|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
کار با دادهها: دادههای غیررابطهای
 |
|---|
| کار با دادههای NoSQL - طرح دستی توسط @nitya |
پیشازدرس: آزمون کوتاه
دادهها محدود به پایگاههای داده رابطهای نیستند. این درس بر دادههای غیررابطهای تمرکز دارد و اصول اولیه صفحات گسترده و NoSQL را پوشش میدهد.
صفحات گسترده
صفحات گسترده یکی از روشهای محبوب برای ذخیره و بررسی دادهها هستند، زیرا راهاندازی و شروع کار با آنها نیاز به تلاش کمتری دارد. در این درس، با اجزای اصلی یک صفحه گسترده، فرمولها و توابع آشنا خواهید شد. مثالها با استفاده از Microsoft Excel نشان داده میشوند، اما بیشتر بخشها و موضوعات در مقایسه با سایر نرمافزارهای صفحات گسترده نامها و مراحل مشابهی خواهند داشت.

یک صفحه گسترده یک فایل است که در سیستم فایل یک کامپیوتر، دستگاه یا سیستم فایل ابری قابل دسترسی است. نرمافزار ممکن است مبتنی بر مرورگر باشد یا بهصورت یک برنامه نصبشده روی کامپیوتر یا اپلیکیشن دانلودشده باشد. در Excel، این فایلها بهعنوان دفترچهکار تعریف میشوند و این اصطلاح در ادامه این درس استفاده خواهد شد.
یک دفترچهکار شامل یک یا چند برگهکار است که هر برگه با زبانهها برچسبگذاری شده است. درون هر برگهکار مستطیلهایی به نام سلول وجود دارد که دادههای واقعی را در خود جای میدهند. یک سلول محل تقاطع یک ردیف و یک ستون است، جایی که ستونها با حروف الفبایی و ردیفها با اعداد برچسبگذاری شدهاند. برخی صفحات گسترده در چند ردیف اول دارای سرصفحههایی هستند که دادههای موجود در یک سلول را توصیف میکنند.
با این عناصر اصلی یک دفترچهکار Excel، از یک مثال از قالبهای مایکروسافت که بر مدیریت موجودی تمرکز دارد، برای بررسی بخشهای اضافی یک صفحه گسترده استفاده خواهیم کرد.
مدیریت موجودی
