|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
ক্লাউডে ডেটা সায়েন্স: "লো কোড/নো কোড" পদ্ধতি
 |
|---|
| ক্লাউডে ডেটা সায়েন্স: লো কোড - Sketchnote by @nitya |
সূচিপত্র:
- ক্লাউডে ডেটা সায়েন্স: "লো কোড/নো কোড" পদ্ধতি
পূর্ব-লেকচার কুইজ
১. ভূমিকা
১.১ Azure Machine Learning কী?
Azure ক্লাউড প্ল্যাটফর্মে ২০০টিরও বেশি পণ্য এবং ক্লাউড পরিষেবা রয়েছে যা আপনাকে নতুন সমাধান তৈরি করতে সহায়তা করে।
ডেটা বিজ্ঞানীরা ডেটা বিশ্লেষণ এবং প্রি-প্রসেসিং, বিভিন্ন মডেল-ট্রেনিং অ্যালগরিদম পরীক্ষা করার জন্য প্রচুর সময় ব্যয় করেন, যাতে সঠিক মডেল তৈরি করা যায়। এই কাজগুলো সময়সাপেক্ষ এবং প্রায়ই ব্যয়বহুল কম্পিউট হার্ডওয়্যারের অকার্যকর ব্যবহার করে।
Azure ML হলো Azure-এ মেশিন লার্নিং সমাধান তৈরি এবং পরিচালনার জন্য একটি ক্লাউড-ভিত্তিক প্ল্যাটফর্ম। এটি ডেটা প্রস্তুত করা, মডেল ট্রেনিং, প্রেডিক্টিভ সার্ভিস প্রকাশ এবং ব্যবহার পর্যবেক্ষণের জন্য বিস্তৃত বৈশিষ্ট্য এবং সক্ষমতা প্রদান করে। সবচেয়ে গুরুত্বপূর্ণভাবে, এটি মডেল ট্রেনিংয়ের সাথে সম্পর্কিত সময়সাপেক্ষ কাজগুলোকে স্বয়ংক্রিয় করে দক্ষতা বৃদ্ধি করে; এবং এটি ক্লাউড-ভিত্তিক কম্পিউট রিসোর্স ব্যবহার করতে সক্ষম করে, যা বড় ডেটা পরিচালনা করতে কার্যকরভাবে স্কেল করে এবং শুধুমাত্র ব্যবহারের সময় খরচ করে।
Azure ML ডেভেলপার এবং ডেটা বিজ্ঞানীদের মেশিন লার্নিং ওয়ার্কফ্লো পরিচালনার জন্য প্রয়োজনীয় সমস্ত টুল সরবরাহ করে। এর মধ্যে রয়েছে:
- Azure Machine Learning Studio: এটি একটি ওয়েব পোর্টাল যা মডেল ট্রেনিং, ডিপ্লয়মেন্ট, অটোমেশন, ট্র্যাকিং এবং অ্যাসেট ম্যানেজমেন্টের জন্য লো-কোড এবং নো-কোড অপশন প্রদান করে। এটি Azure Machine Learning SDK-এর সাথে ইন্টিগ্রেটেড।
- Jupyter Notebooks: দ্রুত প্রোটোটাইপ এবং মডেল পরীক্ষা করার জন্য।
- Azure Machine Learning Designer: ড্র্যাগ-এন্ড-ড্রপ মডিউল ব্যবহার করে পরীক্ষাগুলো তৈরি এবং লো-কোড পরিবেশে পাইপলাইন ডিপ্লয় করার জন্য।
- Automated machine learning UI (AutoML): মেশিন লার্নিং মডেল ডেভেলপমেন্টের পুনরাবৃত্তিমূলক কাজগুলো স্বয়ংক্রিয় করে, উচ্চ স্কেল, দক্ষতা এবং উৎপাদনশীলতার সাথে মডেল তৈরি করতে সহায়তা করে।
- Data Labelling: একটি সহায়ক ML টুল যা ডেটা স্বয়ংক্রিয়ভাবে লেবেল করতে পারে।
- Machine learning extension for Visual Studio Code: ML প্রকল্প তৈরি এবং পরিচালনার জন্য একটি পূর্ণাঙ্গ ডেভেলপমেন্ট পরিবেশ প্রদান করে।
- Machine learning CLI: কমান্ড লাইন থেকে Azure ML রিসোর্স পরিচালনার জন্য কমান্ড সরবরাহ করে।
- PyTorch, TensorFlow, Scikit-learn এবং আরও অনেক ওপেন-সোর্স ফ্রেমওয়ার্কের সাথে ইন্টিগ্রেশন।
- MLflow: মেশিন লার্নিং পরীক্ষার জীবনচক্র পরিচালনার জন্য একটি ওপেন-সোর্স লাইব্রেরি। MLFlow Tracking আপনার ট্রেনিং রান মেট্রিক এবং মডেল আর্টিফ্যাক্ট লগ এবং ট্র্যাক করে।
১.২ হার্ট ফেইলিউর প্রেডিকশন প্রকল্প:
প্রকল্প তৈরি এবং তৈরি করা দক্ষতা এবং জ্ঞান পরীক্ষা করার সেরা উপায়। এই পাঠে, আমরা Azure ML Studio-তে হার্ট ফেইলিউর আক্রমণের প্রেডিকশন প্রকল্প তৈরি করার দুটি ভিন্ন পদ্ধতি অন্বেষণ করব: লো কোড/নো কোড এবং Azure ML SDK ব্যবহার করে। নিচের স্কিমায় দেখানো হয়েছে:
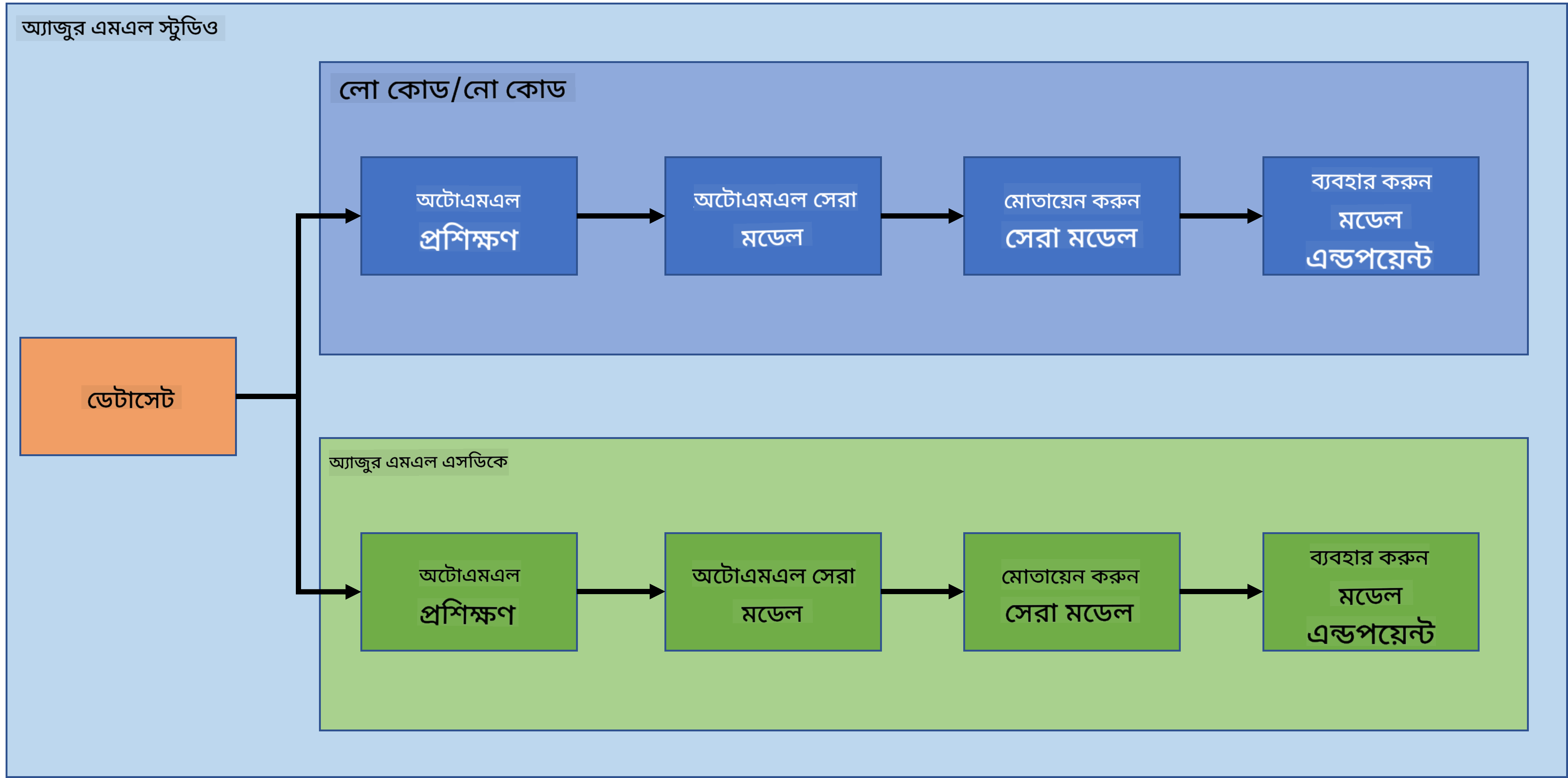
প্রতিটি পদ্ধতির নিজস্ব সুবিধা এবং অসুবিধা রয়েছে। লো কোড/নো কোড পদ্ধতি শুরু করার জন্য সহজ, কারণ এটি GUI (গ্রাফিকাল ইউজার ইন্টারফেস) ব্যবহার করে এবং কোডের পূর্ব জ্ঞান প্রয়োজন হয় না। এই পদ্ধতি প্রকল্পের কার্যকারিতা দ্রুত পরীক্ষা করতে এবং POC (প্রুফ অফ কনসেপ্ট) তৈরি করতে সহায়তা করে। তবে, প্রকল্প বড় হলে এবং প্রোডাকশন-রেডি করতে হলে GUI ব্যবহার করে রিসোর্স তৈরি করা সম্ভব নয়। তখন প্রোগ্রাম্যাটিকভাবে সবকিছু অটোমেট করতে হবে, যেমন রিসোর্স তৈরি থেকে মডেল ডিপ্লয়মেন্ট পর্যন্ত। এই ক্ষেত্রে Azure ML SDK ব্যবহার করার দক্ষতা গুরুত্বপূর্ণ হয়ে ওঠে।
| লো কোড/নো কোড | Azure ML SDK | |
|---|---|---|
| কোড দক্ষতা | প্রয়োজন নেই | প্রয়োজন |
| ডেভেলপমেন্ট সময় | দ্রুত এবং সহজ | কোড দক্ষতার উপর নির্ভরশীল |
| প্রোডাকশন-রেডি | না | হ্যাঁ |
১.৩ হার্ট ফেইলিউর ডেটাসেট:
