|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| solution | 2 weeks ago | |
| README.md | 2 weeks ago | |
| assignment.ipynb | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
| notebook.ipynb | 2 weeks ago | |
README.md
Stručný úvod do statistiky a pravděpodobnosti
 |
|---|
| Statistika a pravděpodobnost - Sketchnote od @nitya |
Teorie statistiky a pravděpodobnosti jsou dvě úzce související oblasti matematiky, které mají velký význam pro datovou vědu. Je možné pracovat s daty bez hlubokých znalostí matematiky, ale je stále lepší znát alespoň některé základní koncepty. Zde vám představíme krátký úvod, který vám pomůže začít.
Kvíz před přednáškou
Pravděpodobnost a náhodné proměnné
Pravděpodobnost je číslo mezi 0 a 1, které vyjadřuje, jak pravděpodobné je, že nastane určitá událost. Je definována jako počet pozitivních výsledků (které vedou k události) dělený celkovým počtem výsledků, za předpokladu, že všechny výsledky jsou stejně pravděpodobné. Například při hodu kostkou je pravděpodobnost, že padne sudé číslo, 3/6 = 0,5.
Když mluvíme o událostech, používáme náhodné proměnné. Například náhodná proměnná, která představuje číslo získané při hodu kostkou, by měla hodnoty od 1 do 6. Množina čísel od 1 do 6 se nazývá prostor vzorků. Můžeme mluvit o pravděpodobnosti, že náhodná proměnná nabude určité hodnoty, například P(X=3)=1/6.
Náhodná proměnná v předchozím příkladu se nazývá diskrétní, protože má spočetný prostor vzorků, tj. existují oddělené hodnoty, které lze vyjmenovat. Existují případy, kdy prostor vzorků je rozsah reálných čísel nebo celá množina reálných čísel. Takové proměnné se nazývají spojité. Dobrým příkladem je čas příjezdu autobusu.
Pravděpodobnostní rozdělení
V případě diskrétních náhodných proměnných je snadné popsat pravděpodobnost každé události pomocí funkce P(X). Pro každou hodnotu s z prostoru vzorků S poskytne číslo od 0 do 1 tak, aby součet všech hodnot P(X=s) pro všechny události byl 1.
Nejznámější diskrétní rozdělení je rovnoměrné rozdělení, ve kterém je prostor vzorků tvořen N prvky, s rovnoměrnou pravděpodobností 1/N pro každý z nich.
Popis pravděpodobnostního rozdělení spojité proměnné, jejíž hodnoty jsou čerpány z nějakého intervalu [a,b] nebo celé množiny reálných čísel ℝ, je složitější. Zvažte případ času příjezdu autobusu. Ve skutečnosti je pravděpodobnost, že autobus přijede přesně v určitém čase t, rovna 0!
Nyní víte, že události s nulovou pravděpodobností se dějí, a to velmi často! Přinejmenším pokaždé, když přijede autobus!
Můžeme mluvit pouze o pravděpodobnosti, že proměnná spadne do určitého intervalu hodnot, např. P(t1≤X<t2). V tomto případě je pravděpodobnostní rozdělení popsáno pomocí funkce hustoty pravděpodobnosti p(x), takové že
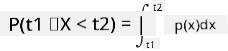
Spojitý analog rovnoměrného rozdělení se nazývá spojité rovnoměrné rozdělení, které je definováno na konečném intervalu. Pravděpodobnost, že hodnota X spadne do intervalu délky l, je úměrná l a stoupá až k 1.
Další důležité rozdělení je normální rozdělení, o kterém si povíme podrobněji níže.
Průměr, rozptyl a směrodatná odchylka
Předpokládejme, že vezmeme sekvenci n vzorků náhodné proměnné X: x1, x2, ..., xn. Můžeme definovat průměrnou (nebo aritmetickou průměrnou) hodnotu sekvence tradičním způsobem jako (x1+x2+xn)/n. Jak zvětšujeme velikost vzorku (tj. bereme limit s n→∞), získáme průměr (také nazývaný očekávání) rozdělení. Očekávání budeme označovat jako E(x).
