|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Arbeiten mit Daten: Python und die Pandas-Bibliothek
 |
|---|
| Arbeiten mit Python - Sketchnote von @nitya |

Datenbanken bieten sehr effiziente Möglichkeiten, Daten zu speichern und sie mit Abfragesprachen zu durchsuchen. Die flexibelste Art der Datenverarbeitung ist jedoch das Schreiben eines eigenen Programms, um Daten zu manipulieren. In vielen Fällen wäre eine Datenbankabfrage effektiver. Es gibt jedoch Situationen, in denen komplexere Datenverarbeitungen erforderlich sind, die mit SQL nicht einfach durchzuführen sind.
Datenverarbeitung kann in jeder Programmiersprache programmiert werden, aber es gibt bestimmte Sprachen, die sich besonders gut für die Arbeit mit Daten eignen. Datenwissenschaftler bevorzugen typischerweise eine der folgenden Sprachen:
- Python, eine universelle Programmiersprache, die aufgrund ihrer Einfachheit oft als eine der besten Optionen für Anfänger gilt. Python verfügt über viele zusätzliche Bibliotheken, die Ihnen helfen können, praktische Probleme zu lösen, wie z. B. das Extrahieren von Daten aus einem ZIP-Archiv oder das Konvertieren eines Bildes in Graustufen. Neben der Datenwissenschaft wird Python auch häufig für die Webentwicklung verwendet.
- R ist ein traditionelles Werkzeug, das speziell für die statistische Datenverarbeitung entwickelt wurde. Es enthält ein großes Repository von Bibliotheken (CRAN), was es zu einer guten Wahl für die Datenverarbeitung macht. Allerdings ist R keine universelle Programmiersprache und wird außerhalb des Bereichs der Datenwissenschaft selten verwendet.
- Julia ist eine weitere Sprache, die speziell für die Datenwissenschaft entwickelt wurde. Sie soll eine bessere Leistung als Python bieten und ist daher ein großartiges Werkzeug für wissenschaftliche Experimente.
In dieser Lektion konzentrieren wir uns auf die Verwendung von Python für einfache Datenverarbeitung. Wir setzen grundlegende Kenntnisse der Sprache voraus. Wenn Sie eine tiefere Einführung in Python wünschen, können Sie auf eine der folgenden Ressourcen zurückgreifen:
- Lernen Sie Python auf unterhaltsame Weise mit Turtle Graphics und Fraktalen - Ein schneller Einführungskurs in Python-Programmierung auf GitHub
- Machen Sie Ihre ersten Schritte mit Python - Lernpfad auf Microsoft Learn
Daten können in vielen Formen vorliegen. In dieser Lektion betrachten wir drei Formen von Daten - tabellarische Daten, Text und Bilder.
Wir konzentrieren uns auf einige Beispiele der Datenverarbeitung, anstatt Ihnen einen vollständigen Überblick über alle zugehörigen Bibliotheken zu geben. Dies ermöglicht es Ihnen, die Hauptidee dessen, was möglich ist, zu verstehen und zu wissen, wo Sie Lösungen für Ihre Probleme finden können, wenn Sie sie benötigen.
Der nützlichste Ratschlag: Wenn Sie eine bestimmte Datenoperation durchführen müssen, aber nicht wissen, wie, suchen Sie im Internet danach. Stackoverflow enthält oft viele nützliche Codebeispiele in Python für viele typische Aufgaben.
Quiz vor der Vorlesung
Tabellarische Daten und Dataframes
Sie haben bereits tabellarische Daten kennengelernt, als wir über relationale Datenbanken gesprochen haben. Wenn Sie viele Daten haben, die in vielen verschiedenen verknüpften Tabellen enthalten sind, macht es definitiv Sinn, SQL zu verwenden, um damit zu arbeiten. Es gibt jedoch viele Fälle, in denen wir eine Tabelle mit Daten haben und Einblicke oder Verständnis über diese Daten gewinnen möchten, wie z. B. die Verteilung oder Korrelation zwischen Werten. In der Datenwissenschaft gibt es viele Fälle, in denen wir einige Transformationen der ursprünglichen Daten durchführen müssen, gefolgt von einer Visualisierung. Beide Schritte können leicht mit Python durchgeführt werden.
