|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Arbeide med Data: Python og Pandas-biblioteket
 |
|---|
| Arbeide med Python - Sketchnote av @nitya |

Mens databaser tilbyr svært effektive måter å lagre data og hente dem ved hjelp av spørringsspråk, er den mest fleksible måten å behandle data på å skrive ditt eget program for å manipulere data. I mange tilfeller vil en databasespørring være en mer effektiv løsning. Men i noen tilfeller, når mer kompleks databehandling er nødvendig, kan det ikke enkelt gjøres med SQL.
Databehandling kan programmeres i hvilket som helst programmeringsspråk, men det finnes visse språk som er mer høy-nivå når det gjelder arbeid med data. Dataforskere foretrekker vanligvis ett av følgende språk:
- Python, et allsidig programmeringsspråk, som ofte anses som et av de beste alternativene for nybegynnere på grunn av sin enkelhet. Python har mange tilleggslibraries som kan hjelpe deg med å løse praktiske problemer, som å hente data fra en ZIP-arkiv eller konvertere et bilde til gråtoner. I tillegg til dataforskning brukes Python også ofte til webutvikling.
- R er en tradisjonell verktøykasse utviklet med statistisk databehandling i tankene. Den inneholder også et stort biblioteklager (CRAN), som gjør det til et godt valg for databehandling. R er imidlertid ikke et allsidig programmeringsspråk og brukes sjelden utenfor dataforskningsområdet.
- Julia er et annet språk utviklet spesielt for dataforskning. Det er ment å gi bedre ytelse enn Python, noe som gjør det til et flott verktøy for vitenskapelige eksperimenter.
I denne leksjonen vil vi fokusere på å bruke Python for enkel databehandling. Vi antar grunnleggende kjennskap til språket. Hvis du ønsker en dypere innføring i Python, kan du se på en av følgende ressurser:
- Lær Python på en morsom måte med Turtle Graphics og Fractals - GitHub-basert introduksjonskurs i Python-programmering
- Ta dine første steg med Python Læringssti på Microsoft Learn
Data kan komme i mange former. I denne leksjonen vil vi se på tre former for data - tabulære data, tekst og bilder.
Vi vil fokusere på noen få eksempler på databehandling, i stedet for å gi deg en full oversikt over alle relaterte biblioteker. Dette vil gi deg en idé om hva som er mulig, og gi deg forståelse for hvor du kan finne løsninger på dine problemer når du trenger dem.
Det mest nyttige rådet. Når du trenger å utføre en bestemt operasjon på data som du ikke vet hvordan du skal gjøre, prøv å søke etter det på internett. Stackoverflow inneholder ofte mange nyttige kodeeksempler i Python for mange typiske oppgaver.
Quiz før leksjonen
Tabulære data og Dataframes
Du har allerede møtt tabulære data da vi snakket om relasjonsdatabaser. Når du har mye data, og det er lagret i mange forskjellige koblede tabeller, gir det definitivt mening å bruke SQL for å arbeide med det. Men det finnes mange tilfeller der vi har en tabell med data, og vi trenger å få en forståelse eller innsikt om disse dataene, som fordeling, korrelasjon mellom verdier, osv. I dataforskning er det mange tilfeller der vi trenger å utføre noen transformasjoner av de opprinnelige dataene, etterfulgt av visualisering. Begge disse trinnene kan enkelt gjøres med Python.
Det finnes to mest nyttige biblioteker i Python som kan hjelpe deg med å arbeide med tabulære data:
- Pandas lar deg manipulere såkalte Dataframes, som er analoge med relasjonstabeller. Du kan ha navngitte kolonner og utføre forskjellige operasjoner på rader, kolonner og dataframes generelt.
- Numpy er et bibliotek for å arbeide med tensore, dvs. flerdimensjonale arrays. Arrays har verdier av samme underliggende type, og det er enklere enn dataframe, men det tilbyr flere matematiske operasjoner og skaper mindre overhead.
