|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
บทนำสู่วงจรชีวิตของวิทยาศาสตร์ข้อมูล
 |
|---|
| บทนำสู่วงจรชีวิตของวิทยาศาสตร์ข้อมูล - สเก็ตช์โน้ตโดย @nitya |
แบบทดสอบก่อนเรียน
ณ จุดนี้ คุณอาจตระหนักแล้วว่าวิทยาศาสตร์ข้อมูลเป็นกระบวนการ กระบวนการนี้สามารถแบ่งออกเป็น 5 ขั้นตอน:
- การเก็บข้อมูล
- การประมวลผล
- การวิเคราะห์
- การสื่อสาร
- การบำรุงรักษา
บทเรียนนี้จะเน้นที่ 3 ส่วนของวงจรชีวิต: การเก็บข้อมูล การประมวลผล และการบำรุงรักษา

การเก็บข้อมูล
ขั้นตอนแรกของวงจรชีวิตมีความสำคัญมาก เนื่องจากขั้นตอนถัดไปจะขึ้นอยู่กับขั้นตอนนี้ โดยพื้นฐานแล้วเป็นการรวมสองขั้นตอนเข้าด้วยกัน: การได้มาซึ่งข้อมูลและการกำหนดวัตถุประสงค์และปัญหาที่ต้องแก้ไข
การกำหนดเป้าหมายของโครงการจะต้องมีความเข้าใจในบริบทของปัญหาหรือคำถามอย่างลึกซึ้ง ก่อนอื่นเราต้องระบุและเข้าถึงผู้ที่ต้องการแก้ปัญหา อาจเป็นผู้มีส่วนได้ส่วนเสียในธุรกิจหรือผู้สนับสนุนโครงการ ซึ่งสามารถช่วยระบุว่าใครหรืออะไรจะได้รับประโยชน์จากโครงการนี้ รวมถึงสิ่งที่พวกเขาต้องการและเหตุผล เป้าหมายที่กำหนดไว้อย่างดีควรสามารถวัดผลได้และมีตัวชี้วัดที่ชัดเจนเพื่อกำหนดผลลัพธ์ที่ยอมรับได้
คำถามที่นักวิทยาศาสตร์ข้อมูลอาจถาม:
- ปัญหานี้เคยถูกแก้ไขมาก่อนหรือไม่? มีการค้นพบอะไรบ้าง?
- ทุกคนที่เกี่ยวข้องเข้าใจวัตถุประสงค์และเป้าหมายหรือไม่?
- มีความคลุมเครือหรือไม่ และจะลดความคลุมเครือนั้นได้อย่างไร?
- มีข้อจำกัดอะไรบ้าง?
- ผลลัพธ์สุดท้ายอาจมีลักษณะอย่างไร?
- มีทรัพยากร (เวลา คน เครื่องมือคำนวณ) เพียงพอหรือไม่?
ถัดไปคือการระบุ รวบรวม และสำรวจข้อมูลที่จำเป็นเพื่อบรรลุเป้าหมายที่กำหนดไว้ ในขั้นตอนการได้มานี้ นักวิทยาศาสตร์ข้อมูลต้องประเมินปริมาณและคุณภาพของข้อมูลด้วย ซึ่งต้องมีการสำรวจข้อมูลบางส่วนเพื่อยืนยันว่าข้อมูลที่ได้มานั้นจะสนับสนุนการบรรลุผลลัพธ์ที่ต้องการ
คำถามที่นักวิทยาศาสตร์ข้อมูลอาจถามเกี่ยวกับข้อมูล:
- ข้อมูลใดที่มีอยู่แล้วสำหรับฉัน?
- ใครเป็นเจ้าของข้อมูลนี้?
- มีข้อกังวลด้านความเป็นส่วนตัวหรือไม่?
- ข้อมูลเพียงพอสำหรับแก้ปัญหานี้หรือไม่?
- คุณภาพของข้อมูลเหมาะสมกับปัญหานี้หรือไม่?