Lze ukázat, že pro jakékoli diskrétní rozdělení s hodnotami {x1, x2, ..., xN} a odpovídajícími pravděpodobnostmi p1, p2, ..., pN, očekávání bude rovno E(X)=x1p1+x2p2+...+xNpN.
Pro určení, jak daleko jsou hodnoty rozptýlené, můžeme vypočítat rozptyl σ2 = ∑(xi - μ)2/n, kde μ je průměr sekvence. Hodnota σ se nazývá směrodatná odchylka a σ2 se nazývá rozptyl.
Mód, medián a kvartily
Někdy průměr neodpovídá dostatečně "typické" hodnotě dat. Například když existuje několik extrémních hodnot, které jsou zcela mimo rozsah, mohou ovlivnit průměr. Dalším dobrým ukazatelem je medián, hodnota, taková že polovina datových bodů je nižší než ona a druhá polovina vyšší.
Pro lepší pochopení rozdělení dat je užitečné mluvit o kvartilech:
- První kvartil, nebo Q1, je hodnota, taková že 25 % dat je pod ní
- Třetí kvartil, nebo Q3, je hodnota, taková že 75 % dat je pod ní
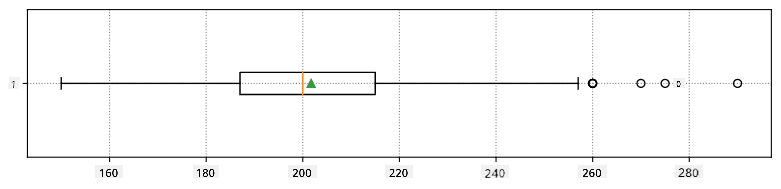
Graficky můžeme vztah mezi mediánem a kvartily znázornit v diagramu nazývaném box plot:

Zde také vypočítáme mezikvartilové rozpětí IQR=Q3-Q1 a tzv. odlehlé hodnoty - hodnoty, které leží mimo hranice [Q1-1.5IQR,Q3+1.5IQR].
Pro konečné rozdělení, které obsahuje malý počet možných hodnot, je dobrá "typická" hodnota ta, která se objevuje nejčastěji, což se nazývá mód. Často se používá u kategoriálních dat, jako jsou barvy. Zvažte situaci, kdy máme dvě skupiny lidí - některé, které silně preferují červenou, a jiné, které preferují modrou. Pokud kódujeme barvy čísly, průměrná hodnota oblíbené barvy by byla někde ve spektru oranžovo-zelené, což neodpovídá skutečné preferenci ani jedné skupiny. Mód by však byl buď jedna z barev, nebo obě barvy, pokud je počet lidí hlasujících pro ně stejný (v tomto případě nazýváme vzorek multimodální).
Data z reálného světa
Když analyzujeme data z reálného života, často nejsou náhodnými proměnnými v tom smyslu, že neprovádíme experimenty s neznámým výsledkem. Například zvažte tým baseballových hráčů a jejich tělesná data, jako je výška, váha a věk. Tato čísla nejsou přesně náhodná, ale stále můžeme použít stejné matematické koncepty. Například sekvenci váhy lidí lze považovat za sekvenci hodnot čerpaných z nějaké náhodné proměnné. Níže je sekvence váhy skutečných baseballových hráčů z Major League Baseball, převzatá z tohoto datasetu (pro vaše pohodlí je zobrazeno pouze prvních 20 hodnot):
[180.0, 215.0, 210.0, 210.0, 188.0, 176.0, 209.0, 200.0, 231.0, 180.0, 188.0, 180.0, 185.0, 160.0, 180.0, 185.0, 197.0, 189.0, 185.0, 219.0]
Note: Pro příklad práce s tímto datasetem se podívejte na doprovodný notebook. V této lekci je také řada výzev, které můžete splnit přidáním nějakého kódu do tohoto notebooku. Pokud si nejste jisti, jak pracovat s daty, nebojte se - k práci s daty pomocí Pythonu se vrátíme později. Pokud nevíte, jak spustit kód v Jupyter Notebooku, podívejte se na tento článek.