Det finnes også et par andre biblioteker du bør kjenne til:
- Matplotlib er et bibliotek som brukes til datavisualisering og graftegning
- SciPy er et bibliotek med noen ekstra vitenskapelige funksjoner. Vi har allerede kommet over dette biblioteket da vi snakket om sannsynlighet og statistikk
Her er et stykke kode som du vanligvis vil bruke for å importere disse bibliotekene i begynnelsen av Python-programmet ditt:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas er sentrert rundt noen få grunnleggende konsepter.
Series
Series er en sekvens av verdier, lik en liste eller numpy-array. Den største forskjellen er at series også har en indeks, og når vi opererer på series (f.eks. legger dem sammen), tas indeksen med i betraktning. Indeksen kan være så enkel som et heltall radnummer (det er indeksen som brukes som standard når du oppretter en series fra en liste eller array), eller den kan ha en kompleks struktur, som et datointervall.
Merk: Det finnes noe innledende Pandas-kode i den medfølgende notebooken
notebook.ipynb. Vi skisserer bare noen av eksemplene her, og du er definitivt velkommen til å sjekke ut hele notebooken.
Tenk på et eksempel: vi ønsker å analysere salget fra vår iskrembutikk. La oss generere en series med salgsnumre (antall solgte varer hver dag) for en tidsperiode:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
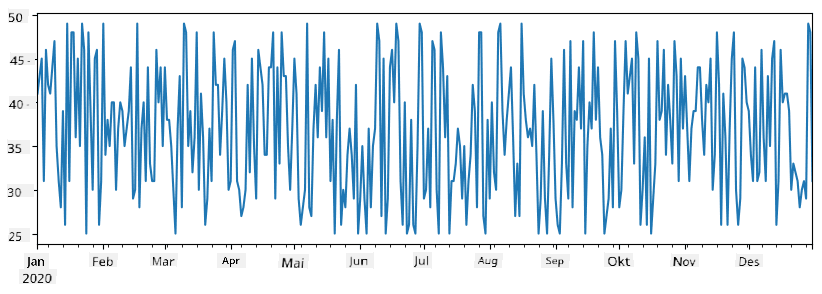
Nå antar vi at vi hver uke arrangerer en fest for venner, og vi tar med oss 10 ekstra pakker med iskrem til festen. Vi kan lage en annen series, indeksert etter uke, for å demonstrere dette:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
Når vi legger sammen to series, får vi totalt antall:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
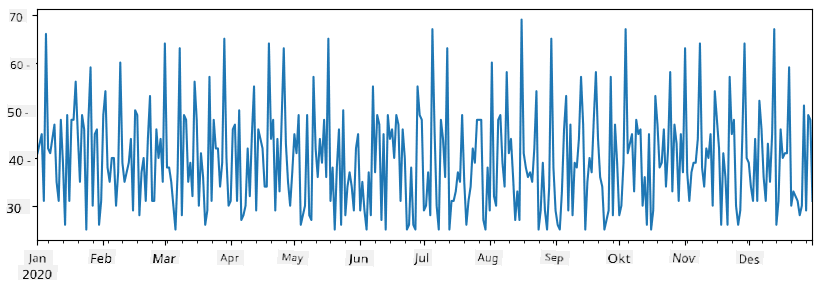
Merk at vi ikke bruker enkel syntaks
total_items+additional_items. Hvis vi gjorde det, ville vi fått mangeNaN(Not a Number) verdier i den resulterende series. Dette er fordi det mangler verdier for noen av indeksene iadditional_items-serien, og å legge tilNaNtil noe resulterer iNaN. Derfor må vi spesifiserefill_value-parameteren under addisjonen.
