|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 3 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
Рад са подацима: Python и библиотека Pandas
 |
|---|
| Рад са Python-ом - Скетч од @nitya |

Иако базе података нуде веома ефикасне начине за складиштење података и њихово претраживање помоћу језика за упите, најфлексибилнији начин обраде података је писање сопственог програма за манипулацију подацима. У многим случајевима, коришћење упита у бази података би било ефикасније. Међутим, у неким случајевима када је потребна сложенија обрада података, то се не може лако урадити помоћу SQL-а. Обрада података може се програмирати у било ком програмском језику, али постоје одређени језици који су на вишем нивоу када је у питању рад са подацима. Научници који се баве подацима обично преферирају један од следећих језика:
- Python, опште-наменски програмски језик, који се често сматра једним од најбољих избора за почетнике због своје једноставности. Python има много додатних библиотека које вам могу помоћи да решите многе практичне проблеме, као што су издвајање података из ZIP архиве или претварање слике у сиве тонове. Поред науке о подацима, Python се често користи и за развој веба.
- R је традиционални алат развијен са циљем статистичке обраде података. Такође садржи велики репозиторијум библиотека (CRAN), што га чини добрим избором за обраду података. Међутим, R није опште-наменски програмски језик и ретко се користи ван домена науке о подацима.
- Julia је још један језик развијен специјално за науку о подацима. Намера му је да пружи боље перформансе од Python-а, што га чини одличним алатом за научне експерименте.
У овом лекцији, фокусираћемо се на коришћење Python-а за једноставну обраду података. Претпоставићемо основно познавање језика. Ако желите дубљи увод у Python, можете се обратити једном од следећих ресурса:
- Научите Python на забаван начин уз Turtle Graphics и фрактале - брзи уводни курс у Python програмирање на GitHub-у
- Направите прве кораке са Python-ом Пут учења на Microsoft Learn
Подаци могу бити у различитим облицима. У овој лекцији, разматраћемо три облика података - табеларни подаци, текст и слике.
Фокусираћемо се на неколико примера обраде података, уместо да вам дамо потпуни преглед свих повезаних библиотека. Ово ће вам омогућити да добијете основну идеју о томе шта је могуће, и оставити вас са разумевањем где да пронађете решења за своје проблеме када вам затребају.
Најкориснији савет. Када треба да извршите одређену операцију на подацима коју не знате како да урадите, покушајте да је потражите на интернету. Stackoverflow обично садржи много корисних примера кода у Python-у за многе типичне задатке.
Квиз пре предавања
Табеларни подаци и DataFrame-ови
Већ сте се сусрели са табеларним подацима када смо говорили о релационим базама података. Када имате много података, и они су садржани у многим различитим повезаним табелама, дефинитивно има смисла користити SQL за рад са њима. Међутим, постоје многи случајеви када имамо табелу података и треба да стекнемо неко разумевање или увиде о тим подацима, као што су расподела, корелација између вредности, итд. У науци о подацима, постоји много случајева када треба да извршимо неке трансформације оригиналних података, праћене визуализацијом. Оба ова корака могу се лако урадити помоћу Python-а.
Постоје две најкорисније библиотеке у Python-у које вам могу помоћи да радите са табеларним подацима:
- Pandas вам омогућава да манипулишете такозваним DataFrame-овима, који су аналогни релационим табелама. Можете имати именоване колоне и извршавати различите операције на редовима, колонама и DataFrame-овима уопште.
- Numpy је библиотека за рад са тензорима, тј. вишедимензионалним низовима. Низ има вредности истог основног типа и једноставнији је од DataFrame-а, али нуди више математичких операција и ствара мање оптерећења.
Постоје и неколико других библиотека које би требало да знате:
- Matplotlib је библиотека која се користи за визуализацију података и цртање графикона
- SciPy је библиотека са неким додатним научним функцијама. Већ смо наишли на ову библиотеку када смо говорили о вероватноћи и статистици
Ево дела кода који бисте обично користили за увоз ових библиотека на почетку вашег Python програма:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas је усредсређен на неколико основних концепата.
