|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 3 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
Darbas su duomenimis: Python ir Pandas biblioteka
 |
|---|
| Darbas su Python - Sketchnote by @nitya |
Nors duomenų bazės siūlo labai efektyvius būdus saugoti duomenis ir užklausas vykdyti naudojant užklausų kalbas, lankstiausias būdas apdoroti duomenis yra rašyti savo programą, kuri manipuliuoja duomenimis. Daugeliu atvejų duomenų bazės užklausa būtų efektyvesnis sprendimas. Tačiau kai kuriais atvejais, kai reikalingas sudėtingesnis duomenų apdorojimas, tai negali būti lengvai atlikta naudojant SQL. Duomenų apdorojimas gali būti programuojamas bet kuria programavimo kalba, tačiau yra tam tikrų kalbų, kurios yra aukštesnio lygio dirbant su duomenimis. Duomenų mokslininkai dažniausiai renkasi vieną iš šių kalbų:
- Python – universali programavimo kalba, dažnai laikoma viena geriausių pasirinkimų pradedantiesiems dėl jos paprastumo. Python turi daugybę papildomų bibliotekų, kurios gali padėti išspręsti daugelį praktinių problemų, pvz., išgauti duomenis iš ZIP archyvo ar konvertuoti paveikslėlį į pilkąjį toną. Be duomenų mokslo, Python taip pat dažnai naudojama interneto svetainių kūrimui.
- R – tradicinė įrankių dėžė, sukurta statistinių duomenų apdorojimui. Ji taip pat turi didelį bibliotekų rinkinį (CRAN), todėl yra geras pasirinkimas duomenų apdorojimui. Tačiau R nėra universali programavimo kalba ir retai naudojama už duomenų mokslo ribų.
- Julia – kita kalba, sukurta specialiai duomenų mokslui. Ji siekia geresnio našumo nei Python, todėl yra puikus įrankis moksliniams eksperimentams.
Šioje pamokoje mes sutelksime dėmesį į Python naudojimą paprastam duomenų apdorojimui. Mes prielaida, kad turite pagrindines žinias apie šią kalbą. Jei norite giliau susipažinti su Python, galite pasinaudoti vienu iš šių šaltinių:
- Learn Python in a Fun Way with Turtle Graphics and Fractals – greitas Python programavimo kursas GitHub platformoje
- Take your First Steps with Python Mokymosi kelias Microsoft Learn
Duomenys gali būti įvairių formų. Šioje pamokoje mes apsvarstysime tris duomenų formas – lentelinius duomenis, tekstą ir vaizdus.
Mes sutelksime dėmesį į keletą duomenų apdorojimo pavyzdžių, o ne pateiksime visą susijusių bibliotekų apžvalgą. Tai leis jums suprasti pagrindinę idėją, kas yra įmanoma, ir paliks jus su žiniomis, kur rasti sprendimus savo problemoms, kai jų prireiks.
Naudingiausias patarimas. Kai reikia atlikti tam tikrą operaciją su duomenimis, kurios nežinote, kaip atlikti, pabandykite ieškoti informacijos internete. Stackoverflow dažnai turi daug naudingų Python kodo pavyzdžių daugeliui tipinių užduočių.
Prieš pamokos testas
Lenteliniai duomenys ir DataFrame
Jūs jau susipažinote su lenteliniais duomenimis, kai kalbėjome apie reliacines duomenų bazes. Kai turite daug duomenų, kurie yra saugomi skirtingose susietose lentelėse, tikrai verta naudoti SQL darbui su jais. Tačiau yra daug atvejų, kai turime vieną duomenų lentelę ir norime gauti tam tikrą supratimą ar įžvalgas apie šiuos duomenis, pvz., pasiskirstymą, vertybių koreliaciją ir pan. Duomenų moksle dažnai reikia atlikti tam tikras pradinio duomenų transformacijas, po kurių seka vizualizacija. Abi šios užduotys gali būti lengvai atliktos naudojant Python.
Yra dvi naudingiausios Python bibliotekos, kurios gali padėti dirbti su lenteliniais duomenimis:
- Pandas leidžia manipuliuoti vadinamaisiais DataFrame, kurie yra analogiški reliacinėms lentelėms. Galite turėti pavadintas stulpelius ir atlikti įvairias operacijas su eilutėmis, stulpeliais ir DataFrame apskritai.