- หากค้นพบข้อมูลเพิ่มเติมจากข้อมูลนี้ ควรพิจารณาเปลี่ยนหรือกำหนดเป้าหมายใหม่หรือไม่?
การประมวลผล
ขั้นตอนการประมวลผลในวงจรชีวิตมุ่งเน้นไปที่การค้นหารูปแบบในข้อมูลและการสร้างแบบจำลอง เทคนิคบางอย่างที่ใช้ในขั้นตอนนี้ต้องอาศัยวิธีการทางสถิติเพื่อค้นหารูปแบบ โดยปกติแล้วจะเป็นงานที่น่าเบื่อสำหรับมนุษย์ในการจัดการกับชุดข้อมูลขนาดใหญ่ และจะพึ่งพาคอมพิวเตอร์เพื่อช่วยเร่งกระบวนการ ขั้นตอนนี้ยังเป็นจุดที่วิทยาศาสตร์ข้อมูลและการเรียนรู้ของเครื่อง (Machine Learning) มาบรรจบกันอีกด้วย ดังที่คุณได้เรียนรู้ในบทเรียนแรก การเรียนรู้ของเครื่องคือกระบวนการสร้างแบบจำลองเพื่อทำความเข้าใจกับข้อมูล แบบจำลองเป็นตัวแทนของความสัมพันธ์ระหว่างตัวแปรในข้อมูลที่ช่วยทำนายผลลัพธ์
เทคนิคทั่วไปที่ใช้ในขั้นตอนนี้มีการกล่าวถึงในหลักสูตร ML for Beginners สามารถติดตามลิงก์เพื่อเรียนรู้เพิ่มเติม:
- การจัดหมวดหมู่ (Classification): การจัดระเบียบข้อมูลเป็นหมวดหมู่เพื่อการใช้งานที่มีประสิทธิภาพมากขึ้น
- การจัดกลุ่ม (Clustering): การจัดกลุ่มข้อมูลที่มีความคล้ายคลึงกัน
- การถดถอย (Regression): การกำหนดความสัมพันธ์ระหว่างตัวแปรเพื่อทำนายหรือคาดการณ์ค่า
การบำรุงรักษา
ในแผนภาพของวงจรชีวิต คุณอาจสังเกตเห็นว่าการบำรุงรักษาอยู่ระหว่างการเก็บข้อมูลและการประมวลผล การบำรุงรักษาเป็นกระบวนการต่อเนื่องในการจัดการ จัดเก็บ และรักษาความปลอดภัยของข้อมูลตลอดกระบวนการของโครงการ และควรได้รับการพิจารณาตลอดระยะเวลาของโครงการ
การจัดเก็บข้อมูล
การพิจารณาว่าจะจัดเก็บข้อมูลอย่างไรและที่ไหนสามารถส่งผลต่อค่าใช้จ่ายในการจัดเก็บ รวมถึงประสิทธิภาพของการเข้าถึงข้อมูล การตัดสินใจเหล่านี้อาจไม่ได้ทำโดยนักวิทยาศาสตร์ข้อมูลเพียงคนเดียว แต่พวกเขาอาจต้องเลือกวิธีการทำงานกับข้อมูลตามวิธีการจัดเก็บ
นี่คือบางแง่มุมของระบบจัดเก็บข้อมูลสมัยใหม่ที่อาจส่งผลต่อการตัดสินใจ:
ในสถานที่ (On premise) กับนอกสถานที่ (Off premise) กับคลาวด์สาธารณะหรือส่วนตัว
