaihe voi kestää jopa tunnin klusterin koosta riippuen.
remote_run = experiment.submit(automl_config)
Voit käyttää RunDetails-widgettiä nähdäksesi eri kokeet.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Mallin käyttöönotto ja päätepisteen hyödyntäminen Azure ML SDK:lla
3.1 Parhaan mallin tallentaminen
remote_run on AutoMLRun-tyyppinen objekti. Tämä objekti sisältää get_output()-metodin, joka palauttaa parhaan ajon ja vastaavan sovitetun mallin.
best_run, fitted_model = remote_run.get_output()
Voit tarkastella parhaan mallin parametreja tulostamalla fitted_model-objektin ja nähdä mallin ominaisuudet käyttämällä get_properties()-metodia.
best_run.get_properties()
Rekisteröi malli register_model-metodilla.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Mallin käyttöönotto
Kun paras malli on tallennettu, voimme ottaa sen käyttöön InferenceConfig-luokan avulla. InferenceConfig edustaa mukautetun ympäristön konfiguraatioasetuksia käyttöönottoa varten. AciWebservice-luokka edustaa koneoppimismallia, joka on otettu käyttöön verkkopalvelupäätepisteenä Azure Container Instances -palvelussa. Käyttöönotettu palvelu luodaan mallista, skriptistä ja niihin liittyvistä tiedostoista. Tuloksena oleva verkkopalvelu on kuormantasattu HTTP-päätepiste, jossa on REST API. Voit lähettää tietoja tähän API:in ja saada mallin palauttaman ennusteen.
Malli otetaan käyttöön deploy-metodilla.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
Tämä vaihe voi kestää muutaman minuutin.
3.3 Päätepisteen hyödyntäminen
Hyödynnä päätepistettä luomalla esimerkkisyöte:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
Tämän jälkeen voit lähettää syötteen mallillesi ennustetta varten:
response = aci_service.run(input_data=test_sample)
response
Tämän pitäisi tuottaa '{"result": [false]}'. Tämä tarkoittaa, että potilaan syöte, jonka lähetimme päätepisteeseen, tuotti ennusteen false, mikä tarkoittaa, että tämä henkilö ei todennäköisesti saa sydänkohtausta.
Onnittelut! Olet juuri käyttänyt Azure ML:ssä koulutettua ja käyttöön otettua mallia Azure ML SDK:n avulla!
NOTE: Kun olet valmis projektin kanssa, muista poistaa kaikki resurssit.
🚀 Haaste
SDK:n avulla voit tehdä monia muitakin asioita, mutta valitettavasti emme voi käsitellä niitä kaikkia tässä oppitunnissa. Hyvä uutinen on, että oppimalla selaamaan SDK-dokumentaatiota pääset pitkälle omatoimisesti. Tutustu Azure ML SDK -dokumentaatioon ja etsi Pipeline-luokka, jonka avulla voit luoda putkistoja. Putkisto on kokoelma vaiheita, jotka voidaan suorittaa työnkulun muodossa.
VIHJE: Mene SDK-dokumentaatioon ja kirjoita hakupalkkiin avainsanoja, kuten "Pipeline". Hakutuloksissa pitäisi näkyä azureml.pipeline.core.Pipeline-luokka.
Oppitunnin jälkeinen kysely
Kertaus ja itseopiskelu
Tässä oppitunnissa opit, kuinka kouluttaa, ottaa käyttöön ja käyttää mallia sydämen vajaatoiminnan riskin ennustamiseen Azure ML SDK:n avulla pilvessä. Katso tämä dokumentaatio saadaksesi lisätietoja Azure ML SDK:sta. Yritä luoda oma mallisi Azure ML SDK:n avulla.
Tehtävä
Data Science -projekti Azure ML SDK:ta käyttäen
Vastuuvapauslauseke:
Tämä asiakirja on käännetty käyttämällä tekoälypohjaista käännöspalvelua Co-op Translator. Vaikka pyrimme tarkkuuteen, huomioithan, että automaattiset käännökset voivat sisältää virheitä tai epätarkkuuksia. Alkuperäistä asiakirjaa sen alkuperäisellä kielellä tulisi pitää ensisijaisena lähteenä. Kriittisen tiedon osalta suositellaan ammattimaista ihmiskäännöstä. Emme ole vastuussa tämän käännöksen käytöstä johtuvista väärinkäsityksistä tai virhetulkinnoista.