Es gibt zwei nützliche Bibliotheken in Python, die Ihnen bei der Arbeit mit tabellarischen Daten helfen können:
- Pandas ermöglicht es Ihnen, sogenannte Dataframes zu manipulieren, die relationalen Tabellen ähneln. Sie können benannte Spalten haben und verschiedene Operationen auf Zeilen, Spalten und Dataframes im Allgemeinen durchführen.
- Numpy ist eine Bibliothek für die Arbeit mit Tensors, d. h. mehrdimensionalen Arrays. Ein Array hat Werte desselben zugrunde liegenden Typs, ist einfacher als ein Dataframe, bietet jedoch mehr mathematische Operationen und erzeugt weniger Overhead.
Es gibt auch ein paar andere Bibliotheken, die Sie kennen sollten:
- Matplotlib ist eine Bibliothek für Datenvisualisierung und das Erstellen von Diagrammen
- SciPy ist eine Bibliothek mit zusätzlichen wissenschaftlichen Funktionen. Wir sind bereits auf diese Bibliothek gestoßen, als wir über Wahrscheinlichkeit und Statistik gesprochen haben.
Hier ist ein Codebeispiel, das Sie typischerweise verwenden würden, um diese Bibliotheken am Anfang Ihres Python-Programms zu importieren:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import ... # you need to specify exact sub-packages that you need
Pandas basiert auf einigen grundlegenden Konzepten.
Series
Series ist eine Sequenz von Werten, ähnlich einer Liste oder einem Numpy-Array. Der Hauptunterschied besteht darin, dass eine Series auch einen Index hat, und wenn wir mit Series arbeiten (z. B. sie addieren), wird der Index berücksichtigt. Der Index kann so einfach wie eine ganze Zeilennummer sein (dies ist der Standardindex, wenn eine Series aus einer Liste oder einem Array erstellt wird), oder er kann eine komplexe Struktur wie ein Datumsintervall haben.
Hinweis: Es gibt einige einführende Pandas-Codes im begleitenden Notebook
notebook.ipynb. Wir skizzieren hier nur einige Beispiele, und Sie sind herzlich eingeladen, das vollständige Notebook zu überprüfen.
Betrachten wir ein Beispiel: Wir möchten die Verkäufe unseres Eisdielenstandes analysieren. Lassen Sie uns eine Serie von Verkaufszahlen (Anzahl der täglich verkauften Artikel) für einen bestimmten Zeitraum generieren:
start_date = "Jan 1, 2020"
end_date = "Mar 31, 2020"
idx = pd.date_range(start_date,end_date)
print(f"Length of index is {len(idx)}")
items_sold = pd.Series(np.random.randint(25,50,size=len(idx)),index=idx)
items_sold.plot()
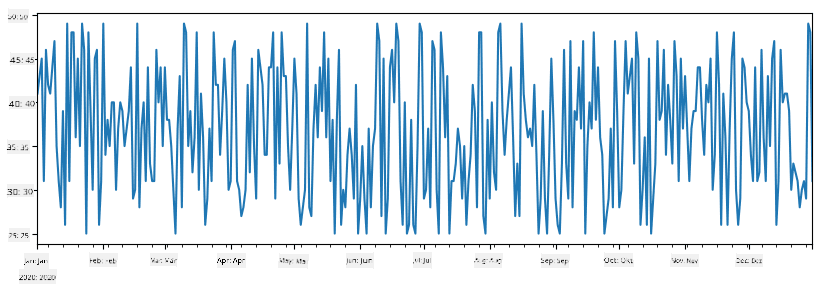
Angenommen, wir organisieren jede Woche eine Party für Freunde und nehmen zusätzlich 10 Packungen Eiscreme für die Party mit. Wir können eine weitere Serie erstellen, die nach Wochen indiziert ist, um dies zu demonstrieren:
additional_items = pd.Series(10,index=pd.date_range(start_date,end_date,freq="W"))
Wenn wir zwei Serien zusammenaddieren, erhalten wir die Gesamtzahl:
total_items = items_sold.add(additional_items,fill_value=0)
total_items.plot()
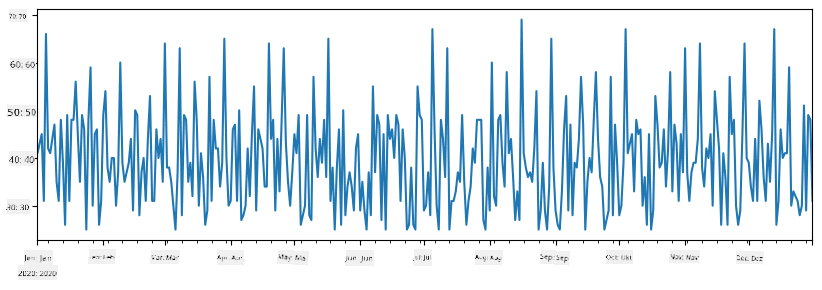
Hinweis: Wir verwenden nicht die einfache Syntax
total_items+additional_items. Wenn wir dies tun würden, würden wir vieleNaN(Not a Number)-Werte in der resultierenden Serie erhalten. Dies liegt daran, dass für einige Indexpunkte in der Serieadditional_itemsWerte fehlen, und das Addieren vonNaNzu irgendetwas ergibtNaN. Daher müssen wir den Parameterfill_valuewährend der Addition angeben.
