|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Data Science i skyen: Den "Azure ML SDK" tilgang
 |
|---|
| Data Science i skyen: Azure ML SDK - Sketchnote af @nitya |
Indholdsfortegnelse:
- Data Science i skyen: Den "Azure ML SDK" tilgang
Quiz før lektionen
1. Introduktion
1.1 Hvad er Azure ML SDK?
Dataforskere og AI-udviklere bruger Azure Machine Learning SDK til at bygge og køre machine learning-workflows med Azure Machine Learning-tjenesten. Du kan interagere med tjenesten i ethvert Python-miljø, herunder Jupyter Notebooks, Visual Studio Code eller din foretrukne Python IDE.
Nøgleområder i SDK inkluderer:
- Udforsk, forbered og administrer livscyklussen for dine datasæt, der bruges i machine learning-eksperimenter.
- Administrer cloud-ressourcer til overvågning, logning og organisering af dine machine learning-eksperimenter.
- Træn modeller enten lokalt eller ved hjælp af cloud-ressourcer, inklusive GPU-accelereret modeltræning.
- Brug automatiseret machine learning, som accepterer konfigurationsparametre og træningsdata. Det itererer automatisk gennem algoritmer og hyperparameterindstillinger for at finde den bedste model til at køre forudsigelser.
- Udrul webtjenester for at konvertere dine trænede modeller til RESTful-tjenester, der kan forbruges i enhver applikation.
Læs mere om Azure Machine Learning SDK
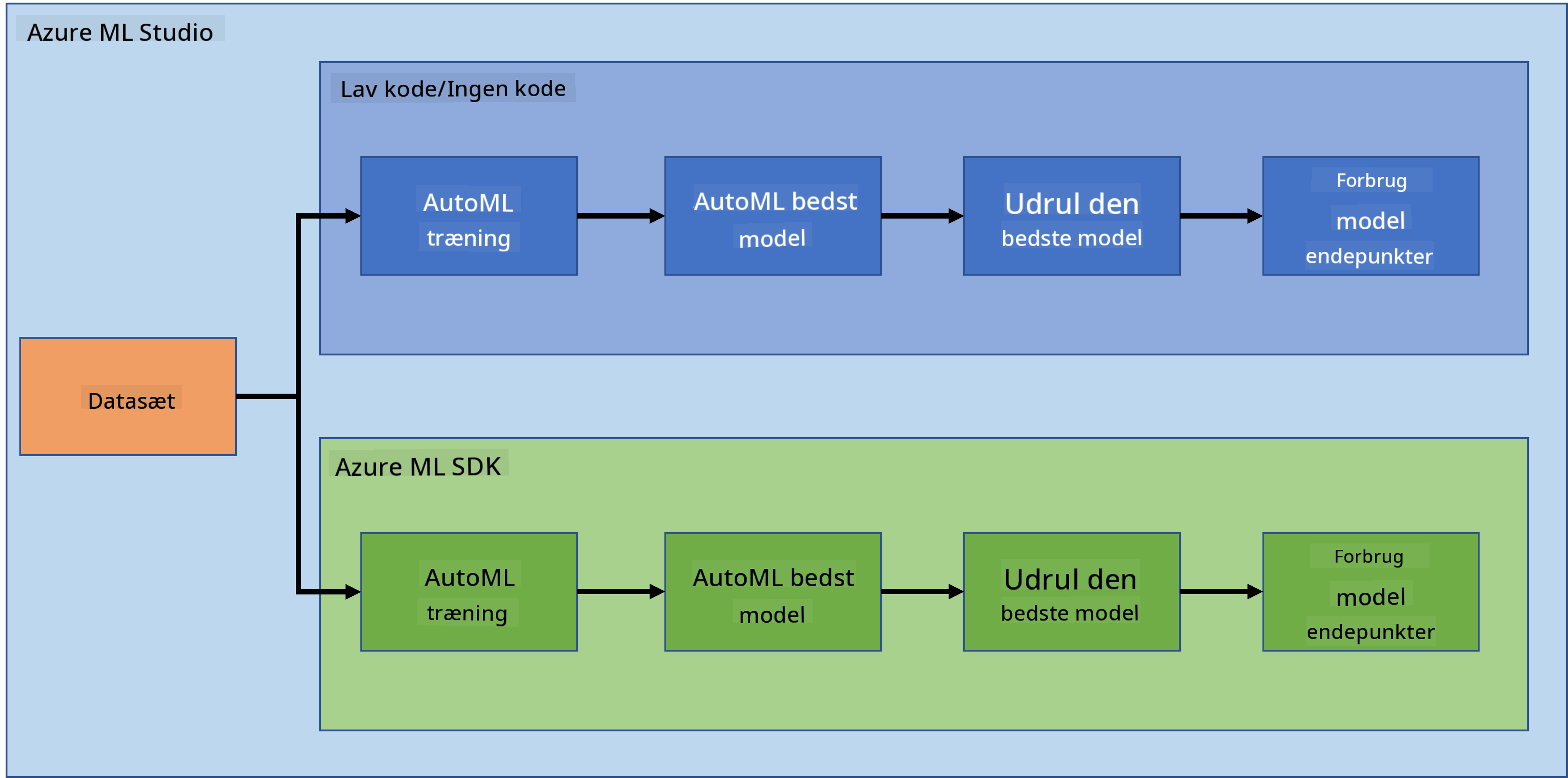
I den forrige lektion så vi, hvordan man træner, udruller og forbruger en model på en Low code/No code-måde. Vi brugte hjertesvigt-datasættet til at generere en hjertesvigtforudsigelsesmodel. I denne lektion vil vi gøre præcis det samme, men ved hjælp af Azure Machine Learning SDK.
