|
|
4 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 4 weeks ago | |
| assignment.md | 4 weeks ago | |
README.md
Наука за данни в облака: Методът "Малко код/Без код"
 |
|---|
| Наука за данни в облака: Малко код - Скица от @nitya |
Съдържание:
- Наука за данни в облака: Методът "Малко код/Без код"
Тест преди лекцията
1. Въведение
1.1 Какво е Azure Machine Learning?
Платформата Azure предлага над 200 продукта и облачни услуги, създадени да ви помогнат да реализирате нови решения. Специалистите по данни отделят много време за изследване и предварителна обработка на данни, както и за тестване на различни алгоритми за обучение на модели, за да създадат точни модели. Тези задачи са трудоемки и често водят до неефективно използване на скъпи изчислителни ресурси.
Azure ML е облачна платформа за създаване и управление на решения за машинно обучение в Azure. Тя включва широк набор от функции и възможности, които помагат на специалистите по данни да подготвят данни, обучават модели, публикуват предсказателни услуги и следят тяхното използване. Най-важното е, че платформата увеличава ефективността, като автоматизира много от трудоемките задачи, свързани с обучението на модели, и позволява използването на облачни изчислителни ресурси, които се мащабират ефективно, за да обработват големи обеми данни, като се начисляват разходи само когато се използват.
Azure ML предоставя всички инструменти, от които разработчиците и специалистите по данни се нуждаят за своите работни процеси за машинно обучение. Те включват:
- Azure Machine Learning Studio: уеб портал в Azure Machine Learning за опции с малко код и без код за обучение на модели, разгръщане, автоматизация, проследяване и управление на активи. Studio се интегрира с Azure Machine Learning SDK за безпроблемно изживяване.
- Jupyter Notebooks: бързо прототипиране и тестване на ML модели.
- Azure Machine Learning Designer: позволява влачене и пускане на модули за създаване на експерименти и разгръщане на конвейери в среда с малко код.
- Автоматизирано машинно обучение (AutoML): автоматизира итеративните задачи за разработване на модели за машинно обучение, позволявайки създаване на ML модели с висока мащабируемост, ефективност и продуктивност, като същевременно поддържа качеството на модела.
- Етикетиране на данни: инструмент за подпомагане на ML, който автоматично етикетира данни.
- Разширение за машинно обучение за Visual Studio Code: предоставя пълнофункционална среда за разработка за създаване и управление на ML проекти.
- CLI за машинно обучение: предоставя команди за управление на ресурси на Azure ML от командния ред.
- Интеграция с рамки с отворен код като PyTorch, TensorFlow, Scikit-learn и много други за обучение, разгръщане и управление на целия процес на машинно обучение.
- MLflow: библиотека с отворен код за управление на жизнения цикъл на вашите експерименти за машинно обучение. MLFlow Tracking е компонент на MLflow, който записва и проследява метриките на вашите тренировъчни изпълнения и артефакти на модела, независимо от средата на вашия експеримент.
1.2 Проект за предсказване на сърдечна недостатъчност:
Няма съмнение, че създаването и разработването на проекти е най-добрият начин да тествате своите умения и знания. В този урок ще разгледаме два различни начина за създаване на проект за наука за данни за предсказване на сърдечни атаки в Azure ML Studio: чрез методите "Малко код/Без код" и чрез Azure ML SDK, както е показано в следната схема:
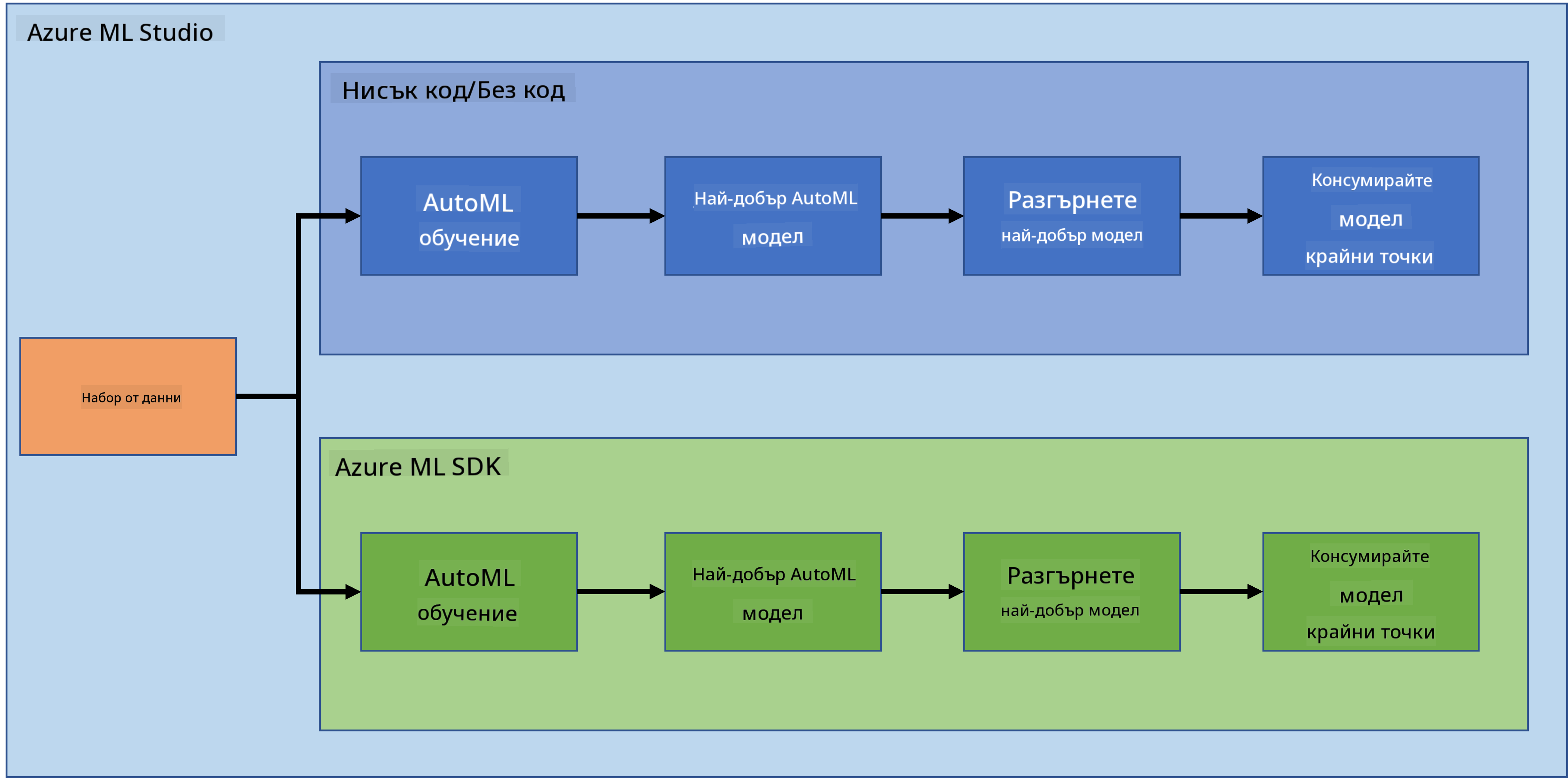
Всеки метод има своите предимства и недостатъци. Методът "Малко код/Без код" е по-лесен за започване, тъй като включва работа с графичен потребителски интерфейс (GUI), без да е необходимо предварително познаване на програмиране. Този метод позволява бързо тестване на жизнеспособността на проекта и създаване на POC (Proof Of Concept). Въпреки това, когато проектът се разраства и трябва да бъде готов за производство, не е практично да се създават ресурси чрез GUI. Тогава става необходимо програмно автоматизиране на всичко - от създаването на ресурси до разгръщането на модел. Тук познанията за използване на Azure ML SDK стават от решаващо значение.
| Малко код/Без код | Azure ML SDK | |
|---|---|---|
| Познания по програмиране | Не се изискват | Изискват се |
| Време за разработка | Бързо и лесно | Зависи от познанията по програмиране |
| Готовност за производство | Не | Да |
1.3 Набор от данни за сърдечна недостатъчност:
Сърдечно-съдовите заболявания (CVDs) са водещата причина за смъртност в световен мащаб, представлявайки 31% от всички смъртни случаи. Екологични и поведенчески рискови фактори като употреба на тютюн, нездравословна диета и затлъстяване, физическа неактивност и вредна употреба на алкохол могат да бъдат използвани като характеристики за модели за оценка. Възможността за оценка на вероятността за развитие на CVD може да бъде от голяма полза за предотвратяване на атаки при хора с висок риск.