Zde je box plot zobrazující průměr, medián a kvartily pro naše data:
Protože naše data obsahují informace o různých hráčských rolích, můžeme také vytvořit box plot podle role - umožní nám získat představu o tom, jak se hodnoty parametrů liší podle rolí. Tentokrát budeme zvažovat výšku:
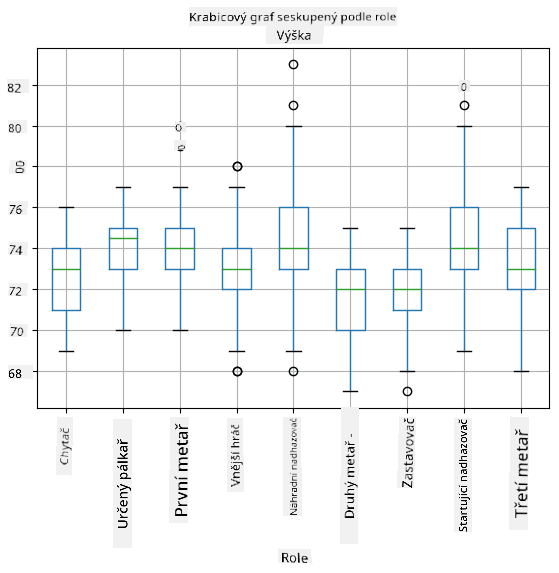
Tento diagram naznačuje, že průměrná výška hráčů na první metě je vyšší než výška hráčů na druhé metě. Později v této lekci se naučíme, jak můžeme tuto hypotézu formálněji otestovat a jak ukázat, že naše data jsou statisticky významná.
Při práci s daty z reálného světa předpokládáme, že všechny datové body jsou vzorky čerpané z nějakého pravděpodobnostního rozdělení. Tento předpoklad nám umožňuje aplikovat techniky strojového učení a vytvářet funkční prediktivní modely.
Abychom viděli, jaké je rozdělení našich dat, můžeme vytvořit graf nazývaný histogram. Osa X by obsahovala počet různých intervalů váhy (tzv. binů) a vertikální osa by ukazovala počet případů, kdy vzorek náhodné proměnné spadl do daného intervalu.
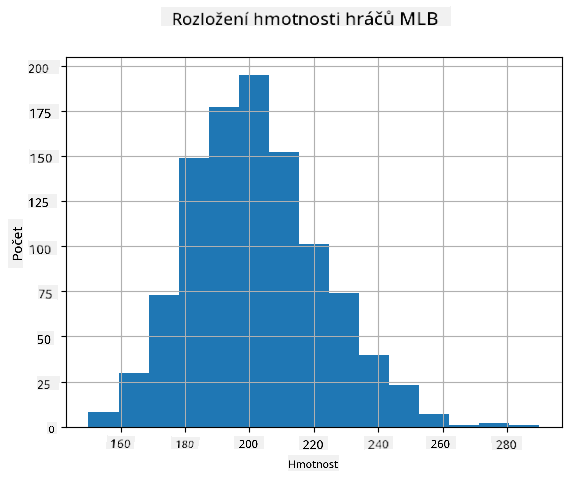
Z tohoto histogramu můžete vidět, že všechny hodnoty jsou soustředěny kolem určité průměrné váhy, a čím dále se od této váhy dostaneme, tím méně váhových hodnot se vyskytuje. Tj. je velmi nepravděpodobné, že váha baseballového hráče bude velmi odlišná od průměrné váhy. Rozptyl váhy ukazuje míru, do jaké se váhy pravděpodobně liší od průměru.
Pokud vezmeme váhy jiných lidí, ne z baseballové ligy, rozdělení bude pravděpodobně odlišné. Tvar rozdělení však zůstane stejný, ale průměr a rozptyl se změní. Pokud tedy trénujeme náš model na baseballových hráčích, je pravděpodobné, že poskytne nesprávné výsledky, když bude aplikován na studenty univerzity, protože základní rozdělení je odlišné.