فایل صفحه گستردهای به نام "InventoryExample" یک صفحه گسترده قالببندیشده از اقلام موجود در یک موجودی است که شامل سه برگهکار است. زبانههای این برگهها با نامهای "Inventory List"، "Inventory Pick List" و "Bin Lookup" برچسبگذاری شدهاند. ردیف ۴ در برگه Inventory List سرصفحه است که مقدار هر سلول در ستون سرصفحه را توصیف میکند.
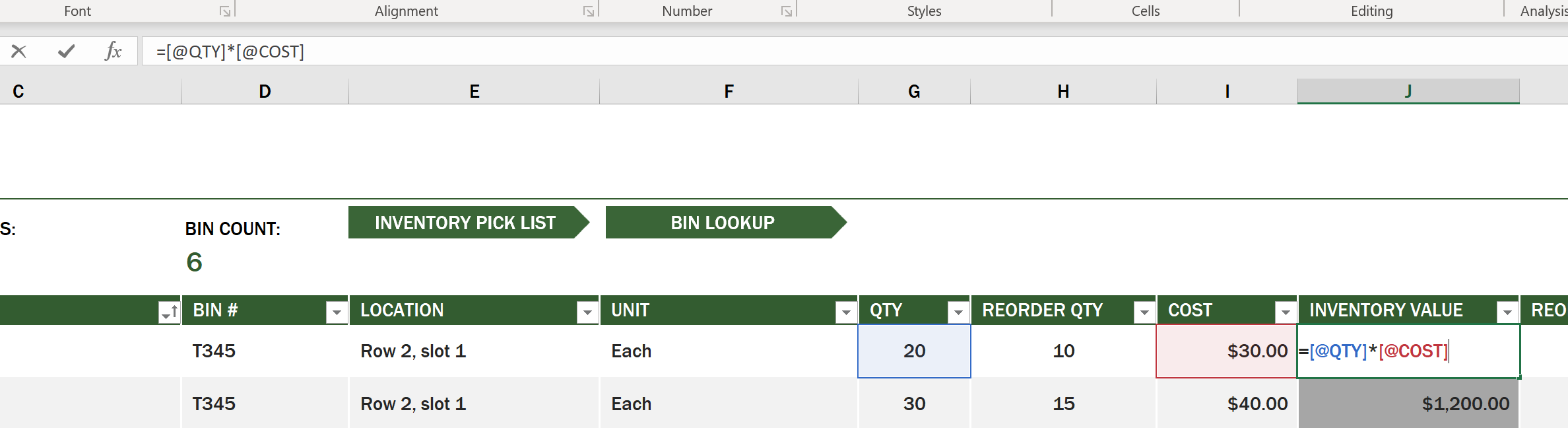
در برخی موارد، مقدار یک سلول به مقادیر سایر سلولها وابسته است تا مقدار خود را تولید کند. صفحه گسترده Inventory List هزینه هر آیتم در موجودی را پیگیری میکند، اما اگر بخواهیم ارزش کل موجودی را بدانیم چه؟ فرمولها عملیاتهایی را روی دادههای سلول انجام میدهند و در این مثال برای محاسبه ارزش موجودی استفاده میشوند. این صفحه گسترده از یک فرمول در ستون Inventory Value استفاده کرده است تا ارزش هر آیتم را با ضرب مقدار در ستون QTY در هزینه در ستون COST محاسبه کند. با دوبار کلیک یا برجسته کردن یک سلول، فرمول نمایش داده میشود. خواهید دید که فرمولها با علامت مساوی شروع میشوند و سپس محاسبه یا عملیات دنبال میشود.
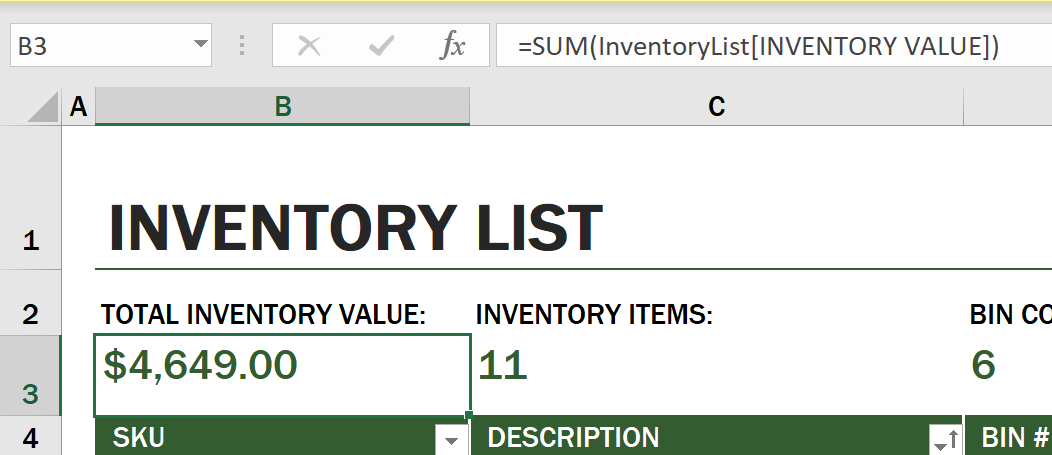
میتوانیم از یک فرمول دیگر برای جمعکردن تمام مقادیر ستون Inventory Value و بهدستآوردن ارزش کل استفاده کنیم. این کار میتواند با جمعکردن هر سلول انجام شود، اما این کار میتواند خستهکننده باشد. Excel دارای توابع یا فرمولهای از پیش تعریفشدهای است که محاسبات را روی مقادیر سلول انجام میدهند. توابع به آرگومانها نیاز دارند که مقادیر موردنیاز برای انجام این محاسبات هستند. وقتی توابع به بیش از یک آرگومان نیاز دارند، باید به ترتیب خاصی فهرست شوند، در غیر این صورت ممکن است تابع مقدار صحیحی را محاسبه نکند. این مثال از تابع SUM استفاده میکند و مقادیر ستون Inventory Value را بهعنوان آرگومان برای جمعکردن و تولید مقدار کل در ردیف ۳، ستون B (که بهعنوان B3 نیز شناخته میشود) استفاده میکند.