Kaggle предоставя набор от данни за сърдечна недостатъчност, който ще използваме за този проект. Можете да изтеглите набора от данни сега. Това е табличен набор от данни с 13 колони (12 характеристики и 1 целева променлива) и 299 реда.
| Име на променливата | Тип | Описание | Пример | |
|---|---|---|---|---|
| 1 | age | числов | възраст на пациента | 25 |
| 2 | anaemia | булев | Намаляване на червените кръвни клетки или хемоглобина | 0 или 1 |
| 3 | creatinine_phosphokinase | числов | Ниво на ензима CPK в кръвта | 542 |
| 4 | diabetes | булев | Дали пациентът има диабет | 0 или 1 |
| 5 | ejection_fraction | числов | Процент кръв, напускаща сърцето при всяка контракция | 45 |
| 6 | high_blood_pressure | булев | Дали пациентът има хипертония | 0 или 1 |
| 7 | platelets | числов | Тромбоцити в кръвта | 149000 |
| 8 | serum_creatinine | числов | Ниво на серумен креатинин в кръвта | 0.5 |
| 9 | serum_sodium | числов | Ниво на серумен натрий в кръвта | jun |
| 10 | sex | булев | жена или мъж | 0 или 1 |
| 11 | smoking | булев | Дали пациентът пуши | 0 или 1 |
| 12 | time | числов | период на проследяване (дни) | 4 |
| ---- | --------------------------- | ----------------- | ----------------------------------------------------------- | ------------------- |
| 21 | DEATH_EVENT [Целева] | булев | дали пациентът умира по време на периода на проследяване | 0 или 1 |
След като имате набора от данни, можем да започнем проекта в Azure.
2. Обучение на модел с малко код/без код в Azure ML Studio
2.1 Създаване на работно пространство в Azure ML
За да обучите модел в Azure ML, първо трябва да създадете работно пространство в Azure ML. Работното пространство е основният ресурс за Azure Machine Learning, предоставящ централизирано място за работа с всички артефакти, които създавате, когато използвате Azure Machine Learning. Работното пространство съхранява историята на всички тренировъчни изпълнения, включително дневници, метрики, изходни данни и моментна снимка на вашите скриптове. Използвате тази информация, за да определите кое тренировъчно изпълнение произвежда най-добрия модел. Научете повече
Препоръчително е да използвате най-актуалния браузър, който е съвместим с вашата операционна система. Поддържаните браузъри са:
- Microsoft Edge (новият Microsoft Edge, последна версия. Не Microsoft Edge legacy)
- Safari (последна версия, само за Mac)
- Chrome (последна версия)
- Firefox (последна версия)
За да използвате Azure Machine Learning, създайте работно пространство във вашия абонамент за Azure. След това можете да използвате това работно пространство, за да управлявате данни, изчислителни ресурси, код, модели и други артефакти, свързани с вашите работни процеси за машинно обучение.
ЗАБЕЛЕЖКА: Вашият абонамент за Azure ще бъде таксуван с малка сума за съхранение на данни, докато работното пространство за Azure Machine Learning съществува във вашия абонамент, затова препоръчваме да изтриете работното пространство за Azure Machine Learning, когато вече не го използвате.
-
Влезте в портала на Azure с Microsoft идентификационните данни, свързани с вашия абонамент за Azure.
-
Изберете +Създаване на ресурс
Потърсете Machine Learning и изберете плочката Machine Learning
Кликнете върху бутона за създаване
Попълнете настройките, както следва:
- Абонамент: Вашият абонамент за Azure
- Група ресурси: Създайте или изберете група ресурси
- Име на работното пространство: Въведете уникално име за вашето работно пространство
- Регион: Изберете географския регион, най-близък до вас
- Акаунт за съхранение: Обърнете внимание на новия акаунт за съхранение, който ще бъде създаден за вашето работно пространство
- Key vault: Обърнете внимание на новия key vault, който ще бъде създаден за вашето работно пространство
- Application insights: Обърнете внимание на новия ресурс за application insights, който ще бъде създаден за вашето работно пространство
- Container registry: Няма (един ще бъде създаден автоматично при първото разгръщане на модел в контейнер)
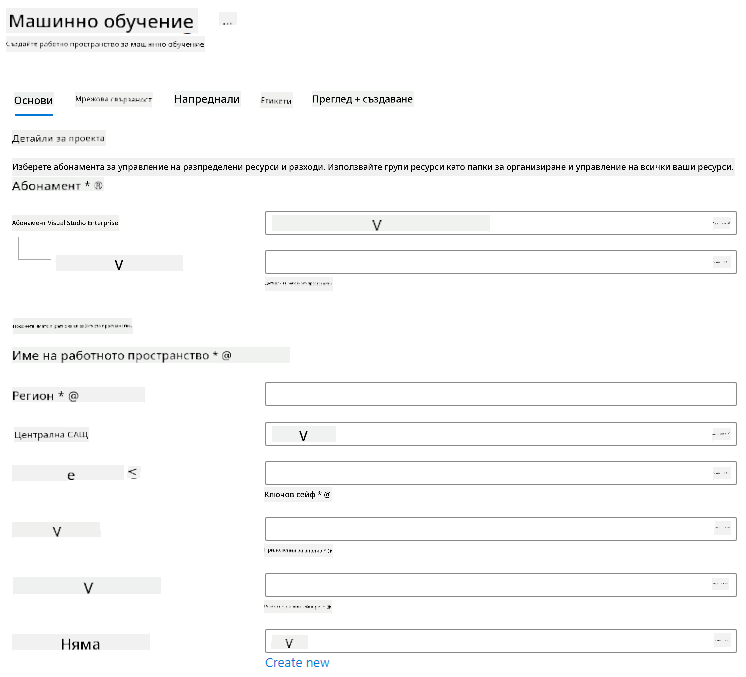
- Кликнете върху "Създаване + преглед" и след това върху бутона "Създаване"
-
Изчакайте вашето работно пространство да бъде създадено (това може да отнеме няколко минути). След това отидете до него в портала. Можете да го намерите чрез услугата Machine Learning в Azure.
-
На страницата "Преглед" за вашето работно пространство стартирайте Azure Machine Learning Studio (или отворете нов раздел в браузъра и навигирайте до https://ml.azure.com), и влезте в Azure Machine Learning Studio с вашия Microsoft акаунт. Ако бъдете подканени, изберете вашия Azure директория и абонамент, както и вашето работно пространство за Azure Machine Learning.
