|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Úvod do životního cyklu datové vědy
 |
|---|
| Úvod do životního cyklu datové vědy - Sketchnote od @nitya |
Kvíz před lekcí
V tuto chvíli jste si pravděpodobně uvědomili, že datová věda je proces. Tento proces lze rozdělit do 5 fází:
- Zachycení
- Zpracování
- Analýza
- Komunikace
- Údržba
Tato lekce se zaměřuje na 3 části životního cyklu: zachycení, zpracování a údržbu.
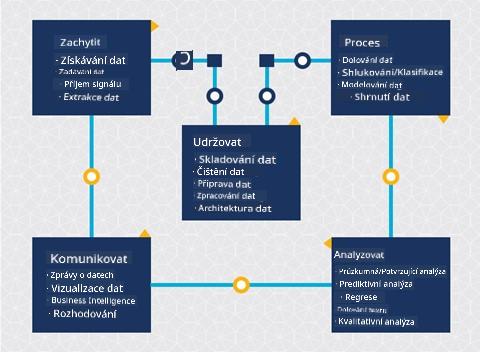
Foto od Berkeley School of Information
Zachycení
První fáze životního cyklu je velmi důležitá, protože na ní závisí všechny další fáze. Prakticky se jedná o dvě fáze spojené do jedné: získávání dat a definování účelu a problémů, které je třeba řešit.
Definování cílů projektu vyžaduje hlubší pochopení problému nebo otázky. Nejprve musíme identifikovat a oslovit ty, kteří potřebují vyřešit svůj problém. Mohou to být zainteresované strany v podniku nebo sponzoři projektu, kteří mohou pomoci určit, kdo nebo co bude mít z projektu prospěch, a také co a proč potřebují. Dobře definovaný cíl by měl být měřitelný a kvantifikovatelný, aby bylo možné stanovit přijatelný výsledek.
Otázky, které si datový vědec může položit:
- Byl tento problém již dříve řešen? Co bylo zjištěno?
- Rozumí všichni zúčastnění účelu a cíli?
- Existuje nejasnost a jak ji snížit?
- Jaké jsou omezení?
- Jak by mohl vypadat konečný výsledek?
- Kolik zdrojů (čas, lidé, výpočetní kapacita) je k dispozici?
Dalším krokem je identifikace, sběr a nakonec prozkoumání dat potřebných k dosažení těchto definovaných cílů. V této fázi získávání musí datoví vědci také zhodnotit množství a kvalitu dat. To vyžaduje určité prozkoumání dat, aby bylo potvrzeno, že získaná data podpoří dosažení požadovaného výsledku.
Otázky, které si datový vědec může položit ohledně dat:
- Jaká data mám již k dispozici?
- Kdo tato data vlastní?
- Jaké jsou obavy ohledně ochrany soukromí?
- Mám dostatek dat k vyřešení tohoto problému?
- Jsou data dostatečně kvalitní pro tento problém?
- Pokud prostřednictvím těchto dat objevím další informace, měli bychom zvážit změnu nebo redefinování cílů?
Zpracování
Fáze zpracování životního cyklu se zaměřuje na objevování vzorců v datech a modelování. Některé techniky používané ve fázi zpracování vyžadují statistické metody k odhalení vzorců. Typicky by to byla zdlouhavá úloha pro člověka při práci s velkým datovým souborem, a proto se spoléháme na počítače, které tento proces urychlí. Tato fáze je také místem, kde se datová věda a strojové učení protínají. Jak jste se dozvěděli v první lekci, strojové učení je proces budování modelů pro pochopení dat. Modely představují vztahy mezi proměnnými v datech, které pomáhají předpovídat výsledky.
Běžné techniky používané v této fázi jsou pokryty v kurikulu ML pro začátečníky. Sledujte odkazy, abyste se o nich dozvěděli více:
- Klasifikace: Organizace dat do kategorií pro efektivnější využití.
- Shlukování: Skupinování dat do podobných skupin.
- Regrese: Určení vztahů mezi proměnnými pro předpověď nebo odhad hodnot.
Údržba
Na diagramu životního cyklu jste si možná všimli, že údržba se nachází mezi zachycením a zpracováním. Údržba je průběžný proces správy, ukládání a zabezpečení dat během celého projektu a měla by být zohledněna po celou dobu trvání projektu.
Ukládání dat
Způsob a místo ukládání dat může ovlivnit náklady na jejich uložení i výkon při jejich přístupu. Taková rozhodnutí pravděpodobně nebudou dělat pouze datoví vědci, ale mohou se ocitnout v situaci, kdy budou muset volit, jak s daty pracovat na základě způsobu jejich uložení.
Zde jsou některé aspekty moderních systémů ukládání dat, které mohou ovlivnit tato rozhodnutí:
On-premise vs off-premise vs veřejný nebo soukromý cloud
On-premise znamená hostování a správu dat na vlastním zařízení, například vlastnění serveru s pevnými disky, které data ukládají, zatímco off-premise spoléhá na zařízení, která nevlastníte, například datové centrum. Veřejný cloud je oblíbenou volbou pro ukládání dat, která nevyžaduje znalost toho, jak nebo kde přesně jsou data uložena, přičemž veřejný odkazuje na jednotnou základní infrastrukturu sdílenou všemi uživateli cloudu. Některé organizace mají přísné bezpečnostní politiky, které vyžadují, aby měly úplný přístup k zařízení, kde jsou data hostována, a spoléhají na soukromý cloud, který poskytuje vlastní cloudové služby. O ukládání dat v cloudu se dozvíte více v pozdějších lekcích.