1.2 Projekt om hjertesvigtforudsigelse og introduktion til datasæt
Se her for introduktion til projektet om hjertesvigtforudsigelse og datasæt.
2. Træning af en model med Azure ML SDK
2.1 Opret et Azure ML workspace
For nemheds skyld vil vi arbejde i en Jupyter Notebook. Dette indebærer, at du allerede har et workspace og en compute-instans. Hvis du allerede har et workspace, kan du direkte springe til sektionen 2.3 Notebook-oprettelse.
Hvis ikke, følg venligst instruktionerne i sektionen 2.1 Opret et Azure ML workspace i den forrige lektion for at oprette et workspace.
2.2 Opret en compute-instans
I Azure ML workspace, som vi oprettede tidligere, gå til compute-menuen, og du vil se de forskellige compute-ressourcer, der er tilgængelige.
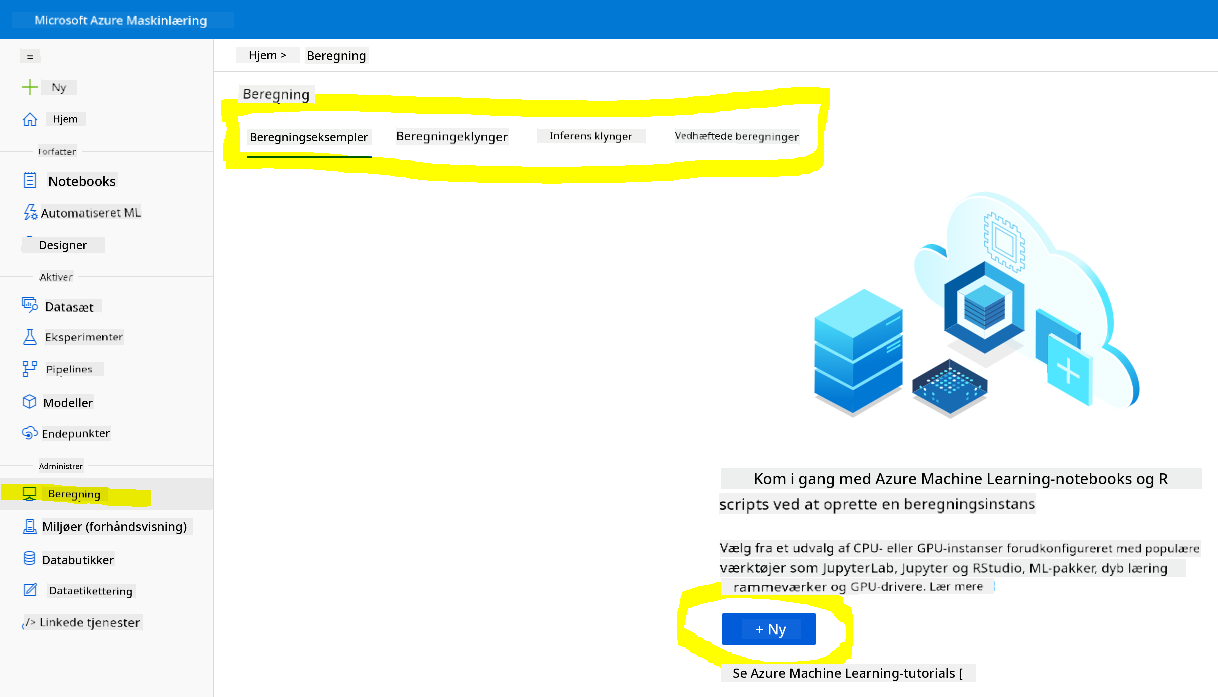
Lad os oprette en compute-instans for at provisionere en Jupyter Notebook.