การจัดเก็บในสถานที่หมายถึงการจัดการข้อมูลบนอุปกรณ์ของคุณเอง เช่น การเป็นเจ้าของเซิร์ฟเวอร์ที่มีฮาร์ดไดรฟ์สำหรับจัดเก็บข้อมูล ในขณะที่การจัดเก็บนอกสถานที่พึ่งพาอุปกรณ์ที่คุณไม่ได้เป็นเจ้าของ เช่น ศูนย์ข้อมูล คลาวด์สาธารณะเป็นตัวเลือกยอดนิยมสำหรับการจัดเก็บข้อมูลที่ไม่ต้องการความรู้เกี่ยวกับวิธีหรือสถานที่จัดเก็บข้อมูลอย่างแน่ชัด ในขณะที่คลาวด์ส่วนตัวเหมาะสำหรับองค์กรที่มีนโยบายความปลอดภัยที่เข้มงวดและต้องการการควบคุมอุปกรณ์ที่จัดเก็บข้อมูล คุณจะได้เรียนรู้เพิ่มเติมเกี่ยวกับข้อมูลในคลาวด์ใน บทเรียนถัดไป
ข้อมูลเย็น (Cold data) กับข้อมูลร้อน (Hot data)
เมื่อฝึกอบรมแบบจำลองของคุณ คุณอาจต้องการข้อมูลฝึกอบรมเพิ่มเติม หากคุณพอใจกับแบบจำลองของคุณแล้ว ข้อมูลเพิ่มเติมจะมาถึงเพื่อให้แบบจำลองทำหน้าที่ของมัน ในกรณีใดก็ตาม ค่าใช้จ่ายในการจัดเก็บและเข้าถึงข้อมูลจะเพิ่มขึ้นเมื่อคุณสะสมข้อมูลมากขึ้น การแยกข้อมูลที่ไม่ค่อยได้ใช้งานหรือข้อมูลเย็นออกจากข้อมูลที่เข้าถึงบ่อยหรือข้อมูลร้อน อาจเป็นตัวเลือกการจัดเก็บข้อมูลที่ถูกกว่าผ่านฮาร์ดแวร์หรือบริการซอฟต์แวร์ หากต้องการเข้าถึงข้อมูลเย็น อาจใช้เวลานานกว่าข้อมูลร้อนเล็กน้อย
การจัดการข้อมูล
เมื่อคุณทำงานกับข้อมูล คุณอาจพบว่าข้อมูลบางส่วนจำเป็นต้องได้รับการทำความสะอาดโดยใช้เทคนิคบางอย่างที่ครอบคลุมในบทเรียนเกี่ยวกับ การเตรียมข้อมูล เพื่อสร้างแบบจำลองที่แม่นยำ เมื่อมีข้อมูลใหม่เข้ามา ข้อมูลนั้นจะต้องได้รับการประยุกต์ใช้เทคนิคเดียวกันเพื่อรักษาความสม่ำเสมอในคุณภาพ โครงการบางโครงการจะเกี่ยวข้องกับการใช้เครื่องมืออัตโนมัติสำหรับการทำความสะอาด การรวมข้อมูล และการบีบอัดก่อนที่ข้อมูลจะถูกย้ายไปยังตำแหน่งสุดท้าย Azure Data Factory เป็นตัวอย่างหนึ่งของเครื่องมือเหล่านี้
การรักษาความปลอดภัยของข้อมูล
หนึ่งในเป้าหมายหลักของการรักษาความปลอดภัยข้อมูลคือการทำให้แน่ใจว่าผู้ที่ทำงานกับข้อมูลสามารถควบคุมสิ่งที่ถูกรวบรวมและบริบทที่ใช้ข้อมูลได้ การรักษาความปลอดภัยข้อมูลเกี่ยวข้องกับการจำกัดการเข้าถึงเฉพาะผู้ที่จำเป็นต้องใช้ข้อมูล ปฏิบัติตามกฎหมายและข้อบังคับท้องถิ่น รวมถึงรักษามาตรฐานทางจริยธรรม ดังที่ได้กล่าวไว้ใน บทเรียนจริยธรรม
