|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Data Science i skyen: Den "Low code/No code"-metode
 |
|---|
| Data Science i skyen: Low Code - Sketchnote af @nitya |
Indholdsfortegnelse:
- Data Science i skyen: Den "Low code/No code"-metode
Quiz før lektionen
1. Introduktion
1.1 Hvad er Azure Machine Learning?
Azure cloud-platformen består af mere end 200 produkter og cloud-tjenester designet til at hjælpe dig med at bringe nye løsninger til live. Dataspecialister bruger meget tid på at udforske og forbehandle data samt afprøve forskellige algoritmer til modeltræning for at producere præcise modeller. Disse opgaver er tidskrævende og udnytter ofte ikke dyre compute-ressourcer effektivt.
Azure ML er en cloud-baseret platform til at bygge og drive maskinlæringsløsninger i Azure. Den inkluderer en bred vifte af funktioner og muligheder, der hjælper dataspecialister med at forberede data, træne modeller, publicere forudsigelsestjenester og overvåge deres brug. Mest af alt hjælper den med at øge effektiviteten ved at automatisere mange af de tidskrævende opgaver, der er forbundet med modeltræning, og den gør det muligt at bruge cloud-baserede compute-ressourcer, der skalerer effektivt til at håndtere store datamængder, mens omkostninger kun påløber, når de faktisk bruges.
Azure ML tilbyder alle de værktøjer, udviklere og dataspecialister har brug for til deres maskinlæringsarbejdsgange. Disse inkluderer:
- Azure Machine Learning Studio: En webportal i Azure Machine Learning til low-code og no-code muligheder for modeltræning, udrulning, automatisering, sporing og asset management. Studiet integreres med Azure Machine Learning SDK for en problemfri oplevelse.
- Jupyter Notebooks: Hurtig prototyping og test af ML-modeller.
- Azure Machine Learning Designer: Muliggør drag-and-drop af moduler til at bygge eksperimenter og derefter udrulle pipelines i et low-code miljø.
- Automated machine learning UI (AutoML): Automatiserer iterative opgaver i udviklingen af maskinlæringsmodeller, hvilket gør det muligt at bygge ML-modeller med høj skala, effektivitet og produktivitet, samtidig med at modelkvaliteten opretholdes.
- Data Labelling: Et assisteret ML-værktøj til automatisk mærkning af data.
- Machine learning extension for Visual Studio Code: Giver et fuldt udviklingsmiljø til at bygge og administrere ML-projekter.
- Machine learning CLI: Tilbyder kommandoer til at administrere Azure ML-ressourcer fra kommandolinjen.
- Integration med open-source frameworks som PyTorch, TensorFlow, Scikit-learn og mange flere til træning, udrulning og styring af hele maskinlæringsprocessen.
- MLflow: Et open-source bibliotek til at administrere livscyklussen for dine maskinlæringseksperimenter. MLFlow Tracking er en komponent i MLflow, der logger og sporer dine træningskørselsmetrikker og modelartefakter, uanset dit eksperimentmiljø.
1.2 Projektet om forudsigelse af hjertesvigt:
Der er ingen tvivl om, at det at lave og bygge projekter er den bedste måde at teste dine færdigheder og viden på. I denne lektion vil vi udforske to forskellige måder at bygge et datavidenskabsprojekt til forudsigelse af hjertesvigt i Azure ML Studio: gennem Low code/No code og gennem Azure ML SDK, som vist i følgende skema:
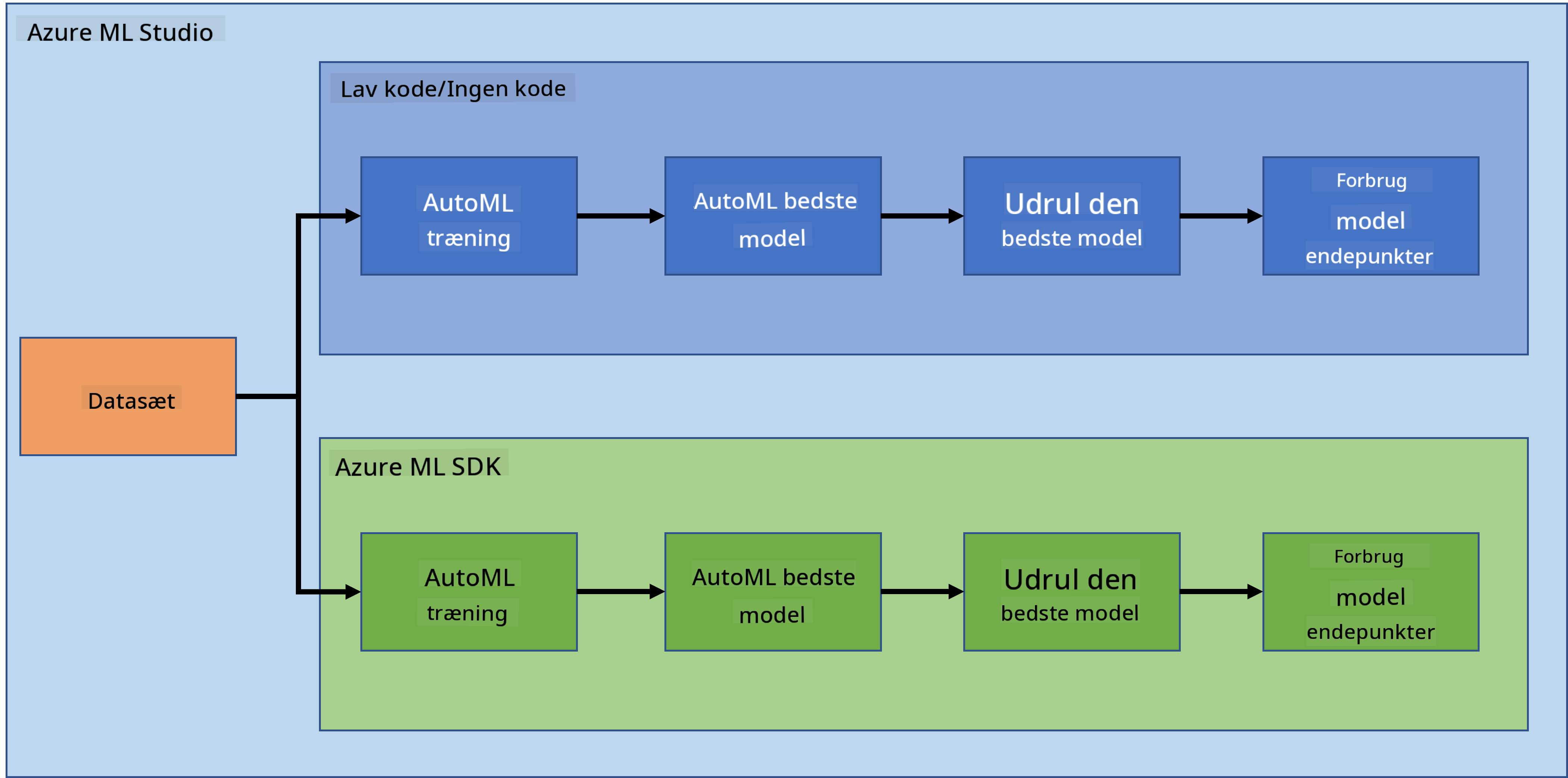
Hver metode har sine egne fordele og ulemper. Low code/No code-metoden er lettere at starte med, da den indebærer interaktion med en GUI (grafisk brugergrænseflade) uden krav om forudgående kendskab til kode. Denne metode muliggør hurtig test af projektets levedygtighed og oprettelse af POC (Proof Of Concept). Men efterhånden som projektet vokser, og det skal være produktionsklart, er det ikke praktisk at oprette ressourcer gennem GUI. Vi skal programmere og automatisere alt, fra oprettelse af ressourcer til udrulning af en model. Her bliver kendskab til brugen af Azure ML SDK afgørende.
| Low code/No code | Azure ML SDK | |
|---|---|---|
| Kendskab til kode | Ikke nødvendigt | Nødvendigt |
| Udviklingstid | Hurtig og nem | Afhænger af kodeekspertise |
| Produktionsklar | Nej | Ja |
1.3 Datasættet om hjertesvigt:
Hjerte-kar-sygdomme (CVD'er) er den største dødsårsag globalt og tegner sig for 31% af alle dødsfald på verdensplan. Miljømæssige og adfærdsmæssige risikofaktorer som tobaksbrug, usund kost og fedme, fysisk inaktivitet og skadelig brug af alkohol kan bruges som funktioner i estimeringsmodeller. At kunne estimere sandsynligheden for udvikling af en CVD kan være meget nyttigt til at forebygge angreb hos højrisikopersoner.
