|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
README.md
Vizualizace vztahů: Vše o medu 🍯
 |
|---|
| Vizualizace vztahů - Sketchnote od @nitya |
Pokračujeme v přírodním zaměření našeho výzkumu a objevujeme zajímavé vizualizace, které ukazují vztahy mezi různými druhy medu podle datasetu odvozeného z Ministerstva zemědělství Spojených států.
Tento dataset obsahuje přibližně 600 položek a zobrazuje produkci medu v mnoha státech USA. Můžete například sledovat počet včelstev, výnos na včelstvo, celkovou produkci, zásoby, cenu za libru a hodnotu vyprodukovaného medu v daném státě od roku 1998 do roku 2012, přičemž každý řádek představuje jeden rok pro každý stát.
Bude zajímavé vizualizovat vztah mezi produkcí medu v daném státě za rok a například cenou medu v tomto státě. Alternativně můžete vizualizovat vztah mezi výnosem medu na včelstvo v jednotlivých státech. Toto časové období zahrnuje devastující fenomén 'CCD' neboli 'Colony Collapse Disorder', poprvé zaznamenaný v roce 2006 (http://npic.orst.edu/envir/ccd.html), což činí tento dataset obzvláště zajímavým ke studiu. 🐝
Kvíz před lekcí
V této lekci můžete použít ggplot2, který jste již dříve používali, jako skvělou knihovnu pro vizualizaci vztahů mezi proměnnými. Zvláště zajímavé je použití funkcí geom_point a qplot z ggplot2, které umožňují rychle vytvářet bodové a čárové grafy pro vizualizaci 'statistických vztahů', což datovým vědcům pomáhá lépe pochopit, jak spolu proměnné souvisejí.
Bodové grafy
Použijte bodový graf k zobrazení, jak se cena medu vyvíjela rok od roku v jednotlivých státech. ggplot2, pomocí ggplot a geom_point, pohodlně seskupí data podle států a zobrazí datové body pro kategorická i číselná data.