NoSQL
NoSQL یک اصطلاح کلی برای روشهای مختلف ذخیره دادههای غیررابطهای است و میتواند بهعنوان "غیر-SQL"، "غیررابطهای" یا "نه فقط SQL" تفسیر شود. این نوع سیستمهای پایگاه داده را میتوان به چهار نوع دستهبندی کرد.
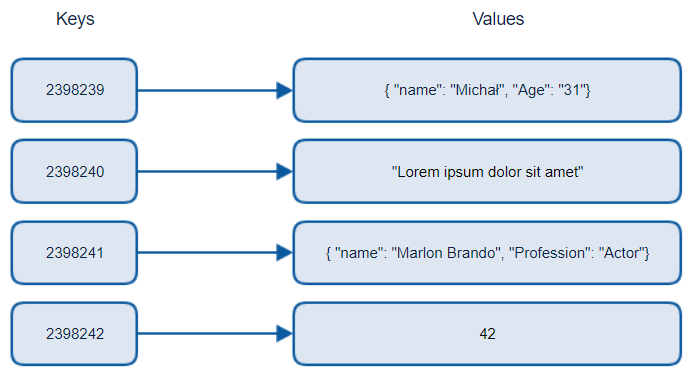
منبع: وبلاگ Michał Białecki
پایگاه دادههای کلید-مقدار کلیدهای منحصربهفرد را که شناسهای منحصربهفرد مرتبط با یک مقدار هستند، جفت میکنند. این جفتها با استفاده از یک جدول هش با یک تابع هش مناسب ذخیره میشوند.
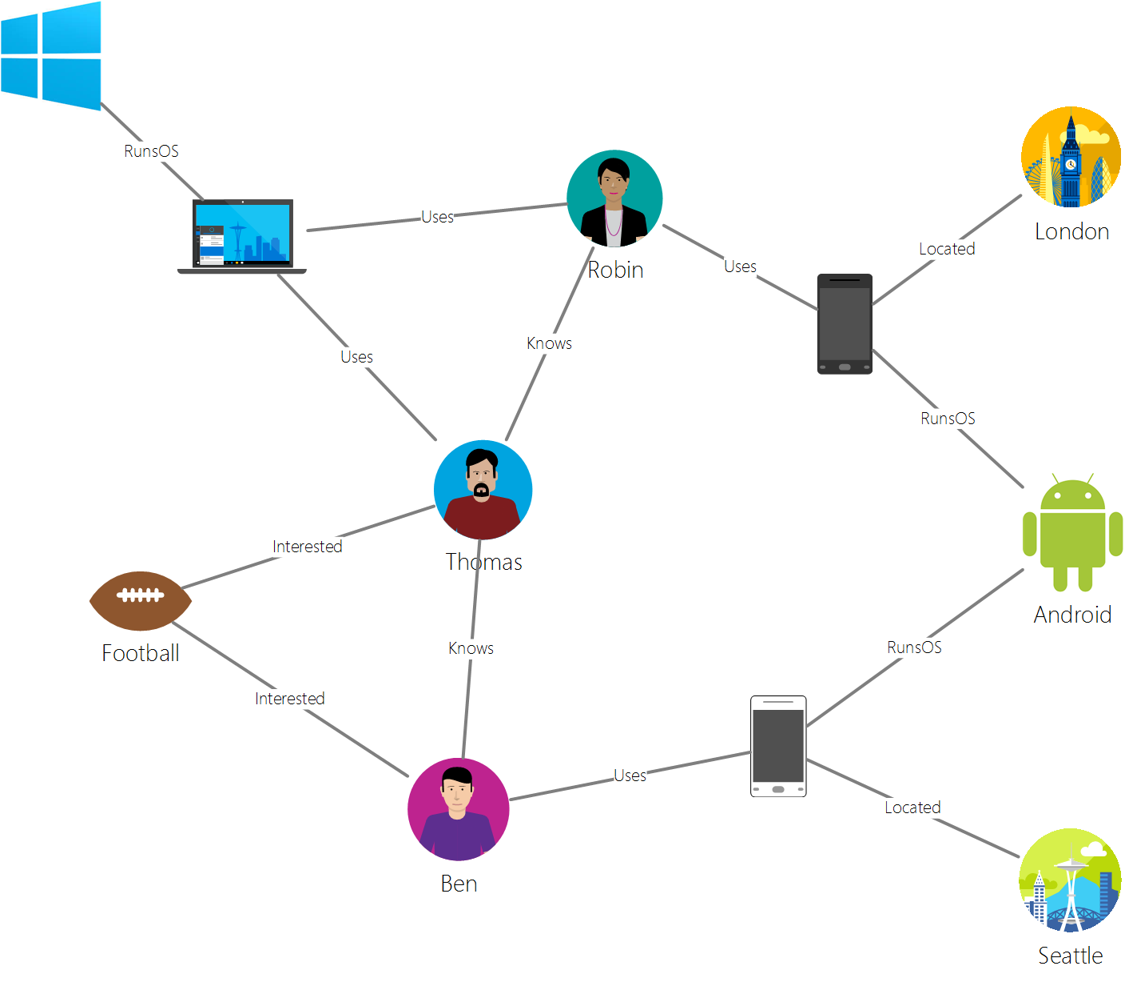
منبع: مایکروسافت
پایگاه دادههای گراف روابط در دادهها را توصیف میکنند و بهصورت مجموعهای از گرهها و یالها نمایش داده میشوند. یک گره نمایانگر یک موجودیت است، چیزی که در دنیای واقعی وجود دارد، مانند یک دانشآموز یا صورتحساب بانکی. یالها رابطه بین دو موجودیت را نشان میدهند. هر گره و یال دارای ویژگیهایی هستند که اطلاعات اضافی درباره هر گره و یال ارائه میدهند.

پایگاه دادههای ستونی دادهها را به ستونها و ردیفها سازماندهی میکنند، مشابه ساختار داده رابطهای، اما هر ستون به گروههایی به نام خانواده ستون تقسیم میشود، جایی که تمام دادههای زیر یک ستون مرتبط هستند و میتوانند بهعنوان یک واحد بازیابی و تغییر داده شوند.
ذخیرهسازی دادههای سندی با Azure Cosmos DB
پایگاه دادههای سندی بر مفهوم پایگاه داده کلید-مقدار بنا شدهاند و از مجموعهای از فیلدها و اشیاء تشکیل شدهاند. این بخش پایگاه دادههای سندی را با استفاده از شبیهساز Cosmos DB بررسی میکند.