Kaggle har gjort et hjertesvigt-datasæt offentligt tilgængeligt, som vi vil bruge til dette projekt. Du kan downloade datasættet nu. Det er et tabelbaseret datasæt med 13 kolonner (12 funktioner og 1 målvariabel) og 299 rækker.
| Variabelnavn | Type | Beskrivelse | Eksempel | |
|---|---|---|---|---|
| 1 | age | numerisk | Patientens alder | 25 |
| 2 | anaemia | boolean | Fald i røde blodlegemer eller hæmoglobin | 0 eller 1 |
| 3 | creatinine_phosphokinase | numerisk | Niveau af CPK-enzym i blodet | 542 |
| 4 | diabetes | boolean | Om patienten har diabetes | 0 eller 1 |
| 5 | ejection_fraction | numerisk | Procentdel af blod, der forlader hjertet ved hver sammentrækning | 45 |
| 6 | high_blood_pressure | boolean | Om patienten har forhøjet blodtryk | 0 eller 1 |
| 7 | platelets | numerisk | Blodplader i blodet | 149000 |
| 8 | serum_creatinine | numerisk | Niveau af serumkreatinin i blodet | 0.5 |
| 9 | serum_sodium | numerisk | Niveau af serumnatrium i blodet | jun |
| 10 | sex | boolean | Kvinde eller mand | 0 eller 1 |
| 11 | smoking | boolean | Om patienten ryger | 0 eller 1 |
| 12 | time | numerisk | Opfølgningsperiode (dage) | 4 |
| ---- | --------------------------- | ----------------- | ----------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [Mål] | boolean | Om patienten dør i opfølgningsperioden | 0 eller 1 |
Når du har datasættet, kan vi starte projektet i Azure.
2. Low code/No code træning af en model i Azure ML Studio
2.1 Opret et Azure ML-arbejdsområde
For at træne en model i Azure ML skal du først oprette et Azure ML-arbejdsområde. Arbejdsområdet er den øverste ressource i Azure Machine Learning og giver et centralt sted at arbejde med alle de artefakter, du opretter, når du bruger Azure Machine Learning. Arbejdsområdet holder en historik over alle træningskørsler, inklusive logfiler, metrikker, output og et snapshot af dine scripts. Du bruger disse oplysninger til at afgøre, hvilken træningskørsel der producerer den bedste model. Lær mere
Det anbefales at bruge den mest opdaterede browser, der er kompatibel med dit operativsystem. Følgende browsere understøttes:
- Microsoft Edge (Den nye Microsoft Edge, seneste version. Ikke Microsoft Edge legacy)
- Safari (seneste version, kun Mac)
- Chrome (seneste version)
- Firefox (seneste version)
For at bruge Azure Machine Learning skal du oprette et arbejdsområde i dit Azure-abonnement. Du kan derefter bruge dette arbejdsområde til at administrere data, compute-ressourcer, kode, modeller og andre artefakter relateret til dine maskinlæringsarbejdsgange.
NOTE: Dit Azure-abonnement vil blive opkrævet et mindre beløb for datalagring, så længe Azure Machine Learning-arbejdsområdet eksisterer i dit abonnement. Vi anbefaler derfor, at du sletter arbejdsområdet, når du ikke længere bruger det.
-
Log ind på Azure-portalen med de Microsoft-legitimationsoplysninger, der er knyttet til dit Azure-abonnement.
-
Vælg +Opret en ressource
Søg efter Machine Learning, og vælg Machine Learning-flisen.
Klik på knappen "Opret".
Udfyld indstillingerne som følger:
- Abonnement: Dit Azure-abonnement
- Ressourcegruppe: Opret eller vælg en ressourcegruppe
- Arbejdsområdenavn: Indtast et unikt navn til dit arbejdsområde
- Region: Vælg den geografiske region, der er tættest på dig
- Lagringskonto: Bemærk den nye standardlagringskonto, der vil blive oprettet til dit arbejdsområde
- Nøglehvælv: Bemærk det nye standardnøglehvælv, der vil blive oprettet til dit arbejdsområde
- Application Insights: Bemærk den nye standard Application Insights-ressource, der vil blive oprettet til dit arbejdsområde
- Containerregister: Ingen (et vil blive oprettet automatisk første gang, du udruller en model til en container)
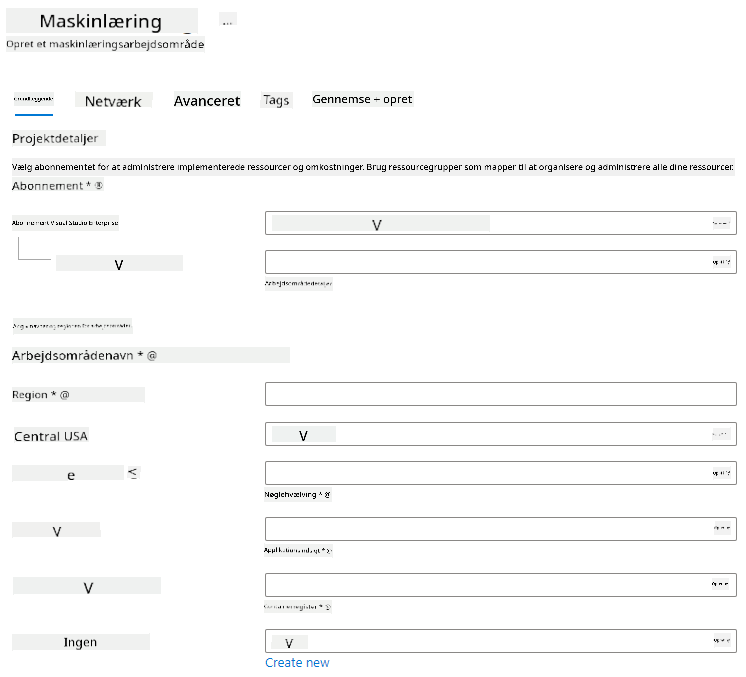
- Klik på "Gennemse + opret", og derefter på knappen "Opret".
-
Vent på, at dit arbejdsområde bliver oprettet (dette kan tage et par minutter). Gå derefter til det i portalen. Du kan finde det via Azure Machine Learning-tjenesten.
-
På oversigtssiden for dit arbejdsområde skal du starte Azure Machine Learning Studio (eller åbne en ny browserfane og navigere til https://ml.azure.com), og logge ind på Azure Machine Learning Studio med din Microsoft-konto. Hvis du bliver bedt om det, skal du vælge din Azure-katalog og dit abonnement samt dit Azure Machine Learning-arbejdsområde.
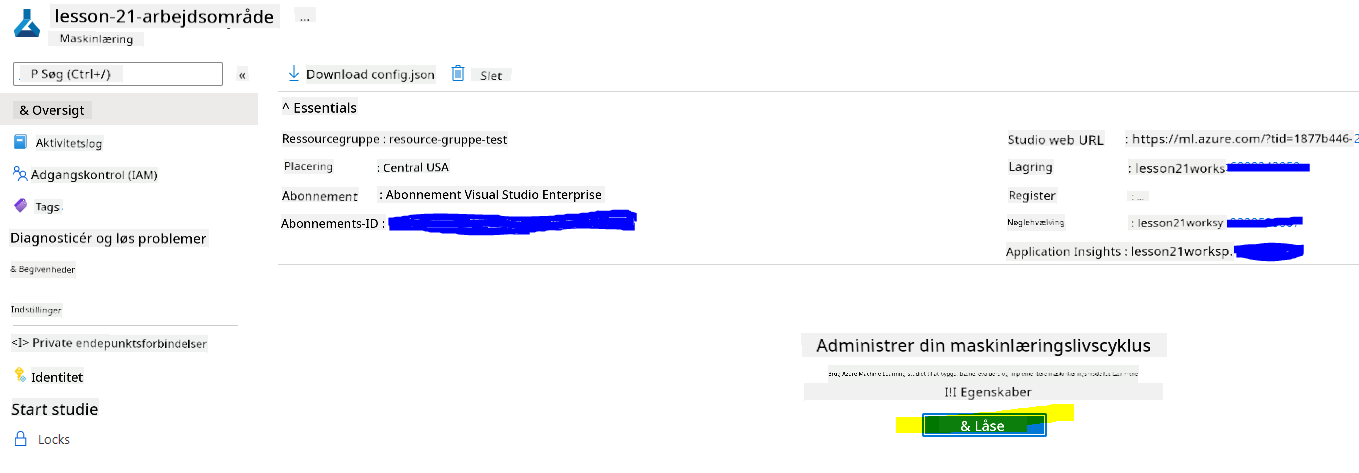
- I Azure Machine Learning Studio skal du skifte ☰-ikonet øverst til venstre for at se de forskellige sider i grænsefladen. Du kan bruge disse sider til at administrere ressourcerne i dit arbejdsområde.