- Numpy yra biblioteka, skirta dirbti su tensoriais, t. y. daugiamačiais masyvais. Masyvas turi vienodo tipo vertybes ir yra paprastesnis nei DataFrame, tačiau siūlo daugiau matematinių operacijų ir sukuria mažiau papildomų išteklių.
Taip pat yra keletas kitų bibliotekų, kurias verta žinoti:
- Matplotlib – biblioteka, naudojama duomenų vizualizacijai ir grafų braižymui
- SciPy – biblioteka su papildomomis mokslinėmis funkcijomis. Jau susidūrėme su šia biblioteka, kai kalbėjome apie tikimybes ir statistiką
Štai kodo fragmentas, kurį paprastai naudotumėte šių bibliotekų importavimui Python programos pradžioje:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas yra pagrįsta keliais pagrindiniais konceptais.
Series
Series yra vertybių seka, panaši į sąrašą arba numpy masyvą. Pagrindinis skirtumas yra tas, kad Series taip pat turi indeksą, ir kai atliekame operacijas su Series (pvz., sudedame jas), indeksas yra įtraukiamas į skaičiavimus. Indeksas gali būti toks paprastas kaip eilutės numeris (tai yra numatytasis indeksas, kai kuriame Series iš sąrašo ar masyvo), arba jis gali turėti sudėtingą struktūrą, pvz., datos intervalą.
Pastaba: Įvadinis Pandas kodas pateiktas pridedamame užrašų knygelėje
notebook.ipynb. Čia pateikiame tik keletą pavyzdžių, tačiau tikrai kviečiame peržiūrėti visą užrašų knygelę.
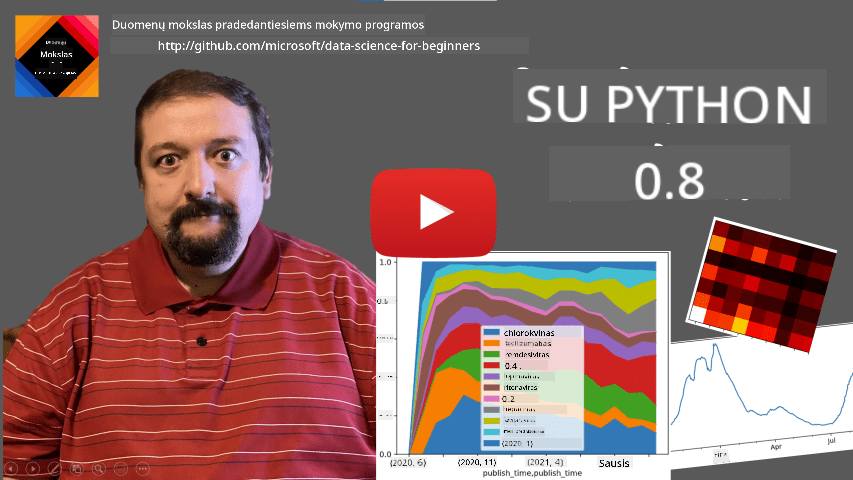
Pavyzdžiui, norime analizuoti mūsų ledų parduotuvės pardavimus. Sukurkime pardavimų skaičių seriją (kiekvieną dieną parduotų prekių skaičius) tam tikram laikotarpiui:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
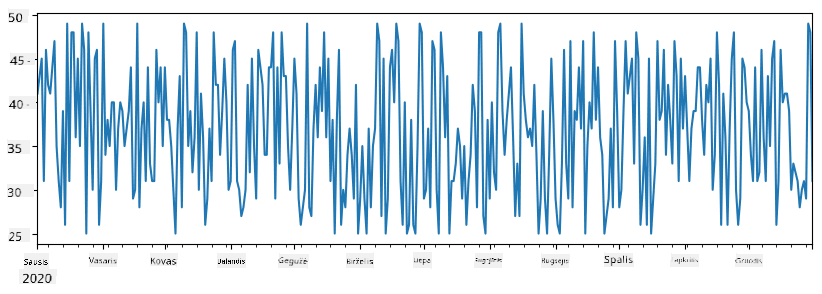
Dabar tarkime, kad kiekvieną savaitę organizuojame vakarėlį draugams ir pasiimame papildomus 10 ledų pakuočių vakarėliui. Galime sukurti kitą seriją, indeksuotą savaitėmis, kad tai parodytume:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
Kai sudedame dvi serijas, gauname bendrą skaičių:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
