|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 3 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
ਡਾਟਾ ਸਾਇੰਸ ਲਾਈਫਸਾਈਕਲ ਦਾ ਪਰਚੇ
| ਡਾਟਾ ਸਾਇੰਸ ਲਾਈਫਸਾਈਕਲ ਦਾ ਪਰਚੇ - @nitya ਦੁਆਰਾ ਬਣਾਈ ਗਈ ਸਕੈਚਨੋਟ |
ਪ੍ਰੀ-ਲੈਕਚਰ ਕਵਿਜ਼
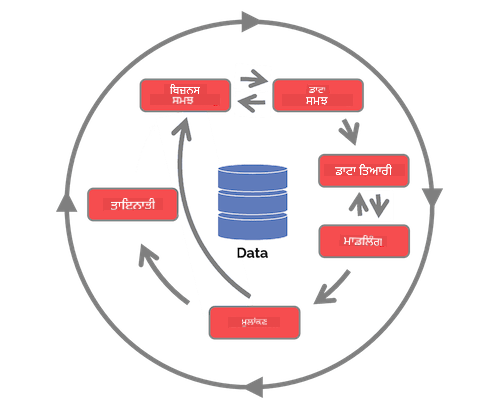
ਇਸ ਸਮੇਂ ਤੱਕ ਤੁਹਾਨੂੰ ਸ਼ਾਇਦ ਇਹ ਅਹਿਸਾਸ ਹੋ ਗਿਆ ਹੋਵੇ ਕਿ ਡਾਟਾ ਸਾਇੰਸ ਇੱਕ ਪ੍ਰਕਿਰਿਆ ਹੈ। ਇਸ ਪ੍ਰਕਿਰਿਆ ਨੂੰ 5 ਚਰਨਾਂ ਵਿੱਚ ਵੰਡਿਆ ਜਾ ਸਕਦਾ ਹੈ:
- ਡਾਟਾ ਇਕੱਠਾ ਕਰਨਾ
- ਪ੍ਰੋਸੈਸਿੰਗ
- ਵਿਸ਼ਲੇਸ਼ਣ
- ਸੰਚਾਰ
- ਰੱਖ-ਰਖਾਵ
ਇਹ ਪਾਠ ਲਾਈਫਸਾਈਕਲ ਦੇ 3 ਹਿੱਸਿਆਂ 'ਤੇ ਧਿਆਨ ਕੇਂਦਰਿਤ ਕਰਦਾ ਹੈ: ਡਾਟਾ ਇਕੱਠਾ ਕਰਨਾ, ਪ੍ਰੋਸੈਸਿੰਗ ਅਤੇ ਰੱਖ-ਰਖਾਵ।
ਬਰਕਲੀ ਸਕੂਲ ਆਫ ਇਨਫਾਰਮੇਸ਼ਨ ਦੁਆਰਾ ਫੋਟੋ
ਡਾਟਾ ਇਕੱਠਾ ਕਰਨਾ
ਲਾਈਫਸਾਈਕਲ ਦਾ ਪਹਿਲਾ ਚਰਨ ਬਹੁਤ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿਉਂਕਿ ਅਗਲੇ ਚਰਨ ਇਸ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ। ਇਹ ਅਸਲ ਵਿੱਚ ਦੋ ਚਰਨਾਂ ਨੂੰ ਇੱਕ ਵਿੱਚ ਜੋੜਦਾ ਹੈ: ਡਾਟਾ ਪ੍ਰਾਪਤ ਕਰਨਾ ਅਤੇ ਉਸ ਦੇ ਉਦੇਸ਼ ਅਤੇ ਸਮੱਸਿਆਵਾਂ ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰਨਾ ਜਿਨ੍ਹਾਂ ਨੂੰ ਹੱਲ ਕਰਨ ਦੀ ਲੋੜ ਹੈ।
ਪ੍ਰੋਜੈਕਟ ਦੇ ਉਦੇਸ਼ਾਂ ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕਰਨ ਲਈ ਸਮੱਸਿਆ ਜਾਂ ਸਵਾਲ ਵਿੱਚ ਡੂੰਘੀ ਸੰਦਰਭਤਾ ਦੀ ਲੋੜ ਹੋਵੇਗੀ। ਪਹਿਲਾਂ, ਸਾਨੂੰ ਉਹਨਾਂ ਦੀ ਪਛਾਣ ਅਤੇ ਪ੍ਰਾਪਤੀ ਕਰਨੀ ਪਵੇਗੀ ਜਿਨ੍ਹਾਂ ਦੀ ਸਮੱਸਿਆ ਹੱਲ ਕਰਨ ਦੀ ਲੋੜ ਹੈ। ਇਹ ਕਾਰੋਬਾਰ ਵਿੱਚ ਹਿੱਸੇਦਾਰ ਜਾਂ ਪ੍ਰੋਜੈਕਟ ਦੇ ਸਪਾਂਸਰ ਹੋ ਸਕਦੇ ਹਨ, ਜੋ ਇਹ ਪਛਾਣ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦੇ ਹਨ ਕਿ ਇਸ ਪ੍ਰੋਜੈਕਟ ਤੋਂ ਕੌਣ ਜਾਂ ਕੀ ਲਾਭ ਪ੍ਰਾਪਤ ਕਰੇਗਾ ਅਤੇ ਕਿਉਂ। ਇੱਕ ਚੰਗਾ ਪਰਿਭਾਸ਼ਿਤ ਉਦੇਸ਼ ਮਾਪਣਯੋਗ ਅਤੇ ਗਣਨਯੋਗ ਹੋਣਾ ਚਾਹੀਦਾ ਹੈ ਤਾਂ ਜੋ ਇੱਕ ਸਵੀਕਾਰਯੋਗ ਨਤੀਜੇ ਨੂੰ ਪਰਿਭਾਸ਼ਿਤ ਕੀਤਾ ਜਾ ਸਕੇ।
ਡਾਟਾ ਸਾਇੰਟਿਸਟ ਪੂਛ ਸਕਦੇ ਹਨ:
- ਕੀ ਇਸ ਸਮੱਸਿਆ ਨੂੰ ਪਹਿਲਾਂ ਹੱਲ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕੀਤੀ ਗਈ ਹੈ? ਕੀ ਪਤਾ ਲੱਗਾ?
- ਕੀ ਉਦੇਸ਼ ਅਤੇ ਮਕਸਦ ਸਾਰੇ ਸ਼ਾਮਲ ਲੋਕਾਂ ਦੁਆਰਾ ਸਮਝੇ ਗਏ ਹਨ?
- ਕੀ ਕੋਈ ਅਸਪਸ਼ਟਤਾ ਹੈ ਅਤੇ ਇਸਨੂੰ ਘਟਾਉਣ ਲਈ ਕੀ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ?
- ਪਾਬੰਦੀਆਂ ਕੀ ਹਨ?
- ਅੰਤਮ ਨਤੀਜਾ ਕਿਵੇਂ ਦਿਖ ਸਕਦਾ ਹੈ?
- ਕਿੰਨੇ ਸਰੋਤ (ਸਮਾਂ, ਲੋਕ, ਗਣਨਾਤਮਕ) ਉਪਲਬਧ ਹਨ?
ਅਗਲਾ ਕਦਮ ਹੈ ਡਾਟਾ ਦੀ ਪਛਾਣ, ਇਕੱਠਾ ਕਰਨਾ ਅਤੇ ਫਿਰ ਉਸ ਡਾਟਾ ਦੀ ਖੋਜ ਕਰਨੀ ਜੋ ਪਰਿਭਾਸ਼ਿਤ ਉਦੇਸ਼ਾਂ ਨੂੰ ਪ੍ਰਾਪਤ ਕਰਨ ਲਈ ਲੋੜੀਂਦਾ ਹੈ। ਇਸ ਪ੍ਰਾਪਤੀ ਦੇ ਕਦਮ 'ਤੇ, ਡਾਟਾ ਸਾਇੰਟਿਸਟਾਂ ਨੂੰ ਡਾਟਾ ਦੀ ਮਾਤਰਾ ਅਤੇ ਗੁਣਵੱਤਾ ਦਾ ਮੁਲਾਂਕਣ ਕਰਨਾ ਪਵੇਗਾ। ਇਸ ਲਈ ਕੁਝ ਡਾਟਾ ਦੀ ਖੋਜ ਕਰਨ ਦੀ ਲੋੜ ਹੋਵੇਗੀ ਤਾਂ ਜੋ ਇਹ ਪੁਸ਼ਟੀ ਕੀਤੀ ਜਾ ਸਕੇ ਕਿ ਜੋ ਪ੍ਰਾਪਤ ਕੀਤਾ ਗਿਆ ਹੈ ਉਹ ਚਾਹੇ ਨਤੀਜੇ ਤੱਕ ਪਹੁੰਚਣ ਵਿੱਚ ਸਹਾਇਕ ਹੋਵੇਗਾ।
ਡਾਟਾ ਸਾਇੰਟਿਸਟ ਡਾਟਾ ਬਾਰੇ ਪੂਛ ਸਕਦੇ ਹਨ:
- ਮੇਰੇ ਕੋਲ ਪਹਿਲਾਂ ਹੀ ਕਿਹੜਾ ਡਾਟਾ ਉਪਲਬਧ ਹੈ?
