|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 3 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
Khoa học Dữ liệu trên Đám mây: Cách sử dụng "Azure ML SDK"
 |
|---|
| Khoa học Dữ liệu trên Đám mây: Azure ML SDK - Sketchnote của @nitya |
Mục lục:
- Khoa học Dữ liệu trên Đám mây: Cách sử dụng "Azure ML SDK"
Câu hỏi trước bài giảng
1. Giới thiệu
1.1 Azure ML SDK là gì?
Các nhà khoa học dữ liệu và nhà phát triển AI sử dụng Azure Machine Learning SDK để xây dựng và chạy các quy trình làm việc học máy với dịch vụ Azure Machine Learning. Bạn có thể tương tác với dịch vụ này trong bất kỳ môi trường Python nào, bao gồm Jupyter Notebooks, Visual Studio Code hoặc IDE Python yêu thích của bạn.
Các lĩnh vực chính của SDK bao gồm:
- Khám phá, chuẩn bị và quản lý vòng đời của các tập dữ liệu được sử dụng trong các thí nghiệm học máy.
- Quản lý tài nguyên đám mây để giám sát, ghi nhật ký và tổ chức các thí nghiệm học máy của bạn.
- Huấn luyện mô hình tại chỗ hoặc sử dụng tài nguyên đám mây, bao gồm huấn luyện mô hình tăng tốc GPU.
- Sử dụng học máy tự động (AutoML), chấp nhận các tham số cấu hình và dữ liệu huấn luyện. Nó tự động lặp qua các thuật toán và cài đặt siêu tham số để tìm mô hình tốt nhất cho việc dự đoán.