Začněme importem dat a knihovny Seaborn:
honey=read.csv('../../data/honey.csv')
head(honey)
Všimnete si, že data o medu obsahují několik zajímavých sloupců, včetně roku a ceny za libru. Prozkoumejme tato data seskupená podle států USA:
| stát | numcol | yieldpercol | totalprod | stocks | priceperlb | prodvalue | year |
|---|---|---|---|---|---|---|---|
| AL | 16000 | 71 | 1136000 | 159000 | 0.72 | 818000 | 1998 |
| AZ | 55000 | 60 | 3300000 | 1485000 | 0.64 | 2112000 | 1998 |
| AR | 53000 | 65 | 3445000 | 1688000 | 0.59 | 2033000 | 1998 |
| CA | 450000 | 83 | 37350000 | 12326000 | 0.62 | 23157000 | 1998 |
| CO | 27000 | 72 | 1944000 | 1594000 | 0.7 | 1361000 | 1998 |
| FL | 230000 | 98 | 22540000 | 4508000 | 0.64 | 14426000 | 1998 |
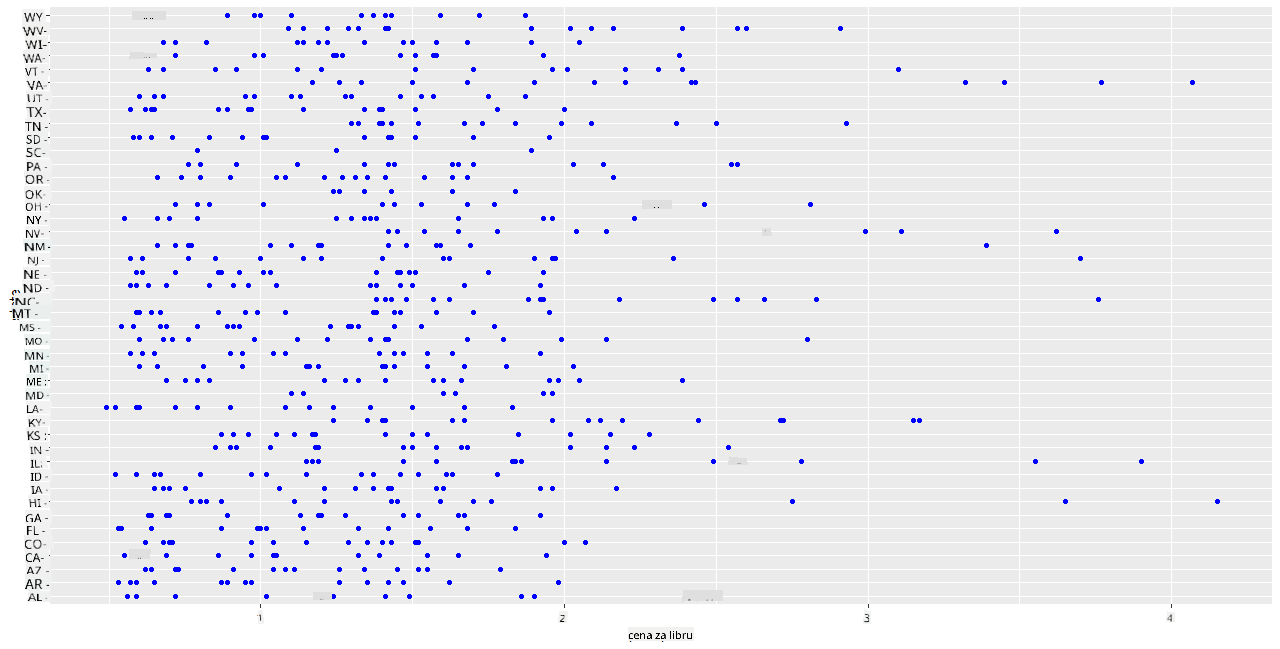
Vytvořte základní bodový graf, který ukáže vztah mezi cenou za libru medu a státem jeho původu. Nastavte osu y dostatečně vysokou, aby zobrazila všechny státy:
library(ggplot2)
ggplot(honey, aes(x = priceperlb, y = state)) +
geom_point(colour = "blue")
Nyní zobrazte stejná data s barevným schématem inspirovaným medem, abyste ukázali, jak se cena vyvíjí v průběhu let. Toho můžete dosáhnout přidáním parametru 'scale_color_gradientn', který ukáže změnu rok od roku:
✅ Více se dozvíte o scale_color_gradientn - vyzkoušejte krásné duhové barevné schéma!
ggplot(honey, aes(x = priceperlb, y = state, color=year)) +
geom_point()+scale_color_gradientn(colours = colorspace::heat_hcl(7))
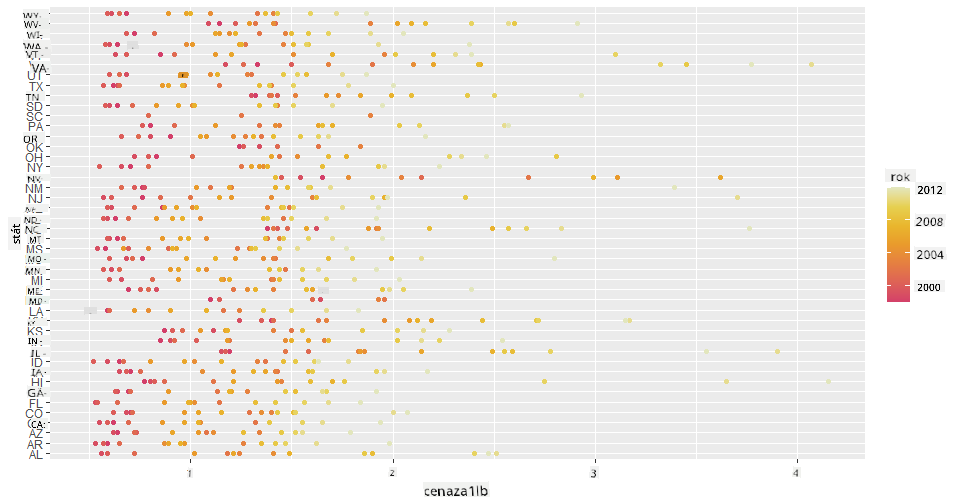
S touto změnou barevného schématu můžete vidět, že v průběhu let dochází k jasnému nárůstu ceny za libru medu. Pokud se podíváte na vzorek dat (například stát Arizona), můžete vidět vzorec zvyšování cen rok od roku s několika výjimkami:
| stát | numcol | yieldpercol | totalprod | stocks | priceperlb | prodvalue | year |
|---|---|---|---|---|---|---|---|
| AZ | 55000 | 60 | 3300000 | 1485000 | 0.64 | 2112000 | 1998 |
| AZ | 52000 | 62 | 3224000 | 1548000 | 0.62 | 1999000 | 1999 |
| AZ | 40000 | 59 | 2360000 | 1322000 | 0.73 | 1723000 | 2000 |
| AZ | 43000 | 59 | 2537000 | 1142000 | 0.72 | 1827000 | 2001 |
| AZ | 38000 | 63 | 2394000 | 1197000 | 1.08 | 2586000 | 2002 |
| AZ | 35000 | 72 | 2520000 | 983000 | 1.34 | 3377000 | 2003 |
| AZ | 32000 | 55 | 1760000 | 774000 | 1.11 | 1954000 | 2004 |
| AZ | 36000 | 50 | 1800000 | 720000 | 1.04 | 1872000 | 2005 |
| AZ | 30000 | 65 | 1950000 | 839000 | 0.91 | 1775000 | 2006 |
| AZ | 30000 | 64 | 1920000 | 902000 | 1.26 | 2419000 | 2007 |
| AZ | 25000 | 64 | 1600000 | 336000 | 1.26 | 2016000 | 2008 |
| AZ | 20000 | 52 | 1040000 | 562000 | 1.45 | 1508000 | 2009 |
| AZ | 24000 | 77 | 1848000 | 665000 | 1.52 | 2809000 | 2010 |
| AZ | 23000 | 53 | 1219000 | 427000 | 1.55 | 1889000 | 2011 |
| AZ | 22000 | 46 | 1012000 | 253000 | 1.79 | 1811000 | 2012 |
Dalším způsobem, jak vizualizovat tento vývoj, je použití velikosti místo barvy. Pro uživatele s poruchami barevného vidění by to mohla být lepší volba. Upravte svou vizualizaci tak, aby nárůst ceny byl zobrazen zvětšením obvodu bodů:
ggplot(honey, aes(x = priceperlb, y = state)) +
geom_point(aes(size = year),colour = "blue") +
scale_size_continuous(range = c(0.25, 3))
Vidíte, že velikost bodů se postupně zvětšuje.
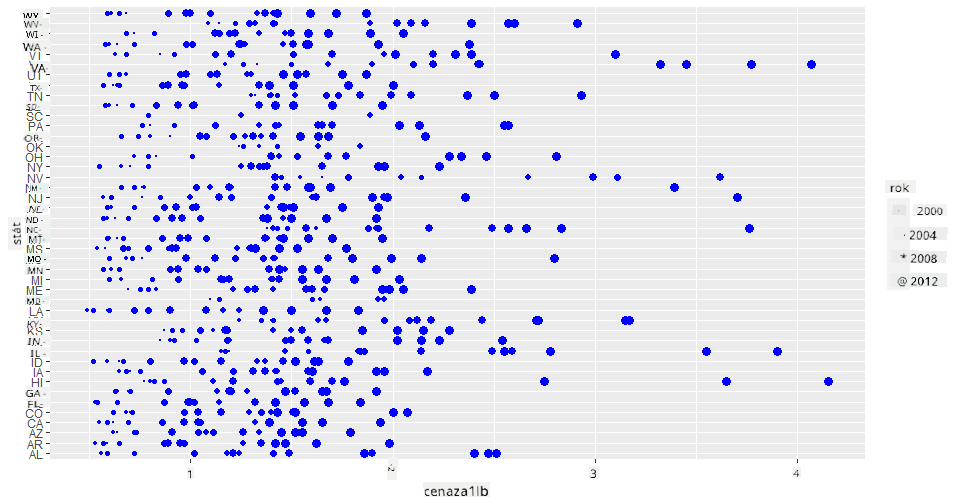
Je to jednoduchý případ nabídky a poptávky? Kvůli faktorům, jako je změna klimatu a kolaps včelstev, je k dispozici méně medu k prodeji rok od roku, a proto cena stoupá?