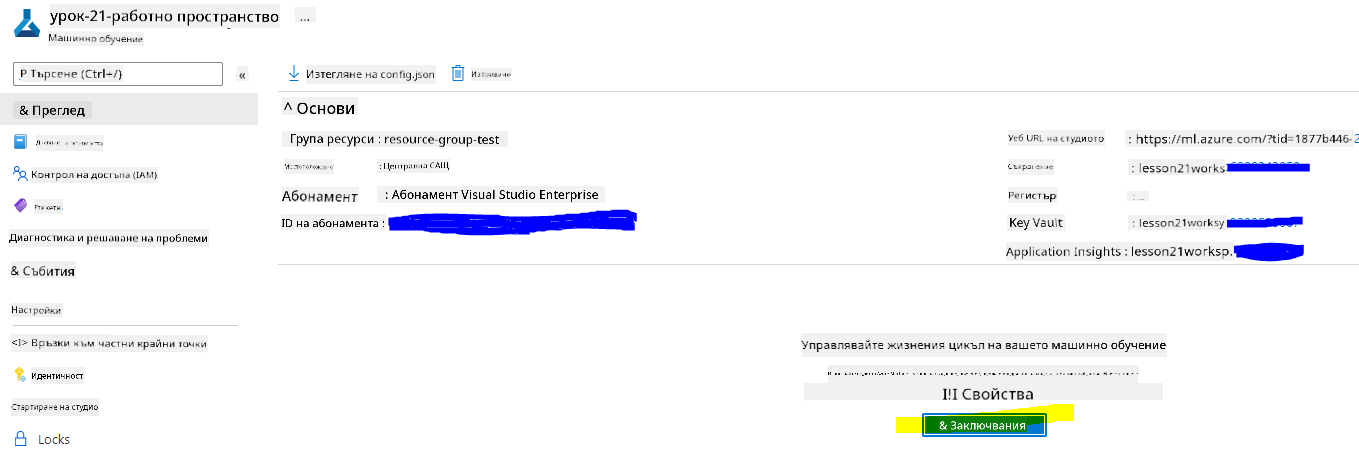
- В Azure Machine Learning Studio, превключете иконата ☰ в горния ляв ъгъл, за да видите различните страници в интерфейса. Можете да използвате тези страници, за да управлявате ресурсите във вашето работно пространство.
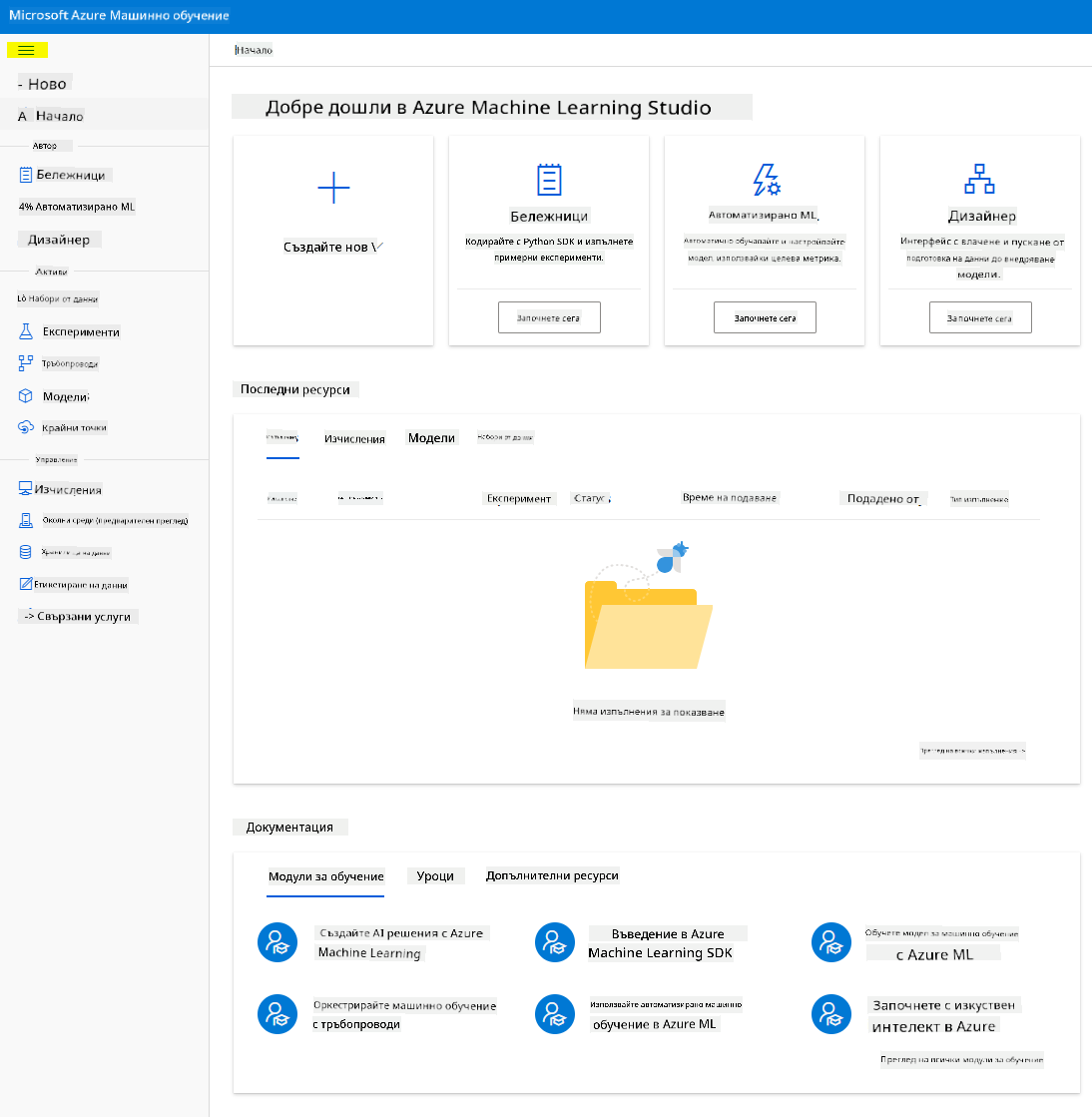
Можете да управлявате вашето работно пространство чрез портала на Azure, но за специалистите по данни и инженерите по операции за машинно обучение, Azure Machine Learning Studio предоставя по-фокусиран потребителски интерфейс за управление на ресурсите на работното пространство.
2.2 Изчислителни ресурси
Изчислителните ресурси са облачни ресурси, на които можете да изпълнявате процеси за обучение на модели и изследване на данни. Има четири вида изчислителни ресурси, които можете да създадете:
- Изчислителни инстанции: Работни станции за разработка, които специалистите по данни могат да използват за работа с данни и модели. Това включва създаване на виртуална машина (VM) и стартиране на инстанция на notebook. След това можете да обучите модел, като извикате изчислителен клъстер от notebook.
- Изчислителни клъстери: Скалиращи клъстери от виртуални машини за обработка на експериментален код при поискване. Ще ви е необходим, когато обучавате модел. Изчислителните клъстери могат също да използват специализирани GPU или CPU ресурси.
- Клъстери за инференция: Цели за разгръщане на предсказателни услуги, които използват вашите обучени модели.
- Свързани изчислителни ресурси: Свързва съществуващи изчислителни ресурси в Azure, като виртуални машини или клъстери на Azure Databricks.
2.2.1 Избор на правилните опции за вашите изчислителни ресурси
Някои ключови фактори трябва да се вземат предвид при създаването на изчислителен ресурс, тъй като тези решения могат да бъдат критични.
Нуждаете ли се от CPU или GPU?
CPU (Централен процесор) е електронната схема, която изпълнява инструкциите на компютърна програма. GPU (Графичен процесор) е специализирана електронна схема, която може да изпълнява графичен код с много висока скорост.
Основната разлика между архитектурата на CPU и GPU е, че CPU е проектиран да обработва широк спектър от задачи бързо (измерено чрез тактовата честота на CPU), но е ограничен в броя на задачите, които могат да се изпълняват едновременно. GPU е проектиран за паралелни изчисления и затова е много по-добър за задачи, свързани с дълбоко обучение.
| CPU | GPU |
|---|---|
| По-евтин | По-скъп |
| По-ниско ниво на паралелност | По-високо ниво на паралелност |
| По-бавен при обучение на модели за дълбоко обучение | Оптимален за дълбоко обучение |
Размер на клъстера
По-големите клъстери са по-скъпи, но осигуряват по-добра отзивчивост. Следователно, ако разполагате с време, но не и с достатъчно средства, започнете с малък клъстер. Обратно, ако разполагате със средства, но не и с много време, започнете с по-голям клъстер.
Размер на виртуалната машина (VM)
В зависимост от вашите времеви и бюджетни ограничения, можете да променяте размера на RAM, диска, броя на ядрата и тактовата честота. Увеличаването на тези параметри ще бъде по-скъпо, но ще доведе до по-добра производителност.
Посветени или нископриоритетни инстанции?