- ਇਸ ਡਾਟਾ ਦਾ ਮਾਲਕ ਕੌਣ ਹੈ?
- ਗੋਪਨੀਯਤਾ ਦੇ ਚਿੰਤਾ ਦੇ ਮੁੱਦੇ ਕੀ ਹਨ?
- ਕੀ ਇਸ ਸਮੱਸਿਆ ਨੂੰ ਹੱਲ ਕਰਨ ਲਈ ਮੇਰੇ ਕੋਲ ਕਾਫ਼ੀ ਡਾਟਾ ਹੈ?
- ਕੀ ਇਹ ਡਾਟਾ ਇਸ ਸਮੱਸਿਆ ਲਈ ਸਵੀਕਾਰਯੋਗ ਗੁਣਵੱਤਾ ਦਾ ਹੈ?
- ਜੇਕਰ ਮੈਂ ਇਸ ਡਾਟਾ ਦੁਆਰਾ ਵਧੇਰੇ ਜਾਣਕਾਰੀ ਦੀ ਖੋਜ ਕਰਦਾ ਹਾਂ, ਤਾਂ ਕੀ ਸਾਨੂੰ ਉਦੇਸ਼ਾਂ ਨੂੰ ਬਦਲਣ ਜਾਂ ਮੁੜ ਪਰਿਭਾਸ਼ਿਤ ਕਰਨ ਬਾਰੇ ਸੋਚਣਾ ਚਾਹੀਦਾ ਹੈ?
ਪ੍ਰੋਸੈਸਿੰਗ
ਲਾਈਫਸਾਈਕਲ ਦਾ ਪ੍ਰੋਸੈਸਿੰਗ ਚਰਨ ਡਾਟਾ ਵਿੱਚ ਪੈਟਰਨ ਦੀ ਖੋਜ ਅਤੇ ਮਾਡਲਿੰਗ 'ਤੇ ਧਿਆਨ ਕੇਂਦਰਿਤ ਕਰਦਾ ਹੈ। ਪ੍ਰੋਸੈਸਿੰਗ ਚਰਨ ਵਿੱਚ ਵਰਤੇ ਜਾਣ ਵਾਲੇ ਕੁਝ ਤਕਨੀਕਾਂ ਪੈਟਰਨ ਦੀ ਖੋਜ ਕਰਨ ਲਈ ਅੰਕੜੇਵਾਦੀ ਵਿਧੀਆਂ ਦੀ ਲੋੜ ਹੋਵੇਗੀ। ਆਮ ਤੌਰ 'ਤੇ, ਇਹ ਇੱਕ ਵੱਡੇ ਡਾਟਾ ਸੈਟ ਨਾਲ ਮਨੁੱਖ ਲਈ ਬਹੁਤ ਥਕਾਵਟ ਭਰਿਆ ਕੰਮ ਹੋਵੇਗਾ ਅਤੇ ਇਸ ਪ੍ਰਕਿਰਿਆ ਨੂੰ ਤੇਜ਼ ਕਰਨ ਲਈ ਕੰਪਿਊਟਰਾਂ 'ਤੇ ਨਿਰਭਰ ਕੀਤਾ ਜਾਵੇਗਾ। ਇਹ ਚਰਨ ਉਹ ਜਗ੍ਹਾ ਹੈ ਜਿੱਥੇ ਡਾਟਾ ਸਾਇੰਸ ਅਤੇ ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਇੱਕ ਦੂਜੇ ਨਾਲ ਜੁੜਦੇ ਹਨ। ਜਿਵੇਂ ਕਿ ਤੁਸੀਂ ਪਹਿਲੇ ਪਾਠ ਵਿੱਚ ਸਿੱਖਿਆ, ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਡਾਟਾ ਨੂੰ ਸਮਝਣ ਲਈ ਮਾਡਲ ਬਣਾਉਣ ਦੀ ਪ੍ਰਕਿਰਿਆ ਹੈ। ਮਾਡਲ ਡਾਟਾ ਵਿੱਚ ਚਲਾਂ ਵਿੱਚ ਵਾਰਸੂਬੰਧਤਾ ਦੀ ਪ੍ਰਤੀਨਿਧਤਾ ਹੁੰਦੇ ਹਨ ਜੋ ਨਤੀਜਿਆਂ ਦੀ ਪੇਸ਼ਗੋਈ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ।