Normální rozdělení
Rozdělení váhy, které jsme viděli výše, je velmi typické a mnoho měření z reálného světa následuje stejný typ rozdělení, ale s různým průměrem a rozptylem. Toto rozdělení se nazývá normální rozdělení a hraje velmi důležitou roli ve statistice.
Použití normálního rozdělení je správný způsob, jak generovat náhodné váhy potenciálních baseballových hráčů. Jakmile známe průměrnou váhu mean a směrodatnou odchylku std, můžeme vygenerovat 1000 vzorků váhy následujícím způsobem:
samples = np.random.normal(mean,std,1000)
Pokud vykreslíme histogram vygenerovaných vzorků, uvidíme obrázek velmi podobný tomu, který je uveden výše. A pokud zvýšíme počet vzorků a počet binů, můžeme vytvořit obrázek normálního rozdělení, který je blíže ideálu:
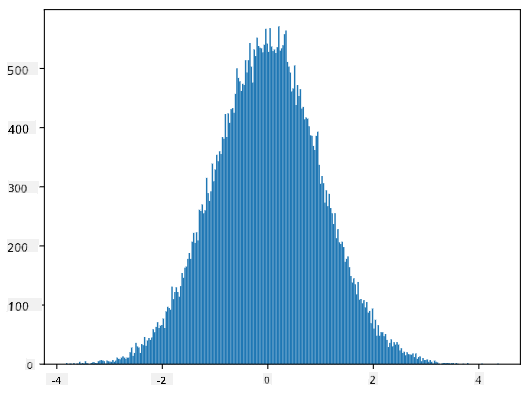
Normální rozdělení s průměrem=0 a směrodatnou odchylkou=1
Intervaly spolehlivosti
Když mluvíme o váhách baseballových hráčů, předpokládáme, že existuje určitá náhodná proměnná W, která odpovídá ideálnímu pravděpodobnostnímu rozdělení váhy všech baseballových hráčů (tzv. populace). Naše sekvence váhy odpovídá podmnožině všech baseballových hráčů, kterou nazýváme vzorek. Zajímavou otázkou je, zda můžeme znát parametry rozdělení W, tj. průměr a rozptyl populace.
Nejjednodušší odpovědí by bylo vypočítat průměr a rozptyl našeho vzorku. Může se však stát, že náš náhodný vzorek přesně neodpovídá celé populaci. Proto má smysl mluvit o intervalu spolehlivosti.
Interval spolehlivosti je odhad skutečného průměru populace na základě našeho vzorku, který je přesný s určitou pravděpodobností (nebo úrovní spolehlivosti).
Předpokládejme, že máme vzorek X.
1, ..., Xn z našeho rozdělení. Pokaždé, když odebereme vzorek z našeho rozdělení, získáme jinou hodnotu průměru μ. Proto může být μ považováno za náhodnou proměnnou. Interval spolehlivosti s pravděpodobností p je dvojice hodnot (Lp,Rp), taková, že P(Lp≤μ≤Rp) = p, tj. pravděpodobnost, že naměřená hodnota průměru spadne do intervalu, se rovná p.
Podrobný popis výpočtu těchto intervalů spolehlivosti přesahuje rámec našeho krátkého úvodu. Další podrobnosti najdete na Wikipedii. Stručně řečeno, definujeme rozdělení vypočítaného průměru vzorku vzhledem ke skutečnému průměru populace, což se nazývá studentovo rozdělení.
Zajímavý fakt: Studentovo rozdělení je pojmenováno po matematikovi Williamu Sealy Gossetovi, který publikoval svůj článek pod pseudonymem "Student". Pracoval v pivovaru Guinness, a podle jedné z verzí jeho zaměstnavatel nechtěl, aby veřejnost věděla, že používají statistické testy k určení kvality surovin.