پایگاه داده Cosmos DB تعریف "نه فقط SQL" را برآورده میکند، جایی که پایگاه داده سندی Cosmos DB برای جستجوی دادهها به SQL متکی است. درس قبلی درباره SQL اصول اولیه این زبان را پوشش میدهد و میتوانیم برخی از همان جستجوها را در اینجا روی یک پایگاه داده سندی اعمال کنیم. ما از شبیهساز Cosmos DB استفاده خواهیم کرد که به ما امکان میدهد یک پایگاه داده سندی را بهصورت محلی روی یک کامپیوتر ایجاد و بررسی کنیم. درباره شبیهساز اینجا بیشتر بخوانید.
یک سند مجموعهای از فیلدها و مقادیر اشیاء است که فیلدها توصیف میکنند که مقدار شیء چه چیزی را نشان میدهد. در زیر یک مثال از یک سند آورده شده است.
{
"firstname": "Eva",
"age": 44,
"id": "8c74a315-aebf-4a16-bb38-2430a9896ce5",
"_rid": "bHwDAPQz8s0BAAAAAAAAAA==",
"_self": "dbs/bHwDAA==/colls/bHwDAPQz8s0=/docs/bHwDAPQz8s0BAAAAAAAAAA==/",
"_etag": "\"00000000-0000-0000-9f95-010a691e01d7\"",
"_attachments": "attachments/",
"_ts": 1630544034
}
فیلدهای مورد توجه در این سند عبارتند از: firstname، id و age. سایر فیلدهایی که با زیرخط شروع میشوند توسط Cosmos DB تولید شدهاند.
بررسی دادهها با شبیهساز Cosmos DB
میتوانید شبیهساز را برای ویندوز از اینجا دانلود و نصب کنید. برای گزینههای اجرای شبیهساز در macOS و لینوکس به این مستندات مراجعه کنید.