Нископриоритетна инстанция означава, че тя е прекъсваема: Microsoft Azure може да вземе тези ресурси и да ги пренасочи към друга задача, прекъсвайки текущата работа. Посветена инстанция, или непрекъсваема, означава, че задачата никога няма да бъде прекратена без ваше разрешение. Това е още един въпрос на баланс между време и средства, тъй като прекъсваемите инстанции са по-евтини от посветените.
2.2.2 Създаване на изчислителен клъстер
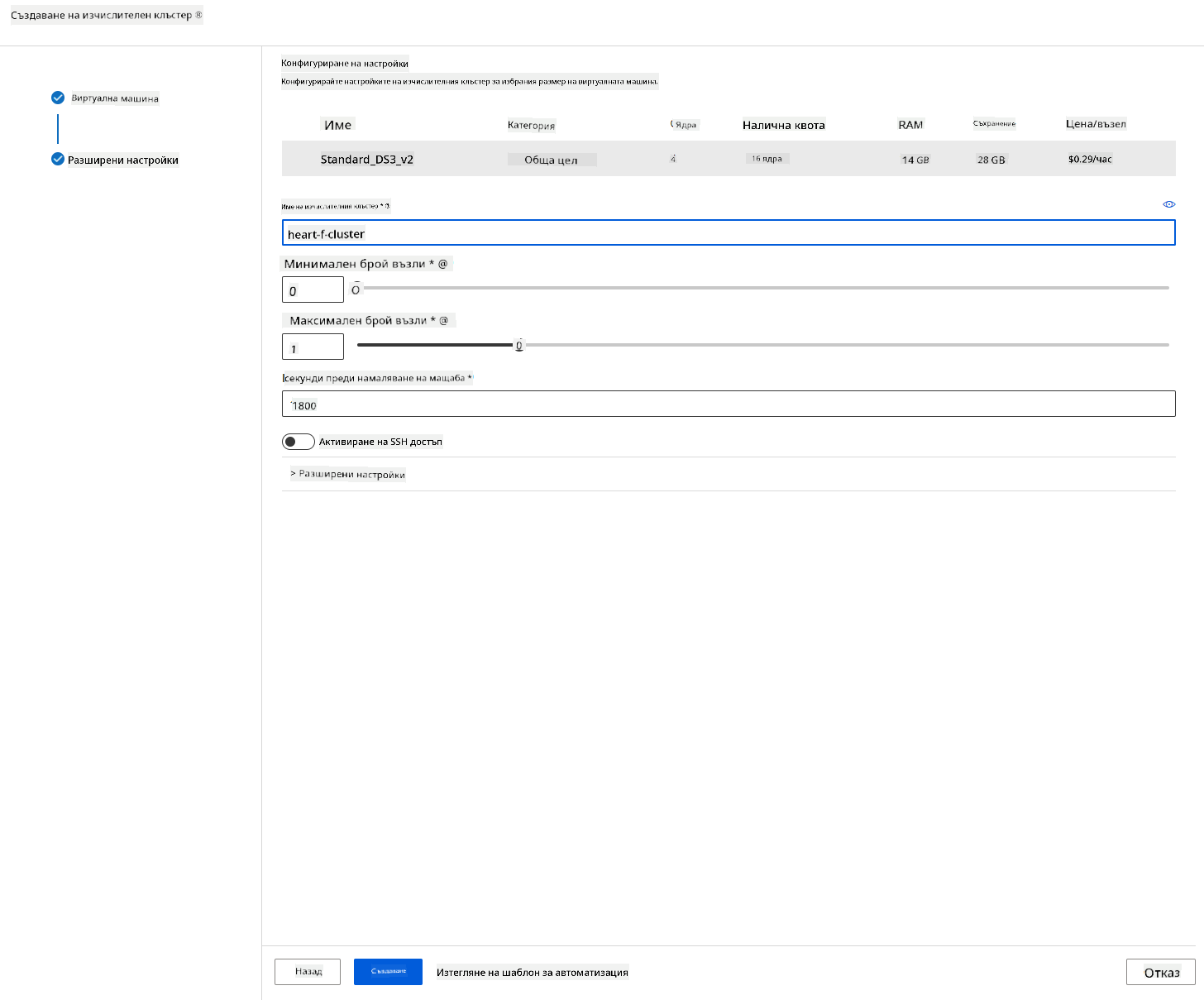
В работното пространство на Azure ML, което създадохме по-рано, отидете на "Compute" и ще видите различните изчислителни ресурси, които обсъдихме (напр. изчислителни инстанции, изчислителни клъстери, клъстери за предсказания и свързани изчисления). За този проект ще ни е необходим изчислителен клъстер за обучение на модела. В Studio кликнете върху менюто "Compute", след това върху таба "Compute cluster" и натиснете бутона "+ New", за да създадете изчислителен клъстер.

- Изберете вашите опции: Посветени срещу нископриоритетни, CPU или GPU, размер на VM и брой ядра (можете да оставите настройките по подразбиране за този проект).
- Натиснете бутона "Next".
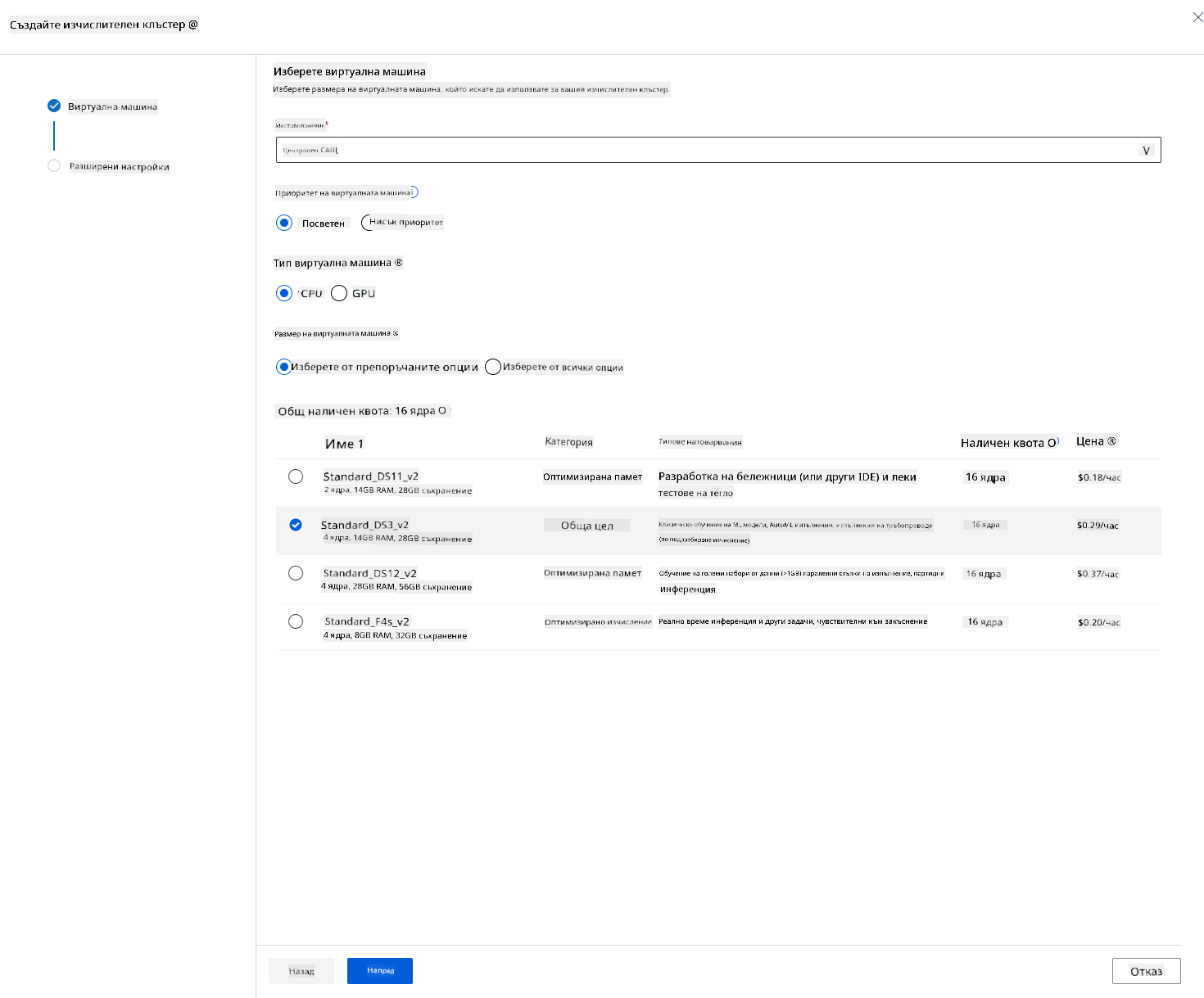
- Дайте име на клъстера.