Pokud chceme odhadnout průměr μ naší populace s pravděpodobností p, musíme vzít (1-p)/2-tý percentil studentova rozdělení A, který lze buď získat z tabulek, nebo vypočítat pomocí vestavěných funkcí statistického softwaru (např. Python, R, atd.). Poté by interval pro μ byl dán X±A*D/√n, kde X je získaný průměr vzorku, D je směrodatná odchylka.
Poznámka: Vynecháváme také diskusi o důležitém konceptu stupňů volnosti, který je důležitý ve vztahu ke studentovu rozdělení. Pro hlubší pochopení tohoto konceptu se můžete obrátit na podrobnější knihy o statistice.
Příklad výpočtu intervalu spolehlivosti pro váhy a výšky je uveden v doprovodných poznámkových blocích.
| p | Průměr váhy |
|---|---|
| 0.85 | 201.73±0.94 |
| 0.90 | 201.73±1.08 |
| 0.95 | 201.73±1.28 |
Všimněte si, že čím vyšší je pravděpodobnost spolehlivosti, tím širší je interval spolehlivosti.
Testování hypotéz
V našem datasetu baseballových hráčů existují různé role hráčů, které lze shrnout níže (podívejte se na doprovodný poznámkový blok, abyste viděli, jak lze tuto tabulku vypočítat):
| Role | Výška | Váha | Počet |
|---|---|---|---|
| Catcher | 72.723684 | 204.328947 | 76 |
| Designated_Hitter | 74.222222 | 220.888889 | 18 |
| First_Baseman | 74.000000 | 213.109091 | 55 |
| Outfielder | 73.010309 | 199.113402 | 194 |
| Relief_Pitcher | 74.374603 | 203.517460 | 315 |
| Second_Baseman | 71.362069 | 184.344828 | 58 |
| Shortstop | 71.903846 | 182.923077 | 52 |
| Starting_Pitcher | 74.719457 | 205.163636 | 221 |
| Third_Baseman | 73.044444 | 200.955556 | 45 |
Můžeme si všimnout, že průměrná výška hráčů na první metě je vyšší než hráčů na druhé metě. Mohli bychom tedy dojít k závěru, že hráči na první metě jsou vyšší než hráči na druhé metě.
Toto tvrzení se nazývá hypotéza, protože nevíme, zda je tento fakt skutečně pravdivý.
Nicméně není vždy zřejmé, zda můžeme tento závěr učinit. Z výše uvedené diskuse víme, že každý průměr má přidružený interval spolehlivosti, a proto může být tento rozdíl pouze statistickou chybou. Potřebujeme formálnější způsob, jak testovat naši hypotézu.
Vypočítejme intervaly spolehlivosti zvlášť pro výšky hráčů na první a druhé metě:
| Spolehlivost | První meta | Druhá meta |
|---|---|---|
| 0.85 | 73.62..74.38 | 71.04..71.69 |
| 0.90 | 73.56..74.44 | 70.99..71.73 |
| 0.95 | 73.47..74.53 | 70.92..71.81 |
Vidíme, že za žádné spolehlivosti se intervaly nepřekrývají. To potvrzuje naši hypotézu, že hráči na první metě jsou vyšší než hráči na druhé metě.
Formálněji řečeno, problém, který řešíme, je zjistit, zda dvě pravděpodobnostní rozdělení jsou stejná, nebo alespoň mají stejné parametry. V závislosti na rozdělení musíme použít různé testy. Pokud víme, že naše rozdělení jsou normální, můžeme použít Studentův t-test.
V Studentově t-testu vypočítáme tzv. t-hodnotu, která indikuje rozdíl mezi průměry, přičemž bere v úvahu rozptyl. Bylo prokázáno, že t-hodnota následuje studentovo rozdělení, což nám umožňuje získat prahovou hodnotu pro danou úroveň spolehlivosti p (to lze vypočítat nebo najít v numerických tabulkách). Poté porovnáme t-hodnotu s touto prahovou hodnotou, abychom hypotézu potvrdili nebo zamítli.
