|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| 17-Introduction | 3 weeks ago | |
| 18-Low-Code | 3 weeks ago | |
| 19-Azure | 3 weeks ago | |
| README.md | 3 weeks ago | |
README.md
क्लाउडमधील डेटा सायन्स

फोटो Jelleke Vanooteghem यांनी Unsplash वरून घेतला आहे
मोठ्या डेटासह डेटा सायन्स करताना, क्लाउड एक गेम चेंजर ठरू शकतो. पुढील तीन धड्यांमध्ये, आपण क्लाउड म्हणजे काय आणि ते कसे उपयुक्त ठरू शकते हे पाहणार आहोत. तसेच, आपण हृदय विकाराचा डेटा सेट एक्सप्लोर करणार आहोत आणि कोणाला हृदय विकार होण्याची शक्यता किती आहे हे ठरवण्यासाठी एक मॉडेल तयार करणार आहोत. क्लाउडची ताकद वापरून आपण मॉडेल ट्रेन, डिप्लॉय आणि दोन वेगवेगळ्या पद्धतींनी वापरणार आहोत. एक पद्धत फक्त यूजर इंटरफेस वापरून Low code/No code प्रकारात, आणि दुसरी पद्धत Azure Machine Learning Software Developer Kit (Azure ML SDK) वापरून.
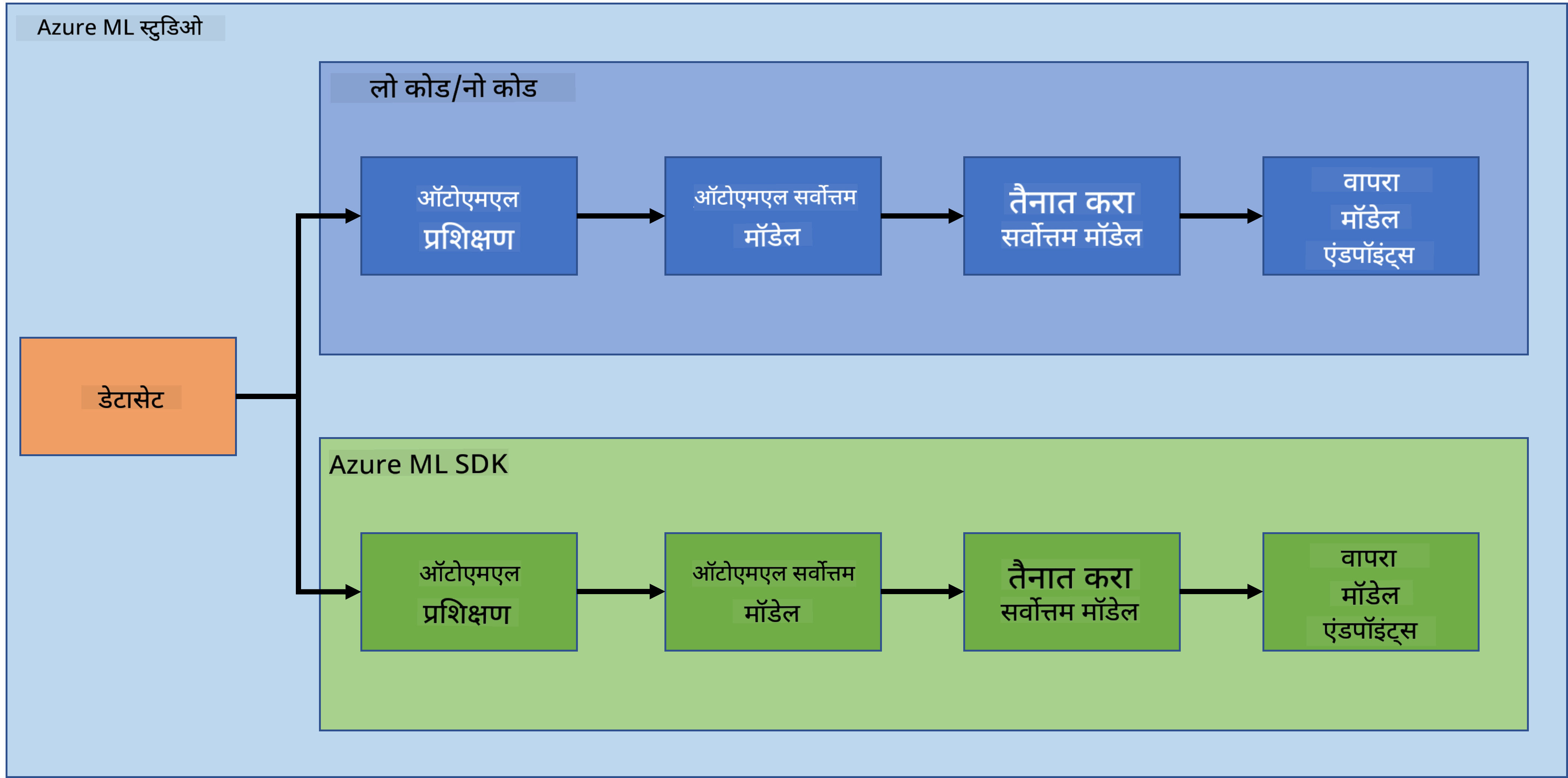
विषय
- डेटा सायन्ससाठी क्लाउड का वापरावे?
- क्लाउडमधील डेटा सायन्स: "Low code/No code" पद्धत
- क्लाउडमधील डेटा सायन्स: "Azure ML SDK" पद्धत
श्रेय
हे धडे ☁️ आणि 💕 सह Maud Levy आणि Tiffany Souterre यांनी लिहिले आहेत.
हृदय विकार प्रेडिक्शन प्रोजेक्टसाठी डेटा Larxel कडून Kaggle वरून घेतला आहे. हा डेटा Attribution 4.0 International (CC BY 4.0) अंतर्गत परवानाधीन आहे.
अस्वीकरण:
हा दस्तऐवज AI भाषांतर सेवा Co-op Translator वापरून भाषांतरित करण्यात आला आहे. आम्ही अचूकतेसाठी प्रयत्नशील असलो तरी कृपया लक्षात ठेवा की स्वयंचलित भाषांतरांमध्ये त्रुटी किंवा अचूकतेचा अभाव असू शकतो. मूळ भाषेतील दस्तऐवज हा अधिकृत स्रोत मानला जावा. महत्त्वाच्या माहितीसाठी व्यावसायिक मानवी भाषांतराची शिफारस केली जाते. या भाषांतराचा वापर करून निर्माण होणाऱ्या कोणत्याही गैरसमज किंवा चुकीच्या अर्थासाठी आम्ही जबाबदार राहणार नाही.