ਇਸ ਚਰਨ ਵਿੱਚ ਵਰਤੀਆਂ ਜਾਣ ਵਾਲੀਆਂ ਆਮ ਤਕਨੀਕਾਂ ML for Beginners ਦੇ ਪਾਠਕ੍ਰਮ ਵਿੱਚ ਕਵਰ ਕੀਤੀਆਂ ਗਈਆਂ ਹਨ। ਇਨ੍ਹਾਂ ਬਾਰੇ ਹੋਰ ਜਾਣਨ ਲਈ ਲਿੰਕਾਂ ਦੀ ਪਾਲਣਾ ਕਰੋ:
- ਕਲਾਸੀਫਿਕੇਸ਼ਨ: ਡਾਟਾ ਨੂੰ ਸ਼੍ਰੇਣੀਆਂ ਵਿੱਚ ਵਿਵਸਥਿਤ ਕਰਨਾ।
- ਕਲਸਟਰਿੰਗ: ਡਾਟਾ ਨੂੰ ਸਮਾਨ ਸਮੂਹਾਂ ਵਿੱਚ ਵੰਡਣਾ।
- ਰਿਗਰੈਸ਼ਨ: ਚਲਾਂ ਵਿੱਚ ਵਾਰਸੂਬੰਧਤਾ ਨੂੰ ਪਤਾ ਲਗਾਉਣਾ ਅਤੇ ਮੁੱਲਾਂ ਦੀ ਪੇਸ਼ਗੋਈ ਕਰਨਾ।
ਰੱਖ-ਰਖਾਵ
ਲਾਈਫਸਾਈਕਲ ਦੇ ਚਿੱਤਰ ਵਿੱਚ, ਤੁਸੀਂ ਸ਼ਾਇਦ ਧਿਆਨ ਦਿੱਤਾ ਹੋਵੇਗਾ ਕਿ ਰੱਖ-ਰਖਾਵ ਡਾਟਾ ਇਕੱਠਾ ਕਰਨ ਅਤੇ ਪ੍ਰੋਸੈਸਿੰਗ ਦੇ ਵਿਚਕਾਰ ਸਥਿਤ ਹੈ। ਰੱਖ-ਰਖਾਵ ਇੱਕ ongoing ਪ੍ਰਕਿਰਿਆ ਹੈ ਜੋ ਪ੍ਰੋਜੈਕਟ ਦੇ ਦੌਰਾਨ ਡਾਟਾ ਦੇ ਪ੍ਰਬੰਧਨ, ਸਟੋਰੇਜ ਅਤੇ ਸੁਰੱਖਿਆ 'ਤੇ ਧਿਆਨ ਕੇਂਦਰਿਤ ਕਰਦੀ ਹੈ ਅਤੇ ਇਸਨੂੰ ਪ੍ਰੋਜੈਕਟ ਦੀ ਪੂਰੀ ਮਿਆਦ ਵਿੱਚ ਧਿਆਨ ਵਿੱਚ ਰੱਖਣਾ ਚਾਹੀਦਾ ਹੈ।
ਡਾਟਾ ਸਟੋਰੇਜ
ਡਾਟਾ ਕਿਵੇਂ ਅਤੇ ਕਿੱਥੇ ਸਟੋਰ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਇਸ ਦੇ ਖਰਚੇ ਅਤੇ ਡਾਟਾ ਤਕ ਪਹੁੰਚਣ ਦੀ ਗਤੀ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰ ਸਕਦਾ ਹੈ। ਇਸ ਤਰ੍ਹਾਂ ਦੇ ਫੈਸਲੇ ਸਿਰਫ਼ ਡਾਟਾ ਸਾਇੰਟਿਸਟ ਦੁਆਰਾ ਨਹੀਂ ਕੀਤੇ ਜਾਂਦੇ, ਪਰ ਉਹ ਡਾਟਾ ਸਟੋਰੇਜ ਦੇ ਅਧਾਰ 'ਤੇ ਡਾਟਾ ਨਾਲ ਕੰਮ ਕਰਨ ਦੇ ਤਰੀਕੇ 'ਤੇ ਚੋਣਾਂ ਕਰਨ ਦੀ ਸਥਿਤੀ ਵਿੱਚ ਹੋ ਸਕਦੇ ਹਨ।
ਆਧੁਨਿਕ ਡਾਟਾ ਸਟੋਰੇਜ ਸਿਸਟਮ ਦੇ ਕੁਝ ਪਹਲੂ ਜੋ ਇਹ ਚੋਣਾਂ ਪ੍ਰਭਾਵਿਤ ਕਰ ਸਕਦੇ ਹਨ:
ਆਨ-ਪ੍ਰੇਮਿਸ ਵਿਰੁੱਧ ਆਫ-ਪ੍ਰੇਮਿਸ ਵਿਰੁੱਧ ਪਬਲਿਕ ਜਾਂ ਪ੍ਰਾਈਵੇਟ ਕਲਾਉਡ
ਆਨ-ਪ੍ਰੇਮਿਸ ਦਾ ਮਤਲਬ ਹੈ ਆਪਣੇ ਸਾਜੋ-ਸਮਾਨ 'ਤੇ ਡਾਟਾ ਦੀ ਹੋਸਟਿੰਗ ਅਤੇ ਪ੍ਰਬੰਧਨ ਕਰਨਾ, ਜਿਵੇਂ ਕਿ ਸੇਰਵਰ ਦਾ ਮਾਲਕ ਹੋਣਾ ਜਿਸ ਵਿੱਚ ਡਾਟਾ ਸਟੋਰ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਜਦਕਿ ਆਫ-ਪ੍ਰੇਮਿਸ ਉਹ ਸਾਜੋ-ਸਮਾਨ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ ਜੋ ਤੁਸੀਂ ਮਾਲਕ ਨਹੀਂ ਹੋ। ਪਬਲਿਕ ਕਲਾਉਡ ਡਾਟਾ ਸਟੋਰ ਕਰਨ ਲਈ ਇੱਕ ਲੋਕਪ੍ਰਿਯ ਚੋਣ ਹੈ ਜਿਸ ਵਿੱਚ ਇਹ ਜਾਣਨ ਦੀ ਲੋੜ ਨਹੀਂ ਹੁੰਦੀ ਕਿ ਡਾਟਾ ਕਿਵੇਂ ਜਾਂ ਕਿੱਥੇ ਸਟੋਰ ਕੀਤਾ ਗਿਆ ਹੈ। ਕੁਝ ਸੰਗਠਨਾਂ ਦੀਆਂ ਸੁਰੱਖਿਆ ਨੀਤੀਆਂ ਸਖ਼ਤ ਹੁੰਦੀਆਂ ਹਨ ਜੋ ਇਹ ਯਕੀਨੀ ਬਣਾਉਂਦੀਆਂ ਹਨ ਕਿ ਉਹ ਸਾਜੋ-ਸਮਾਨ ਤਕ ਪੂਰੀ ਪਹੁੰਚ ਰੱਖਦੇ ਹਨ ਜਿੱਥੇ ਡਾਟਾ ਹੋਸਟ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਅਤੇ ਉਹ ਪ੍ਰਾਈਵੇਟ ਕਲਾਉਡ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹਨ ਜੋ ਆਪਣੀਆਂ ਕਲਾਉਡ ਸੇਵਾਵਾਂ ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ। ਤੁਸੀਂ ਕਲਾਉਡ ਵਿੱਚ ਡਾਟਾ ਬਾਰੇ ਹੋਰ ਜਾਣਕਾਰੀ ਅਗਲੇ ਪਾਠਾਂ ਵਿੱਚ ਸਿੱਖੋਗੇ।
ਕੋਲਡ ਵਿਰੁੱਧ ਹਾਟ ਡਾਟਾ