Series
Series је низ вредности, сличан листи или numpy низу. Главна разлика је у томе што Series такође има индекс, и када радимо са Series (нпр. додајемо их), индекс се узима у обзир. Индекс може бити једноставан као број реда (то је индекс који се користи подразумевано када се креира Series из листе или низа), или може имати сложену структуру, као што је временски интервал.
Напомена: У пратећем нотебуку
notebook.ipynbналази се уводни код за Pandas. Овде ћемо само навести неке примере, а свакако сте добродошли да проверите комплетан нотебук.
Размотримо пример: желимо да анализирамо продају у нашој продавници сладоледа. Генерисаћемо низ бројева продаје (број продатих артикала сваког дана) за одређени временски период:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
Сада претпоставимо да сваке недеље организујемо журку за пријатеље и узимамо додатних 10 пакета сладоледа за журку. Можемо креирати други низ, индексиран по недељама, да то покажемо:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
Када саберемо два низа, добијамо укупан број:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
Напомена да не користимо једноставну синтаксу
total_items+additional_items. Да јесмо, добили бисмо многоNaN(Not a Number) вредности у резултујућем низу. То је зато што недостају вредности за неке тачке индекса у низуadditional_items, а додавањеNaNбило чему резултира уNaN. Због тога морамо да наведемо параметарfill_valueтоком сабирања.
Са временским низовима, можемо такође ресемпловати низове са различитим временским интервалима. На пример, ако желимо да израчунамо просечну количину продаје месечно, можемо користити следећи код:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
DataFrame
DataFrame је у суштини колекција Series-а са истим индексом. Можемо комбиновати неколико Series-а у DataFrame:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
Ово ће креирати хоризонталну табелу попут ове:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
Можемо такође користити Series као колоне и одредити имена колона користећи речник:
df = pd.DataFrame({ 'A' : a, 'B' : b })
Ово ће нам дати табелу попут ове:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
Напомена да ову табелу можемо добити и транспоновањем претходне табеле, нпр. писањем
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
Овде .T означава операцију транспоновања DataFrame-а, тј. промену редова и колона, а операција rename нам омогућава да преименујемо колоне како би одговарале претходном примеру.
Ево неколико најважнијих операција које можемо извршити на DataFrame-овима:
Избор колона. Можемо изабрати појединачне колоне писањем df['A'] - ова операција враћа Series. Такође можемо изабрати подскуп колона у други DataFrame писањем df[['B','A']] - ово враћа други DataFrame.
Филтрирање само одређених редова по критеријуму. На пример, да оставимо само редове где је колона A већа од 5, можемо написати df[df['A']>5].
Напомена: Начин на који филтрирање функционише је следећи. Израз
df['A']<5враћа буловски низ, који указује да ли је изразTrueилиFalseза сваки елемент оригиналног низаdf['A']. Када се буловски низ користи као индекс, он враћа подскуп редова у DataFrame-у. Због тога није могуће користити произвољни Python буловски израз, на пример, писањеdf[df['A']>5 and df['A']<7]било би погрешно. Уместо тога, треба користити посебну операцију&на буловским низовима, писањемdf[(df['A']>5) & (df['A']<7)](заграде су овде важне).
Креирање нових рачунских колона. Можемо лако креирати нове рачунске колоне за наш DataFrame користећи интуитивне изразе попут овог:
df['DivA'] = df['A']-df['A'].mean()
Овај пример израчунава одступање A од његове просечне вредности. Оно што се овде заправо дешава је да рачунамо Series, а затим додељујемо овај Series левој страни, креирајући нову колону. Због тога не можемо користити операције које нису компатибилне са Series-ом, на пример, следећи код је погрешан:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
Последњи пример, иако је синтаксно исправан, даје нам погрешан резултат, јер додељује дужину Series-а B свим вредностима у колони, а не дужину појединачних елемената како смо намеравали.