Med tidsserier kan vi også resample serien med forskjellige tidsintervaller. For eksempel, hvis vi ønsker å beregne gjennomsnittlig salgsvolum månedlig, kan vi bruke følgende kode:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
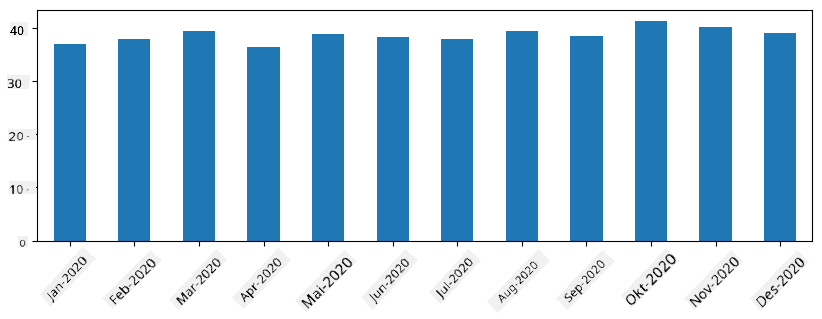
DataFrame
En DataFrame er i hovedsak en samling av series med samme indeks. Vi kan kombinere flere series sammen til en DataFrame:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
Dette vil lage en horisontal tabell som denne:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
Vi kan også bruke Series som kolonner og spesifisere kolonnenavn ved hjelp av en ordbok:
df = pd.DataFrame({ 'A' : a, 'B' : b })
Dette vil gi oss en tabell som denne:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
Merk at vi også kan få denne tabelloppsettet ved å transponere den forrige tabellen, f.eks. ved å skrive
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
Her betyr .T operasjonen med å transponere DataFrame, dvs. bytte rader og kolonner, og rename-operasjonen lar oss gi nytt navn til kolonner for å matche det forrige eksemplet.
Her er noen av de viktigste operasjonene vi kan utføre på DataFrames:
Kolonnevalg. Vi kan velge individuelle kolonner ved å skrive df['A'] - denne operasjonen returnerer en Series. Vi kan også velge et delsett av kolonner til en annen DataFrame ved å skrive df[['B','A']] - dette returnerer en annen DataFrame.
Filtrering av kun visse rader basert på kriterier. For eksempel, for å beholde kun rader med kolonne A større enn 5, kan vi skrive df[df['A']>5].
Merk: Måten filtrering fungerer på er som følger. Uttrykket
df['A']<5returnerer en boolsk series, som indikerer om uttrykket erTrueellerFalsefor hvert element i den opprinnelige seriendf['A']. Når boolsk series brukes som indeks, returnerer det et delsett av rader i DataFrame. Dermed er det ikke mulig å bruke vilkårlige Python boolske uttrykk, for eksempel, å skrivedf[df['A']>5 and df['A']<7]ville være feil. I stedet bør du bruke spesialoperasjonen&på boolske serier, ved å skrivedf[(df['A']>5) & (df['A']<7)](parentesene er viktige her).
Opprette nye beregnbare kolonner. Vi kan enkelt opprette nye beregnbare kolonner for vår DataFrame ved å bruke intuitive uttrykk som dette:
df['DivA'] = df['A']-df['A'].mean()
Dette eksemplet beregner avviket til A fra gjennomsnittsverdien. Det som faktisk skjer her er at vi beregner en series og deretter tilordner denne serien til venstre side, og oppretter en ny kolonne. Dermed kan vi ikke bruke operasjoner som ikke er kompatible med series, for eksempel, koden nedenfor er feil:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
Det siste eksemplet, selv om det er syntaktisk korrekt, gir oss feil resultat, fordi det tilordner lengden på serien B til alle verdier i kolonnen, og ikke lengden på individuelle elementer som vi hadde tenkt.