- Изберете вашите опции: Минимален/максимален брой възли, време на бездействие преди мащабиране надолу, SSH достъп. Имайте предвид, че ако минималният брой възли е 0, ще спестите средства, когато клъстерът е в режим на бездействие. Имайте предвид, че колкото по-голям е максималният брой възли, толкова по-кратко ще бъде обучението. Препоръчителният максимален брой възли е 3.
- Натиснете бутона "Create". Тази стъпка може да отнеме няколко минути.
Чудесно! Сега, когато имаме изчислителен клъстер, трябва да заредим данните в Azure ML Studio.
2.3 Зареждане на набора от данни
-
В работното пространство на Azure ML, което създадохме по-рано, кликнете върху "Datasets" в лявото меню и натиснете бутона "+ Create dataset", за да създадете набор от данни. Изберете опцията "From local files" и изберете набора от данни от Kaggle, който изтеглихме по-рано.
-
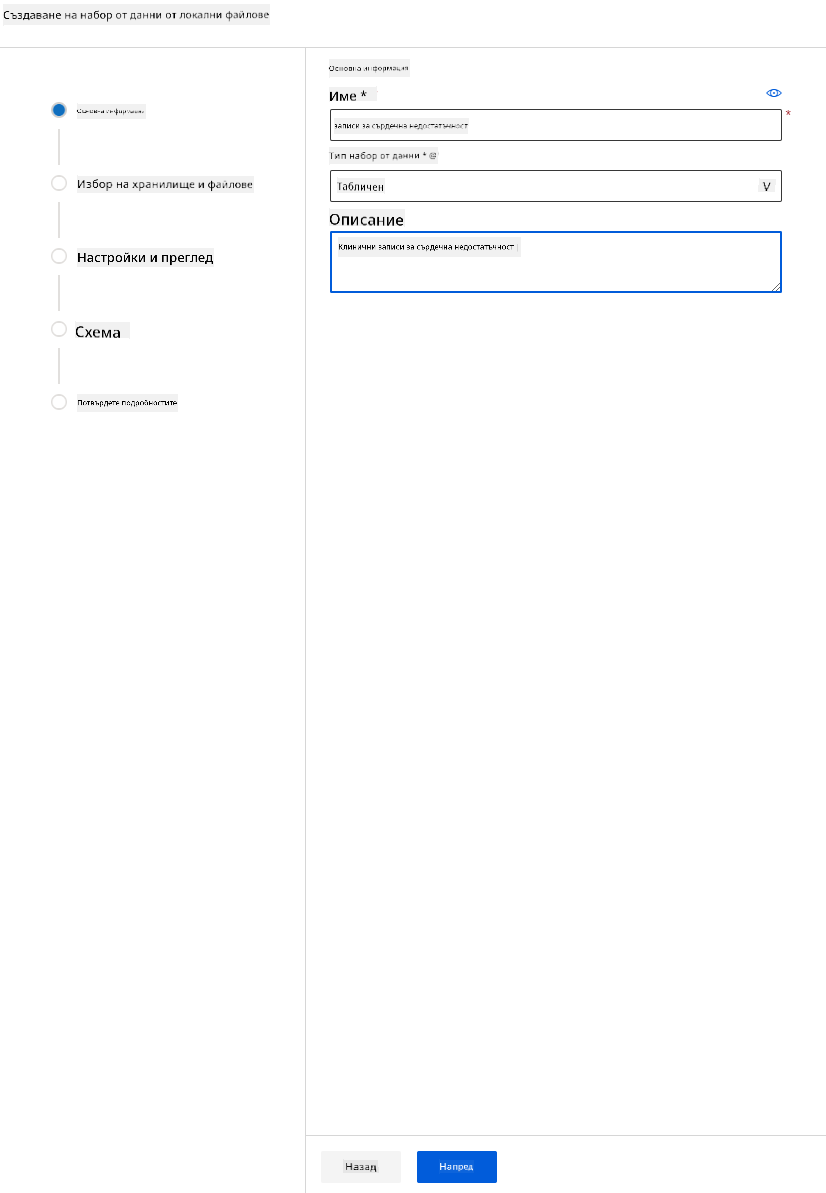
Дайте име, тип и описание на вашия набор от данни. Натиснете "Next". Качете данните от файловете. Натиснете "Next".
-
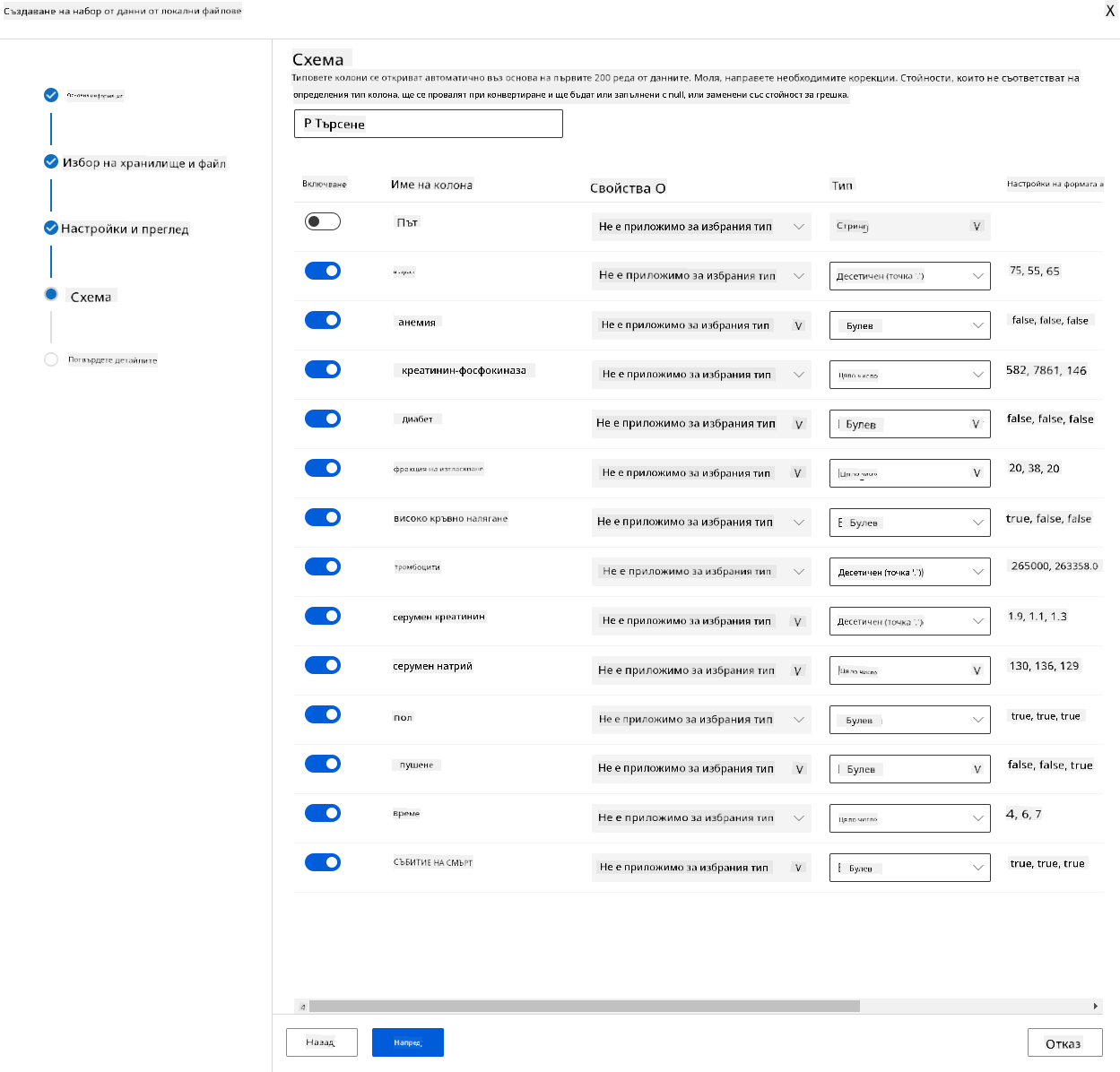
В раздела "Schema" променете типа данни на Boolean за следните характеристики: anaemia, diabetes, high blood pressure, sex, smoking и DEATH_EVENT. Натиснете "Next" и след това "Create".