কার্ডিওভাসকুলার রোগ (CVDs) বিশ্বব্যাপী মৃত্যুর প্রধান কারণ, যা বিশ্বব্যাপী মোট মৃত্যুর ৩১% এর জন্য দায়ী। তামাক ব্যবহার, অস্বাস্থ্যকর খাদ্য এবং স্থূলতা, শারীরিক নিষ্ক্রিয়তা এবং অ্যালকোহলের ক্ষতিকর ব্যবহার ইত্যাদি পরিবেশগত এবং আচরণগত ঝুঁকি ফ্যাক্টরগুলো মডেল অনুমানের বৈশিষ্ট্য হিসেবে ব্যবহার করা যেতে পারে। CVD বিকাশের সম্ভাবনা অনুমান করতে পারা উচ্চ ঝুঁকিপূর্ণ ব্যক্তিদের আক্রমণ প্রতিরোধে অত্যন্ত কার্যকর হতে পারে।
Kaggle একটি Heart Failure dataset প্রকাশ করেছে, যা আমরা এই প্রকল্পে ব্যবহার করব। আপনি এখন ডেটাসেটটি ডাউনলোড করতে পারেন। এটি একটি ট্যাবুলার ডেটাসেট, যেখানে ১৩টি কলাম (১২টি বৈশিষ্ট্য এবং ১টি টার্গেট ভেরিয়েবল) এবং ২৯৯টি সারি রয়েছে।
| ভেরিয়েবল নাম | টাইপ | বিবরণ | উদাহরণ | |
|---|---|---|---|---|
| ১ | age | সংখ্যাগত | রোগীর বয়স | ২৫ |
| ২ | anaemia | বুলিয়ান | রক্তকণিকা বা হিমোগ্লোবিনের অভাব | ০ বা ১ |
| ৩ | creatinine_phosphokinase | সংখ্যাগত | রক্তে CPK এনজাইমের মাত্রা | ৫৪২ |
| ৪ | diabetes | বুলিয়ান | রোগীর ডায়াবেটিস আছে কিনা | ০ বা ১ |
| ৫ | ejection_fraction | সংখ্যাগত | প্রতিটি সংকোচনে হৃদয় থেকে রক্ত বের হওয়ার শতাংশ | ৪৫ |
| ৬ | high_blood_pressure | বুলিয়ান | রোগীর উচ্চ রক্তচাপ আছে কিনা | ০ বা ১ |
| ৭ | platelets | সংখ্যাগত | রক্তে প্লেটলেটের পরিমাণ | ১৪৯০০০ |
| ৮ | serum_creatinine | সংখ্যাগত | রক্তে সিরাম ক্রিয়েটিনিনের মাত্রা | ০.৫ |
| ৯ | serum_sodium | সংখ্যাগত | রক্তে সিরাম সোডিয়ামের মাত্রা | জুন |
| ১০ | sex | বুলিয়ান | নারী বা পুরুষ | ০ বা ১ |
| ১১ | smoking | বুলিয়ান | রোগী ধূমপান করেন কিনা | ০ বা ১ |
| ১২ | time | সংখ্যাগত | ফলো-আপ সময়কাল (দিন) | ৪ |
| ---- | --------------------------- | ----------------- | --------------------------------------------------- | ------------------- |
| ২১ | DEATH_EVENT [Target] | বুলিয়ান | ফলো-আপ সময়কালে রোগী মারা যান কিনা | ০ বা ১ |
ডেটাসেটটি পাওয়ার পর, আমরা Azure-এ প্রকল্প শুরু করতে পারি।
২. Azure ML Studio-তে লো কোড/নো কোড মডেল ট্রেনিং
২.১ Azure ML Workspace তৈরি করা
Azure ML-এ মডেল ট্রেনিং করতে প্রথমে একটি Azure ML Workspace তৈরি করতে হবে। Workspace হলো Azure Machine Learning-এর শীর্ষ-স্তরের রিসোর্স, যা আপনি যখন Azure Machine Learning ব্যবহার করেন তখন তৈরি করা সমস্ত আর্টিফ্যাক্ট পরিচালনার জন্য একটি কেন্দ্রীয় স্থান প্রদান করে। Workspace ট্রেনিং রানগুলোর ইতিহাস সংরক্ষণ করে, যার মধ্যে লগ, মেট্রিক, আউটপুট এবং আপনার স্ক্রিপ্টের স্ন্যাপশট অন্তর্ভুক্ত থাকে। এই তথ্য ব্যবহার করে আপনি নির্ধারণ করতে পারেন কোন ট্রেনিং রানটি সেরা মডেল তৈরি করেছে। আরও জানুন
আপনার অপারেটিং সিস্টেমের সাথে সামঞ্জস্যপূর্ণ সর্বাধিক আপডেটেড ব্রাউজার ব্যবহার করার পরামর্শ দেওয়া হয়। নিম্নলিখিত ব্রাউজারগুলো সমর্থিত:
- Microsoft Edge (নতুন Microsoft Edge, সর্বশেষ সংস্করণ। Microsoft Edge legacy নয়)
- Safari (সর্বশেষ সংস্করণ, শুধুমাত্র Mac)
- Chrome (সর্বশেষ সংস্করণ)
- Firefox (সর্বশেষ সংস্করণ)
Azure Machine Learning ব্যবহার করতে, আপনার Azure সাবস্ক্রিপশনে একটি Workspace তৈরি করুন। এরপর এই Workspace ব্যবহার করে ডেটা, কম্পিউট রিসোর্স, কোড, মডেল এবং মেশিন লার্নিং ওয়ার্কলোডের সাথে সম্পর্কিত অন্যান্য আর্টিফ্যাক্ট পরিচালনা করতে পারেন।
নোট: আপনার Azure সাবস্ক্রিপশনে যতক্ষণ Azure Machine Learning Workspace থাকবে, ততক্ষণ ডেটা স্টোরেজের জন্য সামান্য পরিমাণ চার্জ করা হবে। তাই আমরা পরামর্শ দিই যে আপনি যখন Workspace ব্যবহার করছেন না তখন এটি মুছে ফেলুন।
১. Azure পোর্টাল এ Microsoft ক্রেডেনশিয়াল ব্যবহার করে সাইন ইন করুন।
২. +Create a resource নির্বাচন করুন।
Machine Learning অনুসন্ধান করুন এবং Machine Learning টাইল নির্বাচন করুন।
Create বোতামে ক্লিক করুন।
নিচের মতো সেটিংস পূরণ করুন:
- Subscription: আপনার Azure সাবস্ক্রিপশন
- Resource group: একটি রিসোর্স গ্রুপ তৈরি করুন বা নির্বাচন করুন
- Workspace name: আপনার Workspace-এর জন্য একটি ইউনিক নাম দিন
- Region: আপনার নিকটবর্তী ভৌগোলিক অঞ্চল নির্বাচন করুন
- Storage account: Workspace-এর জন্য একটি নতুন স্টোরেজ অ্যাকাউন্ট তৈরি হবে
- Key vault: Workspace-এর জন্য একটি নতুন Key Vault তৈরি হবে