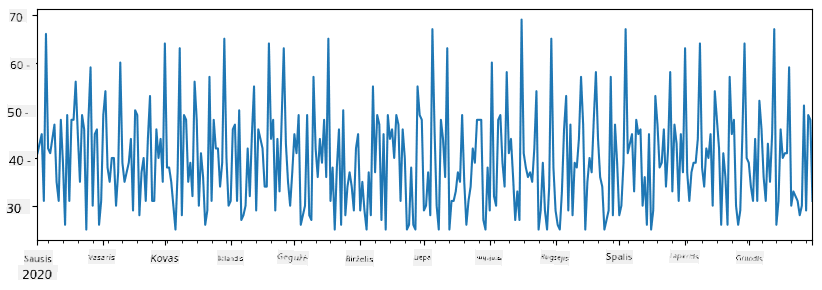
Pastaba: mes nenaudojame paprastos sintaksės
total_items+additional_items. Jei tai darytume, gautume daugNaN(Not a Number) reikšmių rezultato serijoje. Taip yra todėl, kad kai kurių indeksų taškų serijojeadditional_itemstrūksta reikšmių, o sudėjusNaNsu bet kuo gaunamasNaN. Todėl reikia nurodytifill_valueparametrą sudėties metu.
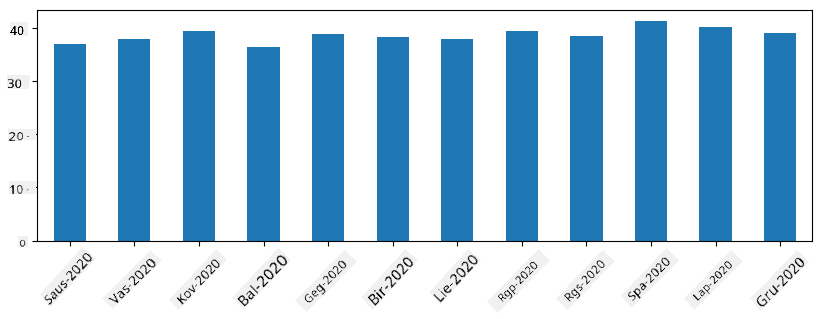
Su laiko serijomis taip pat galime perdaryti seriją su skirtingais laiko intervalais. Pavyzdžiui, jei norime apskaičiuoti vidutinį pardavimų kiekį mėnesiais, galime naudoti šį kodą:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
DataFrame
DataFrame iš esmės yra serijų kolekcija su tuo pačiu indeksu. Galime sujungti kelias serijas į vieną DataFrame:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
Tai sukurs horizontalią lentelę, panašią į šią:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
Taip pat galime naudoti Series kaip stulpelius ir nurodyti stulpelių pavadinimus naudodami žodyną:
df = pd.DataFrame({ 'A' : a, 'B' : b })
Tai suteiks mums lentelę, panašią į šią:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
Pastaba: taip pat galime gauti šį lentelės išdėstymą transponuodami ankstesnę lentelę, pvz., rašydami
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
Čia .T reiškia DataFrame transponavimo operaciją, t. y. eilučių ir stulpelių keitimą vietomis, o rename operacija leidžia pervadinti stulpelius, kad atitiktų ankstesnį pavyzdį.
Štai keletas svarbiausių operacijų, kurias galime atlikti su DataFrame:
Stulpelių pasirinkimas. Galime pasirinkti atskirus stulpelius rašydami df['A'] – ši operacija grąžina Series. Taip pat galime pasirinkti stulpelių pogrupį į kitą DataFrame rašydami df[['B','A']] – tai grąžina kitą DataFrame.
Filtravimas tik tam tikrų eilučių pagal kriterijus. Pavyzdžiui, norėdami palikti tik eilutes, kuriose stulpelis A yra didesnis nei 5, galime rašyti df[df['A']>5].