- Klik på knappen + Ny.
- Giv din compute-instans et navn.
- Vælg dine muligheder: CPU eller GPU, VM-størrelse og antal kerner.
- Klik på knappen Opret.
Tillykke, du har lige oprettet en compute-instans! Vi vil bruge denne compute-instans til at oprette en Notebook i sektionen Oprettelse af notebooks.
2.3 Indlæsning af datasæt
Se sektionen 2.3 Indlæsning af datasæt i den forrige lektion, hvis du endnu ikke har uploadet datasættet.
2.4 Oprettelse af notebooks
NOTE: Til det næste trin kan du enten oprette en ny notebook fra bunden eller uploade den notebook, vi oprettede i din Azure ML Studio. For at uploade den skal du blot klikke på "Notebook"-menuen og uploade notebooken.
Notebooks er en virkelig vigtig del af data science-processen. De kan bruges til at udføre Exploratory Data Analysis (EDA), kalde en compute-cluster for at træne en model, eller kalde en inference-cluster for at udrulle et endpoint.
For at oprette en Notebook har vi brug for en compute-node, der serverer Jupyter Notebook-instansen. Gå tilbage til Azure ML workspace og klik på Compute-instanser. I listen over compute-instanser bør du se compute-instansen, vi oprettede tidligere.
- I sektionen Applikationer skal du klikke på Jupyter-indstillingen.
- Marker boksen "Ja, jeg forstår" og klik på knappen Fortsæt.
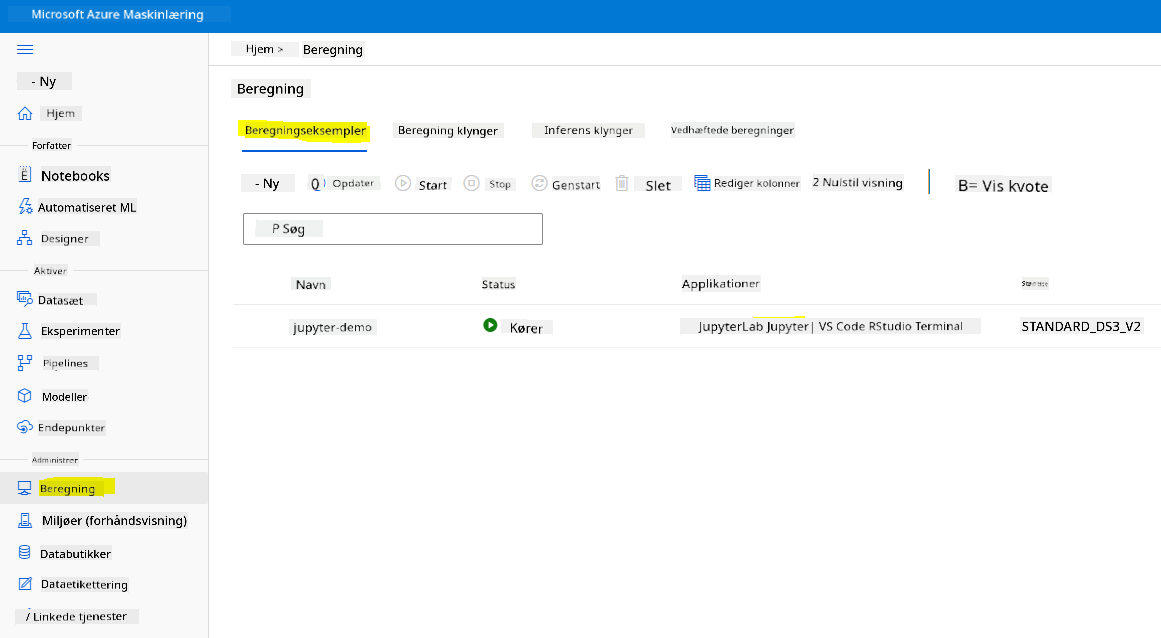
- Dette skulle åbne en ny browserfane med din Jupyter Notebook-instans som vist. Klik på knappen "Ny" for at oprette en notebook.