- Triển khai dịch vụ web để chuyển đổi các mô hình đã huấn luyện thành các dịch vụ RESTful có thể được sử dụng trong bất kỳ ứng dụng nào.
Tìm hiểu thêm về Azure Machine Learning SDK
Trong bài học trước, chúng ta đã thấy cách huấn luyện, triển khai và sử dụng một mô hình theo cách ít mã/không mã. Chúng ta đã sử dụng tập dữ liệu Suy tim để tạo ra một mô hình dự đoán suy tim. Trong bài học này, chúng ta sẽ làm chính xác điều đó nhưng sử dụng Azure Machine Learning SDK.
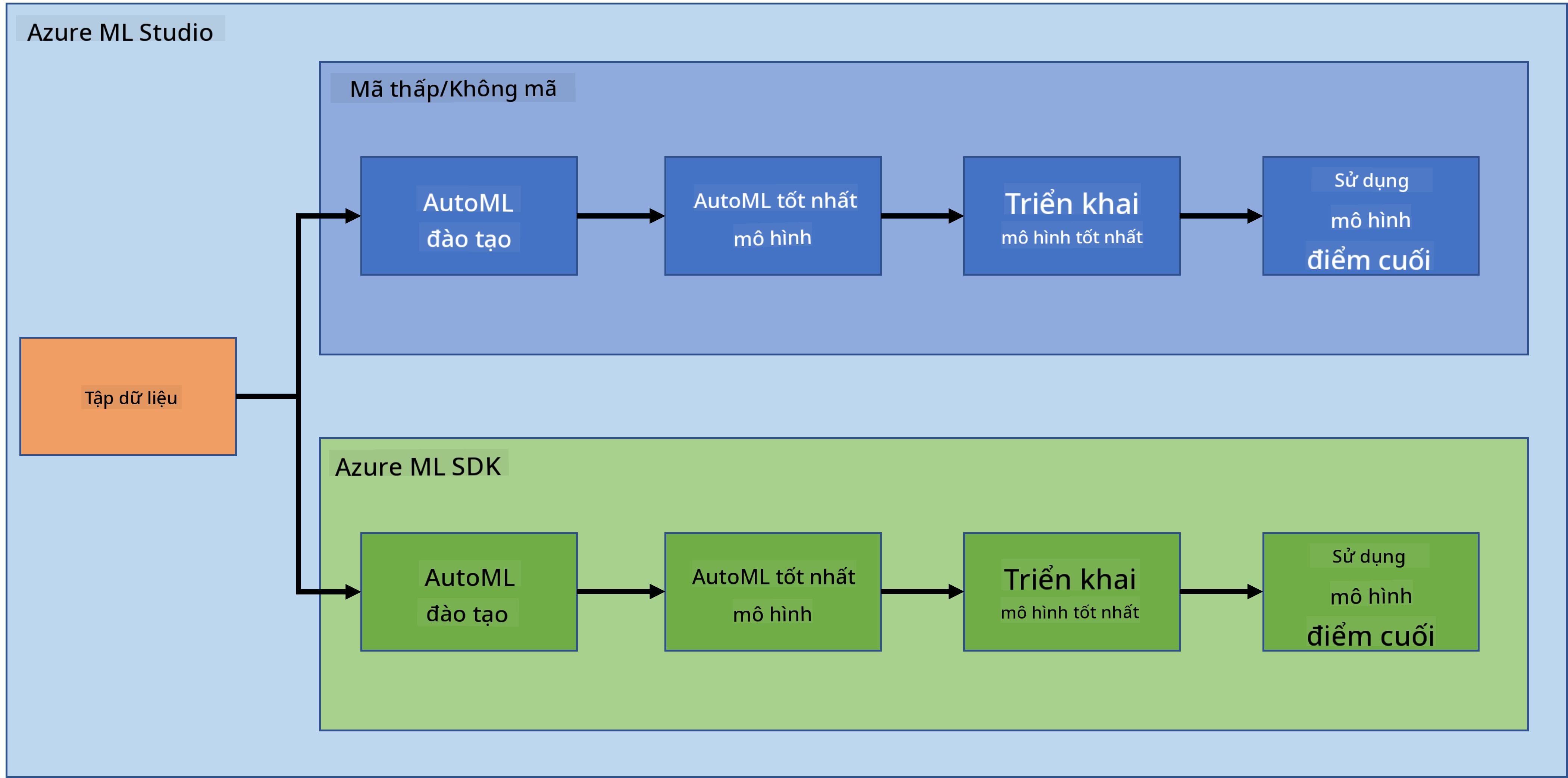
1.2 Dự án dự đoán suy tim và giới thiệu tập dữ liệu
Xem tại đây để biết giới thiệu về dự án dự đoán suy tim và tập dữ liệu.
2. Huấn luyện mô hình với Azure ML SDK
2.1 Tạo một không gian làm việc Azure ML
Để đơn giản, chúng ta sẽ làm việc trên một jupyter notebook. Điều này có nghĩa là bạn đã có một Không gian làm việc và một phiên bản tính toán. Nếu bạn đã có Không gian làm việc, bạn có thể chuyển thẳng đến phần 2.3 Tạo Notebook.
Nếu chưa, vui lòng làm theo hướng dẫn trong phần 2.1 Tạo một không gian làm việc Azure ML trong bài học trước để tạo một không gian làm việc.
2.2 Tạo một phiên bản tính toán
Trong Không gian làm việc Azure ML mà chúng ta đã tạo trước đó, vào menu tính toán và bạn sẽ thấy các tài nguyên tính toán khác nhau có sẵn.
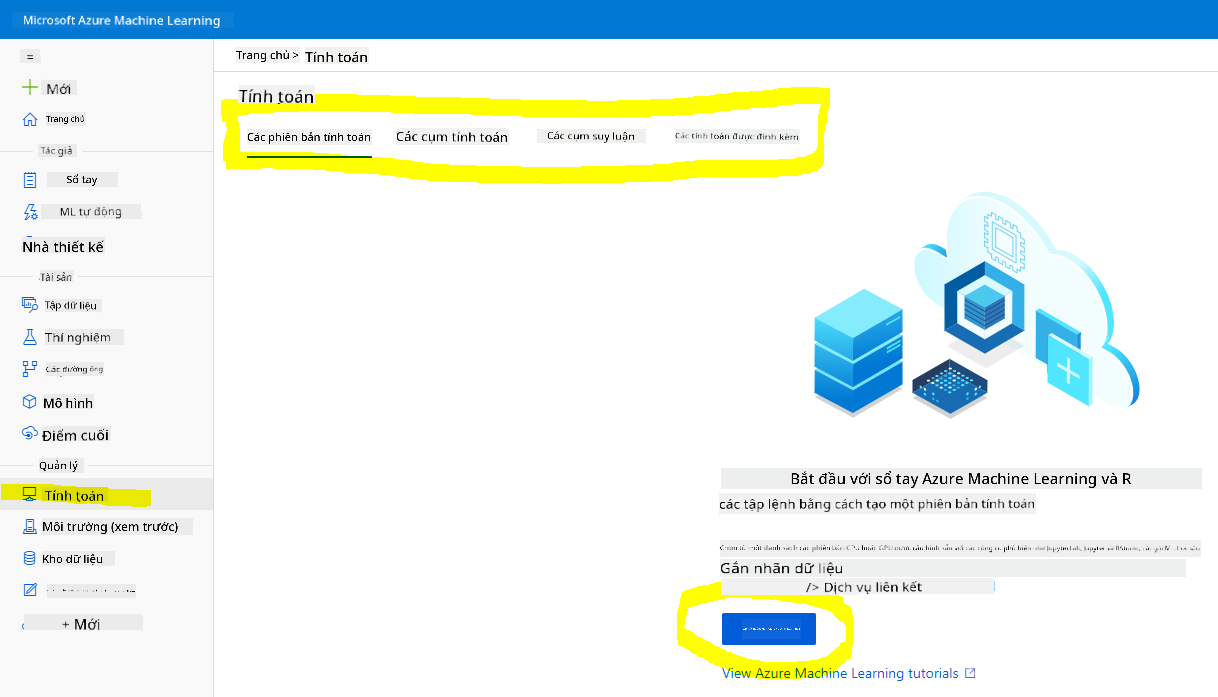
Hãy tạo một phiên bản tính toán để cung cấp một jupyter notebook.