Pastaba: Filtravimas veikia taip. Išraiška
df['A']<5grąžina loginę seriją, kuri nurodo, ar išraiška yraTruearFalsekiekvienam pradiniam serijosdf['A']elementui. Kai loginė serija naudojama kaip indeksas, ji grąžina eilučių pogrupį DataFrame. Todėl negalima naudoti bet kokios Python loginės išraiškos, pvz., rašytidf[df['A']>5 and df['A']<7]būtų neteisinga. Vietoj to, turėtumėte naudoti specialią&operaciją loginėms serijoms, rašydamidf[(df['A']>5) & (df['A']<7)](skliaustai čia yra svarbūs).
Naujų skaičiuojamų stulpelių kūrimas. Galime lengvai sukurti naujus skaičiuojamus stulpelius savo DataFrame naudodami intuityvią išraišką, pvz.:
df['DivA'] = df['A']-df['A'].mean()
Šis pavyzdys apskaičiuoja A nukrypimą nuo jo vidutinės vertės. Kas iš tikrųjų vyksta, tai mes apskaičiuojame seriją ir tada priskiriame šią seriją kairiajai pusei, sukurdami naują stulpelį. Todėl negalime naudoti jokių operacijų, kurios nesuderinamos su serijomis, pvz., žemiau pateiktas kodas yra neteisingas:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
Pastarasis pavyzdys, nors sintaksiškai teisingas, duoda neteisingą rezultatą, nes priskiria serijos B ilgį visoms stulpelio reikšmėms, o ne atskirų elementų ilgį, kaip buvo numatyta.
Jei reikia apskaičiuoti sudėtingas išraiškas, galime naudoti apply funkciją. Paskutinis pavyzdys gali būti parašytas taip:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
Po aukščiau pateiktų operacijų turėsime tokį DataFrame:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
Eilučių pasirinkimas pagal numerius gali būti atliekamas naudojant iloc konstrukciją. Pavyzdžiui, norėdami pasirinkti pirmas 5 eilutes iš DataFrame:
df.iloc[:5]
Grupavimas dažnai naudojamas norint gauti rezultatą, panašų į pivot lenteles Excel programoje. Tarkime, kad norime apskaičiuoti vidutinę stulpelio A vertę kiekvienam LenB skaičiui. Tada galime grupuoti savo DataFrame pagal LenB ir iškviesti mean:
df.groupby(by='LenB').mean()
Jei reikia apskaičiuoti vidurkį ir elementų skaičių grupėje, galime naudoti sudėtingesnę aggregate funkciją:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
Tai suteikia mums tokią lentelę:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
Duomenų gavimas
Mes matėme, kaip lengva sukurti Series ir DataFrames iš Python objektų. Tačiau duomenys dažniausiai pateikiami kaip tekstinis failas arba Excel lentelė. Laimei, Pandas suteikia paprastą būdą įkelti duomenis iš disko. Pavyzdžiui, CSV failo skaitymas yra toks paprastas:
df = pd.read_csv('file.csv')
Daugiau pavyzdžių, kaip įkelti duomenis, įskaitant jų gavimą iš išorinių svetainių, pamatysime skyriuje „Iššūkis“.
Spausdinimas ir Vizualizacija
Duomenų mokslininkas dažnai turi tyrinėti duomenis, todėl svarbu mokėti juos vizualizuoti. Kai DataFrame yra didelis, dažnai norime tik įsitikinti, kad viską darome teisingai, išspausdindami pirmas kelias eilutes. Tai galima padaryti iškviečiant df.head(). Jei tai vykdote iš Jupyter Notebook, jis išspausdins DataFrame gražia lentelės forma.
Mes taip pat matėme, kaip naudoti plot funkciją tam tikrų stulpelių vizualizavimui. Nors plot yra labai naudinga daugeliui užduočių ir palaiko daugybę skirtingų grafiko tipų per kind= parametrą, visada galite naudoti žaliąją matplotlib biblioteką, kad nupieštumėte kažką sudėtingesnio. Duomenų vizualizaciją detaliai aptarsime atskirose kurso pamokose.
Ši apžvalga apima svarbiausias Pandas sąvokas, tačiau biblioteka yra labai turtinga, ir nėra ribų, ką su ja galite padaryti! Dabar pritaikykime šias žinias konkrečiai problemai spręsti.