- Application insights: Workspace-এর জন্য একটি নতুন Application Insights রিসোর্স তৈরি হবে
- Container registry: None (প্রথমবার আপনি একটি মডেল কন্টেইনারে ডিপ্লয় করলে এটি স্বয়ংক্রিয়ভাবে তৈরি হবে)

- Create + Review-এ ক্লিক করুন এবং তারপর Create বোতামে ক্লিক করুন।
৩. আপনার Workspace তৈরি হওয়ার জন্য অপেক্ষা করুন (এটি কয়েক মিনিট সময় নিতে পারে)। এরপর পোর্টালে এটি যান। আপনি এটি Machine Learning Azure সার্ভিসের মাধ্যমে খুঁজে পেতে পারেন।
৪. আপনার Workspace-এর Overview পেজে, Azure Machine Learning Studio চালু করুন (অথবা একটি নতুন ব্রাউজার ট্যাবে https://ml.azure.com-এ যান), এবং Microsoft অ্যাকাউন্ট ব্যবহার করে Azure Machine Learning Studio-তে সাইন ইন করুন। যদি প্রম্পট করা হয়, তাহলে আপনার Azure ডিরেক্টরি এবং সাবস্ক্রিপশন, এবং আপনার Azure Machine Learning Workspace নির্বাচন করুন।
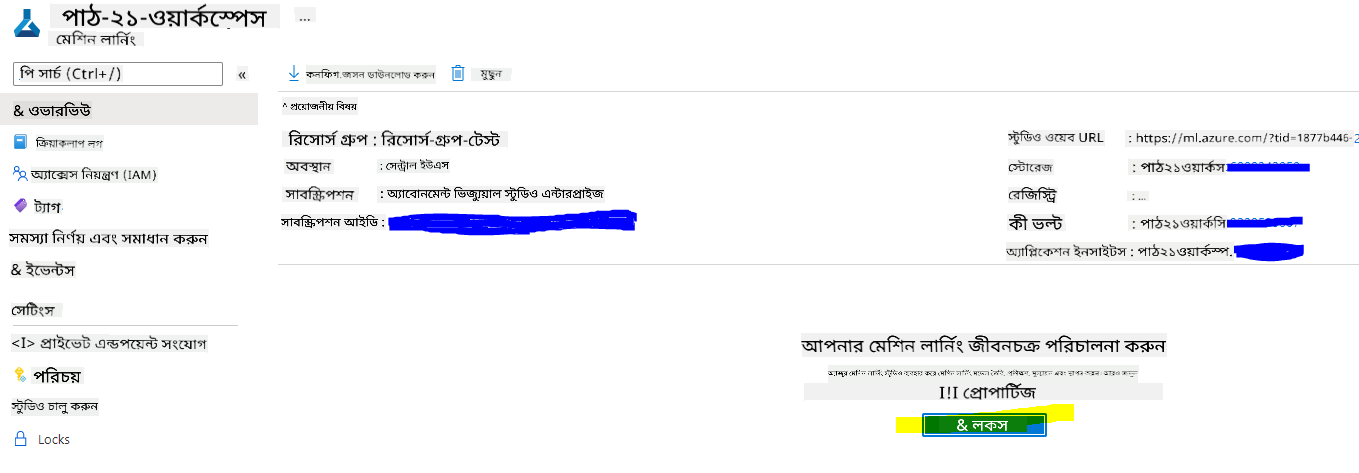
৫. Azure Machine Learning Studio-তে, উপরের বাম দিকে ☰ আইকন টগল করুন যাতে ইন্টারফেসের বিভিন্ন পেজ দেখতে পারেন। আপনি এই পেজগুলো ব্যবহার করে আপনার Workspace-এর রিসোর্সগুলো পরিচালনা করতে পারেন।
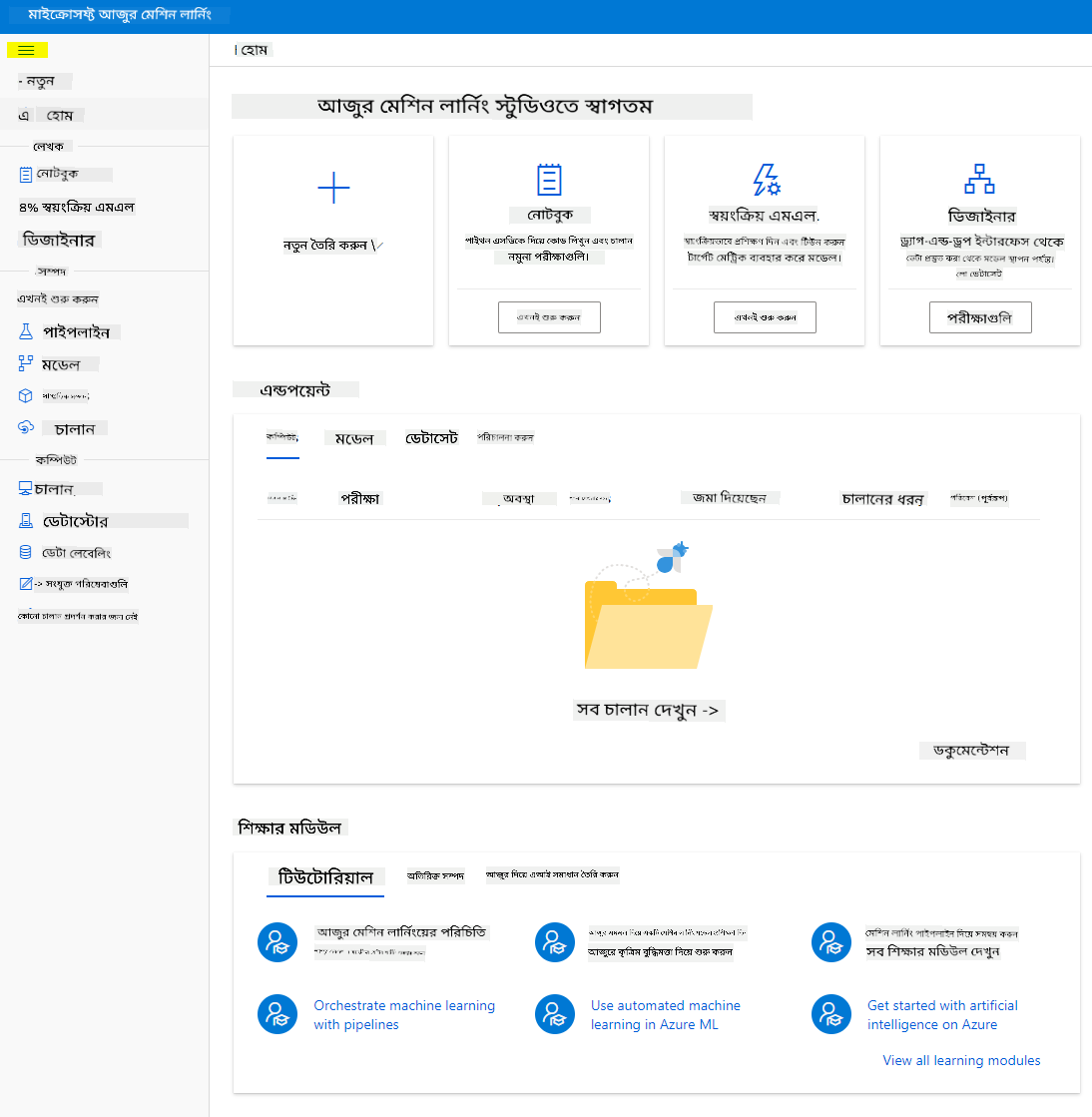
আপনি Azure পোর্টাল ব্যবহার করে আপনার Workspace পরিচালনা করতে পারেন, তবে ডেটা বিজ্ঞানী এবং Machine Learning অপারেশন ইঞ্জিনিয়ারদের জন্য Azure Machine Learning Studio একটি আরও ফোকাসড ইউজার ইন্টারফেস প্রদান করে।
২.২ কম্পিউট রিসোর্স
কম্পিউট রিসোর্স হলো ক্লাউড-ভিত্তিক রিসোর্স, যেখানে আপনি মডেল ট্রেনিং এবং ডেটা এক্সপ্লোরেশন প্রক্রিয়া চালাতে পারেন। চার ধরনের কম্পিউট রিসোর্স তৈরি করা যায়:
- Compute Instances: ডেভেলপমেন্ট ওয়ার্কস্টেশন, যা ডেটা বিজ্ঞানীরা ডেটা এবং মডেলের সাথে কাজ করতে ব্যবহার করতে পারেন। এটি একটি ভার্চুয়াল মেশিন (VM) তৈরি করে এবং একটি নোটবুক ইনস্ট্যান্স চালু করে। এরপর আপনি নোটবুক থেকে একটি কম্পিউট ক্লাস্টার কল করে মডেল ট্রেন করতে পারেন।
- Compute Clusters: স্কেলযোগ্য VM ক্লাস্টার, যা পরীক্ষার কোডের অন-ডিমান্ড প্রসেসিংয়ের জন্য ব্যবহৃত হয়। মডেল ট্রেনিংয়ের সময় এটি প্রয়োজন হয়। Compute Clusters বিশেষ GPU বা CPU রিসোর্সও ব্যবহার করতে পারে।
- Inference Clusters: ডিপ্লয়মেন্ট টার্গেট, যা আপনার ট্রেন করা মডেল ব্যবহার করে প্রেডিক্টিভ সার্ভিস প্রদান করে।
- সংযুক্ত কম্পিউট: বিদ্যমান Azure কম্পিউট রিসোর্সের সাথে সংযোগ স্থাপন করে, যেমন Virtual Machines বা Azure Databricks ক্লাস্টার।
2.2.1 আপনার কম্পিউট রিসোর্সের জন্য সঠিক বিকল্প নির্বাচন করা
কম্পিউট রিসোর্স তৈরি করার সময় কিছু গুরুত্বপূর্ণ বিষয় বিবেচনা করতে হয়, এবং এই সিদ্ধান্তগুলো অত্যন্ত গুরুত্বপূর্ণ হতে পারে।
আপনার কি CPU নাকি GPU প্রয়োজন?
CPU (Central Processing Unit) হলো একটি ইলেকট্রনিক সার্কিট যা কম্পিউটার প্রোগ্রামের নির্দেশাবলী সম্পাদন করে। GPU (Graphics Processing Unit) হলো একটি বিশেষায়িত ইলেকট্রনিক সার্কিট যা গ্রাফিক্স-সম্পর্কিত কোড খুব দ্রুত সম্পাদন করতে পারে।
CPU এবং GPU আর্কিটেকচারের প্রধান পার্থক্য হলো CPU বিভিন্ন কাজ দ্রুত সম্পাদন করার জন্য ডিজাইন করা হয়েছে (যেমন CPU ক্লক স্পিড দ্বারা পরিমাপ করা হয়), তবে এটি একসঙ্গে অনেক কাজ চালানোর ক্ষেত্রে সীমাবদ্ধ। GPU সমান্তরাল কম্পিউটিংয়ের জন্য ডিজাইন করা হয়েছে এবং তাই এটি ডিপ লার্নিং কাজের জন্য অনেক বেশি কার্যকর।
| CPU | GPU |
|---|---|
| কম ব্যয়বহুল | বেশি ব্যয়বহুল |
| কম সমান্তরাল ক্ষমতা | বেশি সমান্তরাল ক্ষমতা |
| ডিপ লার্নিং মডেল প্রশিক্ষণে ধীর | ডিপ লার্নিংয়ের জন্য উপযুক্ত |
ক্লাস্টারের আকার
বড় ক্লাস্টার বেশি ব্যয়বহুল, তবে এটি আরও ভালো প্রতিক্রিয়াশীলতা প্রদান করবে। তাই, যদি আপনার সময় থাকে কিন্তু বাজেট কম থাকে, তাহলে ছোট ক্লাস্টার দিয়ে শুরু করুন। বিপরীতে, যদি আপনার বাজেট থাকে কিন্তু সময় কম থাকে, তাহলে বড় ক্লাস্টার দিয়ে শুরু করুন।
VM আকার
আপনার সময় এবং বাজেটের সীমাবদ্ধতার উপর নির্ভর করে, আপনি RAM, ডিস্ক, কোর সংখ্যা এবং ক্লক স্পিডের আকার পরিবর্তন করতে পারেন। এই সমস্ত প্যারামিটার বাড়ালে খরচ বাড়বে, তবে পারফরম্যান্স উন্নত হবে।
ডেডিকেটেড নাকি লো-প্রায়োরিটি ইনস্ট্যান্স?