ਜਦੋਂ ਤੁਸੀਂ ਆਪਣੇ ਮਾਡਲਾਂ ਨੂੰ ਟ੍ਰੇਨ ਕਰ ਰਹੇ ਹੋ, ਤੁਹਾਨੂੰ ਵਧੇਰੇ ਟ੍ਰੇਨਿੰਗ ਡਾਟਾ ਦੀ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ। ਜੇਕਰ ਤੁਸੀਂ ਆਪਣੇ ਮਾਡਲ ਨਾਲ ਸੰਤੁਸ਼ਟ ਹੋ, ਵਧੇਰੇ ਡਾਟਾ ਮਾਡਲ ਨੂੰ ਇਸਦੇ ਉਦੇਸ਼ ਦੀ ਸੇਵਾ ਕਰਨ ਲਈ ਆਵੇਗਾ। ਕਿਸੇ ਵੀ ਮਾਮਲੇ ਵਿੱਚ, ਜਿਵੇਂ ਤੁਸੀਂ ਵਧੇਰੇ ਡਾਟਾ ਇਕੱਠਾ ਕਰਦੇ ਹੋ, ਡਾਟਾ ਸਟੋਰ ਕਰਨ ਅਤੇ ਇਸ ਤਕ ਪਹੁੰਚਣ ਦੀ ਲਾਗਤ ਵਧੇਗੀ। ਕਦੇ-ਕਦੇ ਵਰਤੇ ਜਾਣ ਵਾਲੇ ਡਾਟਾ, ਜਿਸਨੂੰ ਕੋਲਡ ਡਾਟਾ ਕਿਹਾ ਜਾਂਦਾ ਹੈ, ਨੂੰ ਅਕਸਰ ਵਰਤੇ ਜਾਣ ਵਾਲੇ ਹਾਟ ਡਾਟਾ ਤੋਂ ਵੱਖ ਕਰਨਾ ਇੱਕ ਸਸਤਾ ਡਾਟਾ ਸਟੋਰੇਜ ਵਿਕਲਪ ਹੋ ਸਕਦਾ ਹੈ। ਜੇਕਰ ਕੋਲਡ ਡਾਟਾ ਤਕ ਪਹੁੰਚਣ ਦੀ ਲੋੜ ਹੋਵੇ, ਤਾਂ ਇਸਨੂੰ ਹਾਟ ਡਾਟਾ ਦੇ ਮੁਕਾਬਲੇ ਕੁਝ ਜ਼ਿਆਦਾ ਸਮਾਂ ਲੱਗ ਸਕਦਾ ਹੈ।
ਡਾਟਾ ਦਾ ਪ੍ਰਬੰਧਨ
ਜਦੋਂ ਤੁਸੀਂ ਡਾਟਾ ਨਾਲ ਕੰਮ ਕਰਦੇ ਹੋ, ਤੁਸੀਂ ਪਤਾ ਲਗਾ ਸਕਦੇ ਹੋ ਕਿ ਕੁਝ ਡਾਟਾ ਨੂੰ ਸਾਫ਼ ਕਰਨ ਦੀ ਲੋੜ ਹੈ। ਇਹ ਤਕਨੀਕਾਂ ਡਾਟਾ ਤਿਆਰੀ 'ਤੇ ਧਿਆਨ ਕੇਂਦਰਿਤ ਪਾਠ ਵਿੱਚ ਕਵਰ ਕੀਤੀਆਂ ਗਈਆਂ ਹਨ। ਜਦੋਂ ਨਵਾਂ ਡਾਟਾ ਆਉਂਦਾ ਹੈ, ਇਸਨੂੰ ਗੁਣਵੱਤਾ ਵਿੱਚ ਸਥਿਰਤਾ ਨੂੰ ਬਣਾਈ ਰੱਖਣ ਲਈ ਉਹੀ ਤਕਨੀਕਾਂ ਦੀ ਲੋੜ ਹੋਵੇਗੀ। ਕੁਝ ਪ੍ਰੋਜੈਕਟਾਂ ਵਿੱਚ ਡਾਟਾ ਨੂੰ ਸਾਫ਼ ਕਰਨ, ਇਕੱਠਾ ਕਰਨ ਅਤੇ ਕੰਪ੍ਰੈਸ ਕਰਨ ਲਈ ਇੱਕ ਆਟੋਮੈਟਿਕ ਟੂਲ ਦੀ ਵਰਤੋਂ ਸ਼ਾਮਲ ਹੋਵੇਗੀ। Azure Data Factory ਇਸ ਤਰ੍ਹਾਂ ਦੇ ਟੂਲ ਦਾ ਇੱਕ ਉਦਾਹਰਨ ਹੈ।
ਡਾਟਾ ਦੀ ਸੁਰੱਖਿਆ
ਡਾਟਾ ਦੀ ਸੁਰੱਖਿਆ ਦਾ ਇੱਕ ਮੁੱਖ ਉਦੇਸ਼ ਇਹ ਯਕੀਨੀ ਬਣਾਉਣਾ ਹੈ ਕਿ ਜੋ ਇਸ ਨਾਲ ਕੰਮ ਕਰ ਰਹੇ ਹਨ ਉਹ ਇਸਨੂੰ ਕਿਵੇਂ ਇਕੱਠਾ ਕੀਤਾ ਗਿਆ ਹੈ ਅਤੇ ਕਿਹੜੇ ਸੰਦਰਭ ਵਿੱਚ ਇਸਨੂੰ ਵਰਤਿਆ ਜਾ ਰਿਹਾ ਹੈ, ਇਸ 'ਤੇ ਨਿਯੰਤਰਣ ਰੱਖਦੇ ਹਨ। ਡਾਟਾ ਨੂੰ ਸੁਰੱਖਿਅਤ ਰੱਖਣ ਵਿੱਚ ਸਿਰਫ਼ ਉਹਨਾਂ ਨੂੰ ਪਹੁੰਚ ਦੇਣਾ ਸ਼ਾਮਲ ਹੈ ਜਿਨ੍ਹਾਂ ਨੂੰ ਇਸ ਦੀ ਲੋੜ ਹੈ, ਸਥਾਨਕ ਕਾਨੂੰਨਾਂ ਅਤੇ ਨਿਯਮਾਂ ਦੀ ਪਾਲਣਾ ਕਰਨਾ, ਅਤੇ ਨੈਤਿਕ ਮਿਆਰਾਂ ਨੂੰ ਬਣਾਈ ਰੱਖਣਾ। ਇਹ ਨੈਤਿਕਤਾ ਪਾਠ ਵਿੱਚ ਕਵਰ ਕੀਤਾ ਗਿਆ ਹੈ।
ਇਹ ਕੁਝ ਚੀਜ਼ਾਂ ਹਨ ਜੋ ਸੁਰੱਖਿਆ ਨੂੰ ਧਿਆਨ ਵਿੱਚ ਰੱਖਦੇ ਹੋਏ ਟੀਮ ਕਰ ਸਕਦੀ ਹੈ:
- ਯਕੀਨੀ ਬਣਾਓ ਕਿ ਸਾਰਾ ਡਾਟਾ ਇਨਕ੍ਰਿਪਟ ਕੀਤਾ ਗਿਆ ਹੈ
- ਗਾਹਕਾਂ ਨੂੰ ਇਹ ਜਾਣਕਾਰੀ ਪ੍ਰਦਾਨ ਕਰੋ ਕਿ ਉਹਨਾਂ ਦਾ ਡਾਟਾ ਕਿਵੇਂ ਵਰਤਿਆ ਜਾ ਰਿਹਾ ਹੈ
- ਉਹਨਾਂ ਤੋਂ ਡਾਟਾ ਤੱਕ ਪਹੁੰਚ ਹਟਾਓ ਜੋ ਪ੍ਰੋਜੈਕਟ ਨੂੰ ਛੱਡ ਚੁੱਕੇ ਹਨ
- ਸਿਰਫ਼ ਕੁਝ ਪ੍ਰੋਜੈਕਟ ਮੈਂਬਰਾਂ ਨੂੰ ਡਾਟਾ ਨੂੰ ਬਦਲਣ ਦੀ ਇਜਾਜ਼ਤ ਦਿਓ
🚀 ਚੁਣੌਤੀ
ਡਾਟਾ ਸਾਇੰਸ ਲਾਈਫਸਾਈਕਲ ਦੇ ਕਈ ਵਰਜਨ ਹਨ, ਜਿੱਥੇ ਹਰ ਕਦਮ ਦੇ ਵੱਖ-ਵੱਖ ਨਾਮ ਅਤੇ ਚਰਨਾਂ ਦੀ ਗਿਣਤੀ ਹੋ ਸਕਦੀ ਹੈ ਪਰ ਇਸ ਪਾਠ ਵਿੱਚ ਉਲਲੇਖ ਕੀਤੇ ਪ੍ਰਕਿਰਿਆਵਾਂ ਨੂੰ ਸ਼ਾਮਲ ਕਰਦੇ ਹਨ।
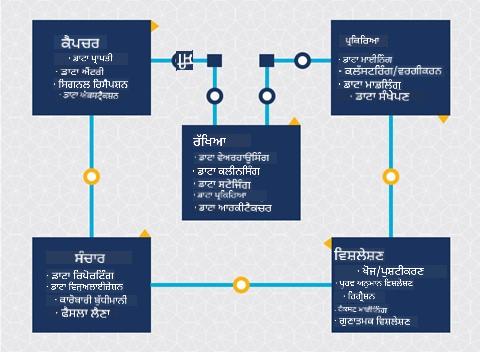
Team Data Science Process lifecycle ਅਤੇ Cross-industry standard process for data mining ਦੀ ਖੋਜ ਕਰੋ। ਦੋਹਾਂ ਵਿੱਚੋਂ 3 ਸਮਾਨਤਾਵਾਂ ਅਤੇ ਵੱਖ-ਵੱਖਤਾ ਦਾ ਨਾਮ ਦਿਓ।
| Team Data Science Process (TDSP) | Cross-industry standard process for data mining (CRISP-DM) |
|---|---|
 |
 |
| Microsoft ਦੁਆਰਾ ਚਿੱਤਰ | Data Science Process Alliance ਦੁਆਰਾ ਚਿੱਤਰ |