Pro nalezení korelace mezi některými proměnnými v tomto datasetu prozkoumejme čárové grafy.
Čárové grafy
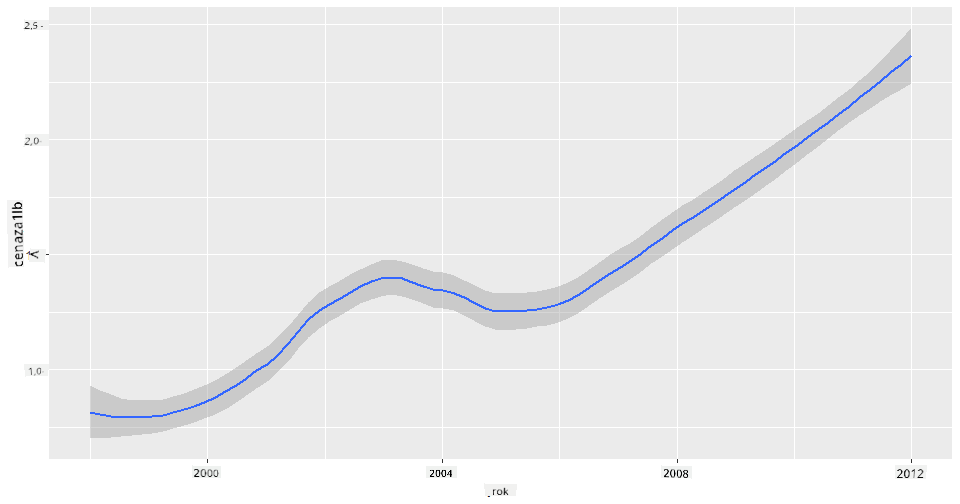
Otázka: Je zde jasný nárůst ceny medu za libru rok od roku? Nejjednodušeji to zjistíte vytvořením jednoho čárového grafu:
qplot(honey$year,honey$priceperlb, geom='smooth', span =0.5, xlab = "year",ylab = "priceperlb")
Odpověď: Ano, s několika výjimkami kolem roku 2003:
Otázka: Vidíme v roce 2003 také nárůst zásob medu? Co když se podíváte na celkovou produkci rok od roku?
qplot(honey$year,honey$totalprod, geom='smooth', span =0.5, xlab = "year",ylab = "totalprod")
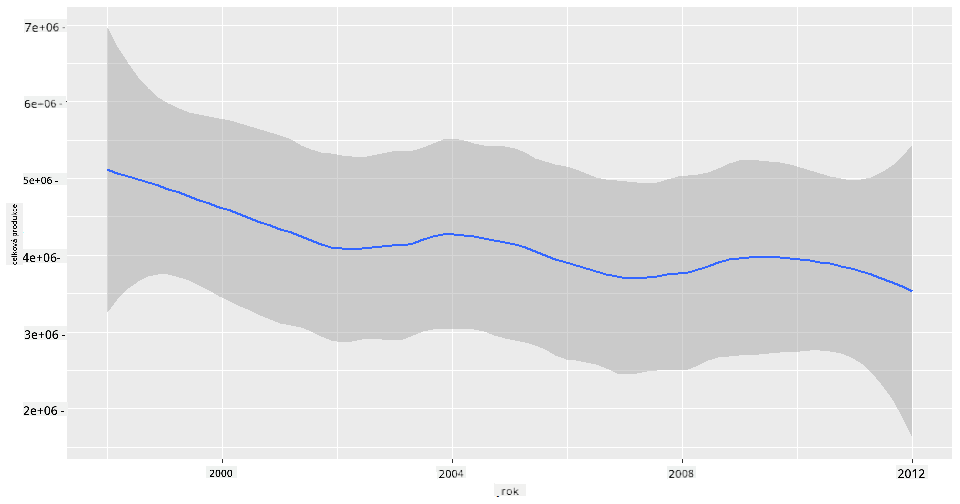
Odpověď: Ne tak docela. Pokud se podíváte na celkovou produkci, zdá se, že v tomto konkrétním roce skutečně vzrostla, i když obecně produkce medu během těchto let klesá.