লো-প্রায়োরিটি ইনস্ট্যান্স মানে এটি বাধাগ্রস্ত হতে পারে: মূলত, Microsoft Azure এই রিসোর্সগুলো অন্য কাজে ব্যবহার করতে পারে, ফলে একটি কাজ বাধাগ্রস্ত হতে পারে। একটি ডেডিকেটেড ইনস্ট্যান্স, বা নন-ইন্টারাপ্টেবল, মানে কাজটি আপনার অনুমতি ছাড়া কখনো বন্ধ হবে না। এটি আবার সময় বনাম অর্থের একটি বিবেচনা, কারণ লো-প্রায়োরিটি ইনস্ট্যান্স ডেডিকেটেড ইনস্ট্যান্সের তুলনায় কম ব্যয়বহুল।
2.2.2 একটি কম্পিউট ক্লাস্টার তৈরি করা
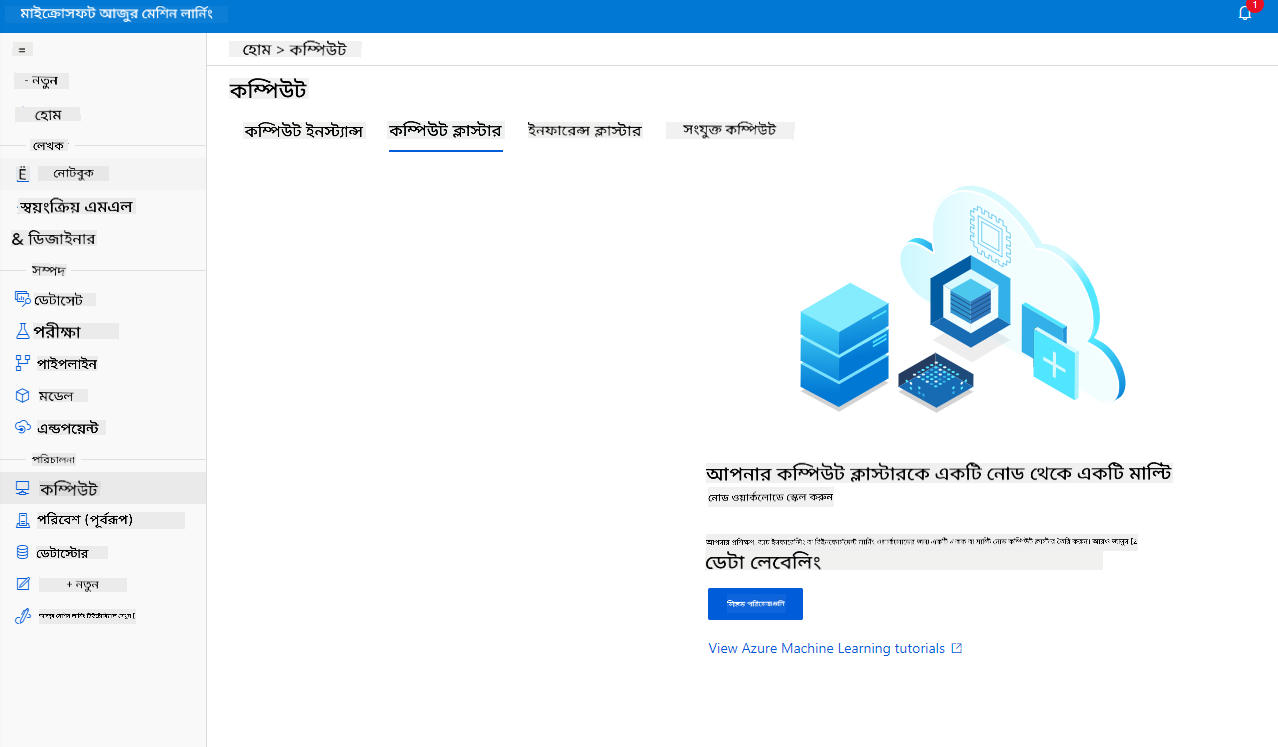
আমরা আগে তৈরি করা Azure ML ওয়ার্কস্পেসে যান, "Compute" এ ক্লিক করুন এবং আপনি বিভিন্ন কম্পিউট রিসোর্স দেখতে পাবেন (যেমন কম্পিউট ইনস্ট্যান্স, কম্পিউট ক্লাস্টার, ইনফারেন্স ক্লাস্টার এবং সংযুক্ত কম্পিউট)। এই প্রকল্পের জন্য, আমাদের মডেল প্রশিক্ষণের জন্য একটি কম্পিউট ক্লাস্টার প্রয়োজন। Studio-তে, "Compute" মেনুতে যান, তারপর "Compute cluster" ট্যাবে ক্লিক করুন এবং "+ New" বোতামে ক্লিক করে একটি কম্পিউট ক্লাস্টার তৈরি করুন।
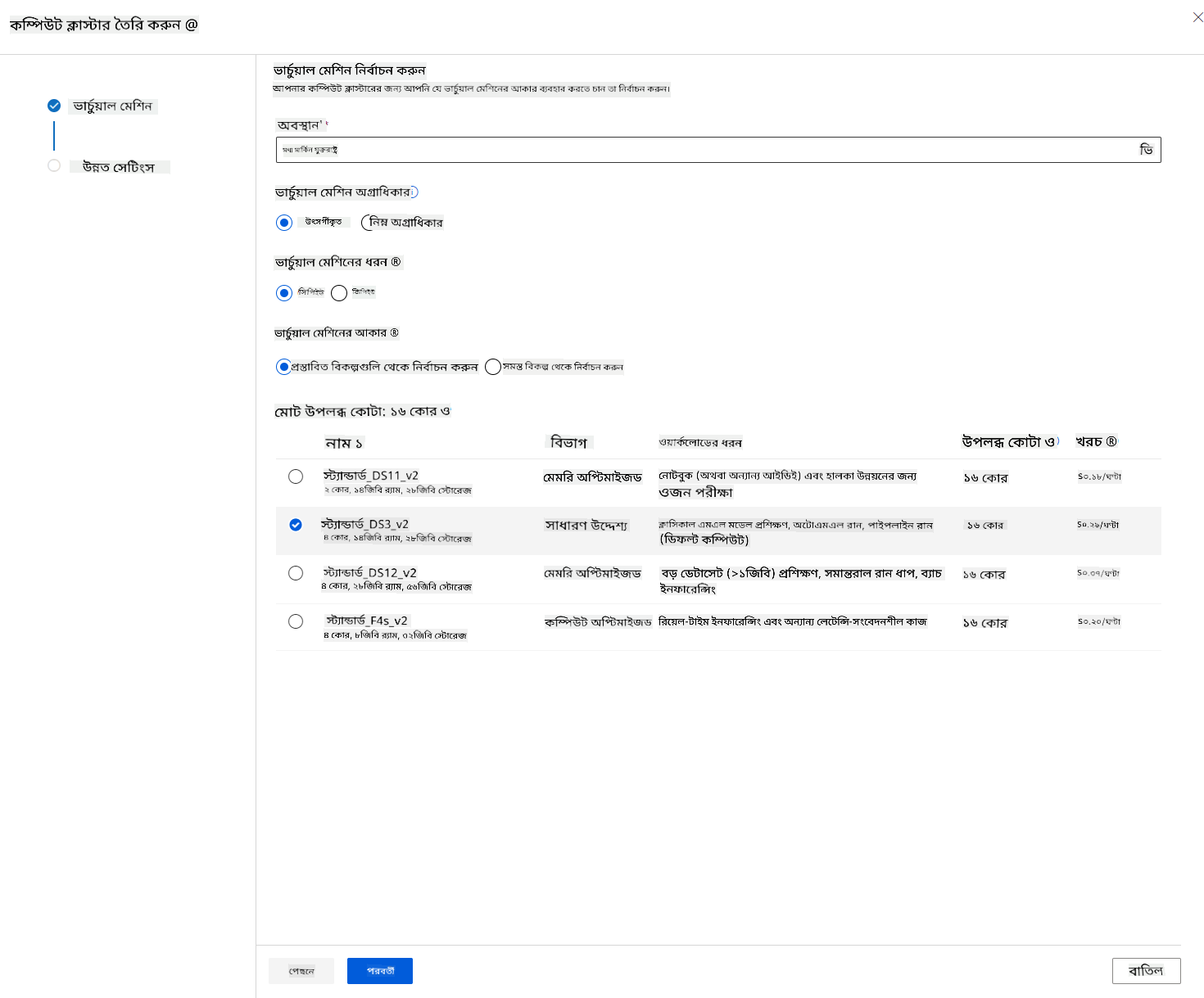
- আপনার বিকল্প নির্বাচন করুন: ডেডিকেটেড বনাম লো-প্রায়োরিটি, CPU বা GPU, VM আকার এবং কোর সংখ্যা (এই প্রকল্পের জন্য ডিফল্ট সেটিংস রাখতে পারেন)।
- "Next" বোতামে ক্লিক করুন।
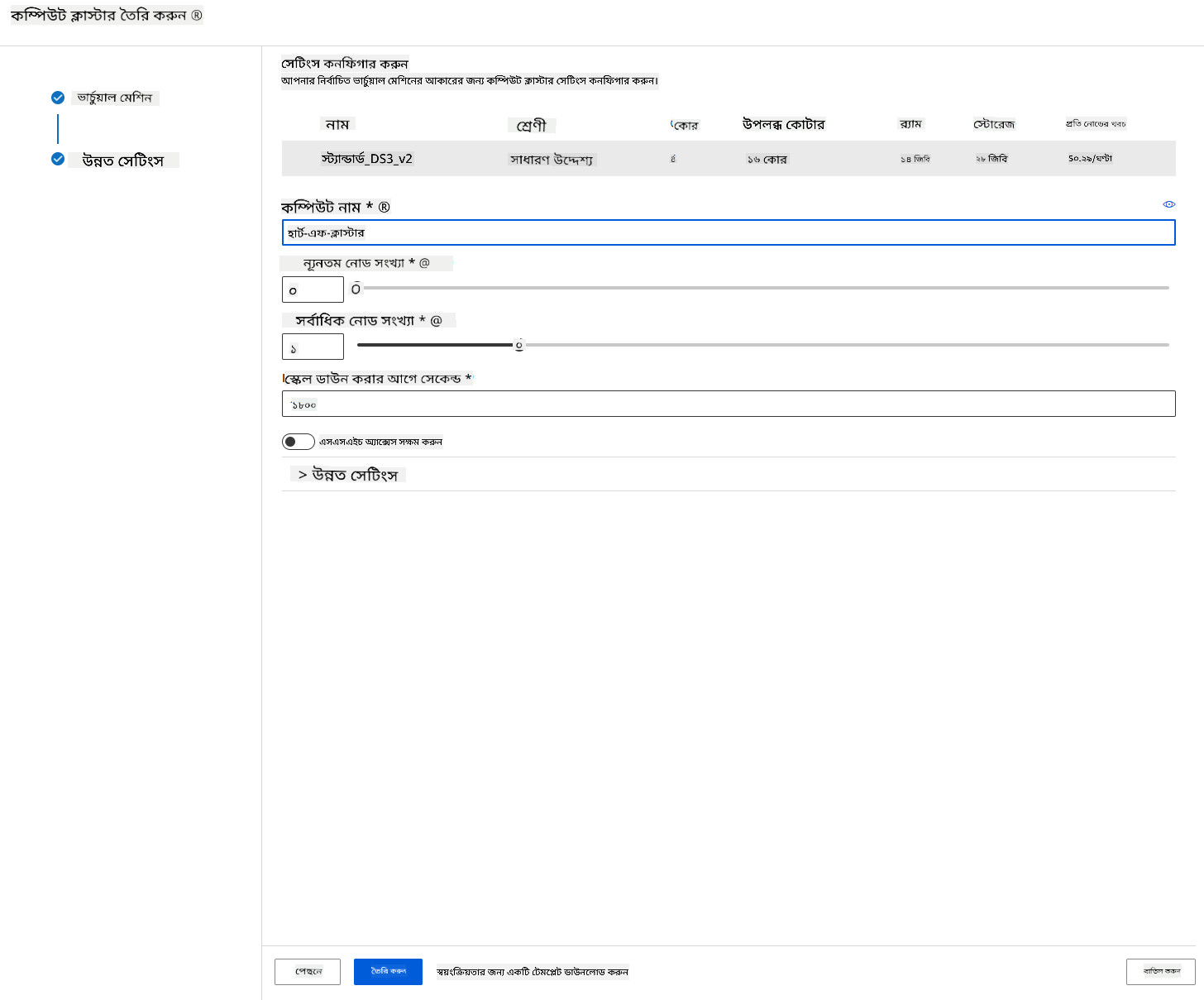
- ক্লাস্টারের জন্য একটি নাম দিন।