شبیهساز یک پنجره مرورگر باز میکند که نمای Explorer به شما امکان میدهد اسناد را بررسی کنید.
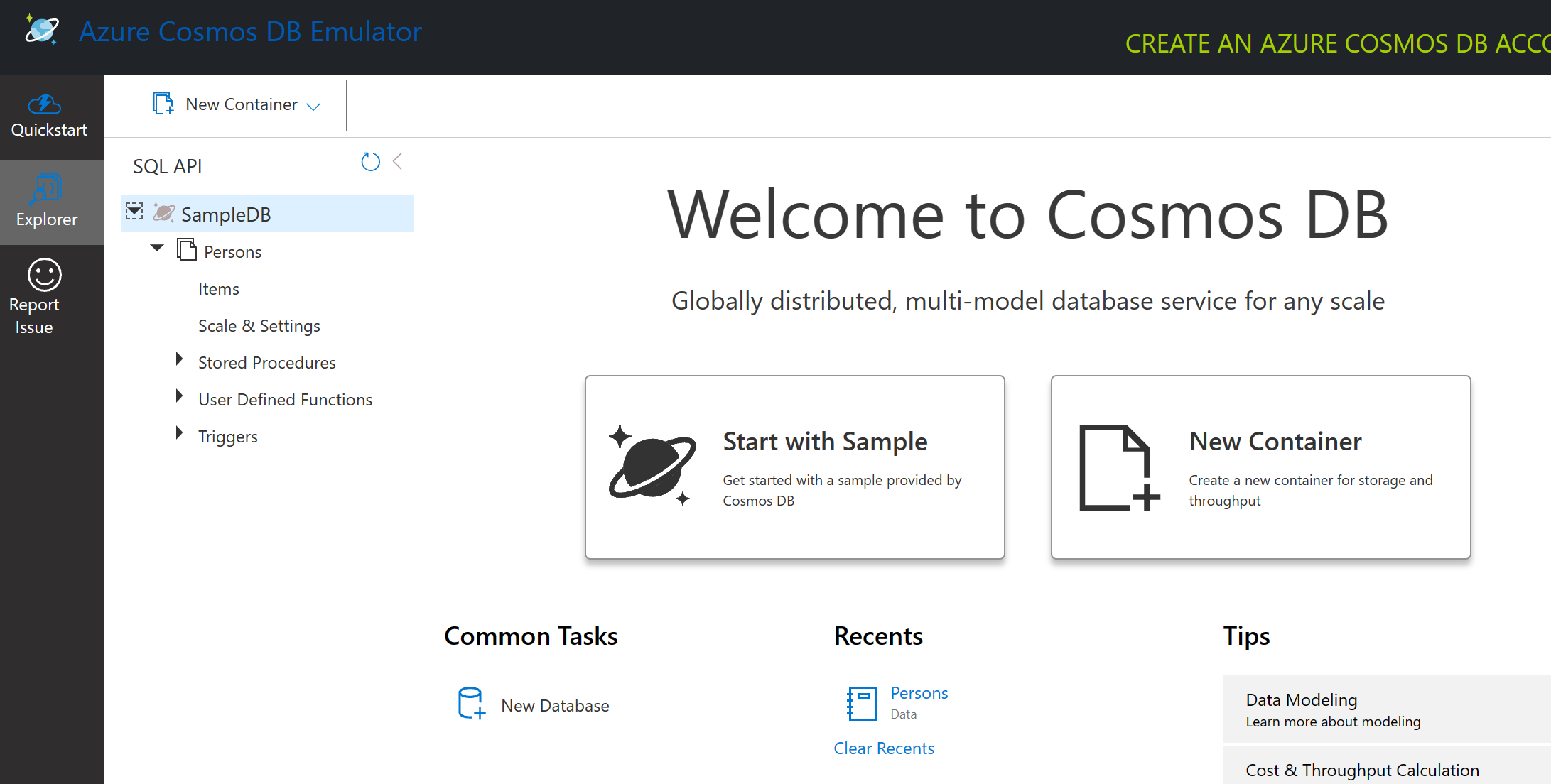
اگر همراهی میکنید، روی "Start with Sample" کلیک کنید تا یک پایگاه داده نمونه به نام SampleDB ایجاد شود. اگر SampleDB را با کلیک روی فلش گسترش دهید، یک کانتینر به نام Persons پیدا خواهید کرد. کانتینر مجموعهای از آیتمها را نگه میدارد که اسناد درون کانتینر هستند. میتوانید چهار سند جداگانه را زیر Items بررسی کنید.