Hvis vi trenger å beregne komplekse uttrykk som dette, kan vi bruke apply-funksjonen. Det siste eksemplet kan skrives som følger:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
Etter operasjonene ovenfor vil vi ende opp med følgende DataFrame:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
Velge rader basert på tall kan gjøres ved hjelp av iloc-konstruksjonen. For eksempel, for å velge de første 5 radene fra DataFrame:
df.iloc[:5]
Gruppering brukes ofte for å få et resultat som ligner på pivot-tabeller i Excel. Anta at vi ønsker å beregne gjennomsnittsverdien av kolonnen A for hver gitt verdi av LenB. Da kan vi gruppere vår DataFrame etter LenB og kalle mean:
df.groupby(by='LenB').mean()
Hvis vi trenger å beregne gjennomsnittet og antall elementer i gruppen, kan vi bruke den mer komplekse aggregate-funksjonen:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
Dette gir oss følgende tabell:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
Hente Data
Vi har sett hvor enkelt det er å konstruere Series og DataFrames fra Python-objekter. Men data kommer vanligvis i form av en tekstfil eller en Excel-tabell. Heldigvis tilbyr Pandas oss en enkel måte å laste inn data fra disk. For eksempel, å lese en CSV-fil er så enkelt som dette:
df = pd.read_csv('file.csv')
Vi vil se flere eksempler på å laste inn data, inkludert å hente det fra eksterne nettsteder, i "Utfordring"-seksjonen.
Utskrift og Visualisering
En Data Scientist må ofte utforske dataene, og det er derfor viktig å kunne visualisere dem. Når en DataFrame er stor, ønsker vi ofte bare å forsikre oss om at vi gjør alt riktig ved å skrive ut de første radene. Dette kan gjøres ved å kalle df.head(). Hvis du kjører det fra Jupyter Notebook, vil det skrive ut DataFrame i en fin tabellform.
Vi har også sett bruken av plot-funksjonen for å visualisere noen kolonner. Selv om plot er veldig nyttig for mange oppgaver og støtter mange forskjellige grafetyper via kind=-parameteren, kan du alltid bruke det rå matplotlib-biblioteket for å lage noe mer komplekst. Vi vil dekke datavisualisering i detalj i separate kursleksjoner.
Denne oversikten dekker de viktigste konseptene i Pandas, men biblioteket er veldig rikt, og det er ingen grenser for hva du kan gjøre med det! La oss nå bruke denne kunnskapen til å løse et spesifikt problem.
🚀 Utfordring 1: Analysere COVID-spredning
Det første problemet vi skal fokusere på er modellering av epidemisk spredning av COVID-19. For å gjøre dette, vil vi bruke data om antall smittede individer i forskjellige land, levert av Center for Systems Science and Engineering (CSSE) ved Johns Hopkins University. Datasettet er tilgjengelig i denne GitHub-repositorien.
Siden vi ønsker å demonstrere hvordan man håndterer data, inviterer vi deg til å åpne notebook-covidspread.ipynb og lese den fra topp til bunn. Du kan også kjøre cellene og gjøre noen utfordringer som vi har lagt igjen til deg på slutten.
Hvis du ikke vet hvordan du kjører kode i Jupyter Notebook, ta en titt på denne artikkelen.
Arbeide med Ustrukturert Data
Selv om data ofte kommer i tabellform, må vi i noen tilfeller håndtere mindre strukturert data, for eksempel tekst eller bilder. I slike tilfeller, for å bruke databehandlingsteknikker vi har sett ovenfor, må vi på en eller annen måte ekstrahere strukturert data. Her er noen eksempler:
- Ekstrahere nøkkelord fra tekst og se hvor ofte disse nøkkelordene vises
- Bruke nevrale nettverk for å hente informasjon om objekter på et bilde
- Få informasjon om følelsene til mennesker på videokamera-feed
🚀 Utfordring 2: Analysere COVID-artikler
I denne utfordringen fortsetter vi med temaet COVID-pandemien og fokuserer på behandling av vitenskapelige artikler om emnet. Det finnes CORD-19-datasettet med mer enn 7000 (på tidspunktet for skriving) artikler om COVID, tilgjengelig med metadata og sammendrag (og for omtrent halvparten av dem er også fulltekst tilgjengelig).