Mit Zeitreihen können wir die Serie auch mit unterschiedlichen Zeitintervallen neu abtasten. Zum Beispiel, wenn wir das durchschnittliche Verkaufsvolumen monatlich berechnen möchten, können wir den folgenden Code verwenden:
monthly = total_items.resample("1M").mean()
ax = monthly.plot(kind='bar')
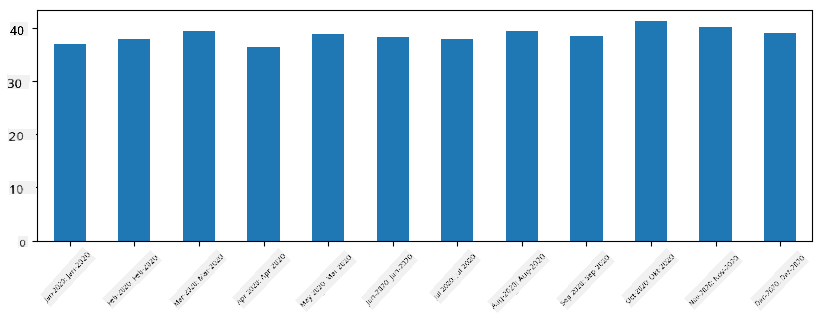
DataFrame
Ein DataFrame ist im Wesentlichen eine Sammlung von Series mit demselben Index. Wir können mehrere Series zu einem DataFrame kombinieren:
a = pd.Series(range(1,10))
b = pd.Series(["I","like","to","play","games","and","will","not","change"],index=range(0,9))
df = pd.DataFrame([a,b])
Dies erstellt eine horizontale Tabelle wie diese:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | I | like | to | use | Python | and | Pandas | very | much |
Wir können Series auch als Spalten verwenden und Spaltennamen mit einem Wörterbuch angeben:
df = pd.DataFrame({ 'A' : a, 'B' : b })
Dies ergibt eine Tabelle wie diese:
| A | B | |
|---|---|---|
| 0 | 1 | I |
| 1 | 2 | like |
| 2 | 3 | to |
| 3 | 4 | use |
| 4 | 5 | Python |
| 5 | 6 | and |
| 6 | 7 | Pandas |
| 7 | 8 | very |
| 8 | 9 | much |
Hinweis: Wir können dieses Tabellenlayout auch erhalten, indem wir die vorherige Tabelle transponieren, z. B. durch Schreiben von
df = pd.DataFrame([a,b]).T..rename(columns={ 0 : 'A', 1 : 'B' })
Hier bedeutet .T die Operation des Transponierens des DataFrames, d. h. das Tauschen von Zeilen und Spalten, und die rename-Operation ermöglicht es uns, Spalten umzubenennen, um das vorherige Beispiel zu entsprechen.
Hier sind einige der wichtigsten Operationen, die wir auf DataFrames ausführen können:
Spaltenauswahl. Wir können einzelne Spalten auswählen, indem wir df['A'] schreiben - diese Operation gibt eine Series zurück. Wir können auch eine Teilmenge von Spalten in einen anderen DataFrame auswählen, indem wir df[['B','A']] schreiben - dies gibt einen anderen DataFrame zurück.