- Nhấp vào nút + New.
- Đặt tên cho phiên bản tính toán của bạn.
- Chọn các tùy chọn: CPU hoặc GPU, kích thước VM và số lõi.
- Nhấp vào nút Create.
Chúc mừng, bạn vừa tạo một phiên bản tính toán! Chúng ta sẽ sử dụng phiên bản tính toán này để tạo một Notebook trong phần Tạo Notebooks.
2.3 Tải tập dữ liệu
Tham khảo bài học trước trong phần 2.3 Tải tập dữ liệu nếu bạn chưa tải tập dữ liệu lên.
2.4 Tạo Notebooks
LƯU Ý: Trong bước tiếp theo, bạn có thể tạo một notebook mới từ đầu hoặc tải lên notebook mà chúng ta đã tạo trong Azure ML Studio của bạn. Để tải lên, chỉ cần nhấp vào menu "Notebook" và tải notebook lên.
Notebooks là một phần rất quan trọng trong quy trình khoa học dữ liệu. Chúng có thể được sử dụng để thực hiện Phân tích Dữ liệu Khám phá (EDA), gọi đến một cụm tính toán để huấn luyện mô hình, hoặc gọi đến một cụm suy luận để triển khai một endpoint.
Để tạo một Notebook, chúng ta cần một nút tính toán đang phục vụ phiên bản jupyter notebook. Quay lại Không gian làm việc Azure ML và nhấp vào Compute instances. Trong danh sách các phiên bản tính toán, bạn sẽ thấy phiên bản tính toán mà chúng ta đã tạo trước đó.
- Trong phần Applications, nhấp vào tùy chọn Jupyter.
- Tích vào ô "Yes, I understand" và nhấp vào nút Continue.
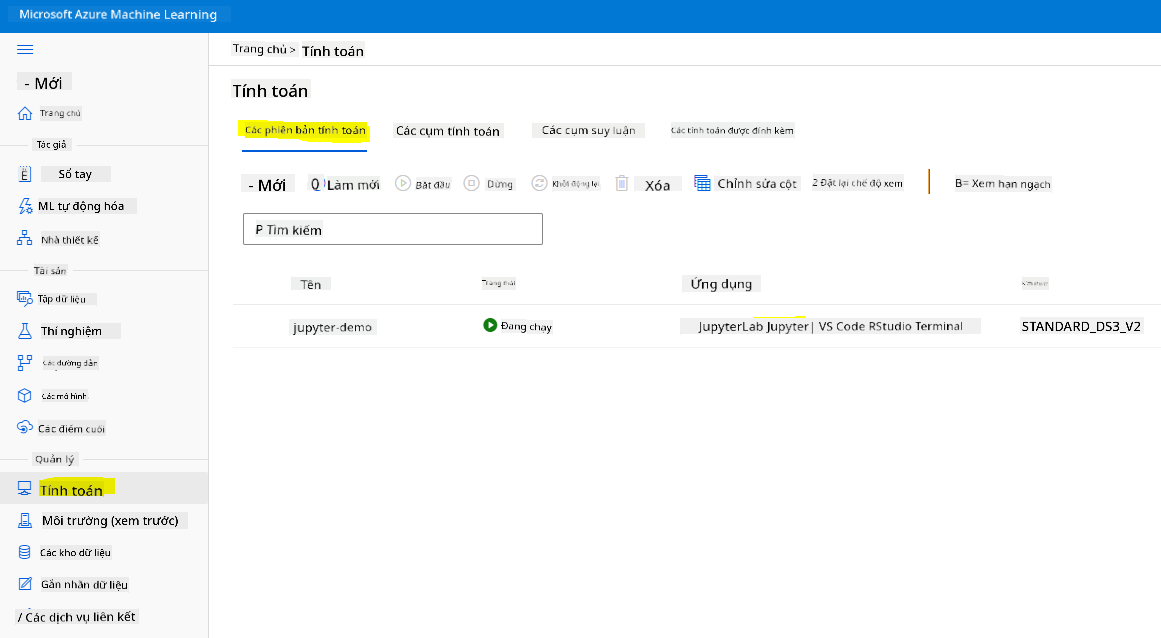
- Điều này sẽ mở một tab trình duyệt mới với phiên bản jupyter notebook của bạn như sau. Nhấp vào nút "New" để tạo một notebook.