Et fullstendig eksempel på analyse av dette datasettet ved hjelp av Text Analytics for Health kognitive tjeneste er beskrevet i denne bloggposten. Vi vil diskutere en forenklet versjon av denne analysen.
NOTE: Vi gir ikke en kopi av datasettet som en del av denne repositorien. Du må kanskje først laste ned
metadata.csv-filen fra dette datasettet på Kaggle. Registrering hos Kaggle kan være nødvendig. Du kan også laste ned datasettet uten registrering herfra, men det vil inkludere alle fulltekster i tillegg til metadatafilen.
Åpne notebook-papers.ipynb og les den fra topp til bunn. Du kan også kjøre cellene og gjøre noen utfordringer som vi har lagt igjen til deg på slutten.
Behandling av Bildedata
Nylig har svært kraftige AI-modeller blitt utviklet som lar oss forstå bilder. Det finnes mange oppgaver som kan løses ved hjelp av forhåndstrente nevrale nettverk eller skytjenester. Noen eksempler inkluderer:
- Bildeklassifisering, som kan hjelpe deg med å kategorisere bildet i en av de forhåndsdefinerte klassene. Du kan enkelt trene dine egne bildeklassifiserere ved hjelp av tjenester som Custom Vision
- Objektdeteksjon for å oppdage forskjellige objekter i bildet. Tjenester som computer vision kan oppdage en rekke vanlige objekter, og du kan trene Custom Vision-modellen til å oppdage spesifikke objekter av interesse.
- Ansiktsdeteksjon, inkludert alder, kjønn og følelsesdeteksjon. Dette kan gjøres via Face API.
Alle disse skytjenestene kan kalles ved hjelp av Python SDKs, og kan derfor enkelt integreres i din datautforskningsarbeidsflyt.
Her er noen eksempler på utforsking av data fra bildedatakilder:
- I bloggposten Hvordan lære datavitenskap uten koding utforsker vi Instagram-bilder, og prøver å forstå hva som får folk til å gi flere likes til et bilde. Vi ekstraherer først så mye informasjon fra bilder som mulig ved hjelp av computer vision, og bruker deretter Azure Machine Learning AutoML for å bygge en tolkbar modell.
- I Facial Studies Workshop bruker vi Face API for å ekstrahere følelser hos mennesker på fotografier fra arrangementer, for å prøve å forstå hva som gjør folk glade.
Konklusjon
Enten du allerede har strukturert eller ustrukturert data, kan du med Python utføre alle trinn relatert til databehandling og forståelse. Det er sannsynligvis den mest fleksible måten å behandle data på, og det er grunnen til at flertallet av dataforskere bruker Python som sitt primære verktøy. Å lære Python i dybden er sannsynligvis en god idé hvis du er seriøs med din datavitenskapsreise!
Quiz etter forelesning
Gjennomgang og Selvstudium
Bøker
Nettressurser
- Offisiell 10 minutter til Pandas-veiledning
- Dokumentasjon om Pandas-visualisering
Lære Python
- Lær Python på en morsom måte med Turtle Graphics og Fractals
- Ta dine første steg med Python Læringssti på Microsoft Learn
Oppgave
Utfør en mer detaljert datastudie for utfordringene ovenfor
Kreditering
Denne leksjonen er skrevet med ♥️ av Dmitry Soshnikov
Ansvarsfraskrivelse:
Dette dokumentet er oversatt ved hjelp av AI-oversettelsestjenesten Co-op Translator. Selv om vi tilstreber nøyaktighet, vennligst vær oppmerksom på at automatiserte oversettelser kan inneholde feil eller unøyaktigheter. Det originale dokumentet på sitt opprinnelige språk bør betraktes som den autoritative kilden. For kritisk informasjon anbefales profesjonell menneskelig oversettelse. Vi er ikke ansvarlige for eventuelle misforståelser eller feiltolkninger som oppstår ved bruk av denne oversettelsen.