นี่คือสิ่งที่ทีมอาจทำโดยคำนึงถึงความปลอดภัย:
- ยืนยันว่าข้อมูลทั้งหมดถูกเข้ารหัส
- ให้ข้อมูลแก่ลูกค้าเกี่ยวกับวิธีการใช้ข้อมูลของพวกเขา
- ลบการเข้าถึงข้อมูลจากผู้ที่ออกจากโครงการ
- อนุญาตให้สมาชิกโครงการบางคนเท่านั้นที่สามารถแก้ไขข้อมูลได้
🚀 ความท้าทาย
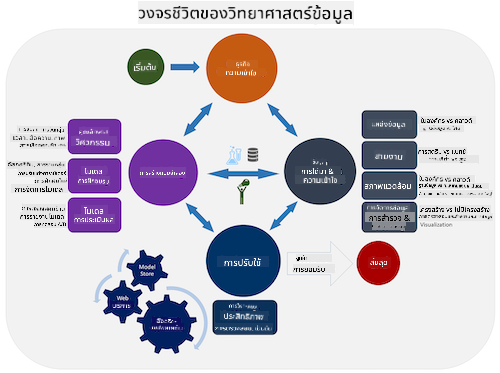
มีหลายเวอร์ชันของวงจรชีวิตวิทยาศาสตร์ข้อมูล ซึ่งแต่ละขั้นตอนอาจมีชื่อและจำนวนขั้นตอนที่แตกต่างกัน แต่จะมีกระบวนการเดียวกันที่กล่าวถึงในบทเรียนนี้
สำรวจ วงจรชีวิต Team Data Science Process และ มาตรฐานข้ามอุตสาหกรรมสำหรับการทำเหมืองข้อมูล (CRISP-DM) ระบุ 3 ความเหมือนและความแตกต่างระหว่างทั้งสอง
| Team Data Science Process (TDSP) | มาตรฐานข้ามอุตสาหกรรมสำหรับการทำเหมืองข้อมูล (CRISP-DM) |
|---|---|
 |
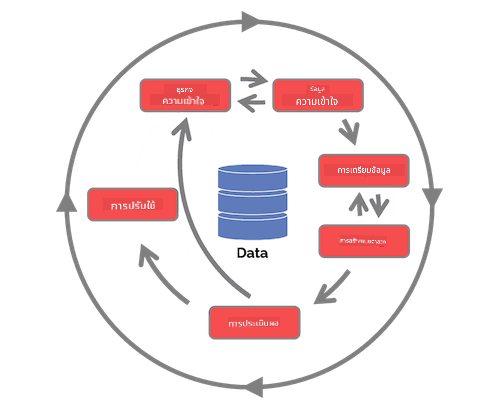 |
| ภาพโดย Microsoft | ภาพโดย Data Science Process Alliance |
แบบทดสอบหลังเรียน
ทบทวนและศึกษาด้วยตนเอง
การประยุกต์ใช้วงจรชีวิตวิทยาศาสตร์ข้อมูลเกี่ยวข้องกับบทบาทและงานหลายอย่าง ซึ่งบางคนอาจมุ่งเน้นไปที่ส่วนใดส่วนหนึ่งของแต่ละขั้นตอน Team Data Science Process มีทรัพยากรบางอย่างที่อธิบายประเภทของบทบาทและงานที่ใครบางคนอาจมีในโครงการ
- บทบาทและงานใน Team Data Science Process
- ดำเนินการงานวิทยาศาสตร์ข้อมูล: การสำรวจ การสร้างแบบจำลอง และการปรับใช้
การบ้าน
ข้อจำกัดความรับผิดชอบ:
เอกสารนี้ได้รับการแปลโดยใช้บริการแปลภาษา AI Co-op Translator แม้ว่าเราจะพยายามให้การแปลมีความถูกต้อง แต่โปรดทราบว่าการแปลโดยอัตโนมัติอาจมีข้อผิดพลาดหรือความไม่ถูกต้อง เอกสารต้นฉบับในภาษาที่เป็นต้นฉบับควรถือว่าเป็นแหล่งข้อมูลที่เชื่อถือได้ สำหรับข้อมูลที่สำคัญ ขอแนะนำให้ใช้บริการแปลภาษามืออาชีพ เราไม่รับผิดชอบต่อความเข้าใจผิดหรือการตีความที่ผิดพลาดซึ่งเกิดจากการใช้การแปลนี้