V Pythonu můžeme použít balíček SciPy, který obsahuje funkci ttest_ind (kromě mnoha dalších užitečných statistických funkcí!). Tato funkce pro nás vypočítá t-hodnotu a také provede zpětné vyhledání p-hodnoty spolehlivosti, takže můžeme jednoduše zkontrolovat spolehlivost a učinit závěr.
Například naše porovnání výšek hráčů na první a druhé metě nám dává následující výsledky:
from scipy.stats import ttest_ind
tval, pval = ttest_ind(df.loc[df['Role']=='First_Baseman',['Height']], df.loc[df['Role']=='Designated_Hitter',['Height']],equal_var=False)
print(f"T-value = {tval[0]:.2f}\nP-value: {pval[0]}")
T-value = 7.65
P-value: 9.137321189738925e-12
V našem případě je p-hodnota velmi nízká, což znamená, že existují silné důkazy podporující, že hráči na první metě jsou vyšší.
Existují také různé jiné typy hypotéz, které bychom mohli chtít testovat, například:
- Dokázat, že daný vzorek odpovídá nějakému rozdělení. V našem případě jsme předpokládali, že výšky mají normální rozdělení, ale to vyžaduje formální statistické ověření.
- Dokázat, že průměrná hodnota vzorku odpovídá nějaké předem definované hodnotě.
- Porovnat průměry několika vzorků (např. jaký je rozdíl v úrovni štěstí mezi různými věkovými skupinami).
Zákon velkých čísel a centrální limitní věta
Jedním z důvodů, proč je normální rozdělení tak důležité, je tzv. centrální limitní věta. Předpokládejme, že máme velký vzorek nezávislých hodnot N X1, ..., XN, odebraných z libovolného rozdělení s průměrem μ a rozptylem σ2. Poté, pro dostatečně velké N (jinými slovy, když N→∞), bude průměr ΣiXi normálně rozdělený, s průměrem μ a rozptylem σ2/N.
Jiný způsob interpretace centrální limitní věty je říci, že bez ohledu na rozdělení, když vypočítáte průměr součtu libovolných hodnot náhodné proměnné, skončíte s normálním rozdělením.
Z centrální limitní věty také vyplývá, že když N→∞, pravděpodobnost, že průměr vzorku bude roven μ, se stává 1. To je známé jako zákon velkých čísel.
Kovariance a korelace
Jednou z věcí, které Data Science dělá, je hledání vztahů mezi daty. Říkáme, že dvě sekvence korelují, když vykazují podobné chování ve stejnou dobu, tj. buď společně rostou/klesají, nebo jedna sekvence roste, když druhá klesá, a naopak. Jinými slovy, zdá se, že mezi dvěma sekvencemi existuje nějaký vztah.
Korelace nutně neznamená příčinný vztah mezi dvěma sekvencemi; někdy mohou obě proměnné záviset na nějaké externí příčině, nebo může být korelace čistě náhodná. Nicméně silná matematická korelace je dobrým indikátorem, že dvě proměnné jsou nějakým způsobem propojené.
Matematicky hlavní koncept, který ukazuje vztah mezi dvěma náhodnými proměnnými, je kovariance, která se počítá takto: Cov(X,Y) = E[(X-E(X))(Y-E(Y))]. Počítáme odchylku obou proměnných od jejich průměrných hodnot a poté součin těchto odchylek. Pokud obě proměnné odchylují společně, součin bude vždy kladná hodnota, která se sečte na kladnou kovarianci. Pokud obě proměnné odchylují nesynchronizovaně (tj. jedna klesá pod průměr, když druhá stoupá nad průměr), vždy dostaneme záporné hodnoty, které se sečtou na zápornou kovarianci. Pokud odchylky nejsou závislé, sečtou se přibližně na nulu.