Filtern bestimmter Zeilen nach Kriterien. Zum Beispiel, um nur Zeilen mit Spalte A größer als 5 zu behalten, können wir df[df['A']>5] schreiben.
Hinweis: So funktioniert das Filtern. Der Ausdruck
df['A']<5gibt eine boolesche Serie zurück, die angibt, ob der Ausdruck für jedes Element der ursprünglichen Seriedf['A']TrueoderFalseist. Wenn eine boolesche Serie als Index verwendet wird, gibt sie eine Teilmenge der Zeilen im DataFrame zurück. Daher ist es nicht möglich, beliebige Python-Boolesche Ausdrücke zu verwenden. Zum Beispiel wäre das Schreiben vondf[df['A']>5 and df['A']<7]falsch. Stattdessen sollten Sie die spezielle&-Operation auf booleschen Serien verwenden, indem Siedf[(df['A']>5) & (df['A']<7)]schreiben (Klammern sind hier wichtig).
Erstellen neuer berechneter Spalten. Wir können leicht neue berechnete Spalten für unseren DataFrame erstellen, indem wir intuitive Ausdrücke wie diesen verwenden:
df['DivA'] = df['A']-df['A'].mean()
Dieses Beispiel berechnet die Abweichung von A von seinem Mittelwert. Was hier tatsächlich passiert, ist, dass wir eine Serie berechnen und diese dann der linken Seite zuweisen, wodurch eine weitere Spalte erstellt wird. Daher können wir keine Operationen verwenden, die nicht mit Serien kompatibel sind. Zum Beispiel ist der folgende Code falsch:
# Wrong code -> df['ADescr'] = "Low" if df['A'] < 5 else "Hi"
df['LenB'] = len(df['B']) # <- Wrong result
Das letzte Beispiel, obwohl syntaktisch korrekt, gibt uns ein falsches Ergebnis, da es die Länge der Serie B allen Werten in der Spalte zuweist und nicht die Länge der einzelnen Elemente, wie wir beabsichtigt hatten.
Wenn wir komplexe Ausdrücke wie diesen berechnen müssen, können wir die Funktion apply verwenden. Das letzte Beispiel kann wie folgt geschrieben werden:
df['LenB'] = df['B'].apply(lambda x : len(x))
# or
df['LenB'] = df['B'].apply(len)
Nach den obigen Operationen erhalten wir den folgenden DataFrame:
| A | B | DivA | LenB | |
|---|---|---|---|---|
| 0 | 1 | I | -4.0 | 1 |
| 1 | 2 | like | -3.0 | 4 |
| 2 | 3 | to | -2.0 | 2 |
| 3 | 4 | use | -1.0 | 3 |
| 4 | 5 | Python | 0.0 | 6 |
| 5 | 6 | and | 1.0 | 3 |
| 6 | 7 | Pandas | 2.0 | 6 |
| 7 | 8 | very | 3.0 | 4 |
| 8 | 9 | much | 4.0 | 4 |
Auswahl von Zeilen basierend auf Zahlen kann mit der iloc-Konstruktion durchgeführt werden. Zum Beispiel, um die ersten 5 Zeilen aus dem DataFrame auszuwählen:
df.iloc[:5]
Gruppierung wird oft verwendet, um ein Ergebnis ähnlich wie Pivot-Tabellen in Excel zu erhalten. Angenommen, wir möchten den Mittelwert der Spalte A für jede gegebene Anzahl von LenB berechnen. Dann können wir unseren DataFrame nach LenB gruppieren und mean aufrufen:
df.groupby(by='LenB').mean()
Wenn wir den Mittelwert und die Anzahl der Elemente in der Gruppe berechnen müssen, können wir die komplexere Funktion aggregate verwenden:
df.groupby(by='LenB') \
.aggregate({ 'DivA' : len, 'A' : lambda x: x.mean() }) \
.rename(columns={ 'DivA' : 'Count', 'A' : 'Mean'})
Dies ergibt die folgende Tabelle:
| LenB | Count | Mean |
|---|---|---|
| 1 | 1 | 1.000000 |
| 2 | 1 | 3.000000 |
| 3 | 2 | 5.000000 |
| 4 | 3 | 6.333333 |
| 6 | 2 | 6.000000 |
Daten abrufen
Wir haben gesehen, wie einfach es ist, Series und DataFrames aus Python-Objekten zu erstellen. Allerdings liegen Daten normalerweise in Form einer Textdatei oder einer Excel-Tabelle vor. Glücklicherweise bietet uns Pandas eine einfache Möglichkeit, Daten von der Festplatte zu laden. Zum Beispiel ist das Lesen einer CSV-Datei so einfach wie hier gezeigt:
df = pd.read_csv('file.csv')
Wir werden weitere Beispiele zum Laden von Daten sehen, einschließlich des Abrufens von externen Websites, im Abschnitt "Challenge".