Bây giờ chúng ta đã có một Notebook, chúng ta có thể bắt đầu huấn luyện mô hình với Azure ML SDK.
2.5 Huấn luyện mô hình
Trước tiên, nếu bạn có bất kỳ thắc mắc nào, hãy tham khảo tài liệu Azure ML SDK. Tài liệu này chứa tất cả thông tin cần thiết để hiểu các module mà chúng ta sẽ xem trong bài học này.
2.5.1 Thiết lập không gian làm việc, thí nghiệm, cụm tính toán và tập dữ liệu
Bạn cần tải workspace từ tệp cấu hình bằng đoạn mã sau:
from azureml.core import Workspace
ws = Workspace.from_config()
Điều này trả về một đối tượng kiểu Workspace đại diện cho không gian làm việc. Sau đó, bạn cần tạo một experiment bằng đoạn mã sau:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
Để lấy hoặc tạo một thí nghiệm từ không gian làm việc, bạn yêu cầu thí nghiệm bằng tên thí nghiệm. Tên thí nghiệm phải từ 3-36 ký tự, bắt đầu bằng một chữ cái hoặc số, và chỉ chứa các chữ cái, số, dấu gạch dưới và dấu gạch ngang. Nếu không tìm thấy thí nghiệm trong không gian làm việc, một thí nghiệm mới sẽ được tạo.
Bây giờ bạn cần tạo một cụm tính toán để huấn luyện bằng đoạn mã sau. Lưu ý rằng bước này có thể mất vài phút.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Bạn có thể lấy tập dữ liệu từ không gian làm việc bằng tên tập dữ liệu theo cách sau:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 Cấu hình AutoML và huấn luyện
Để thiết lập cấu hình AutoML, sử dụng lớp AutoMLConfig.
Như được mô tả trong tài liệu, có rất nhiều tham số mà bạn có thể tùy chỉnh. Đối với dự án này, chúng ta sẽ sử dụng các tham số sau:
experiment_timeout_minutes: Thời gian tối đa (tính bằng phút) mà thí nghiệm được phép chạy trước khi nó tự động dừng và kết quả được tự động cung cấp.max_concurrent_iterations: Số lần lặp huấn luyện đồng thời tối đa được phép cho thí nghiệm.primary_metric: Chỉ số chính được sử dụng để xác định trạng thái của thí nghiệm.compute_target: Mục tiêu tính toán Azure Machine Learning để chạy thí nghiệm Học máy Tự động.task: Loại nhiệm vụ cần chạy. Các giá trị có thể là 'classification', 'regression', hoặc 'forecasting' tùy thuộc vào loại vấn đề AutoML cần giải quyết.training_data: Dữ liệu huấn luyện được sử dụng trong thí nghiệm. Nó nên chứa cả các đặc trưng huấn luyện và một cột nhãn (tùy chọn một cột trọng số mẫu).label_column_name: Tên của cột nhãn.path: Đường dẫn đầy đủ đến thư mục dự án Azure Machine Learning.enable_early_stopping: Có bật dừng sớm nếu điểm số không cải thiện trong ngắn hạn hay không.featurization: Chỉ báo cho biết bước tạo đặc trưng có nên được thực hiện tự động hay không, hoặc có nên sử dụng tạo đặc trưng tùy chỉnh hay không.debug_log: Tệp nhật ký để ghi thông tin gỡ lỗi.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Bây giờ bạn đã thiết lập cấu hình, bạn có thể huấn luyện mô hình bằng đoạn mã sau. Bước này có thể mất đến một giờ tùy thuộc vào kích thước cụm của bạn.