Ако треба да израчунамо сложене изразе попут овог, можемо користити функцију apply. Последњи пример може се написати на следећи начин:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
Након горе наведених операција, добићемо следећи DataFrame:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
Избор редова на основу бројева може се урадити коришћењем конструкта iloc. На пример, да изаберемо првих 5 редова из DataFrame-а:
df.iloc[:5]
Груписање се често користи за добијање резултата сличних пивот табелама у Excel-у. Претпоставимо да желимо да израчунамо просечну вредност колоне A за сваки дати број LenB. Тада можемо груписати наш DataFrame по LenB и позвати mean:
df.groupby(by='LenB').mean()
Ако треба да израчунамо просек и број елемената у групи, онда можемо користити сложенију функцију aggregate:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
Ово нам даје следећу табелу:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
Добијање података
Видели смо колико је лако конструисати Series и DataFrame објекте из Python објеката. Међутим, подаци обично долазе у облику текстуалних фајлова или Excel табела. Срећом, Pandas нам нуди једноставан начин за учитавање података са диска. На пример, читање CSV фајла је једноставно као ово:
df = pd.read_csv('file.csv')
Видећемо више примера учитавања података, укључујући и преузимање са спољних веб сајтова, у одељку "Изазов".
Штампање и графички приказ
Data Scientist често мора да истражује податке, па је важно да их може визуализовати. Када је DataFrame велики, често желимо само да проверимо да ли све радимо исправно тако што ћемо одштампати првих неколико редова. Ово се може урадити позивом df.head(). Ако га покрећете из Jupyter Notebook-а, он ће приказати DataFrame у лепом табеларном облику.
Такође смо видели употребу функције plot за визуализацију неких колона. Иако је plot веома користан за многе задатке и подржава различите типове графикона преко параметра kind=, увек можете користити библиотеку matplotlib за сложеније графиконе. Детаљно ћемо обрадити визуализацију података у посебним лекцијама курса.
Овај преглед покрива најважније концепте Pandas-а, али библиотека је веома богата и нема ограничења у томе шта можете да урадите са њом! Хајде сада да применимо ово знање за решавање конкретног проблема.
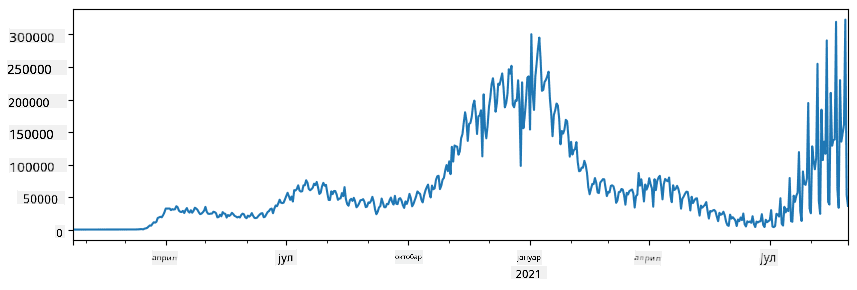
🚀 Изазов 1: Анализа ширења COVID-а
Први проблем на који ћемо се фокусирати је моделирање ширења епидемије COVID-19. Да бисмо то урадили, користићемо податке о броју заражених особа у различитим земљама, које пружа Center for Systems Science and Engineering (CSSE) на Johns Hopkins University. Скуп података је доступан у овом GitHub репозиторијуму.
Пошто желимо да демонстрирамо како се ради са подацима, позивамо вас да отворите notebook-covidspread.ipynb и прочитате га од почетка до краја. Такође можете извршавати ћелије и решавати неке изазове које смо оставили за вас на крају.
Ако не знате како да покренете код у Jupyter Notebook-у, погледајте овај чланак.