- আপনার বিকল্প নির্বাচন করুন: ন্যূনতম/সর্বাধিক নোড সংখ্যা, স্কেল ডাউন করার আগে নিষ্ক্রিয় সেকেন্ড, SSH অ্যাক্সেস। মনে রাখবেন, যদি ন্যূনতম নোড সংখ্যা 0 হয়, তাহলে ক্লাস্টার নিষ্ক্রিয় থাকলে আপনি অর্থ সাশ্রয় করবেন। সর্বাধিক নোড সংখ্যা যত বেশি হবে, প্রশিক্ষণ তত দ্রুত হবে। সর্বাধিক নোড সংখ্যা 3 সুপারিশ করা হয়।
- "Create" বোতামে ক্লিক করুন। এই ধাপটি কয়েক মিনিট সময় নিতে পারে।
অসাধারণ! এখন আমাদের একটি কম্পিউট ক্লাস্টার রয়েছে, আমরা Azure ML Studio-তে ডেটা লোড করতে পারি।
2.3 ডেটাসেট লোড করা
-
আমরা আগে তৈরি করা Azure ML ওয়ার্কস্পেসে যান, বাম মেনুতে "Datasets" এ ক্লিক করুন এবং "+ Create dataset" বোতামে ক্লিক করে একটি ডেটাসেট তৈরি করুন। "From local files" বিকল্পটি নির্বাচন করুন এবং আমরা আগে ডাউনলোড করা Kaggle ডেটাসেটটি নির্বাচন করুন।
-
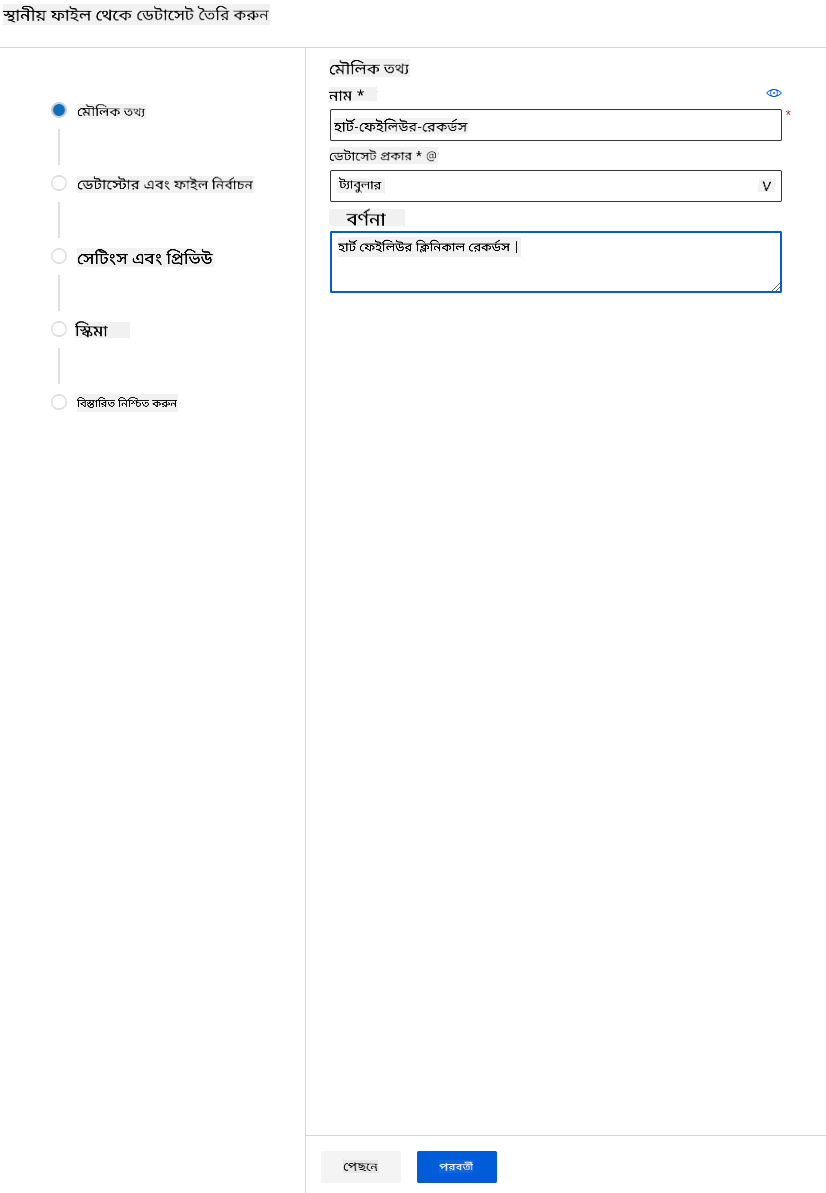
আপনার ডেটাসেটের জন্য একটি নাম, টাইপ এবং বিবরণ দিন। "Next" এ ক্লিক করুন। ফাইল থেকে ডেটা আপলোড করুন। "Next" এ ক্লিক করুন।
-
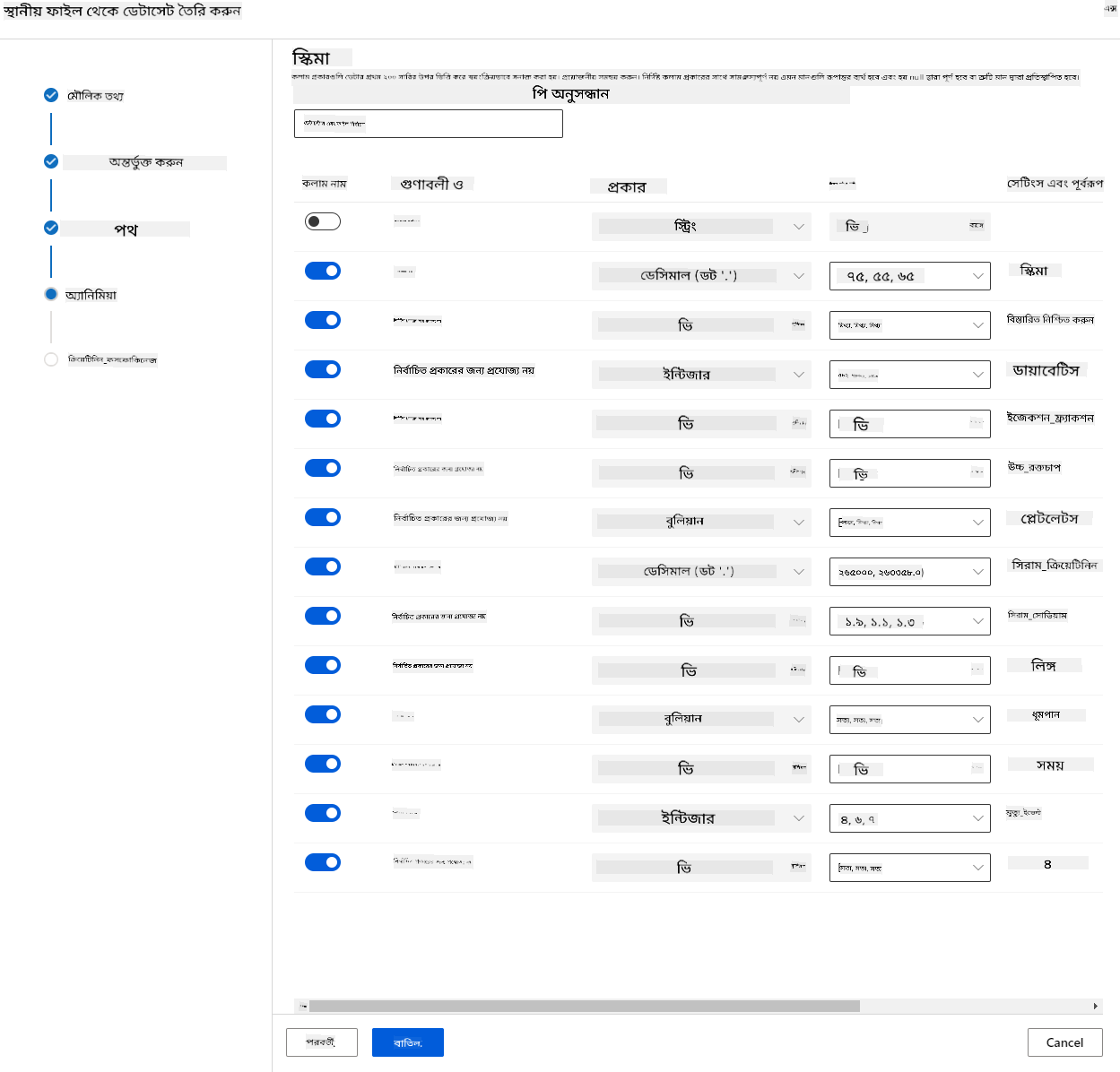
স্কিমায়, নিম্নলিখিত বৈশিষ্ট্যগুলির জন্য ডেটা টাইপ Boolean-এ পরিবর্তন করুন: anaemia, diabetes, high blood pressure, sex, smoking, এবং DEATH_EVENT। "Next" এ ক্লিক করুন এবং "Create" এ ক্লিক করুন।
দারুণ! এখন ডেটাসেট প্রস্তুত এবং কম্পিউট ক্লাস্টার তৈরি হয়েছে, আমরা মডেল প্রশিক্ষণ শুরু করতে পারি!