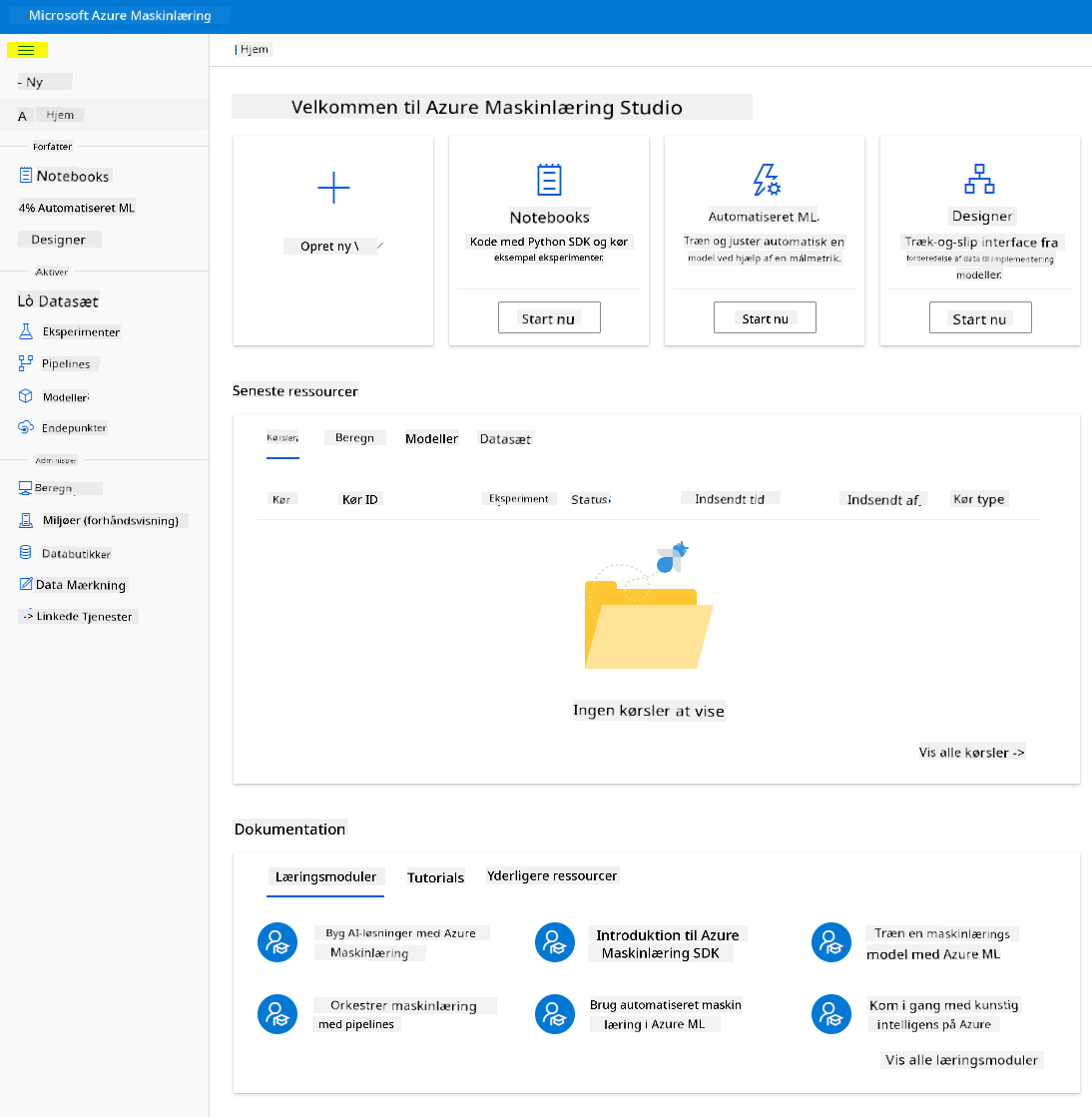
Du kan administrere dit arbejdsområde ved hjælp af Azure-portalen, men for dataspecialister og maskinlæringsingeniører giver Azure Machine Learning Studio en mere fokuseret brugergrænseflade til at administrere arbejdsområderessourcer.
2.2 Compute-ressourcer
Compute-ressourcer er cloud-baserede ressourcer, som du kan bruge til at køre modeltræning og dataudforskningsprocesser. Der er fire typer compute-ressourcer, du kan oprette:
- Compute-instanser: Udviklingsarbejdsstationer, som dataspecialister kan bruge til at arbejde med data og modeller. Dette indebærer oprettelse af en virtuel maskine (VM) og start af en notebook-instans. Du kan derefter træne en model ved at kalde en compute-klynge fra notebooken.
- Compute-klynger: Skalerbare klynger af VM'er til on-demand behandling af eksperimentkode. Du vil få brug for det, når du træner en model. Compute-klynger kan også anvende specialiserede GPU- eller CPU-ressourcer.
- Inference-klynger: Udrulningsmål for forudsigelsestjenester, der bruger dine trænet modeller.
- Tilsluttet Compute: Forbinder til eksisterende Azure compute-ressourcer, såsom virtuelle maskiner eller Azure Databricks-klynger.
2.2.1 Valg af de rigtige muligheder for dine compute-ressourcer
Nogle vigtige faktorer skal overvejes, når du opretter en compute-ressource, og disse valg kan være afgørende beslutninger.
Har du brug for CPU eller GPU?
En CPU (Central Processing Unit) er den elektroniske kredsløbsenhed, der udfører instruktioner i et computerprogram. En GPU (Graphics Processing Unit) er et specialiseret elektronisk kredsløb, der kan udføre grafikrelateret kode med meget høj hastighed.
Den primære forskel mellem CPU- og GPU-arkitektur er, at en CPU er designet til hurtigt at håndtere en bred vifte af opgaver (målt ved CPU'ens clockhastighed), men er begrænset i samtidigheden af opgaver, der kan køre. GPU'er er designet til parallel computing og er derfor meget bedre til deep learning-opgaver.
| CPU | GPU |
|---|---|
| Mindre dyr | Mere dyr |
| Lavere niveau af samtidighed | Højere niveau af samtidighed |
| Langsommere til træning af deep learning-modeller | Optimal til deep learning |
Klyngestørrelse
Større klynger er dyrere, men vil resultere i bedre responsivitet. Derfor, hvis du har tid, men ikke nok penge, bør du starte med en lille klynge. Omvendt, hvis du har penge, men ikke meget tid, bør du starte med en større klynge.
VM-størrelse
Afhængigt af dine tids- og budgetmæssige begrænsninger kan du variere størrelsen på din RAM, disk, antal kerner og clockhastighed. At øge alle disse parametre vil være dyrere, men vil resultere i bedre ydeevne.
Dedikerede eller lavprioriterede instanser?
En lavprioriteret instans betyder, at den er afbrydelig: Microsoft Azure kan i princippet tage disse ressourcer og tildele dem til en anden opgave, hvilket afbryder et job. En dedikeret instans, eller ikke-afbrydelig, betyder, at jobbet aldrig vil blive afsluttet uden din tilladelse. Dette er endnu en overvejelse mellem tid og penge, da afbrydelige instanser er billigere end dedikerede.
2.2.2 Oprettelse af en compute-klynge
I Azure ML-arbejdsområdet, som vi oprettede tidligere, skal du gå til Compute, og du vil kunne se de forskellige compute-ressourcer, vi lige har diskuteret (dvs. compute-instanser, compute-klynger, inferensklynger og tilsluttet compute). Til dette projekt skal vi bruge en compute-klynge til modeltræning. I Studio skal du klikke på menuen "Compute", derefter fanen "Compute cluster" og klikke på knappen "+ New" for at oprette en compute-klynge.
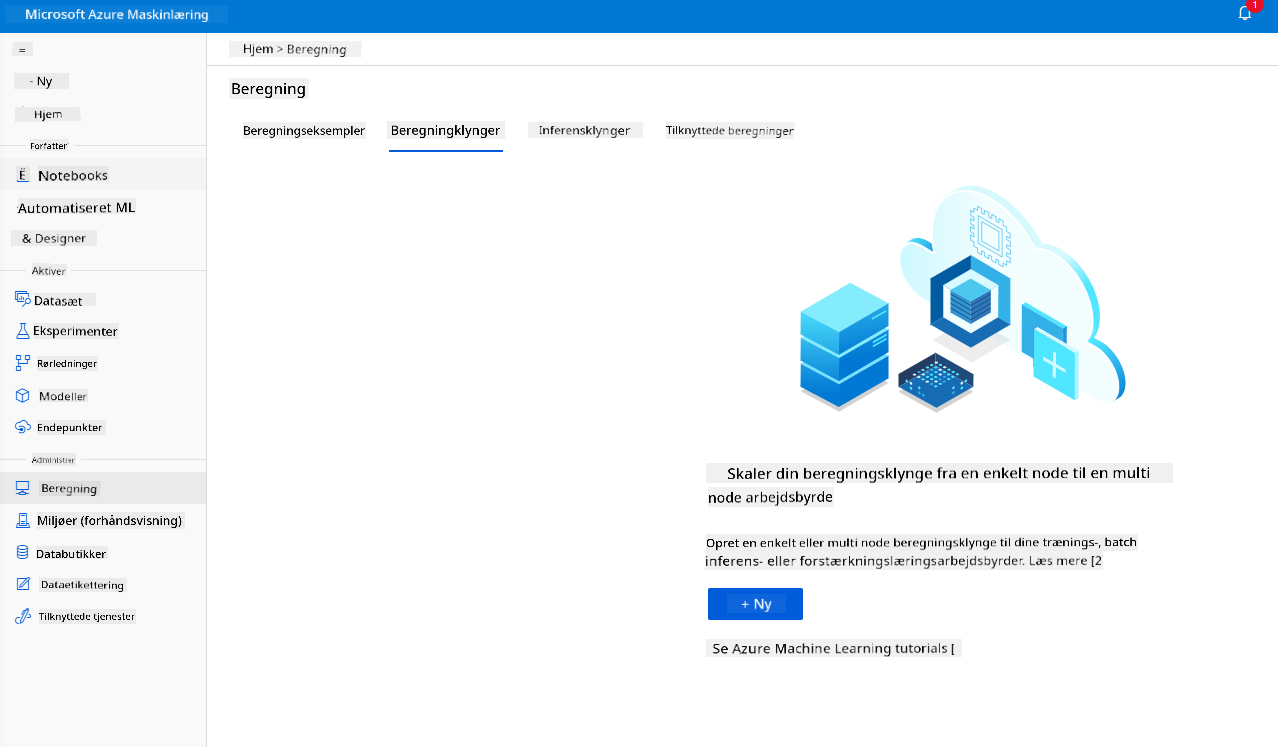
- Vælg dine muligheder: Dedikeret vs Lav prioritet, CPU eller GPU, VM-størrelse og antal kerner (du kan beholde standardindstillingerne for dette projekt).