remote_run = experiment.submit(automl_config)
Bạn có thể chạy widget RunDetails để hiển thị các thí nghiệm khác nhau.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Triển khai mô hình và sử dụng endpoint với Azure ML SDK
3.1 Lưu mô hình tốt nhất
remote_run là một đối tượng kiểu AutoMLRun. Đối tượng này chứa phương thức get_output() trả về lần chạy tốt nhất và mô hình đã được huấn luyện tương ứng.
best_run, fitted_model = remote_run.get_output()
Bạn có thể xem các tham số được sử dụng cho mô hình tốt nhất chỉ bằng cách in fitted_model và xem các thuộc tính của mô hình tốt nhất bằng cách sử dụng phương thức get_properties().
best_run.get_properties()
Bây giờ hãy đăng ký mô hình với phương thức register_model.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Triển khai mô hình
Khi mô hình tốt nhất đã được lưu, chúng ta có thể triển khai nó với lớp InferenceConfig. InferenceConfig đại diện cho các cài đặt cấu hình cho một môi trường tùy chỉnh được sử dụng để triển khai. Lớp AciWebservice đại diện cho một mô hình học máy được triển khai dưới dạng một endpoint dịch vụ web trên Azure Container Instances. Một dịch vụ được triển khai được tạo từ một mô hình, tập lệnh và các tệp liên quan. Dịch vụ web kết quả là một endpoint HTTP cân bằng tải với REST API. Bạn có thể gửi dữ liệu đến API này và nhận dự đoán trả về từ mô hình.
Mô hình được triển khai bằng phương thức deploy.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
Bước này sẽ mất vài phút.
3.3 Sử dụng endpoint
Bạn sử dụng endpoint của mình bằng cách tạo một đầu vào mẫu:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
Sau đó, bạn có thể gửi đầu vào này đến mô hình của mình để dự đoán:
response = aci_service.run(input_data=test_sample)
response
Điều này sẽ xuất ra '{"result": [false]}'. Điều này có nghĩa là dữ liệu bệnh nhân mà chúng ta gửi đến endpoint đã tạo ra dự đoán false, tức là người này không có khả năng bị đau tim.
Chúc mừng bạn! Bạn vừa sử dụng mô hình được triển khai và huấn luyện trên Azure ML với Azure ML SDK!
NOTE: Khi hoàn thành dự án, đừng quên xóa tất cả các tài nguyên.
🚀 Thử thách
Có rất nhiều điều khác bạn có thể làm thông qua SDK, tuy nhiên, chúng ta không thể xem hết trong bài học này. Nhưng tin tốt là, việc học cách tìm kiếm nhanh qua tài liệu SDK có thể giúp bạn tiến xa hơn. Hãy xem tài liệu Azure ML SDK và tìm lớp Pipeline, lớp này cho phép bạn tạo các pipeline. Pipeline là một tập hợp các bước có thể được thực thi như một quy trình làm việc.
GỢI Ý: Truy cập tài liệu SDK và nhập các từ khóa như "Pipeline" vào thanh tìm kiếm. Bạn sẽ thấy lớp azureml.pipeline.core.Pipeline trong kết quả tìm kiếm.
Câu hỏi sau bài giảng
Ôn tập & Tự học
Trong bài học này, bạn đã học cách huấn luyện, triển khai và sử dụng một mô hình để dự đoán nguy cơ suy tim với Azure ML SDK trên đám mây. Xem tài liệu này để biết thêm thông tin về Azure ML SDK. Hãy thử tạo mô hình của riêng bạn với Azure ML SDK.
Bài tập
Dự án Khoa học Dữ liệu sử dụng Azure ML SDK
Tuyên bố miễn trừ trách nhiệm:
Tài liệu này đã được dịch bằng dịch vụ dịch thuật AI Co-op Translator. Mặc dù chúng tôi cố gắng đảm bảo độ chính xác, xin lưu ý rằng các bản dịch tự động có thể chứa lỗi hoặc không chính xác. Tài liệu gốc bằng ngôn ngữ bản địa nên được coi là nguồn thông tin chính thức. Đối với các thông tin quan trọng, nên sử dụng dịch vụ dịch thuật chuyên nghiệp từ con người. Chúng tôi không chịu trách nhiệm về bất kỳ sự hiểu lầm hoặc diễn giải sai nào phát sinh từ việc sử dụng bản dịch này.