Чудесно! Сега, когато наборът от данни е на място и изчислителният клъстер е създаден, можем да започнем обучението на модела!
2.4 Обучение с малко или без код с AutoML
Традиционното разработване на модели за машинно обучение изисква много ресурси, значителни познания в областта и време за създаване и сравнение на десетки модели. Автоматизираното машинно обучение (AutoML) автоматизира времево интензивните, итеративни задачи при разработването на модели за машинно обучение. То позволява на специалисти по данни, анализатори и разработчици да създават ML модели с висока ефективност и продуктивност, като същевременно поддържат качеството на модела. Това намалява времето, необходимо за създаване на готови за производство ML модели, с голяма лекота и ефективност. Научете повече
-
В работното пространство на Azure ML, което създадохме по-рано, кликнете върху "Automated ML" в лявото меню и изберете набора от данни, който току-що качихте. Натиснете "Next".
-
Въведете ново име на експеримент, целевата колона (DEATH_EVENT) и изчислителния клъстер, който създадохме. Натиснете "Next".
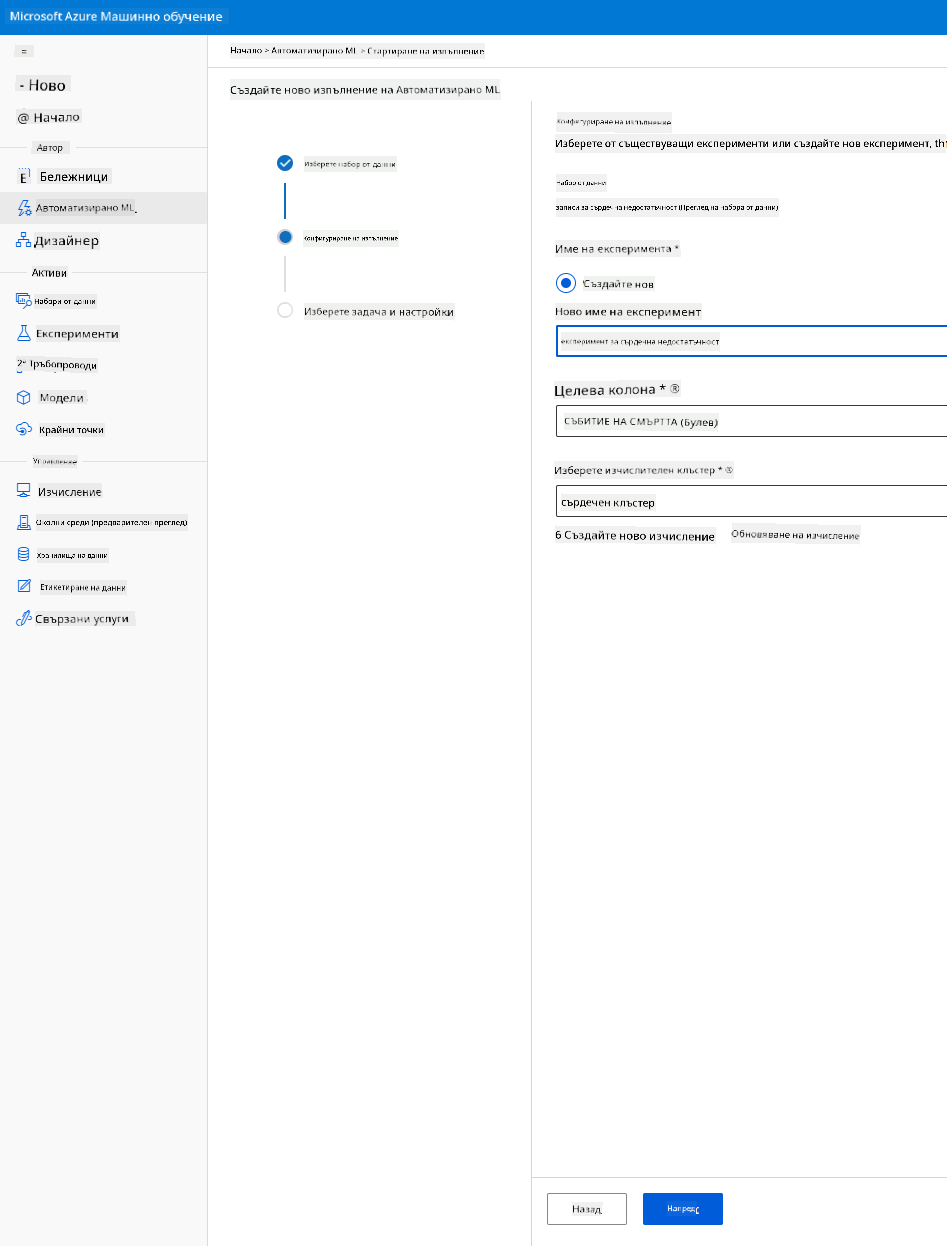
-
Изберете "Classification" и натиснете "Finish". Тази стъпка може да отнеме между 30 минути и 1 час, в зависимост от размера на вашия изчислителен клъстер.
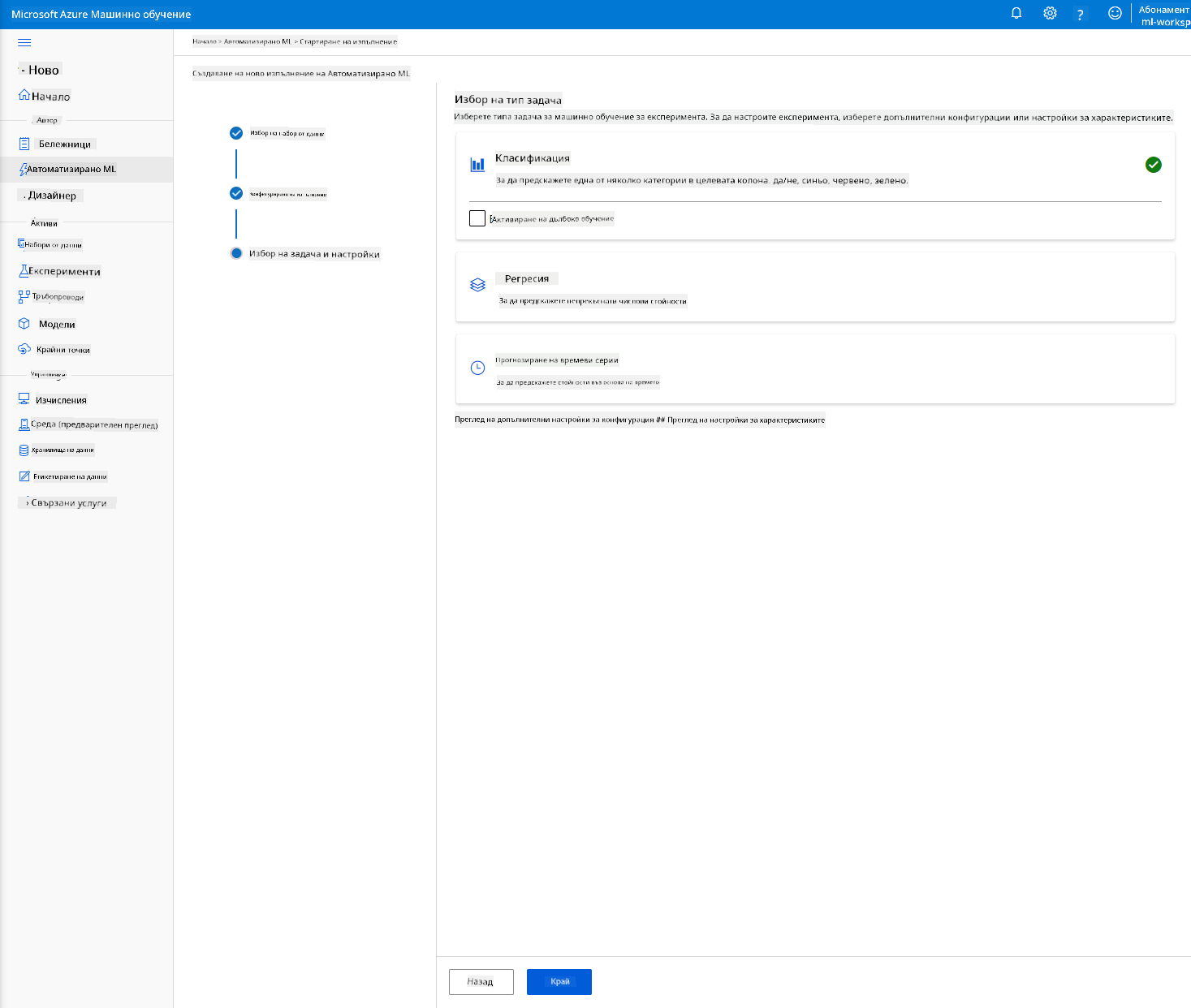
-
След като изпълнението приключи, кликнете върху таба "Automated ML", изберете вашето изпълнение и кликнете върху алгоритъма в картата "Best model summary".