- Klik på knappen Næste.
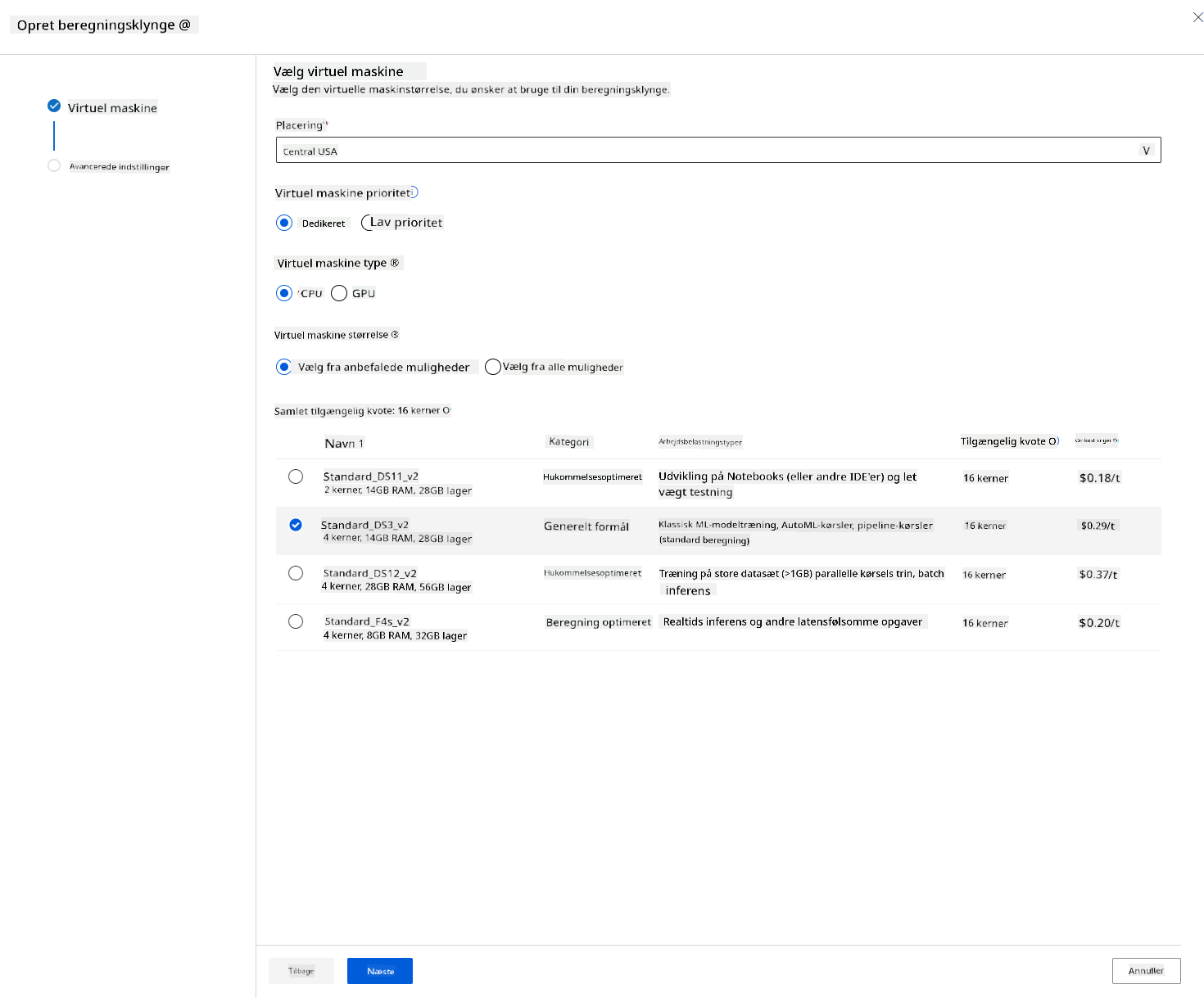
- Giv klyngen et computenavn.
- Vælg dine muligheder: Minimum/maksimum antal noder, inaktive sekunder før nedskalering, SSH-adgang. Bemærk, at hvis minimumsantallet af noder er 0, sparer du penge, når klyngen er inaktiv. Bemærk, at jo højere antallet af maksimale noder er, jo kortere vil træningen være. Det anbefalede maksimale antal noder er 3.
- Klik på knappen "Create". Dette trin kan tage et par minutter.
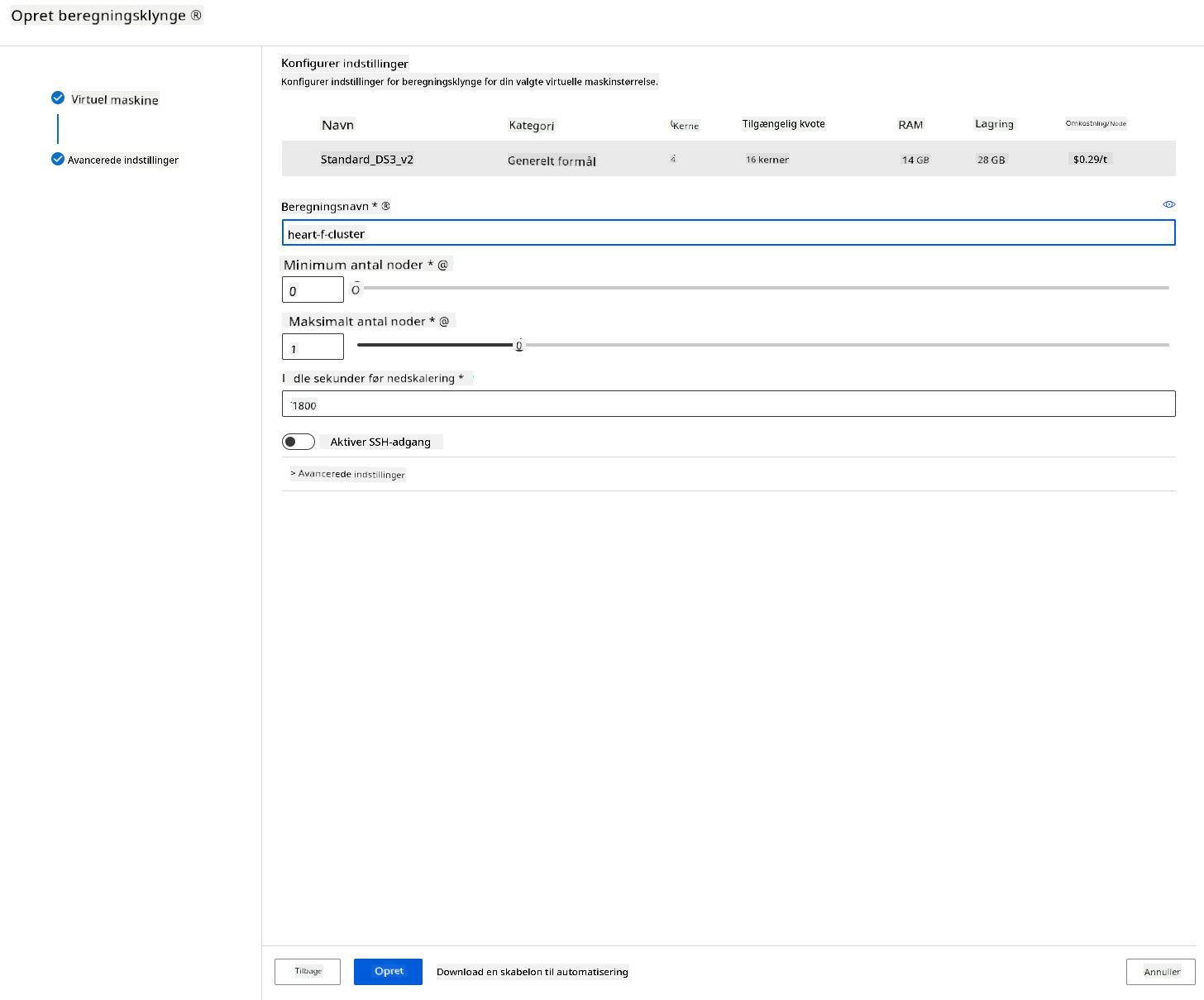
Fantastisk! Nu hvor vi har en compute-klynge, skal vi indlæse dataene i Azure ML Studio.
2.3 Indlæsning af datasættet
-
I Azure ML-arbejdsområdet, som vi oprettede tidligere, skal du klikke på "Datasets" i venstre menu og klikke på knappen "+ Create dataset" for at oprette et datasæt. Vælg muligheden "From local files" og vælg det Kaggle-datasæt, vi downloadede tidligere.
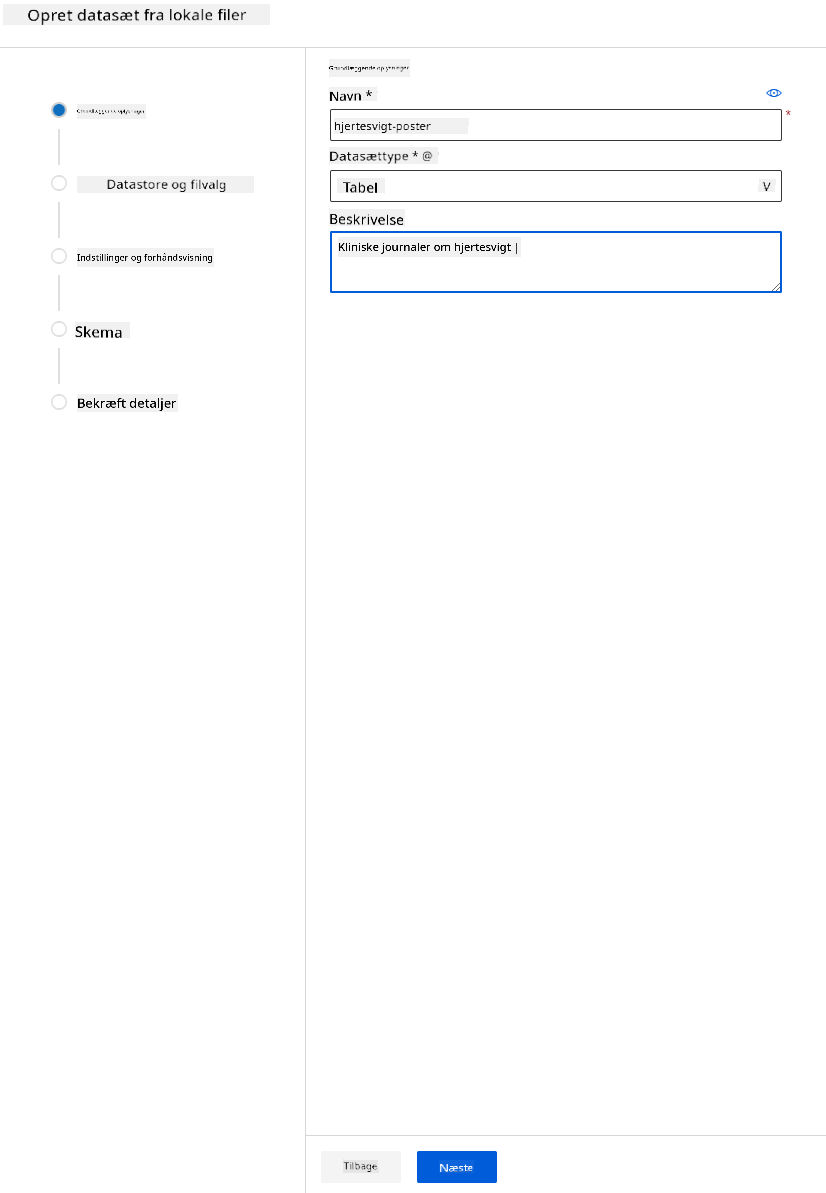
-
Giv dit datasæt et navn, en type og en beskrivelse. Klik på Næste. Upload dataene fra filer. Klik på Næste.
-
I skemaet skal du ændre datatype til Boolean for følgende funktioner: anaemia, diabetes, high blood pressure, sex, smoking og DEATH_EVENT. Klik på Næste og derefter Opret.
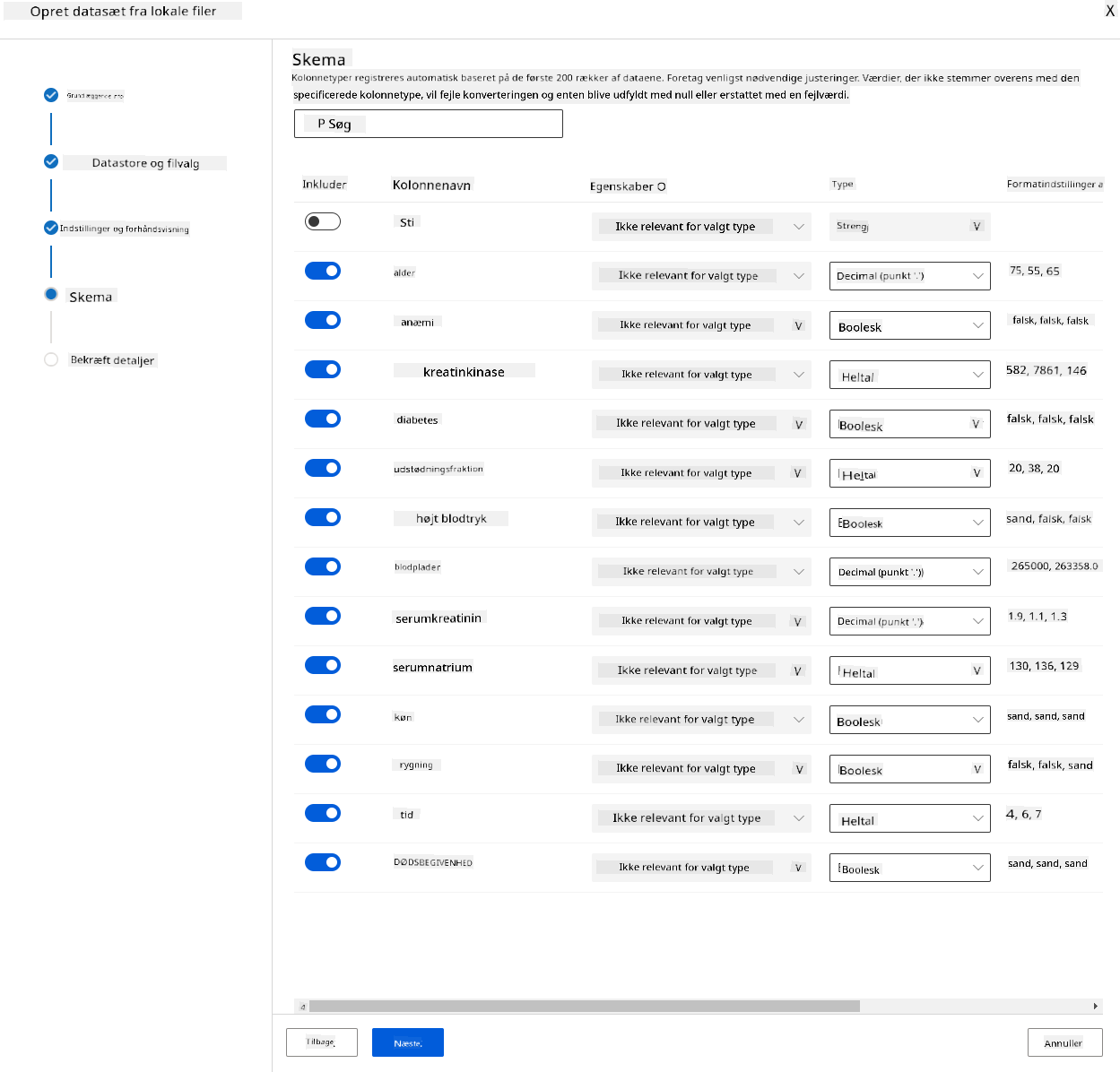
Fremragende! Nu hvor datasættet er på plads, og compute-klyngen er oprettet, kan vi begynde træningen af modellen!
2.4 Lavkode/Ingen kode-træning med AutoML
Traditionel udvikling af maskinlæringsmodeller er ressourcekrævende, kræver betydelig domæneviden og tid til at producere og sammenligne dusinvis af modeller.