2.4 লো কোড/নো কোড প্রশিক্ষণ AutoML দিয়ে
প্রথাগত মেশিন লার্নিং মডেল ডেভেলপমেন্ট সময়সাপেক্ষ, উল্লেখযোগ্য ডোমেইন জ্ঞান এবং একাধিক মডেল তৈরি ও তুলনা করার জন্য প্রচুর সময় প্রয়োজন।
Automated Machine Learning (AutoML) হলো মেশিন লার্নিং মডেল ডেভেলপমেন্টের সময়সাপেক্ষ, পুনরাবৃত্তিমূলক কাজগুলো স্বয়ংক্রিয় করার প্রক্রিয়া। এটি ডেটা বিজ্ঞানী, বিশ্লেষক এবং ডেভেলপারদের উচ্চ স্কেল, দক্ষতা এবং উৎপাদনশীলতার সাথে ML মডেল তৈরি করতে সহায়তা করে, মডেলের গুণমান বজায় রেখে। এটি উৎপাদন-প্রস্তুত ML মডেল তৈরি করার সময় কমিয়ে দেয়, সহজে এবং দক্ষতার সাথে। আরও জানুন
-
আমরা আগে তৈরি করা Azure ML ওয়ার্কস্পেসে যান, বাম মেনুতে "Automated ML" এ ক্লিক করুন এবং আপনি যে ডেটাসেটটি আপলোড করেছেন তা নির্বাচন করুন। "Next" এ ক্লিক করুন।
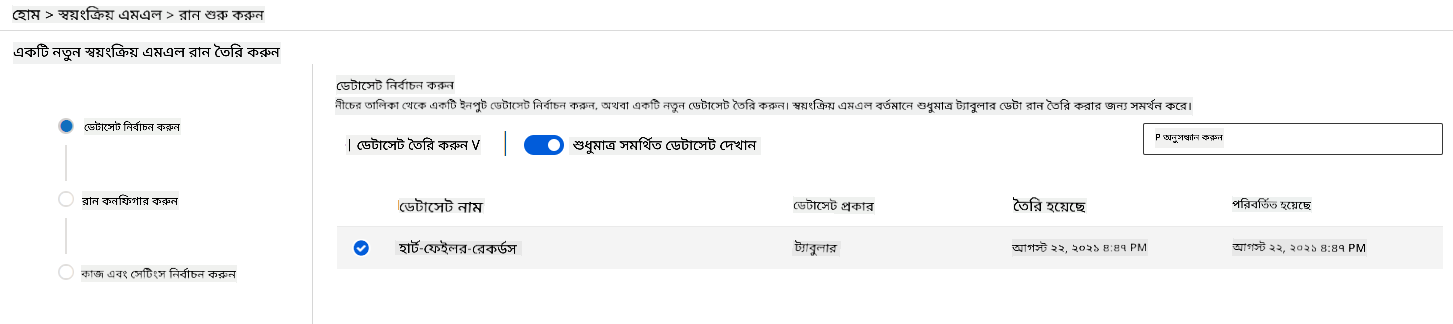
-
একটি নতুন এক্সপেরিমেন্ট নাম, টার্গেট কলাম (DEATH_EVENT) এবং আমরা তৈরি করা কম্পিউট ক্লাস্টারটি প্রবেশ করান। "Next" এ ক্লিক করুন।
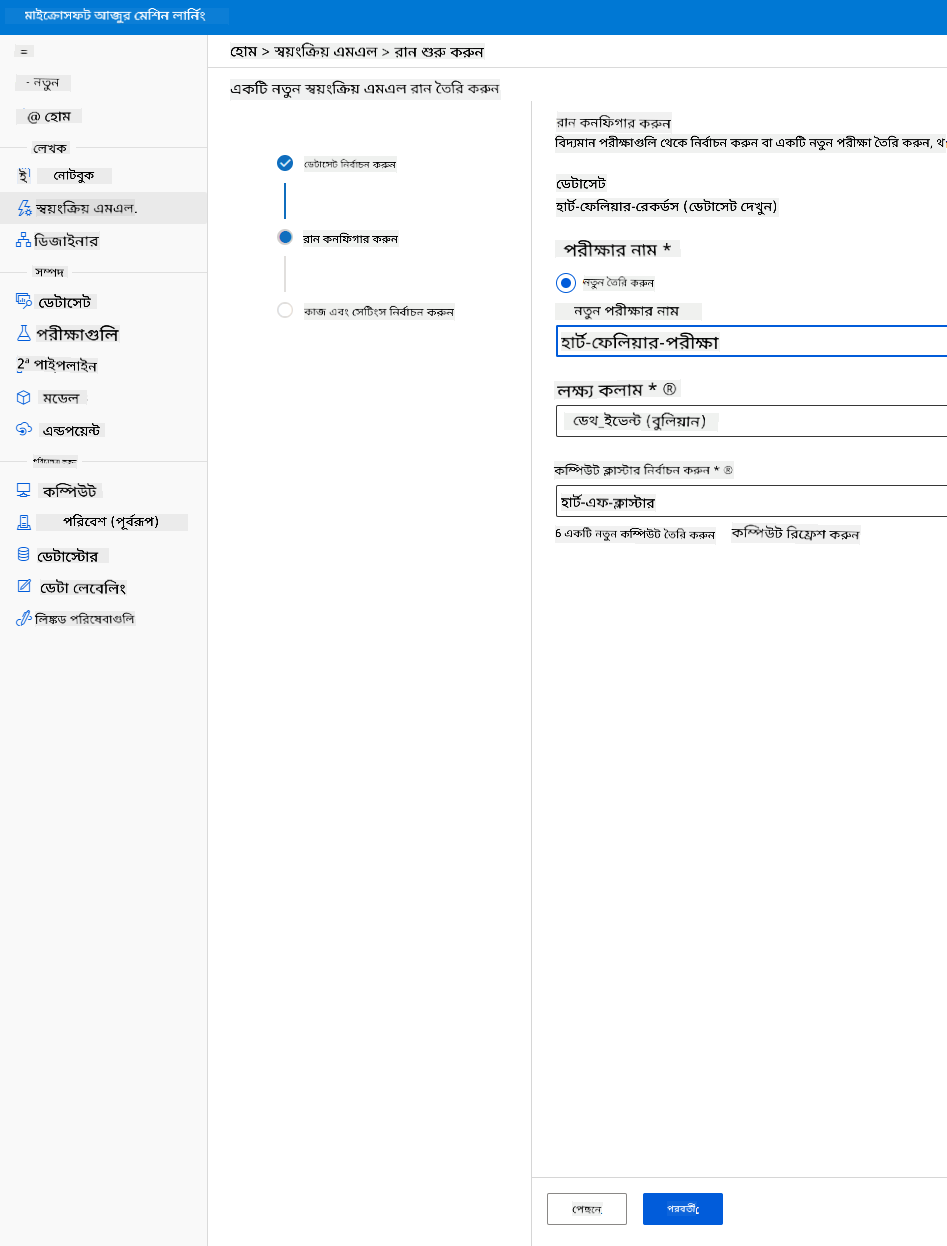
-
"Classification" নির্বাচন করুন এবং "Finish" এ ক্লিক করুন। এই ধাপটি কম্পিউট ক্লাস্টারের আকারের উপর নির্ভর করে ৩০ মিনিট থেকে ১ ঘণ্টা সময় নিতে পারে।
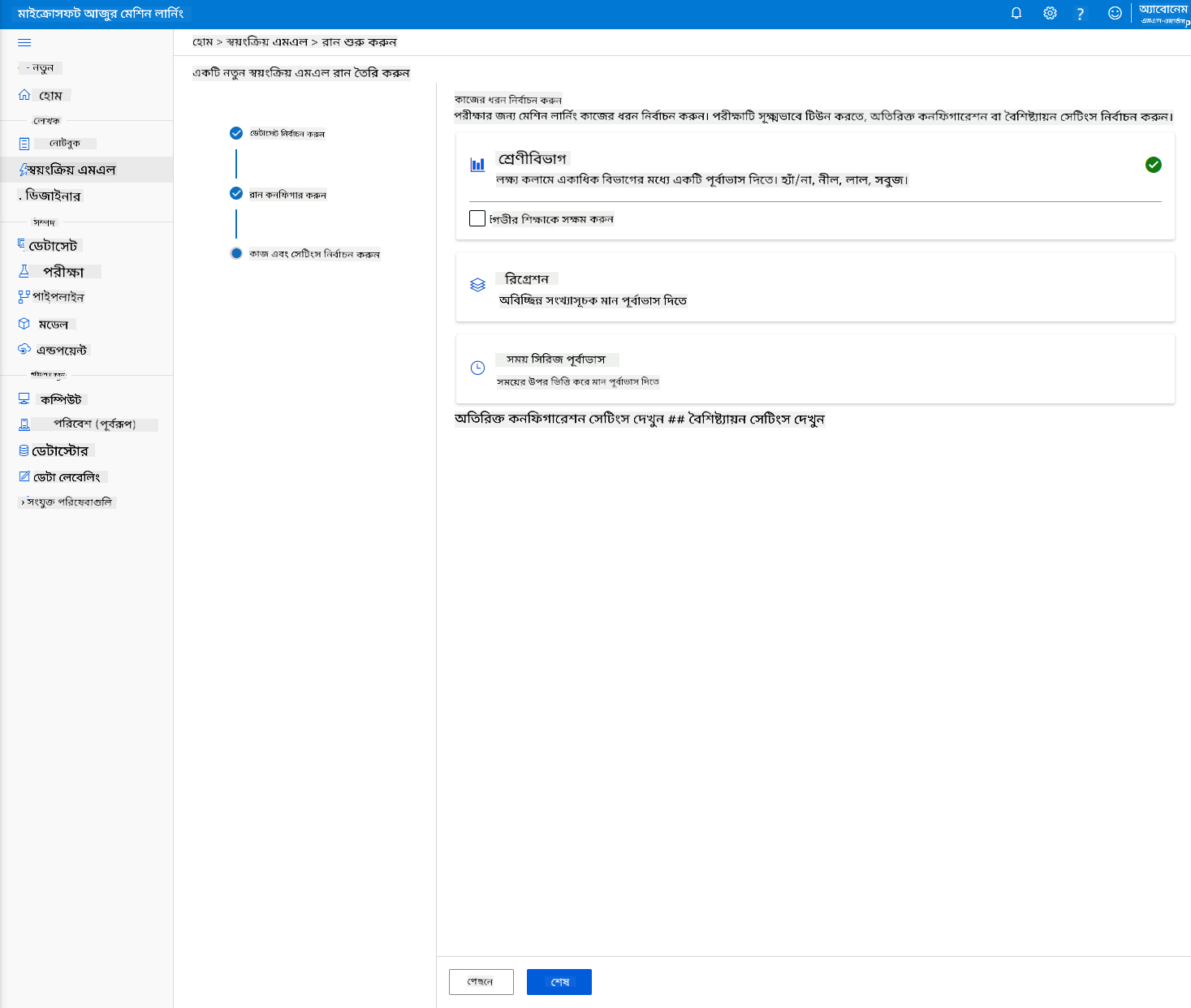
-
রান সম্পন্ন হলে, "Automated ML" ট্যাবে ক্লিক করুন, আপনার রান নির্বাচন করুন এবং "Best model summary" কার্ডে অ্যালগরিদমে ক্লিক করুন।
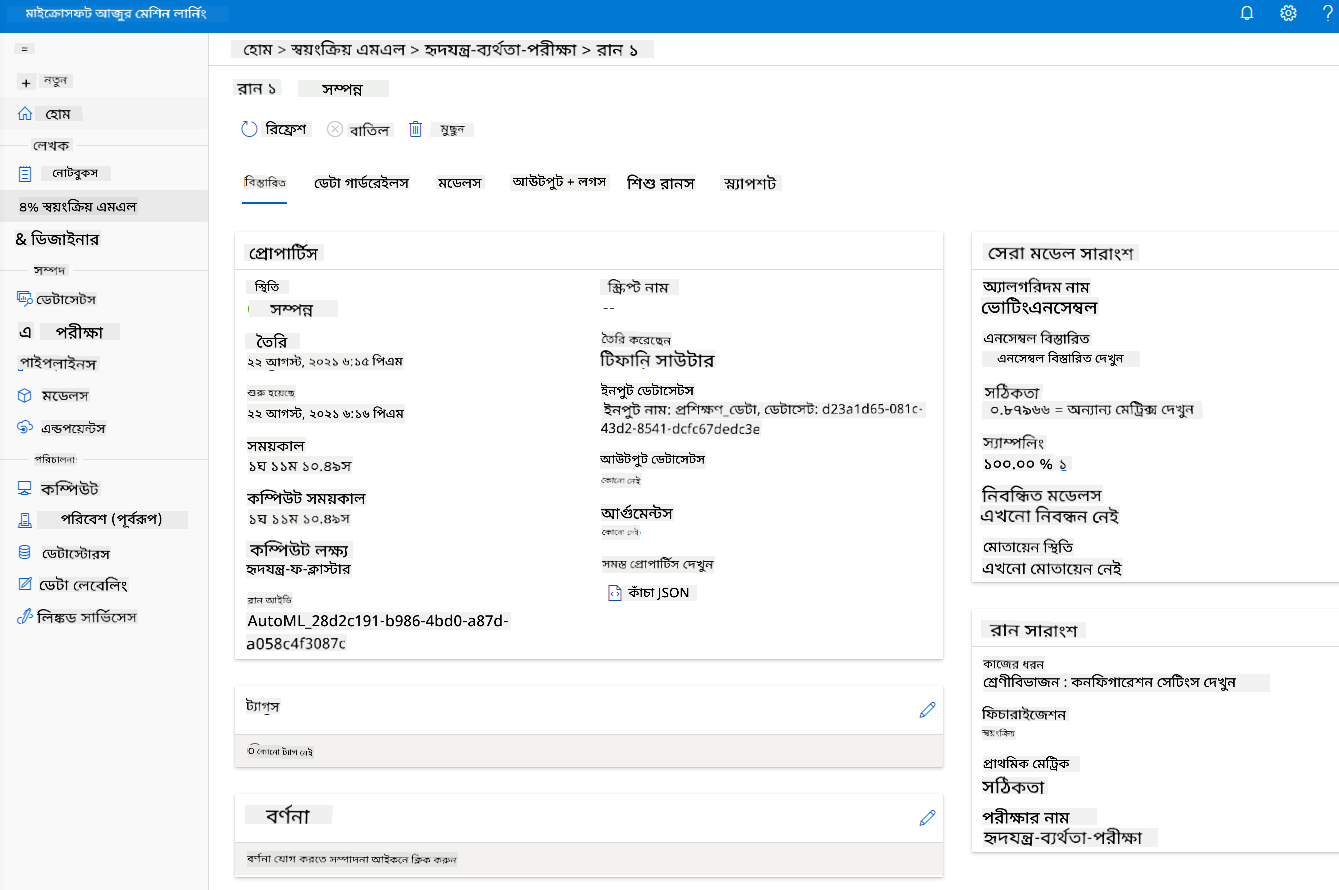
এখানে আপনি AutoML দ্বারা তৈরি করা সেরা মডেলের বিস্তারিত বিবরণ দেখতে পাবেন। "Models" ট্যাবে অন্যান্য মডেলগুলোও অন্বেষণ করতে পারেন। কয়েক মিনিট সময় নিয়ে মডেলগুলো এবং "Explanations (preview)" বোতামে বিশ্লেষণ করুন। একবার আপনি যে মডেলটি ব্যবহার করতে চান তা নির্বাচন করলে (এখানে আমরা AutoML দ্বারা নির্বাচিত সেরা মডেলটি বেছে নেব), আমরা এটি কীভাবে ডিপ্লয় করতে পারি তা দেখব।
3. লো কোড/নো কোড মডেল ডিপ্লয়মেন্ট এবং এন্ডপয়েন্ট ব্যবহার
3.1 মডেল ডিপ্লয়মেন্ট