Absolutní hodnota kovariance nám neříká mnoho o tom, jak velká je korelace, protože závisí na velikosti skutečných hodnot. Abychom ji normalizovali, můžeme kovarianci vydělit směrodatnou odchylkou obou proměnných, čímž získáme korelaci. Dobré je, že korelace je vždy v rozmezí [-1,1], kde 1 znamená silnou kladnou korelaci mezi hodnotami, -1 - silnou zápornou korelaci, a 0 - žádnou korelaci (proměnné jsou nezávislé).
Příklad: Můžeme vypočítat korelaci mezi váhami a výškami baseballových hráčů z výše zmíněného datasetu:
print(np.corrcoef(weights,heights))
Výsledkem je korelační matice jako tato:
array([[1. , 0.52959196],
[0.52959196, 1. ]])
Korelační matice C může být vypočítána pro libovolný počet vstupních sekvencí S1, ..., Sn. Hodnota Cij je korelace mezi Si a Sj, a diagonální prvky jsou vždy 1 (což je také vlastní korelace Si).
V našem případě hodnota 0.53 naznačuje, že existuje určitá korelace mezi váhou a výškou osoby. Můžeme také vytvořit scatter plot jedné hodnoty proti druhé, abychom viděli vztah vizuálně:
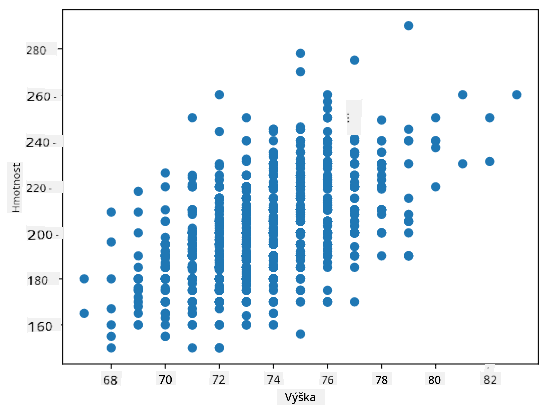
Další příklady korelace a kovariance najdete v doprovodném poznámkovém bloku.
Závěr
V této sekci jsme se naučili:
- základní statistické vlastnosti dat, jako průměr, rozptyl, modus a kvartily
- různá rozdělení náhodných proměnných, včetně normálního rozdělení
- jak najít korelaci mezi různými vlastnostmi
- jak použít matematický a statistický aparát k ověření hypotéz
- jak vypočítat intervaly spolehlivosti pro náhodnou proměnnou na základě vzorku dat
I když to rozhodně není vyčerpávající seznam témat, která existují v oblasti pravděpodobnosti a statistiky, mělo by to být dostatečné pro dobrý začátek tohoto kurzu.
🚀 Výzva
Použijte ukázkový kód v poznámkovém bloku k testování dalších hypotéz:
- Hráči na první metě jsou starší než hráči na druhé metě.
- Hráči na první metě jsou vyšší než hráči na třetí metě.
- Shortstops jsou vyšší než hráči na druhé metě.
Kvíz po přednášce
Přehled & Samostudium
Pravděpodobnost a statistika je tak široké téma, že si zaslouží vlastní kurz. Pokud se chcete ponořit hlouběji do teorie, můžete pokračovat ve čtení některých z následujících knih:
- Carlos Fernandez-Granda z New York University má skvělé poznámky z přednášek Probability and Statistics for Data Science (dostupné online).
- Peter a Andrew Bruce. Practical Statistics for Data Scientists. [ukázkový kód v R].
- James D. Miller. Statistics for Data Science [ukázkový kód v R].
Zadání
Poděkování
Tuto lekci vytvořil s ♥️ Dmitry Soshnikov.
Prohlášení:
Tento dokument byl přeložen pomocí služby pro automatický překlad Co-op Translator. I když se snažíme o co největší přesnost, mějte prosím na paměti, že automatické překlady mohou obsahovat chyby nebo nepřesnosti. Za autoritativní zdroj by měl být považován původní dokument v jeho původním jazyce. Pro důležité informace doporučujeme profesionální lidský překlad. Neodpovídáme za žádná nedorozumění nebo nesprávné výklady vyplývající z použití tohoto překladu.