Automatiseret maskinlæring (AutoML) er processen med at automatisere de tidskrævende, iterative opgaver i udviklingen af maskinlæringsmodeller. Det giver dataforskere, analytikere og udviklere mulighed for at bygge ML-modeller med høj skala, effektivitet og produktivitet, samtidig med at modelkvaliteten opretholdes. Det reducerer den tid, det tager at få produktionsklare ML-modeller, med stor lethed og effektivitet. Læs mere
-
I Azure ML-arbejdsområdet, som vi oprettede tidligere, skal du klikke på "Automated ML" i venstre menu og vælge det datasæt, du lige har uploadet. Klik på Næste.
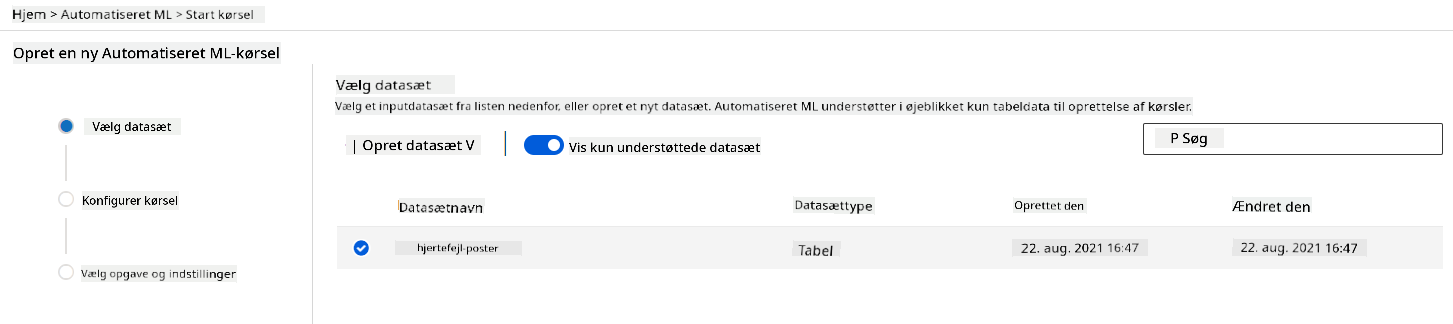
-
Indtast et nyt eksperimentnavn, målsøjlen (DEATH_EVENT) og den compute-klynge, vi oprettede. Klik på Næste.
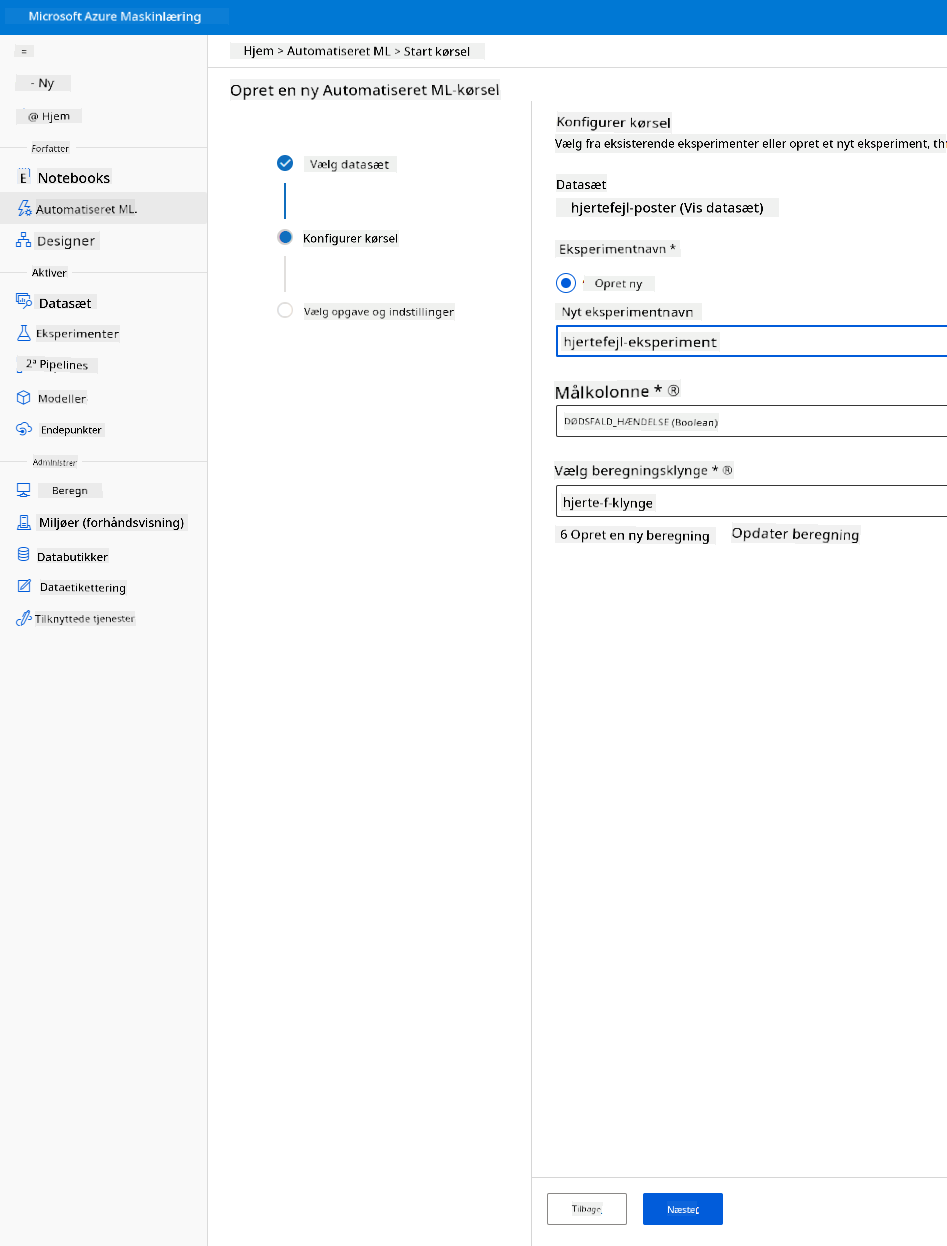
-
Vælg "Classification" og klik på Finish. Dette trin kan tage mellem 30 minutter og 1 time, afhængigt af størrelsen på din compute-klynge.
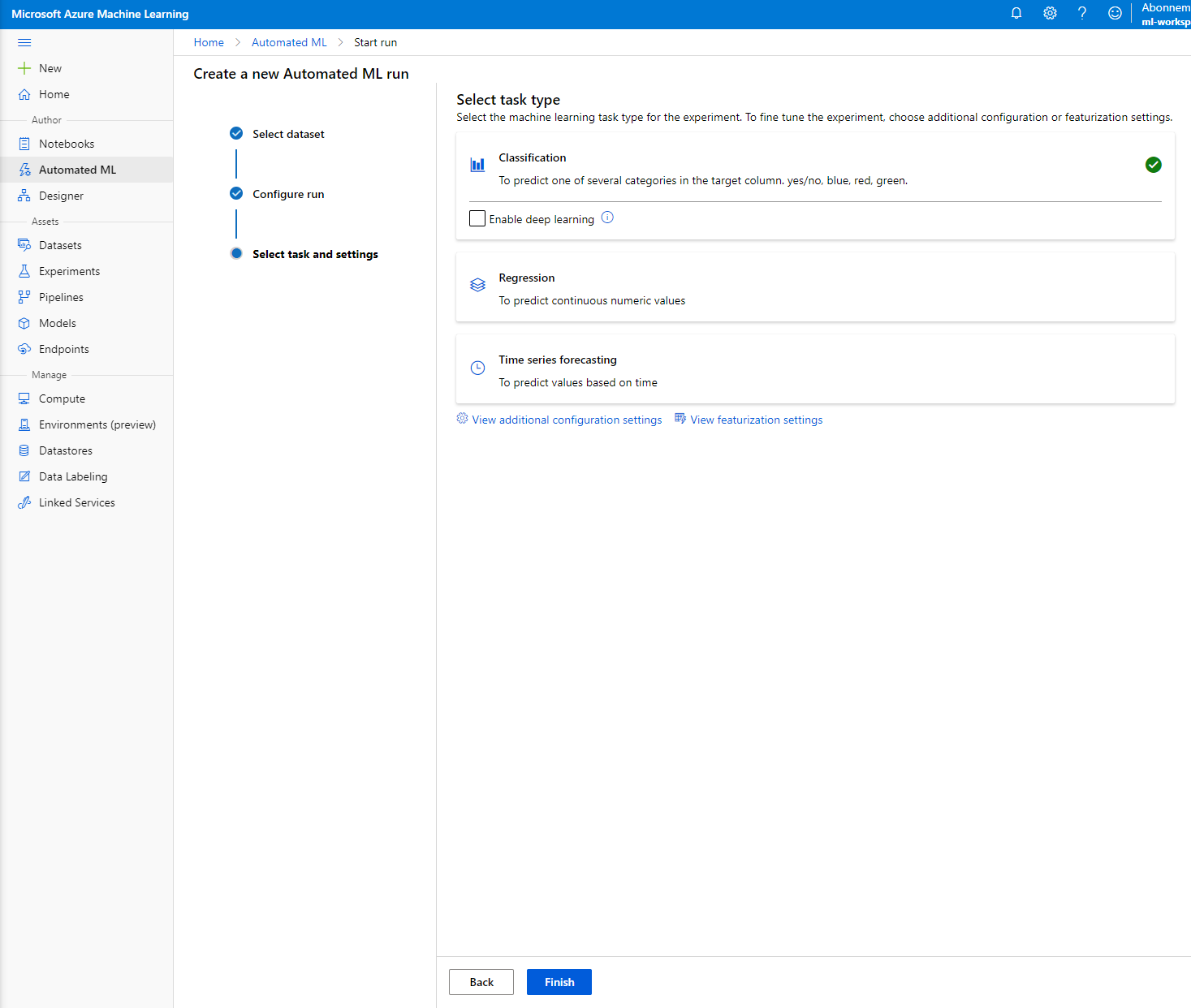
-
Når kørslen er færdig, skal du klikke på fanen "Automated ML", klikke på din kørsel og klikke på algoritmen i kortet "Best model summary".