Рад са неструктурираним подацима
Иако подаци често долазе у табеларном облику, у неким случајевима морамо радити са мање структурираном врстом података, на пример, текстом или сликама. У том случају, да бисмо применили технике обраде података које смо видели, морамо некако извући структуиране податке. Ево неколико примера:
- Извлачење кључних речи из текста и праћење њихове учесталости
- Коришћење неуронских мрежа за извлачење информација о објектима на слици
- Добијање информација о емоцијама људи са видео камере
🚀 Изазов 2: Анализа COVID научних радова
У овом изазову настављамо тему COVID пандемије и фокусирамо се на обраду научних радова на ту тему. Постоји CORD-19 Dataset са више од 7000 (у време писања) радова о COVID-у, доступан са метаподацима и апстрактима (а за око половину њих доступан је и цео текст).
Потпун пример анализе овог скупа података коришћењем когнитивне услуге Text Analytics for Health описан је у овом блогу. Размотрићемо поједностављену верзију ове анализе.
NOTE: Не пружамо копију скупа података као део овог репозиторијума. Можда ћете прво морати да преузмете фајл
metadata.csvиз овог скупа података на Kaggle-у. Регистрација на Kaggle може бити потребна. Такође можете преузети скуп података без регистрације овде, али ће укључивати све пуне текстове поред метаподатака.
Отворите notebook-papers.ipynb и прочитајте га од почетка до краја. Такође можете извршавати ћелије и решавати неке изазове које смо оставили за вас на крају.
Обрада података са слика
У последње време развијени су веома моћни AI модели који нам омогућавају да разумемо слике. Постоји много задатака који се могу решити коришћењем претходно обучених неуронских мрежа или cloud услуга. Неки примери укључују:
- Класификација слика, која вам може помоћи да категоризујете слику у једну од унапред дефинисаних класа. Лако можете обучити сопствене класификаторе слика користећи услуге као што је Custom Vision
- Детекција објеката за откривање различитих објеката на слици. Услуге као што је computer vision могу детектовати бројне уобичајене објекте, а можете обучити Custom Vision модел за детекцију специфичних објеката од интереса.
- Детекција лица, укључујући процену старости, пола и емоција. Ово се може урадити преко Face API.
Све те cloud услуге могу се позивати коришћењем Python SDK-ова, и тако се лако могу укључити у ваш ток истраживања података.
Ево неколико примера истраживања података из извора слика:
- У блогу Како учити Data Science без кодирања истражујемо Instagram фотографије, покушавајући да разумемо шта људе мотивише да дају више лајкова на фотографију. Прво извлачимо што више информација из слика користећи computer vision, а затим користимо Azure Machine Learning AutoML за изградњу интерпретабилног модела.
- У Радионици о студијама лица користимо Face API за извлачење емоција људи на фотографијама са догађаја, како бисмо покушали да разумемо шта људе чини срећним.
Закључак
Без обзира да ли већ имате структуиране или неструктуиране податке, коришћењем Python-а можете извршити све кораке везане за обраду и разумевање података. Python је вероватно најфлексибилнији начин за обраду података, и то је разлог зашто већина Data Scientist-а користи Python као свој примарни алат. Учити Python детаљно је вероватно добра идеја ако сте озбиљни у својој Data Science авантури!
Квиз након предавања
Преглед и самостално учење
Књиге
Онлајн ресурси
- Званични 10 минута до Pandas туторијал
- Документација о Pandas визуализацији
Учење Python-а
- Научите Python на забаван начин са Turtle Graphics и фракталима
- Направите своје прве кораке са Python-ом Learning Path на Microsoft Learn
Задатак
Извршите детаљнију студију података за горе наведене изазове
Кредити
Ова лекција је написана са ♥️ од стране Dmitry Soshnikov
Одрицање од одговорности:
Овај документ је преведен коришћењем услуге за превођење помоћу вештачке интелигенције Co-op Translator. Иако се трудимо да обезбедимо тачност, имајте у виду да аутоматски преводи могу садржати грешке или нетачности. Оригинални документ на изворном језику треба сматрати ауторитативним извором. За критичне информације препоручује се професионални превод од стране људи. Не сносимо одговорност за било каква погрешна тумачења или неспоразуме који могу произаћи из коришћења овог превода.