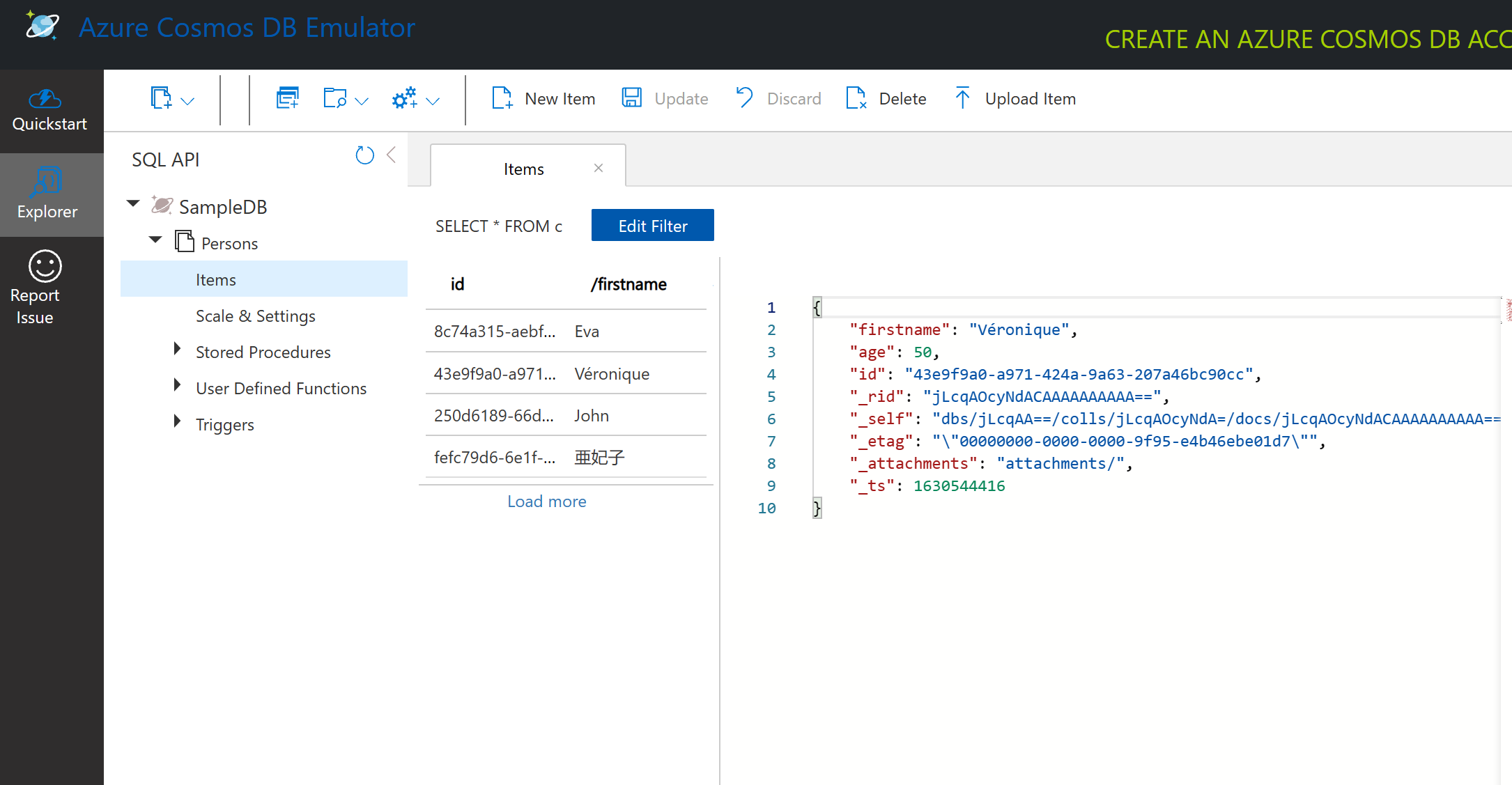
جستجوی دادههای سندی با شبیهساز Cosmos DB
ما همچنین میتوانیم دادههای نمونه را با کلیک روی دکمه New SQL Query (دومین دکمه از سمت چپ) جستجو کنیم.