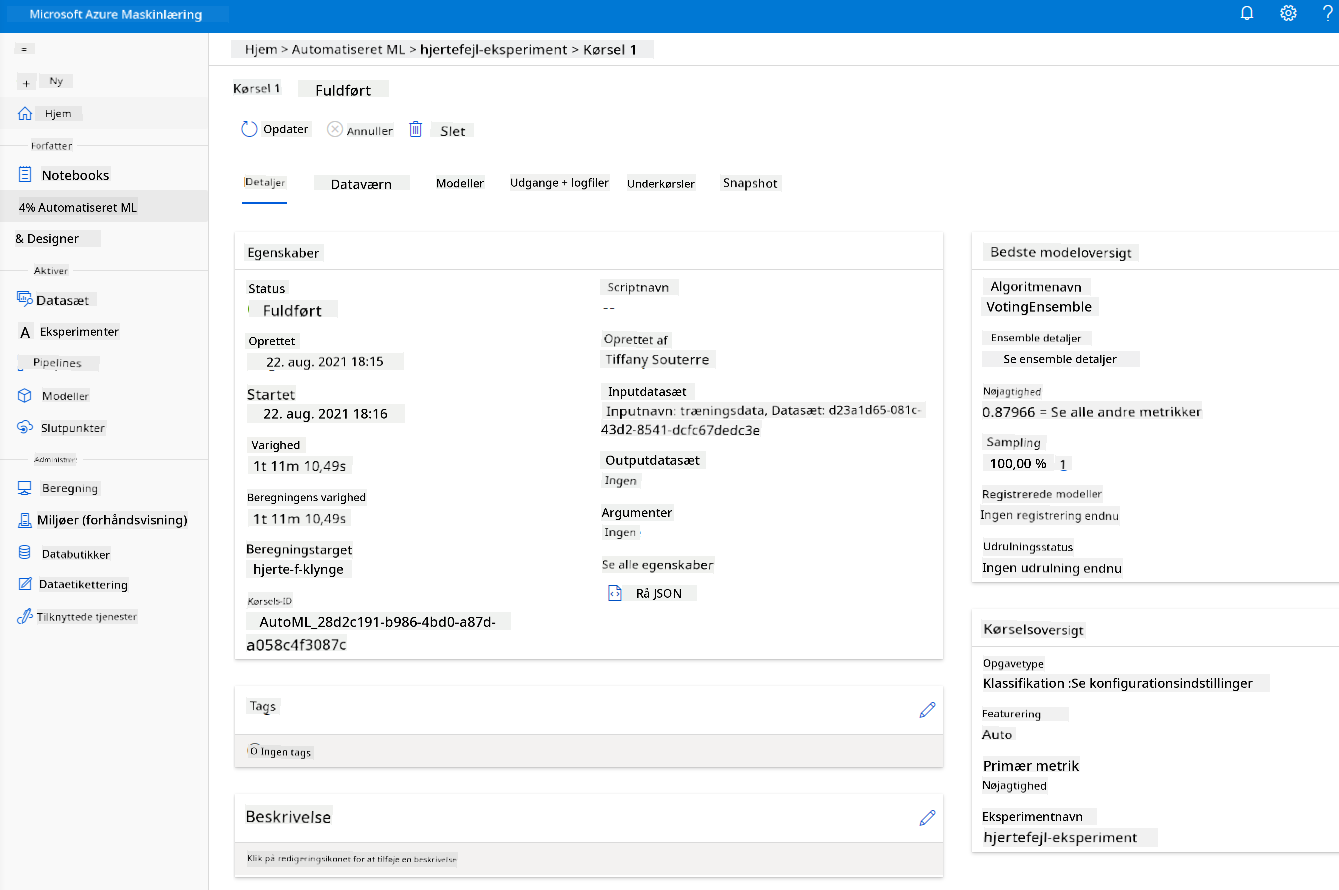
Her kan du se en detaljeret beskrivelse af den bedste model, som AutoML genererede. Du kan også udforske andre modeller, der er genereret, i fanen Models. Brug et par minutter på at udforske modellerne i forklaringerne (preview-knappen). Når du har valgt den model, du vil bruge (her vælger vi den bedste model valgt af AutoML), vil vi se, hvordan vi kan implementere den.
3. Lavkode/Ingen kode-modelimplementering og endpoint-forbrug
3.1 Modelimplementering
Den automatiserede maskinlæringsgrænseflade giver dig mulighed for at implementere den bedste model som en webtjeneste i få trin. Implementering er integrationen af modellen, så den kan lave forudsigelser baseret på nye data og identificere potentielle muligheder. Til dette projekt betyder implementering til en webtjeneste, at medicinske applikationer vil kunne bruge modellen til at lave live-forudsigelser af deres patienters risiko for at få et hjerteanfald.
I beskrivelsen af den bedste model skal du klikke på knappen "Deploy".
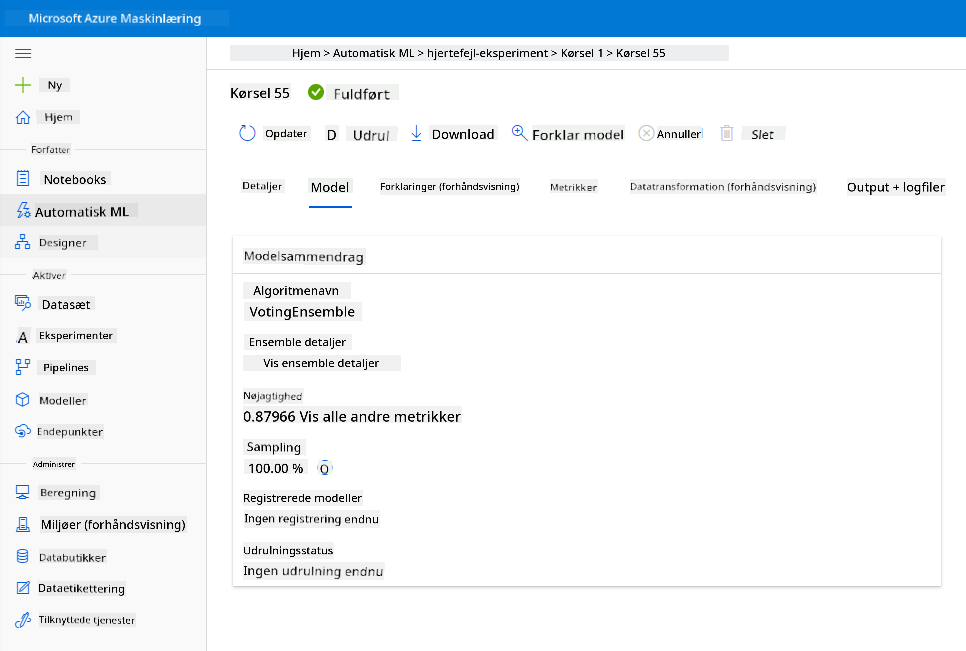
- Giv den et navn, en beskrivelse, computetype (Azure Container Instance), aktiver godkendelse, og klik på Deploy. Dette trin kan tage omkring 20 minutter at fuldføre. Implementeringsprocessen indebærer flere trin, herunder registrering af modellen, generering af ressourcer og konfiguration af dem til webtjenesten. En statusmeddelelse vises under Deploy status. Vælg Opdater periodisk for at kontrollere implementeringsstatus. Den er implementeret og kører, når status er "Healthy".