Studená vs horká data
Při trénování modelů můžete potřebovat více trénovacích dat. Pokud jste spokojeni se svým modelem, budou přicházet další data, aby model mohl plnit svůj účel. V každém případě se náklady na ukládání a přístup k datům zvýší, jakmile jich budete mít více. Oddělení zřídka používaných dat, známých jako studená data, od často přistupovaných horkých dat může být levnější možností ukládání dat prostřednictvím hardwarových nebo softwarových služeb. Pokud je potřeba přistupovat ke studeným datům, může jejich načtení trvat o něco déle ve srovnání s horkými daty.
Správa dat
Při práci s daty můžete zjistit, že některá data je třeba vyčistit pomocí některých technik pokrytých v lekci zaměřené na přípravu dat, aby bylo možné vytvořit přesné modely. Když dorazí nová data, bude třeba aplikovat stejné postupy, aby byla zachována konzistence kvality. Některé projekty budou zahrnovat použití automatizovaného nástroje pro čištění, agregaci a kompresi dat před jejich přesunem na konečné místo. Příkladem jednoho z těchto nástrojů je Azure Data Factory.
Zabezpečení dat
Jedním z hlavních cílů zabezpečení dat je zajistit, aby ti, kdo s nimi pracují, měli kontrolu nad tím, co je shromažďováno a v jakém kontextu je to používáno. Udržování dat v bezpečí zahrnuje omezení přístupu pouze na ty, kteří jej potřebují, dodržování místních zákonů a předpisů a udržování etických standardů, jak je popsáno v lekci o etice.
Zde je několik věcí, které může tým dělat s ohledem na bezpečnost:
- Ověřit, že všechna data jsou šifrována
- Poskytnout zákazníkům informace o tom, jak jsou jejich data používána
- Odebrat přístup k datům těm, kteří projekt opustili
- Povolit pouze určitým členům projektu měnit data
🚀 Výzva
Existuje mnoho verzí životního cyklu datové vědy, kde každý krok může mít jiný název a počet fází, ale obsahuje stejné procesy zmíněné v této lekci.
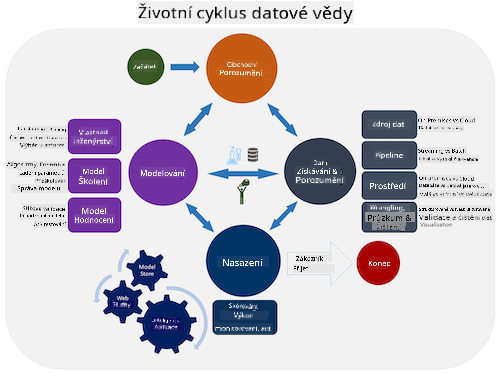
Prozkoumejte životní cyklus procesu týmové datové vědy a průmyslový standardní proces pro dolování dat. Uveďte 3 podobnosti a rozdíly mezi nimi.
| Proces týmové datové vědy (TDSP) | Průmyslový standardní proces pro dolování dat (CRISP-DM) |
|---|---|
 |
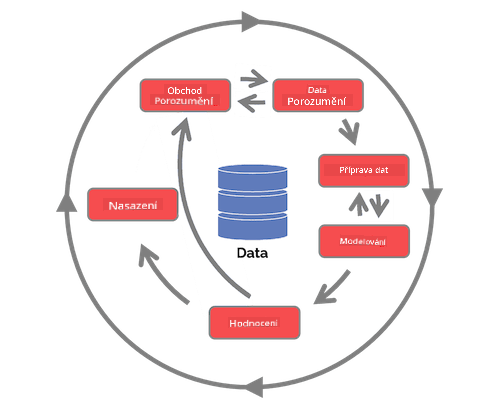 |
| Obrázek od Microsoft | Obrázek od Data Science Process Alliance |
Kvíz po lekci
Přehled a samostudium
Aplikace životního cyklu datové vědy zahrnuje různé role a úkoly, přičemž některé se zaměřují na konkrétní části každé fáze. Proces týmové datové vědy poskytuje několik zdrojů, které vysvětlují typy rolí a úkolů, které může někdo v projektu mít.
- Role a úkoly v procesu týmové datové vědy
- Provádění úkolů datové vědy: průzkum, modelování a nasazení
Zadání
Prohlášení:
Tento dokument byl přeložen pomocí služby pro automatický překlad Co-op Translator. I když se snažíme o přesnost, mějte prosím na paměti, že automatické překlady mohou obsahovat chyby nebo nepřesnosti. Původní dokument v jeho původním jazyce by měl být považován za autoritativní zdroj. Pro důležité informace doporučujeme profesionální lidský překlad. Neodpovídáme za žádná nedorozumění nebo nesprávné interpretace vyplývající z použití tohoto překladu.