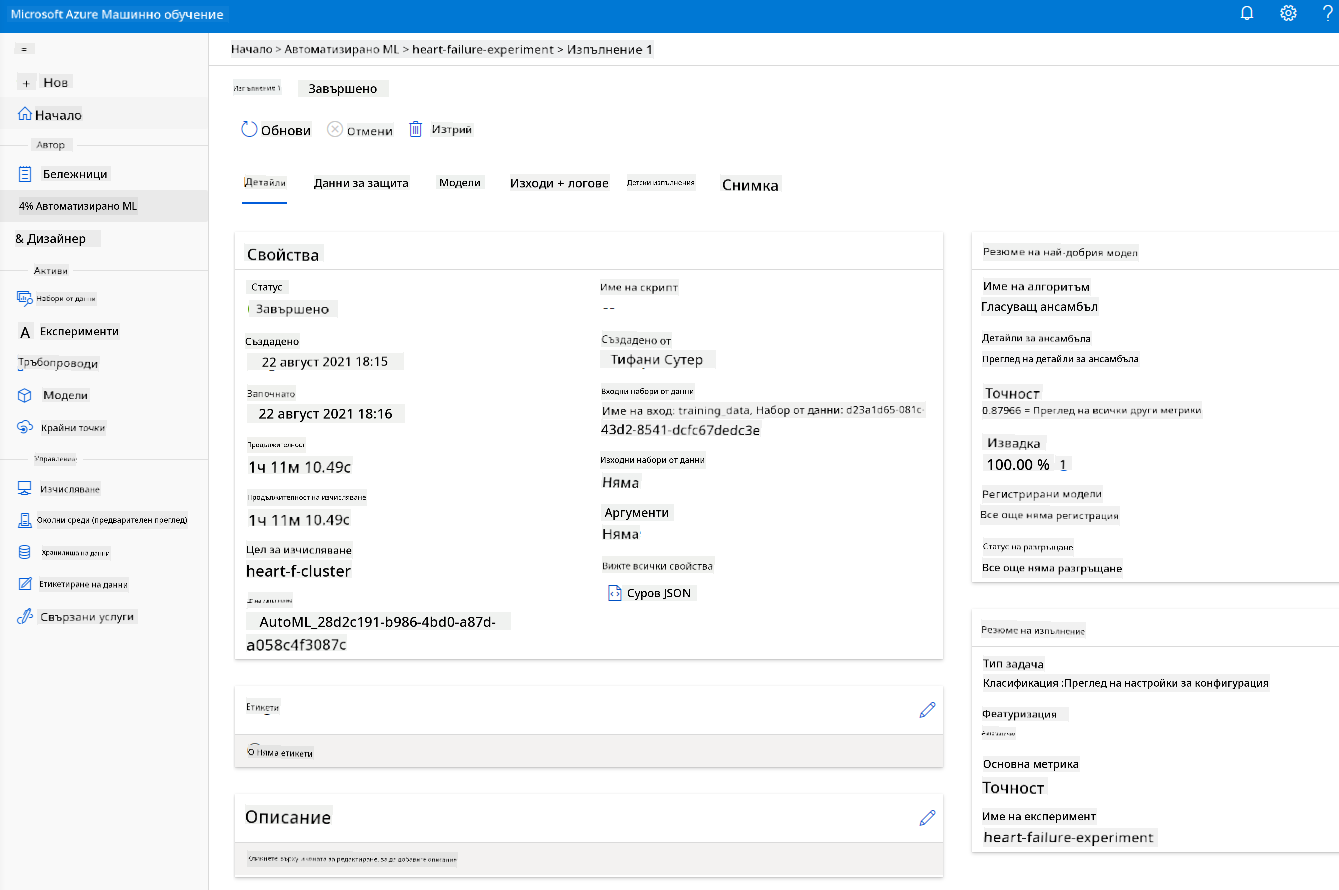
Тук можете да видите подробно описание на най-добрия модел, който AutoML е генерирал. Можете също така да разгледате други модели в таба "Models". Отделете няколко минути, за да разгледате моделите в раздела "Explanations (preview)". След като изберете модела, който искате да използвате (тук ще изберем най-добрия модел, избран от AutoML), ще видим как можем да го разположим.
3. Разполагане на модел с малко или без код и консумация на крайна точка
3.1 Разполагане на модела
Интерфейсът на автоматизираното машинно обучение ви позволява да разположите най-добрия модел като уеб услуга в няколко стъпки. Разполагането е интеграцията на модела, така че той да може да прави прогнози въз основа на нови данни и да идентифицира потенциални области за подобрение. За този проект разполагането като уеб услуга означава, че медицински приложения ще могат да използват модела, за да правят прогнози в реално време за риска от сърдечен удар на своите пациенти.
В описанието на най-добрия модел кликнете върху бутона "Deploy".
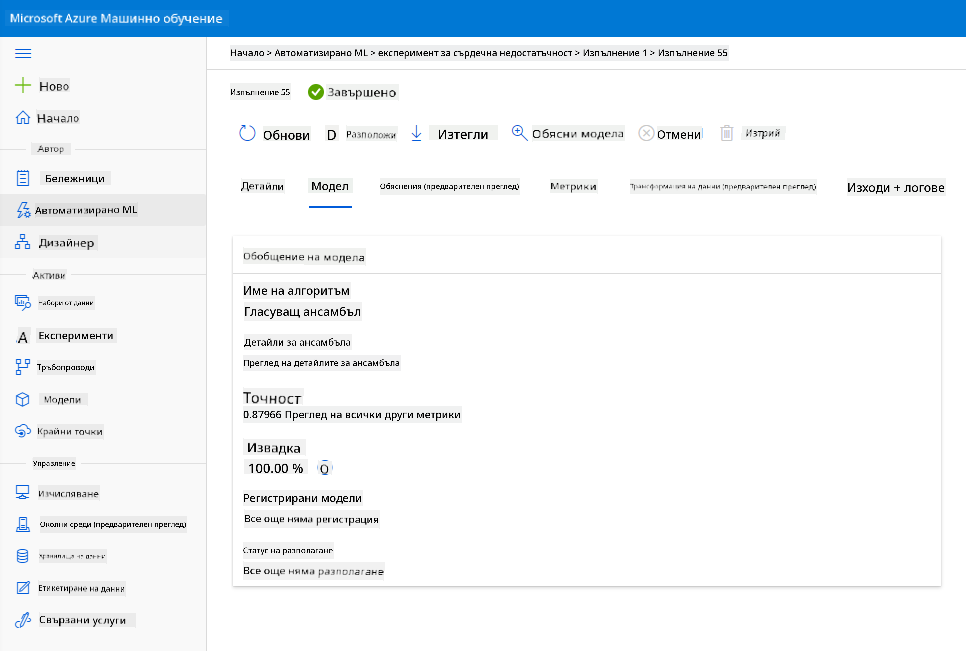
- Дайте име, описание, тип изчисление (Azure Container Instance), активирайте автентикацията и натиснете "Deploy". Тази стъпка може да отнеме около 20 минути. Процесът на разполагане включва няколко стъпки, включително регистриране на модела, генериране на ресурси и конфигурирането им за уеб услугата. Статусът на разполагане ще се появи под "Deploy status". Натискайте "Refresh" периодично, за да проверите статуса. Когато статусът е "Healthy", разполагането е завършено и работи.