ਪੋਸਟ-ਲੈਕਚਰ ਕਵਿਜ਼
ਸਮੀਖਿਆ ਅਤੇ ਸਵੈ ਅਧਿਐਨ
ਡਾਟਾ ਸਾਇੰਸ ਲਾਈਫਸਾਈਕਲ ਨੂੰ ਲਾਗੂ ਕਰਨ ਵਿੱਚ ਕਈ ਭੂਮਿਕਾਵਾਂ ਅਤੇ ਕੰਮ ਸ਼ਾਮਲ ਹੁੰਦੇ ਹਨ, ਜਿੱਥੇ ਕੁਝ ਹਰ ਚਰਨ ਦੇ ਵਿਸ਼ੇਸ਼ ਹਿੱਸਿਆਂ 'ਤੇ ਧਿਆਨ ਕੇਂਦਰਿਤ ਕਰਦੇ ਹਨ। Team Data Science Process ਕੁਝ ਸਰੋਤ ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ ਜੋ ਇਹ ਸਮਝਾਉਂਦੇ ਹਨ ਕਿ ਕਿਸੇ ਪ੍ਰੋਜੈਕਟ ਵਿੱਚ ਕਿਸੇ ਵਿਅਕਤੀ ਦੀਆਂ ਭੂਮਿਕਾਵਾਂ ਅਤੇ ਕੰਮ ਕੀ ਹੋ ਸਕਦੇ ਹਨ।
- Team Data Science Process roles and tasks
- Execute data science tasks: exploration, modeling, and deployment
ਅਸਾਈਨਮੈਂਟ
ਅਸਵੀਕਰਤੀ:
ਇਹ ਦਸਤਾਵੇਜ਼ AI ਅਨੁਵਾਦ ਸੇਵਾ Co-op Translator ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਅਨੁਵਾਦ ਕੀਤਾ ਗਿਆ ਹੈ। ਜਦੋਂ ਕਿ ਅਸੀਂ ਸਹੀਤਾ ਲਈ ਯਤਨਸ਼ੀਲ ਹਾਂ, ਕਿਰਪਾ ਕਰਕੇ ਧਿਆਨ ਦਿਓ ਕਿ ਸਵੈਚਾਲਿਤ ਅਨੁਵਾਦਾਂ ਵਿੱਚ ਗਲਤੀਆਂ ਜਾਂ ਅਸੁਚੀਤਤਾਵਾਂ ਹੋ ਸਕਦੀਆਂ ਹਨ। ਮੂਲ ਦਸਤਾਵੇਜ਼ ਨੂੰ ਇਸਦੀ ਮੂਲ ਭਾਸ਼ਾ ਵਿੱਚ ਅਧਿਕਾਰਤ ਸਰੋਤ ਮੰਨਿਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ। ਮਹੱਤਵਪੂਰਨ ਜਾਣਕਾਰੀ ਲਈ, ਪੇਸ਼ੇਵਰ ਮਨੁੱਖੀ ਅਨੁਵਾਦ ਦੀ ਸਿਫਾਰਸ਼ ਕੀਤੀ ਜਾਂਦੀ ਹੈ। ਇਸ ਅਨੁਵਾਦ ਦੀ ਵਰਤੋਂ ਤੋਂ ਪੈਦਾ ਹੋਣ ਵਾਲੇ ਕਿਸੇ ਵੀ ਗਲਤ ਫਹਿਮੀ ਜਾਂ ਗਲਤ ਵਿਆਖਿਆ ਲਈ ਅਸੀਂ ਜ਼ਿੰਮੇਵਾਰ ਨਹੀਂ ਹਾਂ।