Automated Machine Learning ইন্টারফেস আপনাকে কয়েকটি ধাপে সেরা মডেলটি একটি ওয়েব সার্ভিস হিসেবে ডিপ্লয় করতে দেয়। ডিপ্লয়মেন্ট হলো মডেলকে একীভূত করা যাতে এটি নতুন ডেটার উপর ভিত্তি করে পূর্বাভাস দিতে পারে এবং সম্ভাব্য সুযোগ চিহ্নিত করতে পারে। এই প্রকল্পের জন্য, ওয়েব সার্ভিসে ডিপ্লয়মেন্ট মানে হলো মেডিকেল অ্যাপ্লিকেশনগুলো মডেলটি ব্যবহার করে তাদের রোগীদের হার্ট অ্যাটাকের ঝুঁকি পূর্বাভাস দিতে পারবে।
সেরা মডেলের বিবরণে "Deploy" বোতামে ক্লিক করুন।
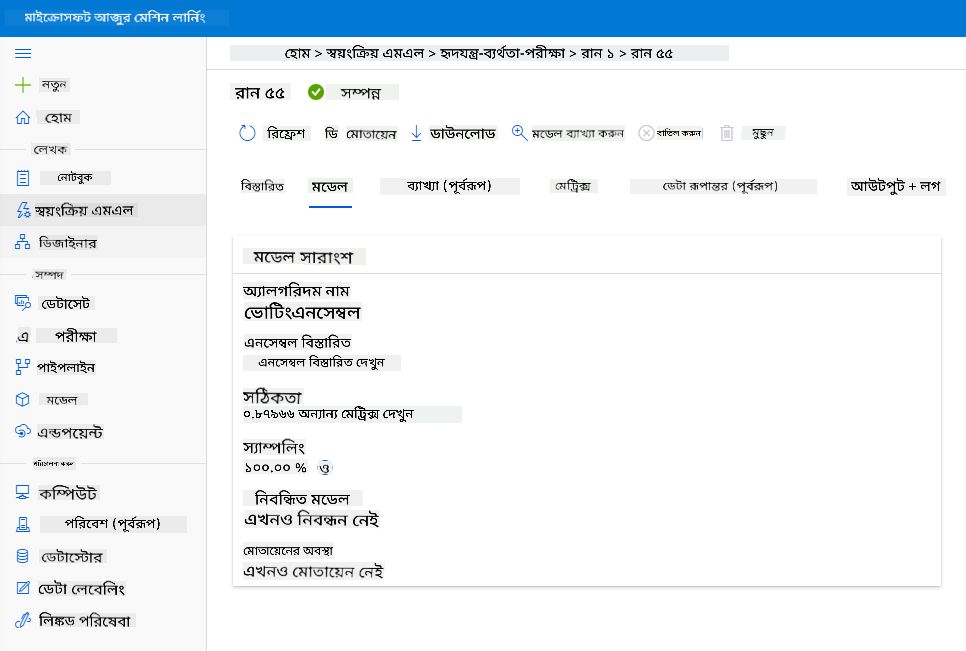
- একটি নাম, বিবরণ, কম্পিউট টাইপ (Azure Container Instance), প্রমাণীকরণ সক্রিয় করুন এবং "Deploy" এ ক্লিক করুন। এই ধাপটি প্রায় ২০ মিনিট সময় নিতে পারে। ডিপ্লয়মেন্ট প্রক্রিয়ায় মডেল নিবন্ধন, রিসোর্স তৈরি এবং ওয়েব সার্ভিসের জন্য কনফিগার করা অন্তর্ভুক্ত। "Deploy status"-এর অধীনে একটি স্ট্যাটাস বার্তা প্রদর্শিত হয়। স্ট্যাটাস পরীক্ষা করতে "Refresh" নির্বাচন করুন। স্ট্যাটাস "Healthy" হলে এটি ডিপ্লয় এবং চালু হয়েছে।
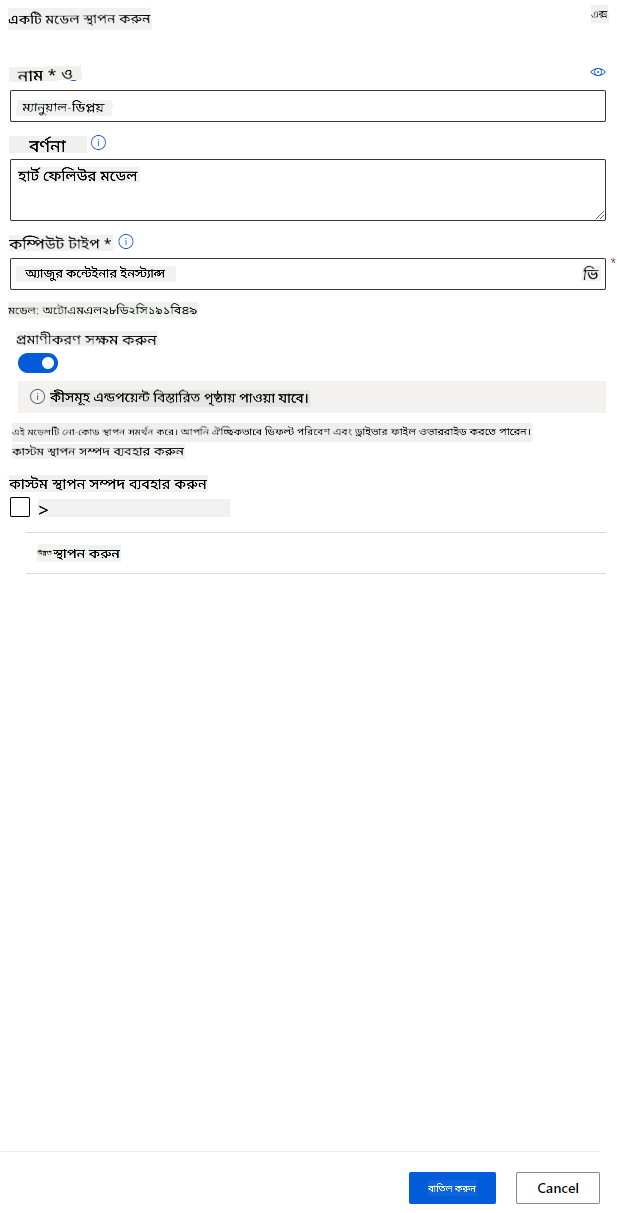
- একবার এটি ডিপ্লয় হয়ে গেলে, "Endpoint" ট্যাবে ক্লিক করুন এবং আপনি যে এন্ডপয়েন্টটি ডিপ্লয় করেছেন তাতে ক্লিক করুন। এখানে আপনি এন্ডপয়েন্ট সম্পর্কে সমস্ত বিবরণ খুঁজে পাবেন।
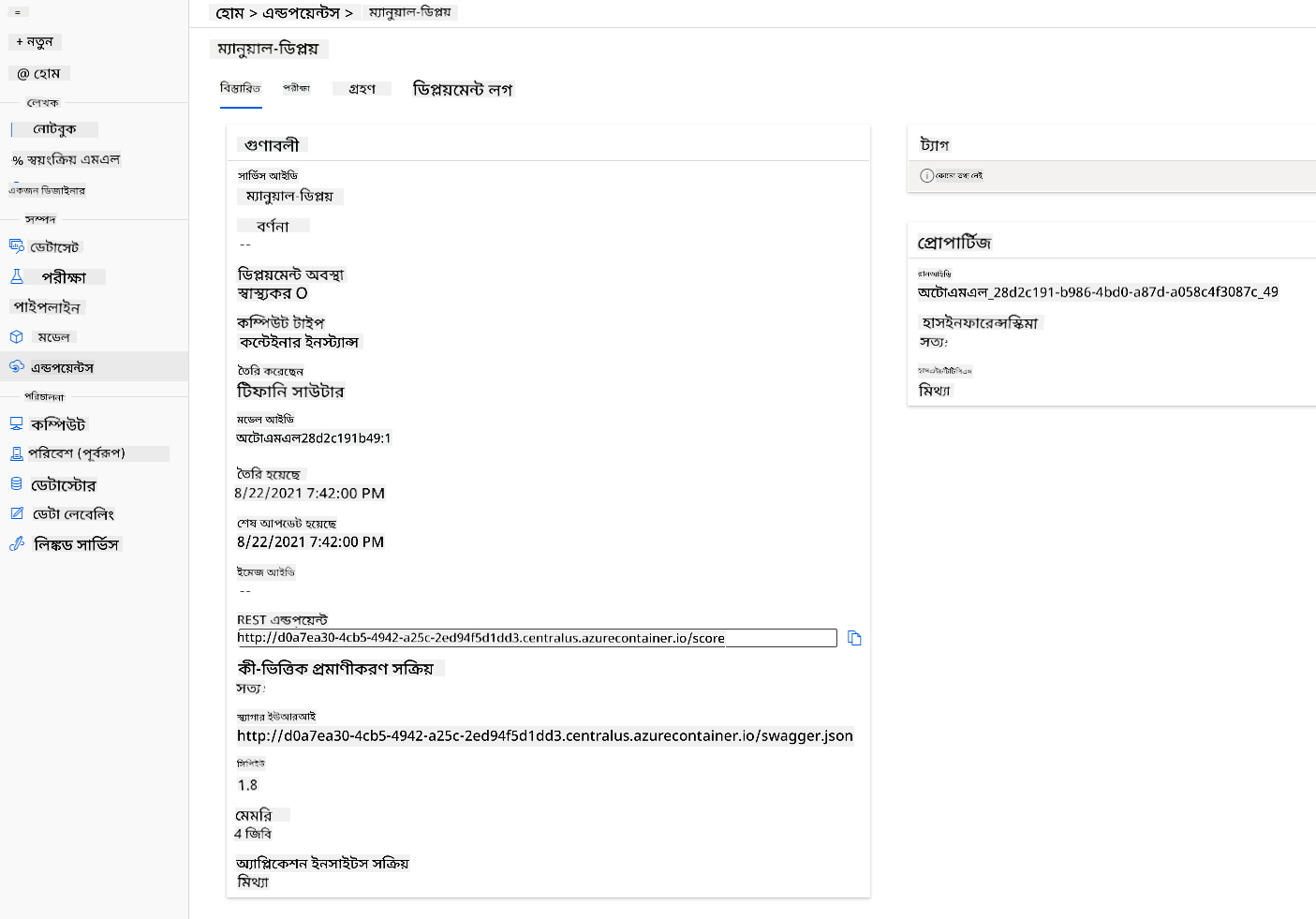
অসাধারণ! এখন আমাদের একটি মডেল ডিপ্লয় করা হয়েছে, আমরা এন্ডপয়েন্ট ব্যবহার শুরু করতে পারি।
3.2 এন্ডপয়েন্ট ব্যবহার
"Consume" ট্যাবে ক্লিক করুন। এখানে আপনি REST এন্ডপয়েন্ট এবং কনজাম্পশন অপশনে একটি পাইথন স্ক্রিপ্ট খুঁজে পাবেন। পাইথন কোডটি পড়তে কিছু সময় নিন।
এই স্ক্রিপ্টটি সরাসরি আপনার লোকাল মেশিন থেকে চালানো যেতে পারে এবং এটি আপনার এন্ডপয়েন্ট ব্যবহার করবে।
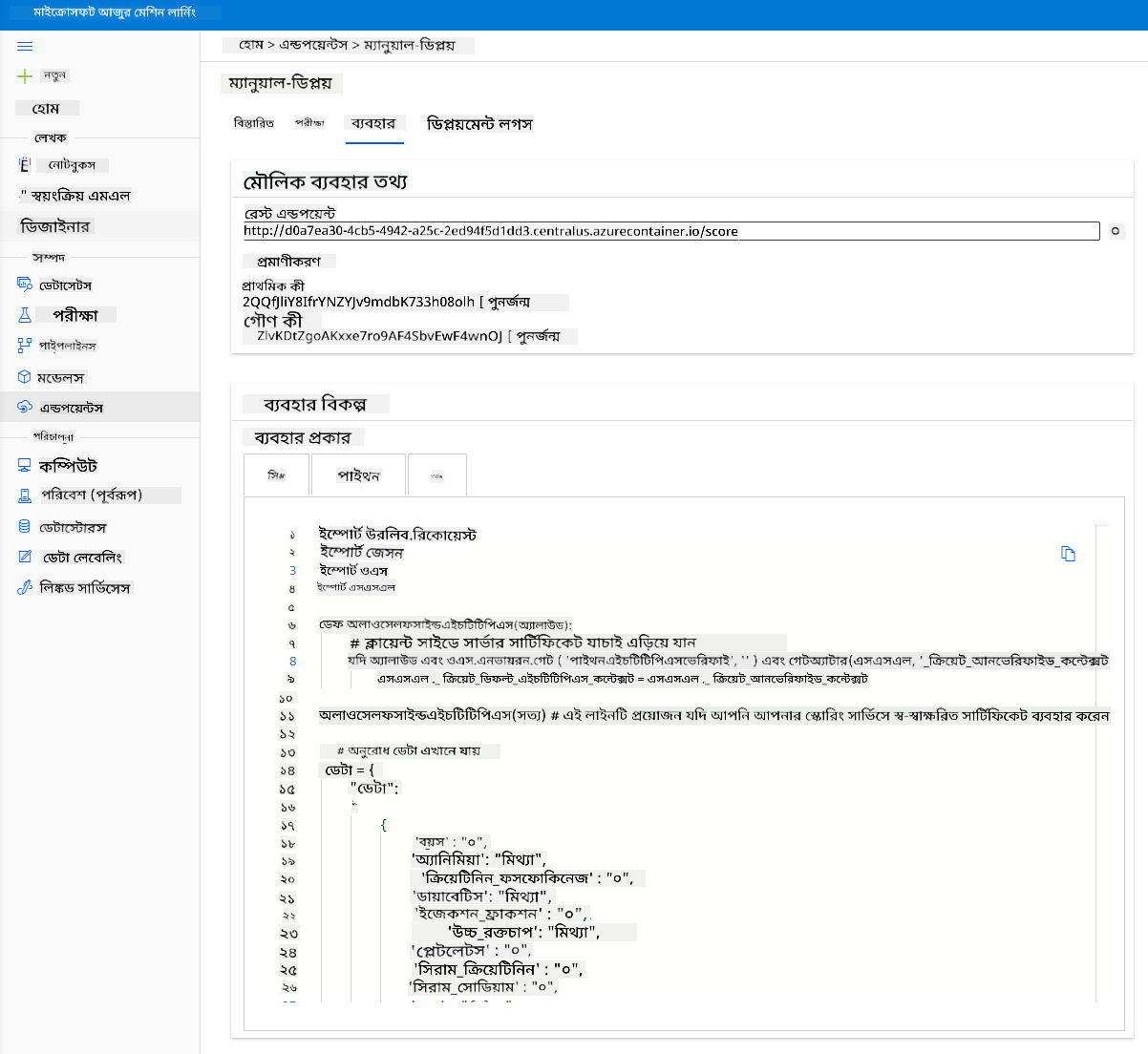
এই দুটি লাইনের কোড পরীক্ষা করুন:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
url ভেরিয়েবলটি কনজাম্পশন ট্যাবে পাওয়া REST এন্ডপয়েন্ট এবং api_key ভেরিয়েবলটি প্রাথমিক কী (যদি আপনি প্রমাণীকরণ সক্রিয় করে থাকেন)। এইভাবেই স্ক্রিপ্টটি এন্ডপয়েন্ট ব্যবহার করতে পারে।