Nu hvor vi har en Notebook, kan vi begynde at træne modellen med Azure ML SDK.
2.5 Træning af en model
Først og fremmest, hvis du nogensinde er i tvivl, henvis til Azure ML SDK-dokumentationen. Den indeholder alle nødvendige oplysninger for at forstå de moduler, vi skal se i denne lektion.
2.5.1 Opsætning af workspace, eksperiment, compute-cluster og datasæt
Du skal indlæse workspace fra konfigurationsfilen ved hjælp af følgende kode:
from azureml.core import Workspace
ws = Workspace.from_config()
Dette returnerer et objekt af typen Workspace, der repræsenterer workspace. Derefter skal du oprette et eksperiment ved hjælp af følgende kode:
from azureml.core import Experiment
experiment_name = 'aml-experiment'
experiment = Experiment(ws, experiment_name)
For at få eller oprette et eksperiment fra et workspace anmoder du om eksperimentet ved hjælp af eksperimentnavnet. Eksperimentnavnet skal være 3-36 tegn, starte med et bogstav eller et tal og kan kun indeholde bogstaver, tal, understregninger og bindestreger. Hvis eksperimentet ikke findes i workspace, oprettes et nyt eksperiment.
Nu skal du oprette en compute-cluster til træningen ved hjælp af følgende kode. Bemærk, at dette trin kan tage et par minutter.
from azureml.core.compute import AmlCompute
aml_name = "heart-f-cluster"
try:
aml_compute = AmlCompute(ws, aml_name)
print('Found existing AML compute context.')
except:
print('Creating new AML compute context.')
aml_config = AmlCompute.provisioning_configuration(vm_size = "Standard_D2_v2", min_nodes=1, max_nodes=3)
aml_compute = AmlCompute.create(ws, name = aml_name, provisioning_configuration = aml_config)
aml_compute.wait_for_completion(show_output = True)
cts = ws.compute_targets
compute_target = cts[aml_name]
Du kan få datasættet fra workspace ved hjælp af datasætnavnet på følgende måde:
dataset = ws.datasets['heart-failure-records']
df = dataset.to_pandas_dataframe()
df.describe()
2.5.2 AutoML-konfiguration og træning
For at indstille AutoML-konfigurationen skal du bruge AutoMLConfig-klassen.
Som beskrevet i dokumentationen er der mange parametre, du kan lege med. For dette projekt vil vi bruge følgende parametre:
experiment_timeout_minutes: Den maksimale tid (i minutter), som eksperimentet må køre, før det automatisk stoppes, og resultaterne automatisk gøres tilgængelige.max_concurrent_iterations: Det maksimale antal samtidige træningsiterationer, der er tilladt for eksperimentet.primary_metric: Den primære metrik, der bruges til at bestemme eksperimentets status.compute_target: Azure Machine Learning compute-målet, som det automatiserede machine learning-eksperiment skal køre på.task: Typen af opgave, der skal køres. Værdier kan være 'classification', 'regression' eller 'forecasting' afhængigt af typen af automatiseret ML-problem, der skal løses.training_data: Træningsdataene, der skal bruges i eksperimentet. Det skal indeholde både træningsfunktioner og en label-kolonne (valgfrit en sample weights-kolonne).label_column_name: Navnet på label-kolonnen.path: Den fulde sti til Azure Machine Learning-projektmappen.enable_early_stopping: Om tidlig afslutning skal aktiveres, hvis scoren ikke forbedres på kort sigt.featurization: Indikator for, om featurization-trinnet skal udføres automatisk eller ej, eller om tilpasset featurization skal bruges.debug_log: Logfilen til at skrive debug-information til.
from azureml.train.automl import AutoMLConfig
project_folder = './aml-project'
automl_settings = {
"experiment_timeout_minutes": 20,
"max_concurrent_iterations": 3,
"primary_metric" : 'AUC_weighted'
}
automl_config = AutoMLConfig(compute_target=compute_target,
task = "classification",
training_data=dataset,
label_column_name="DEATH_EVENT",
path = project_folder,
enable_early_stopping= True,
featurization= 'auto',
debug_log = "automl_errors.log",
**automl_settings
)
Nu hvor du har din konfiguration indstillet, kan du træne modellen ved hjælp af følgende kode. Dette trin kan tage op til en time afhængigt af din cluster-størrelse.
remote_run = experiment.submit(automl_config)
Du kan køre RunDetails-widgeten for at vise de forskellige eksperimenter.