Otázka: Co tedy mohlo způsobit nárůst ceny medu kolem roku 2003?
Prozkoumejte to pomocí mřížky facetů.
Mřížky facetů
Mřížky facetů vezmou jednu část vašeho datasetu (v našem případě můžete zvolit 'rok', abyste se vyhnuli příliš mnoha facetům). Seaborn pak vytvoří graf pro každý z těchto facetů na základě zvolených os x a y pro snadnější vizuální porovnání. Vyniká rok 2003 v tomto typu porovnání?
Vytvořte mřížku facetů pomocí facet_wrap, jak doporučuje dokumentace ggplot2.
ggplot(honey, aes(x=yieldpercol, y = numcol,group = 1)) +
geom_line() + facet_wrap(vars(year))
V této vizualizaci můžete porovnat výnos na včelstvo a počet včelstev rok od roku vedle sebe s nastavením wrap na 3 pro sloupce:
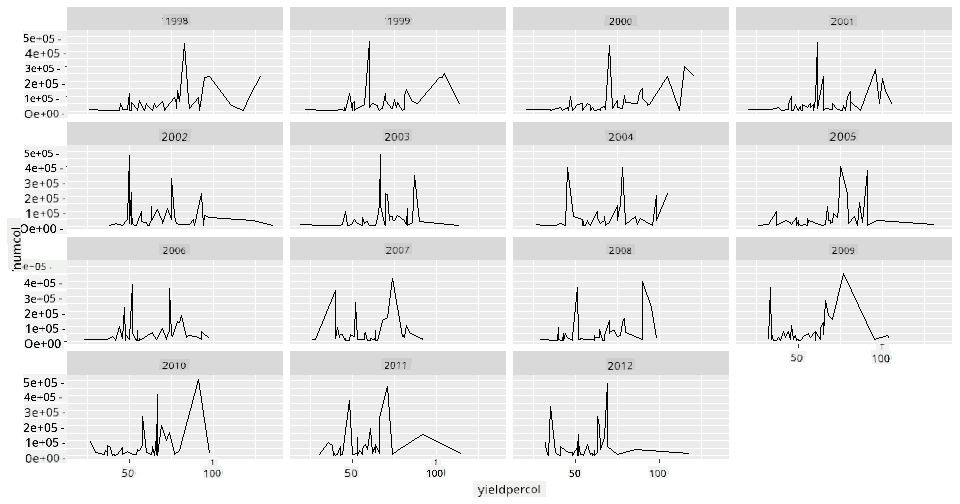
Pro tento dataset nic zvláštního nevyniká, pokud jde o počet včelstev a jejich výnos rok od roku a stát od státu. Existuje jiný způsob, jak najít korelaci mezi těmito dvěma proměnnými?