- স্ক্রিপ্ট চালানোর পরে, আপনি নিম্নলিখিত আউটপুট দেখতে পাবেন:
b'"{\\"result\\": [true]}"'
এটি বোঝায় যে প্রদত্ত ডেটার জন্য হার্ট ফেলিওরের পূর্বাভাস সত্য। এটি যৌক্তিক কারণ স্ক্রিপ্টে স্বয়ংক্রিয়ভাবে তৈরি করা ডেটা আরও ঘনিষ্ঠভাবে দেখলে দেখা যায়, সবকিছু ডিফল্টভাবে 0 এবং মিথ্যা। আপনি নিম্নলিখিত ইনপুট নমুনা দিয়ে ডেটা পরিবর্তন করতে পারেন:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
স্ক্রিপ্টটি নিম্নলিখিত আউটপুট প্রদান করবে:
python b'"{\\"result\\": [true, false]}"'
অভিনন্দন! আপনি Azure ML-এ মডেল প্রশিক্ষণ এবং ডিপ্লয় করে এটি ব্যবহার করলেন!
NOTE: প্রকল্প শেষ হলে, সমস্ত রিসোর্স মুছে ফেলতে ভুলবেন না।
🚀 চ্যালেঞ্জ
AutoML দ্বারা তৈরি শীর্ষ মডেলগুলোর ব্যাখ্যা এবং বিশদ বিবরণ ঘনিষ্ঠভাবে দেখুন। বোঝার চেষ্টা করুন কেন সেরা মডেলটি অন্যগুলোর চেয়ে ভালো। কোন অ্যালগরিদমগুলো তুলনা করা হয়েছিল? তাদের মধ্যে পার্থক্য কী? কেন এই ক্ষেত্রে সেরা মডেলটি ভালো পারফর্ম করছে?
পোস্ট-লেকচার কুইজ
পুনরালোচনা ও স্ব-অধ্যয়ন
এই পাঠে, আপনি ক্লাউডে লো কোড/নো কোড পদ্ধতিতে হার্ট ফেলিওর ঝুঁকি পূর্বাভাসের জন্য একটি মডেল প্রশিক্ষণ, ডিপ্লয় এবং ব্যবহার করতে শিখেছেন। যদি আপনি এখনও না করে থাকেন, AutoML দ্বারা তৈরি শীর্ষ মডেলগুলোর ব্যাখ্যা আরও গভীরভাবে দেখুন এবং বোঝার চেষ্টা করুন কেন সেরা মডেলটি অন্যগুলোর চেয়ে ভালো।
লো কোড/নো কোড AutoML সম্পর্কে আরও জানতে এই ডকুমেন্টেশন পড়ুন।
অ্যাসাইনমেন্ট
Azure ML-এ লো কোড/নো কোড ডেটা সায়েন্স প্রকল্প
অস্বীকৃতি:
এই নথিটি AI অনুবাদ পরিষেবা Co-op Translator ব্যবহার করে অনুবাদ করা হয়েছে। আমরা যথাসম্ভব সঠিক অনুবাদের চেষ্টা করি, তবে অনুগ্রহ করে মনে রাখবেন যে স্বয়ংক্রিয় অনুবাদে ত্রুটি বা অসঙ্গতি থাকতে পারে। নথিটির মূল ভাষায় লেখা সংস্করণটিকেই প্রামাণিক উৎস হিসেবে বিবেচনা করা উচিত। গুরুত্বপূর্ণ তথ্যের জন্য, পেশাদার মানব অনুবাদ ব্যবহার করার পরামর্শ দেওয়া হচ্ছে। এই অনুবাদ ব্যবহারের ফলে সৃষ্ট কোনো ভুল বোঝাবুঝি বা ভুল ব্যাখ্যার জন্য আমরা দায়ী নই।