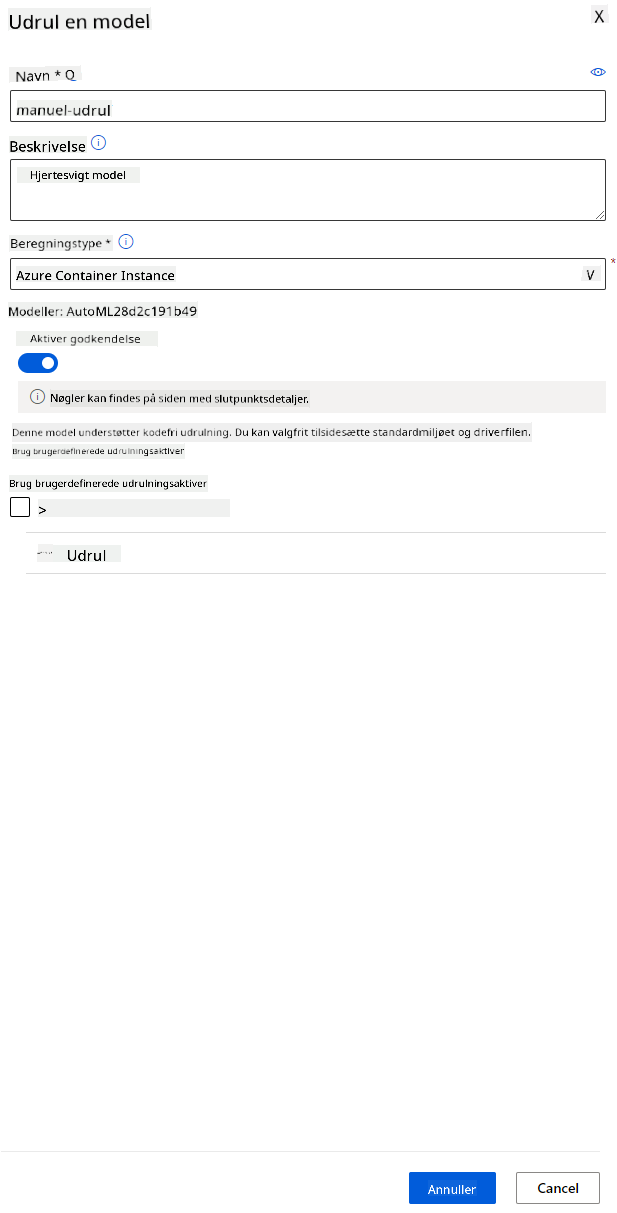
- Når den er implementeret, skal du klikke på fanen Endpoint og klikke på det endpoint, du lige har implementeret. Her kan du finde alle de detaljer, du har brug for at vide om endpointet.
Fantastisk! Nu hvor vi har en model implementeret, kan vi begynde at forbruge endpointet.
3.2 Endpoint-forbrug
Klik på fanen "Consume". Her kan du finde REST-endpointet og et Python-script i forbrugsindstillingen. Tag dig tid til at læse Python-koden.
Dette script kan køres direkte fra din lokale maskine og vil forbruge dit endpoint.
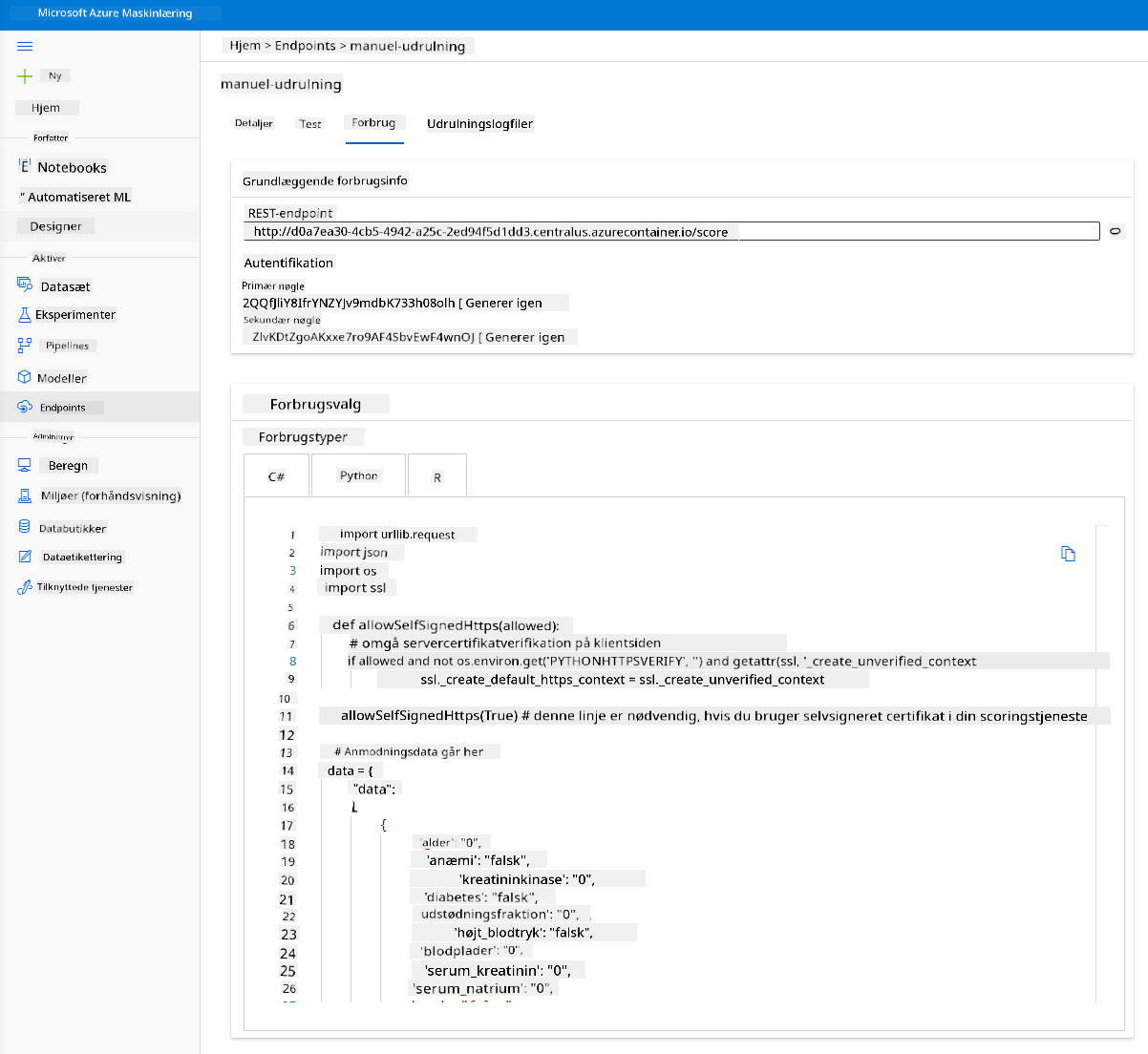
Tag et øjeblik til at tjekke disse 2 linjer kode:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
Variablen url er REST-endpointet, der findes i fanen Consume, og variablen api_key er den primære nøgle, der også findes i fanen Consume (kun hvis du har aktiveret godkendelse). Dette er, hvordan scriptet kan forbruge endpointet.
- Når du kører scriptet, skulle du se følgende output:
b'"{\\"result\\": [true]}"'
Dette betyder, at forudsigelsen af hjertesvigt for de givne data er sand. Dette giver mening, fordi hvis du ser nærmere på de data, der automatisk genereres i scriptet, er alt som standard 0 og falsk. Du kan ændre dataene med følgende inputeksempel:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
Scriptet skulle returnere:
python b'"{\\"result\\": [true, false]}"'
Tillykke! Du har lige forbrugt den implementerede model og trænet den på Azure ML!
NOTE: Når du er færdig med projektet, skal du huske at slette alle ressourcer.
🚀 Udfordring
Se nærmere på model-forklaringerne og detaljerne, som AutoML genererede for de bedste modeller. Prøv at forstå, hvorfor den bedste model er bedre end de andre. Hvilke algoritmer blev sammenlignet? Hvad er forskellene mellem dem? Hvorfor præsterer den bedste bedre i dette tilfælde?
Post-Lecture Quiz
Gennemgang & Selvstudie
I denne lektion lærte du, hvordan man træner, implementerer og forbruger en model til at forudsige risikoen for hjertesvigt på en lavkode/ingen kode-måde i skyen. Hvis du ikke allerede har gjort det, så dyk dybere ned i model-forklaringerne, som AutoML genererede for de bedste modeller, og prøv at forstå, hvorfor den bedste model er bedre end de andre.
Du kan gå videre med lavkode/ingen kode AutoML ved at læse denne dokumentation.
Opgave
Low code/No code Data Science-projekt på Azure ML
Ansvarsfraskrivelse:
Dette dokument er blevet oversat ved hjælp af AI-oversættelsestjenesten Co-op Translator. Selvom vi bestræber os på nøjagtighed, skal du være opmærksom på, at automatiserede oversættelser kan indeholde fejl eller unøjagtigheder. Det originale dokument på dets oprindelige sprog bør betragtes som den autoritative kilde. For kritisk information anbefales professionel menneskelig oversættelse. Vi påtager os ikke ansvar for eventuelle misforståelser eller fejltolkninger, der måtte opstå som følge af brugen af denne oversættelse.