🚀 Iššūkis 1: COVID plitimo analizė
Pirmoji problema, į kurią sutelksime dėmesį, yra COVID-19 epidemijos plitimo modeliavimas. Tam naudosime duomenis apie užsikrėtusių asmenų skaičių skirtingose šalyse, kuriuos pateikia Sistemų mokslo ir inžinerijos centras (CSSE) iš Johns Hopkins universiteto. Duomenų rinkinys yra pasiekiamas šiame GitHub saugykloje.
Kadangi norime parodyti, kaip dirbti su duomenimis, kviečiame atidaryti notebook-covidspread.ipynb ir perskaityti jį nuo pradžios iki pabaigos. Taip pat galite vykdyti ląsteles ir atlikti kai kuriuos iššūkius, kuriuos palikome jums pabaigoje.
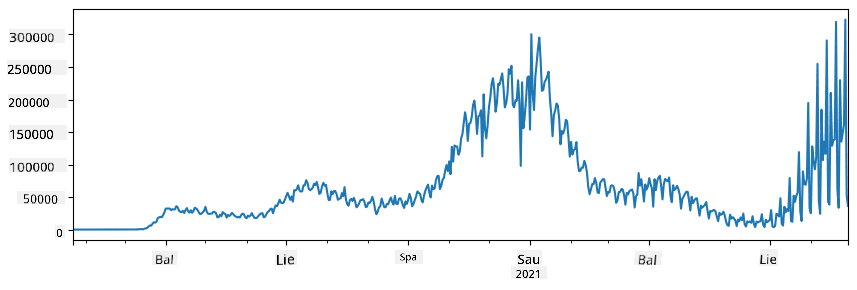
Jei nežinote, kaip vykdyti kodą Jupyter Notebook, peržiūrėkite šį straipsnį.
Darbas su nestruktūrizuotais duomenimis
Nors duomenys dažnai pateikiami lentelės forma, kai kuriais atvejais turime dirbti su mažiau struktūrizuotais duomenimis, pavyzdžiui, tekstu ar vaizdais. Tokiu atveju, norėdami taikyti aukščiau matytas duomenų apdorojimo technikas, turime kažkaip išgauti struktūrizuotus duomenis. Štai keletas pavyzdžių:
- Raktažodžių išgavimas iš teksto ir jų pasikartojimo dažnio analizė
- Neuroninių tinklų naudojimas informacijai apie objektus paveikslėlyje išgauti
- Informacijos apie žmonių emocijas vaizdo kameros sraute gavimas
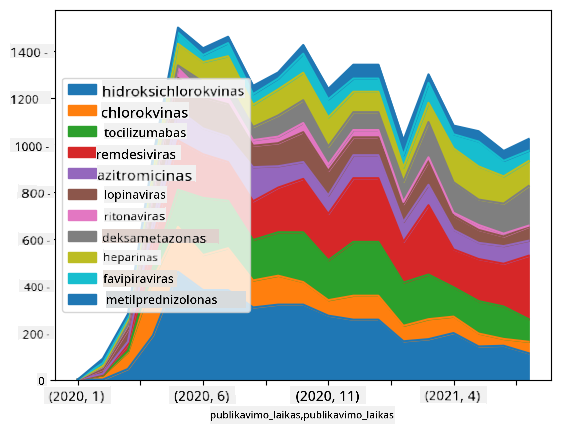
🚀 Iššūkis 2: COVID mokslinių straipsnių analizė
Šiame iššūkyje tęsime COVID pandemijos temą ir sutelksime dėmesį į mokslinių straipsnių šia tema apdorojimą. Yra CORD-19 duomenų rinkinys, kuriame yra daugiau nei 7000 (rašymo metu) straipsnių apie COVID, pateikiamų su metaduomenimis ir santraukomis (apie pusę jų taip pat pateikiamas visas tekstas).
Pilnas šio duomenų rinkinio analizės pavyzdys naudojant Text Analytics for Health kognityvinę paslaugą aprašytas šiame tinklaraščio įraše. Aptarsime supaprastintą šios analizės versiją.