Drucken und Plotten
Ein Data Scientist muss oft die Daten erkunden, daher ist es wichtig, sie visualisieren zu können. Wenn ein DataFrame groß ist, möchten wir oft nur sicherstellen, dass wir alles richtig machen, indem wir die ersten paar Zeilen ausgeben. Dies kann durch Aufrufen von df.head() erfolgen. Wenn Sie es in einem Jupyter Notebook ausführen, wird der DataFrame in einer schönen tabellarischen Form angezeigt.
Wir haben auch die Verwendung der Funktion plot gesehen, um einige Spalten zu visualisieren. Während plot für viele Aufgaben sehr nützlich ist und viele verschiedene Diagrammtypen über den Parameter kind= unterstützt, können Sie immer die Bibliothek matplotlib verwenden, um etwas Komplexeres zu erstellen. Wir werden die Datenvisualisierung in separaten Kurslektionen ausführlich behandeln.
Dieser Überblick deckt die wichtigsten Konzepte von Pandas ab, jedoch ist die Bibliothek sehr umfangreich, und es gibt keine Grenzen, was Sie damit tun können! Wenden wir dieses Wissen nun an, um ein spezifisches Problem zu lösen.
🚀 Challenge 1: Analyse der COVID-Ausbreitung
Das erste Problem, auf das wir uns konzentrieren werden, ist die Modellierung der epidemischen Ausbreitung von COVID-19. Dazu verwenden wir die Daten über die Anzahl der infizierten Personen in verschiedenen Ländern, bereitgestellt vom Center for Systems Science and Engineering (CSSE) der Johns Hopkins University. Der Datensatz ist in diesem GitHub-Repository verfügbar.
Da wir demonstrieren möchten, wie man mit Daten umgeht, laden wir Sie ein, notebook-covidspread.ipynb zu öffnen und es von oben nach unten zu lesen. Sie können auch Zellen ausführen und einige Herausforderungen lösen, die wir am Ende für Sie hinterlassen haben.
Wenn Sie nicht wissen, wie man Code in Jupyter Notebook ausführt, schauen Sie sich diesen Artikel an.
Arbeiten mit unstrukturierten Daten
Während Daten sehr oft in tabellarischer Form vorliegen, müssen wir in einigen Fällen mit weniger strukturierten Daten umgehen, z. B. Text oder Bildern. In diesem Fall müssen wir, um die oben gesehenen Datenverarbeitungstechniken anzuwenden, irgendwie strukturierte Daten extrahieren. Hier sind einige Beispiele:
- Extrahieren von Schlüsselwörtern aus Text und Analysieren, wie oft diese Schlüsselwörter vorkommen
- Verwenden von neuronalen Netzwerken, um Informationen über Objekte auf einem Bild zu extrahieren
- Ermitteln von Emotionen von Personen in einem Video-Feed
🚀 Challenge 2: Analyse von COVID-Fachartikeln
In dieser Challenge bleiben wir beim Thema der COVID-Pandemie und konzentrieren uns auf die Verarbeitung wissenschaftlicher Artikel zu diesem Thema. Es gibt den CORD-19-Datensatz mit mehr als 7000 (zum Zeitpunkt der Erstellung) Artikeln über COVID, verfügbar mit Metadaten und Abstracts (und für etwa die Hälfte davon ist auch der Volltext verfügbar).
Ein vollständiges Beispiel für die Analyse dieses Datensatzes mit dem kognitiven Dienst Text Analytics for Health wird in diesem Blogpost beschrieben. Wir werden eine vereinfachte Version dieser Analyse besprechen.