Dvojité čárové grafy
Vyzkoušejte vícenásobný čárový graf překrytím dvou čárových grafů na sebe pomocí funkcí par a plot v R. Budeme vykreslovat roky na ose x a zobrazovat dvě osy y. Zobrazte výnos na včelstvo a počet včelstev překryté:
par(mar = c(5, 4, 4, 4) + 0.3)
plot(honey$year, honey$numcol, pch = 16, col = 2,type="l")
par(new = TRUE)
plot(honey$year, honey$yieldpercol, pch = 17, col = 3,
axes = FALSE, xlab = "", ylab = "",type="l")
axis(side = 4, at = pretty(range(y2)))
mtext("colony yield", side = 4, line = 3)
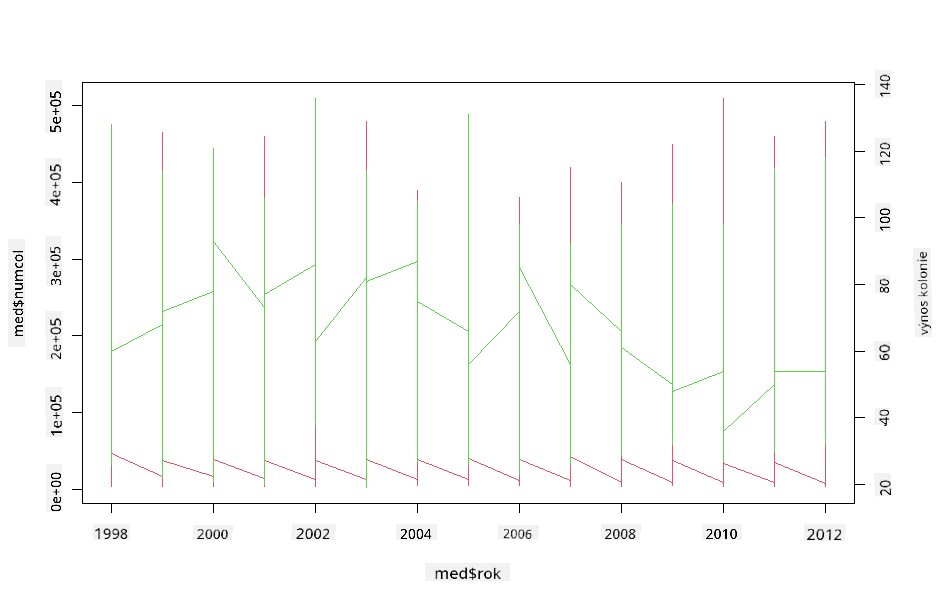
I když kolem roku 2003 nic výrazně nevyniká, umožňuje nám to zakončit tuto lekci na trochu pozitivnější notě: i když celkový počet včelstev klesá, jejich počet se stabilizuje, i když jejich výnos na včelstvo klesá.
Do toho, včely, do toho!
🐝❤️
🚀 Výzva
V této lekci jste se dozvěděli více o dalších způsobech použití bodových grafů a mřížek facetů, včetně mřížek facetů. Vyzkoušejte si vytvořit mřížku facetů s jiným datasetem, možná s tím, který jste použili v předchozích lekcích. Všimněte si, jak dlouho jejich vytvoření trvá a jak je třeba být opatrný ohledně počtu mřížek, které je třeba vykreslit pomocí těchto technik.
Kvíz po lekci
Přehled a samostudium
Čárové grafy mohou být jednoduché nebo poměrně složité. Přečtěte si něco více v dokumentaci ggplot2 o různých způsobech, jak je můžete vytvořit. Zkuste vylepšit čárové grafy, které jste vytvořili v této lekci, pomocí dalších metod uvedených v dokumentaci.
Zadání
Prohlášení:
Tento dokument byl přeložen pomocí služby pro automatický překlad Co-op Translator. I když se snažíme o přesnost, mějte na paměti, že automatické překlady mohou obsahovat chyby nebo nepřesnosti. Původní dokument v jeho původním jazyce by měl být považován za autoritativní zdroj. Pro důležité informace se doporučuje profesionální lidský překlad. Neodpovídáme za žádná nedorozumění nebo nesprávné interpretace vyplývající z použití tohoto překladu.