NOTE: Mes nepateikiame šio duomenų rinkinio kopijos kaip šios saugyklos dalies. Pirmiausia gali tekti atsisiųsti
metadata.csvfailą iš šio Kaggle duomenų rinkinio. Gali reikėti registracijos Kaggle. Taip pat galite atsisiųsti duomenų rinkinį be registracijos iš čia, tačiau jis apims visus pilnus tekstus be metaduomenų failo.
Atidarykite notebook-papers.ipynb ir perskaitykite jį nuo pradžios iki pabaigos. Taip pat galite vykdyti ląsteles ir atlikti kai kuriuos iššūkius, kuriuos palikome jums pabaigoje.
Vaizdų duomenų apdorojimas
Pastaruoju metu buvo sukurti labai galingi AI modeliai, leidžiantys suprasti vaizdus. Yra daug užduočių, kurias galima išspręsti naudojant iš anksto apmokytus neuroninius tinklus arba debesų paslaugas. Keletas pavyzdžių:
- Vaizdų klasifikacija, kuri gali padėti kategorizuoti vaizdą į vieną iš iš anksto apibrėžtų klasių. Galite lengvai apmokyti savo vaizdų klasifikatorius naudodami tokias paslaugas kaip Custom Vision
- Objektų atpažinimas, skirtas aptikti skirtingus objektus vaizde. Tokios paslaugos kaip computer vision gali aptikti daugybę bendrų objektų, o jūs galite apmokyti Custom Vision modelį aptikti specifinius jus dominančius objektus.
- Veidų atpažinimas, įskaitant amžiaus, lyties ir emocijų nustatymą. Tai galima atlikti naudojant Face API.
Visos šios debesų paslaugos gali būti iškviečiamos naudojant Python SDKs, todėl jas lengva įtraukti į jūsų duomenų tyrinėjimo darbo eigą.
Štai keletas pavyzdžių, kaip tyrinėti duomenis iš vaizdų šaltinių:
- Tinklaraščio įraše Kaip išmokti duomenų mokslą be programavimo mes tyrinėjame Instagram nuotraukas, bandydami suprasti, kas skatina žmones labiau pamėgti nuotrauką. Pirmiausia iš paveikslėlių išgauname kuo daugiau informacijos naudodami computer vision, o tada naudojame Azure Machine Learning AutoML, kad sukurtume interpretuojamą modelį.
- Veidų tyrimų dirbtuvėse mes naudojame Face API, kad išgautume emocijas žmonių nuotraukose iš renginių, bandydami suprasti, kas daro žmones laimingus.
Išvada
Nesvarbu, ar jau turite struktūrizuotus, ar nestruktūrizuotus duomenis, naudodami Python galite atlikti visus su duomenų apdorojimu ir supratimu susijusius veiksmus. Tai turbūt lankstiausias duomenų apdorojimo būdas, ir būtent todėl dauguma duomenų mokslininkų naudoja Python kaip pagrindinį įrankį. Mokytis Python išsamiai yra gera idėja, jei rimtai žiūrite į savo duomenų mokslo kelionę!
Po paskaitos testas
Apžvalga ir savarankiškas mokymasis
Knygos
Internetiniai ištekliai
- Oficialus 10 minučių Pandas vadovas
- Pandas vizualizacijos dokumentacija
Python mokymasis
- Išmokite Python smagiai su Turtle Graphics ir Fractals
- Pradėkite savo pirmuosius žingsnius su Python mokymosi kelias Microsoft Learn
Užduotis
Atlikite detalesnį duomenų tyrimą aukščiau pateiktiems iššūkiams
Kreditas
Ši pamoka buvo sukurta su ♥️ Dmitry Soshnikov
Atsakomybės apribojimas:
Šis dokumentas buvo išverstas naudojant AI vertimo paslaugą Co-op Translator. Nors stengiamės užtikrinti tikslumą, prašome atkreipti dėmesį, kad automatiniai vertimai gali turėti klaidų ar netikslumų. Originalus dokumentas jo gimtąja kalba turėtų būti laikomas autoritetingu šaltiniu. Dėl svarbios informacijos rekomenduojama profesionali žmogaus vertimo paslauga. Mes neprisiimame atsakomybės už nesusipratimus ar klaidingus interpretavimus, kylančius dėl šio vertimo naudojimo.