NOTE: Wir stellen keine Kopie des Datensatzes als Teil dieses Repositories bereit. Sie müssen möglicherweise zuerst die Datei
metadata.csvaus diesem Datensatz auf Kaggle herunterladen. Eine Registrierung bei Kaggle kann erforderlich sein. Alternativ können Sie den Datensatz ohne Registrierung hier herunterladen, aber er wird alle Volltexte zusätzlich zur Metadaten-Datei enthalten.
Öffnen Sie notebook-papers.ipynb und lesen Sie es von oben nach unten. Sie können auch Zellen ausführen und einige Herausforderungen lösen, die wir am Ende für Sie hinterlassen haben.
Verarbeitung von Bilddaten
In letzter Zeit wurden sehr leistungsstarke KI-Modelle entwickelt, die es ermöglichen, Bilder zu verstehen. Es gibt viele Aufgaben, die mit vortrainierten neuronalen Netzwerken oder Cloud-Diensten gelöst werden können. Einige Beispiele sind:
- Bildklassifikation, die Ihnen helfen kann, ein Bild in eine der vordefinierten Klassen einzuordnen. Sie können Ihre eigenen Bildklassifikatoren einfach mit Diensten wie Custom Vision trainieren.
- Objekterkennung, um verschiedene Objekte im Bild zu erkennen. Dienste wie Computer Vision können eine Reihe von gängigen Objekten erkennen, und Sie können ein Custom Vision-Modell trainieren, um spezifische Objekte von Interesse zu erkennen.
- Gesichtserkennung, einschließlich Alter, Geschlecht und Emotionserkennung. Dies kann über die Face API erfolgen.
All diese Cloud-Dienste können mit Python SDKs aufgerufen werden und können somit leicht in Ihren Datenexplorations-Workflow integriert werden.
Hier sind einige Beispiele für die Erkundung von Daten aus Bilddatenquellen:
- Im Blogpost How to Learn Data Science without Coding untersuchen wir Instagram-Fotos, um zu verstehen, was Menschen dazu bringt, einem Foto mehr Likes zu geben. Wir extrahieren zunächst so viele Informationen wie möglich aus Bildern mit Computer Vision und verwenden dann Azure Machine Learning AutoML, um ein interpretierbares Modell zu erstellen.
- Im Facial Studies Workshop verwenden wir die Face API, um Emotionen von Personen auf Fotos von Veranstaltungen zu extrahieren, um zu verstehen, was Menschen glücklich macht.
Fazit
Egal, ob Sie bereits strukturierte oder unstrukturierte Daten haben, mit Python können Sie alle Schritte der Datenverarbeitung und -analyse durchführen. Es ist wahrscheinlich die flexibelste Methode zur Datenverarbeitung, und das ist der Grund, warum die Mehrheit der Data Scientists Python als ihr Hauptwerkzeug verwendet. Python gründlich zu lernen, ist wahrscheinlich eine gute Idee, wenn Sie Ihre Reise in die Datenwissenschaft ernsthaft verfolgen möchten!
Quiz nach der Vorlesung
Rückblick & Selbststudium
Bücher
Online-Ressourcen
- Offizielles 10 Minuten zu Pandas-Tutorial
- Dokumentation zur Pandas-Visualisierung
Python lernen
- Lernen Sie Python auf unterhaltsame Weise mit Turtle Graphics und Fraktalen
- Machen Sie Ihre ersten Schritte mit Python Lernpfad auf Microsoft Learn
Aufgabe
Führen Sie eine detailliertere Datenanalyse für die oben genannten Herausforderungen durch
Credits
Diese Lektion wurde mit ♥️ von Dmitry Soshnikov erstellt.
Haftungsausschluss:
Dieses Dokument wurde mit dem KI-Übersetzungsdienst Co-op Translator übersetzt. Obwohl wir uns um Genauigkeit bemühen, weisen wir darauf hin, dass automatisierte Übersetzungen Fehler oder Ungenauigkeiten enthalten können. Das Originaldokument in seiner ursprünglichen Sprache sollte als maßgebliche Quelle betrachtet werden. Für kritische Informationen wird eine professionelle menschliche Übersetzung empfohlen. Wir übernehmen keine Haftung für Missverständnisse oder Fehlinterpretationen, die aus der Nutzung dieser Übersetzung entstehen.