SELECT * FROM c تمام اسناد موجود در کانتینر را برمیگرداند. بیایید یک عبارت where اضافه کنیم و همه افرادی را که کمتر از ۴۰ سال دارند پیدا کنیم.
SELECT * FROM c where c.age < 40
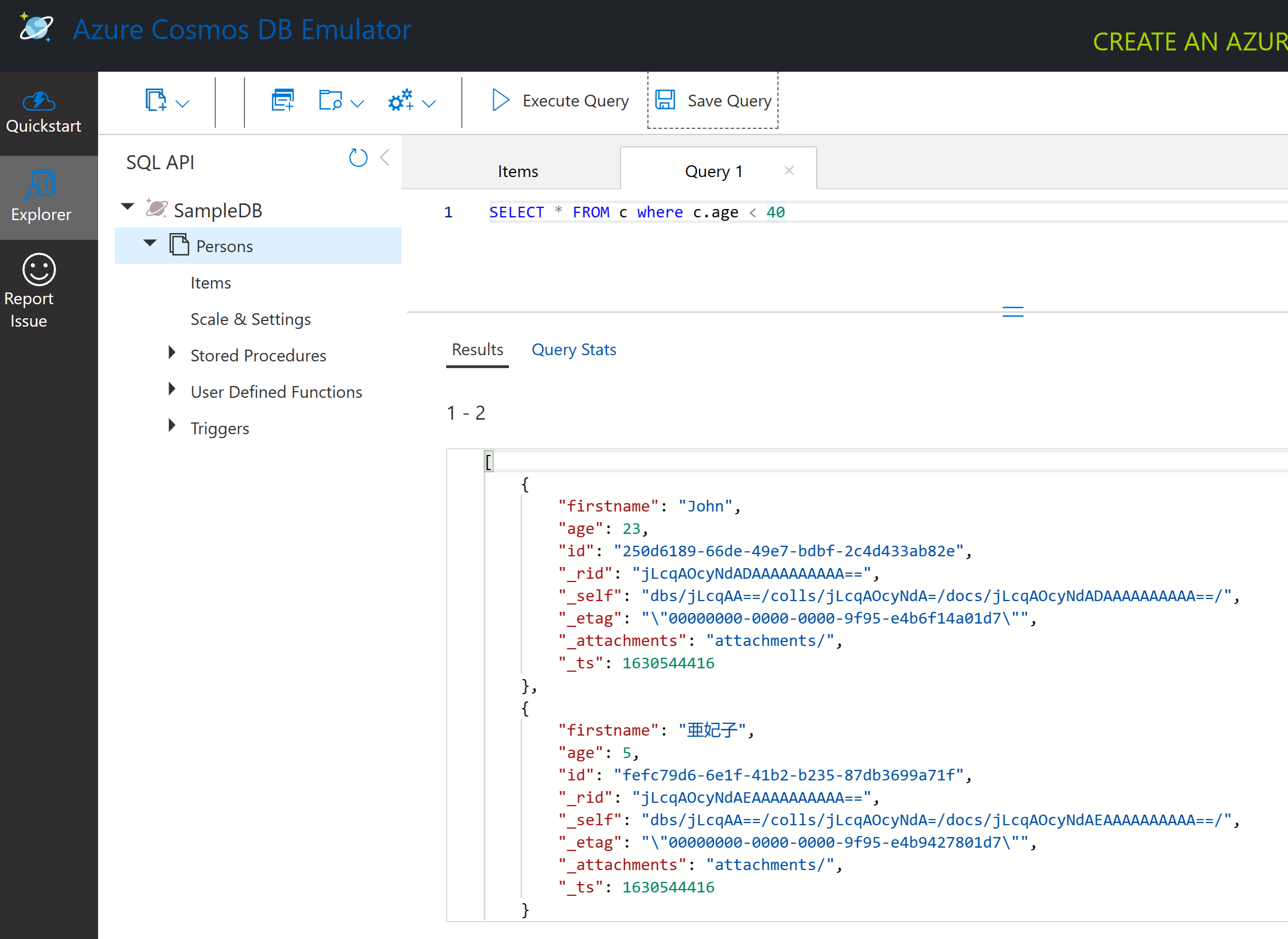
این جستجو دو سند را برمیگرداند، توجه کنید که مقدار age برای هر سند کمتر از ۴۰ است.