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
3. Modeludrulning og endpoint-forbrug med Azure ML SDK
3.1 Gem den bedste model
remote_run er et objekt af typen AutoMLRun. Dette objekt indeholder metoden get_output(), som returnerer den bedste kørsel og den tilsvarende tilpassede model.
best_run, fitted_model = remote_run.get_output()
Du kan se de parametre, der blev brugt til den bedste model, ved blot at printe fitted_model og se egenskaberne for den bedste model ved hjælp af metoden get_properties().
best_run.get_properties()
Registrer nu modellen med metoden register_model.
model_name = best_run.properties['model_name']
script_file_name = 'inference/score.py'
best_run.download_file('outputs/scoring_file_v_1_0_0.py', 'inference/score.py')
description = "aml heart failure project sdk"
model = best_run.register_model(model_name = model_name,
model_path = './outputs/',
description = description,
tags = None)
3.2 Modeludrulning
Når den bedste model er gemt, kan vi udrulle den med klassen InferenceConfig. InferenceConfig repræsenterer konfigurationsindstillingerne for et tilpasset miljø, der bruges til udrulning. Klassen AciWebservice repræsenterer en machine learning-model, der er udrullet som en webtjeneste-endpoint på Azure Container Instances. En udrullet tjeneste oprettes fra en model, script og tilhørende filer. Den resulterende webtjeneste er et load-balanceret HTTP-endpoint med en REST API. Du kan sende data til denne API og modtage forudsigelsen returneret af modellen.
Modellen udrulles ved hjælp af metoden deploy.
from azureml.core.model import InferenceConfig, Model
from azureml.core.webservice import AciWebservice
inference_config = InferenceConfig(entry_script=script_file_name, environment=best_run.get_environment())
aciconfig = AciWebservice.deploy_configuration(cpu_cores = 1,
memory_gb = 1,
tags = {'type': "automl-heart-failure-prediction"},
description = 'Sample service for AutoML Heart Failure Prediction')
aci_service_name = 'automl-hf-sdk'
aci_service = Model.deploy(ws, aci_service_name, [model], inference_config, aciconfig)
aci_service.wait_for_deployment(True)
print(aci_service.state)
Dette trin bør tage et par minutter.
3.3 Endpoint-forbrug
Du forbruger dit endpoint ved at oprette en prøveinput:
data = {
"data":
[
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
test_sample = str.encode(json.dumps(data))
Og derefter kan du sende dette input til din model for at få en forudsigelse:
response = aci_service.run(input_data=test_sample)
response
Dette bør give outputtet '{"result": [false]}'. Det betyder, at patientdataene, vi sendte til endpointet, genererede forudsigelsen false, hvilket betyder, at denne person sandsynligvis ikke vil få et hjerteanfald.
Tillykke! Du har netop brugt modellen, der er implementeret og trænet på Azure ML med Azure ML SDK!
NOTE: Når du er færdig med projektet, må du ikke glemme at slette alle ressourcer.
🚀 Udfordring
Der er mange andre ting, du kan gøre med SDK'en, men desværre kan vi ikke gennemgå dem alle i denne lektion. Men gode nyheder: Hvis du lærer at navigere i SDK-dokumentationen, kan du komme langt på egen hånd. Tag et kig på Azure ML SDK-dokumentationen og find klassen Pipeline, som giver dig mulighed for at oprette pipelines. En pipeline er en samling af trin, der kan udføres som en arbejdsgang.
TIP: Gå til SDK-dokumentationen og skriv nøgleord i søgefeltet som "Pipeline". Du bør finde klassen azureml.pipeline.core.Pipeline i søgeresultaterne.
Quiz efter lektionen
Gennemgang & Selvstudie
I denne lektion lærte du, hvordan man træner, implementerer og bruger en model til at forudsige risikoen for hjertesvigt med Azure ML SDK i skyen. Se denne dokumentation for yderligere information om Azure ML SDK. Prøv at oprette din egen model med Azure ML SDK.
Opgave
Data Science-projekt med Azure ML SDK
Ansvarsfraskrivelse:
Dette dokument er blevet oversat ved hjælp af AI-oversættelsestjenesten Co-op Translator. Selvom vi bestræber os på nøjagtighed, skal du være opmærksom på, at automatiserede oversættelser kan indeholde fejl eller unøjagtigheder. Det originale dokument på dets oprindelige sprog bør betragtes som den autoritative kilde. For kritisk information anbefales professionel menneskelig oversættelse. Vi er ikke ansvarlige for eventuelle misforståelser eller fejltolkninger, der opstår som følge af brugen af denne oversættelse.