JSON و اسناد
اگر با JavaScript Object Notation (JSON) آشنا باشید، متوجه خواهید شد که اسناد شبیه JSON هستند. یک فایل PersonsData.json در این دایرکتوری وجود دارد که میتوانید آن را از طریق دکمه Upload Item به کانتینر Persons در شبیهساز آپلود کنید.
در بیشتر موارد، APIهایی که دادههای JSON را برمیگردانند میتوانند مستقیماً به پایگاه دادههای سندی منتقل و ذخیره شوند. در زیر یک سند دیگر آورده شده است که توییتهایی از حساب توییتر مایکروسافت را نشان میدهد که با استفاده از API توییتر بازیابی شده و سپس در Cosmos DB درج شده است.
{
"created_at": "2021-08-31T19:03:01.000Z",
"id": "1432780985872142341",
"text": "Blank slate. Like this tweet if you’ve ever painted in Microsoft Paint before. https://t.co/cFeEs8eOPK",
"_rid": "dhAmAIUsA4oHAAAAAAAAAA==",
"_self": "dbs/dhAmAA==/colls/dhAmAIUsA4o=/docs/dhAmAIUsA4oHAAAAAAAAAA==/",
"_etag": "\"00000000-0000-0000-9f84-a0958ad901d7\"",
"_attachments": "attachments/",
"_ts": 1630537000
فیلدهای مورد توجه در این سند عبارتند از: created_at، id و text.
🚀 چالش
یک فایل TwitterData.json وجود دارد که میتوانید آن را به پایگاه داده SampleDB آپلود کنید. توصیه میشود آن را به یک کانتینر جداگانه اضافه کنید. این کار را میتوان با انجام مراحل زیر انجام داد:
- کلیک روی دکمه New Container در بالا سمت راست
- انتخاب پایگاه داده موجود (SampleDB) و ایجاد یک شناسه کانتینر برای کانتینر
- تنظیم کلید پارتیشن به
/id - کلیک روی OK (میتوانید بقیه اطلاعات در این نما را نادیده بگیرید زیرا این یک مجموعه داده کوچک است که بهصورت محلی روی دستگاه شما اجرا میشود)
- باز کردن کانتینر جدید و آپلود فایل Twitter Data با دکمه
Upload Item
سعی کنید چند جستجوی SELECT اجرا کنید تا اسنادی را پیدا کنید که در فیلد text آنها کلمه Microsoft وجود دارد. نکته: سعی کنید از کلمه کلیدی LIKE استفاده کنید.
پسازدرس: آزمون کوتاه
مرور و مطالعه شخصی
-
برخی از قالببندیها و ویژگیهای اضافی به این صفحه گسترده اضافه شدهاند که این درس آنها را پوشش نمیدهد. مایکروسافت دارای کتابخانه بزرگی از مستندات و ویدیوها درباره Excel است اگر علاقهمند به یادگیری بیشتر هستید.
-
این مستندات معماری ویژگیهای انواع مختلف دادههای غیررابطهای را توضیح میدهد: دادههای غیررابطهای و NoSQL
-
Cosmos DB یک پایگاه داده غیررابطهای مبتنی بر ابر است که میتواند انواع مختلف NoSQL ذکر شده در این درس را نیز ذخیره کند. درباره این انواع در این ماژول آموزشی Cosmos DB مایکروسافت بیشتر بیاموزید.
تکلیف
سلب مسئولیت:
این سند با استفاده از سرویس ترجمه هوش مصنوعی Co-op Translator ترجمه شده است. در حالی که ما برای دقت تلاش میکنیم، لطفاً توجه داشته باشید که ترجمههای خودکار ممکن است شامل خطاها یا نادقتیها باشند. سند اصلی به زبان اصلی آن باید به عنوان منبع معتبر در نظر گرفته شود. برای اطلاعات حساس، ترجمه حرفهای انسانی توصیه میشود. ما هیچ مسئولیتی در قبال سوءتفاهمها یا تفسیرهای نادرست ناشی از استفاده از این ترجمه نداریم.