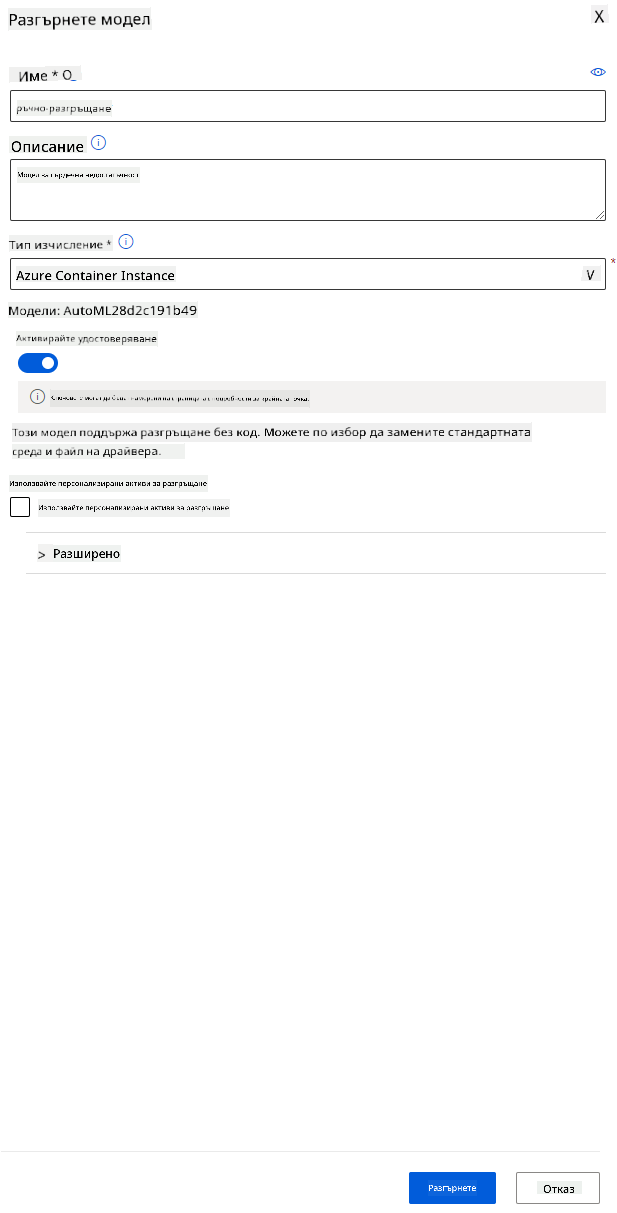
- След като разполагането приключи, кликнете върху таба "Endpoint" и изберете крайната точка, която току-що разположихте. Тук можете да намерите всички детайли за крайната точка.
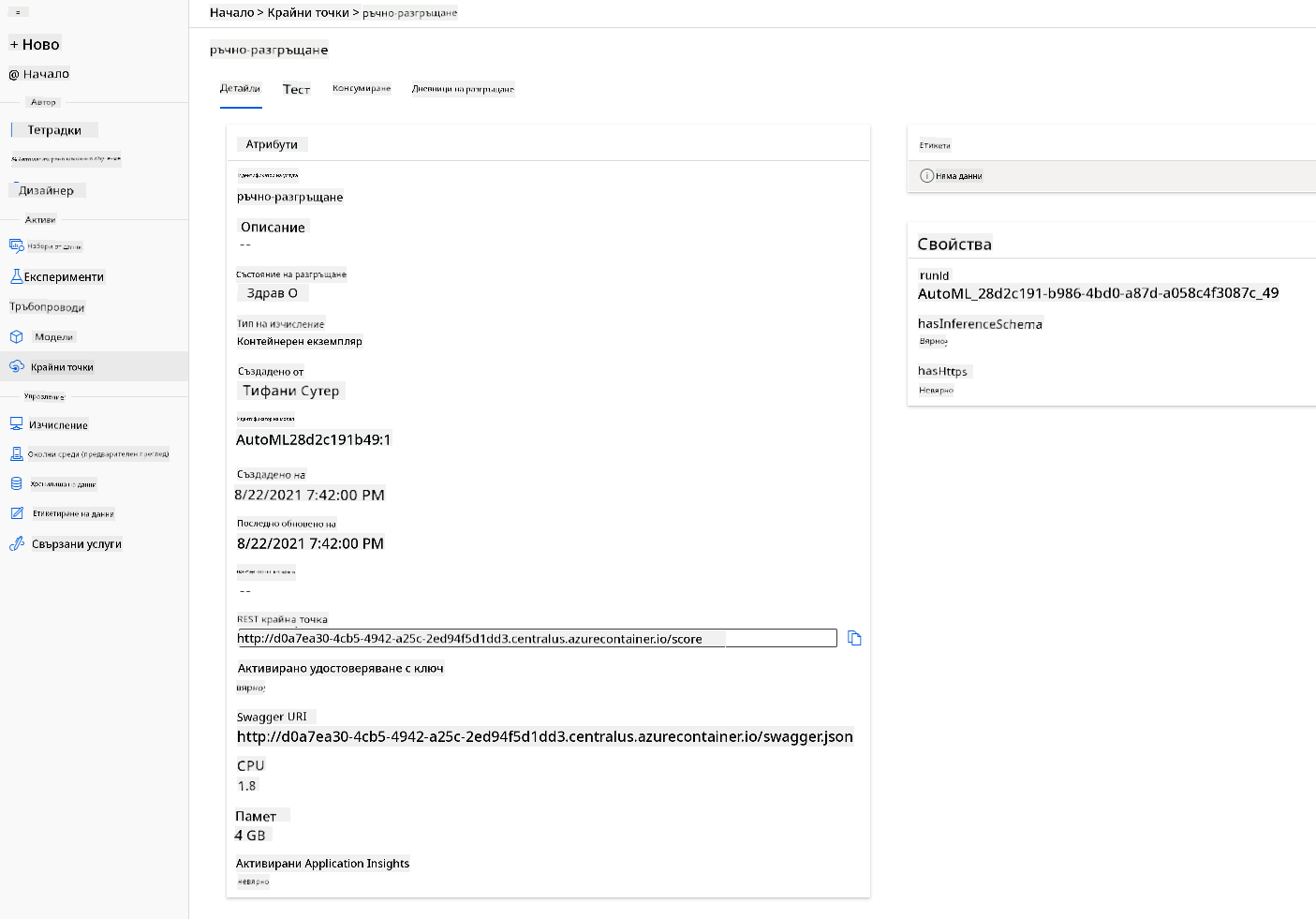
Страхотно! Сега, когато имаме разположен модел, можем да започнем консумацията на крайната точка.
3.2 Консумация на крайна точка
Кликнете върху таба "Consume". Тук ще намерите REST крайната точка и Python скрипт в опцията за консумация. Отделете време, за да прочетете Python кода.
Този скрипт може да бъде изпълнен директно от вашата локална машина и ще консумира крайната точка.
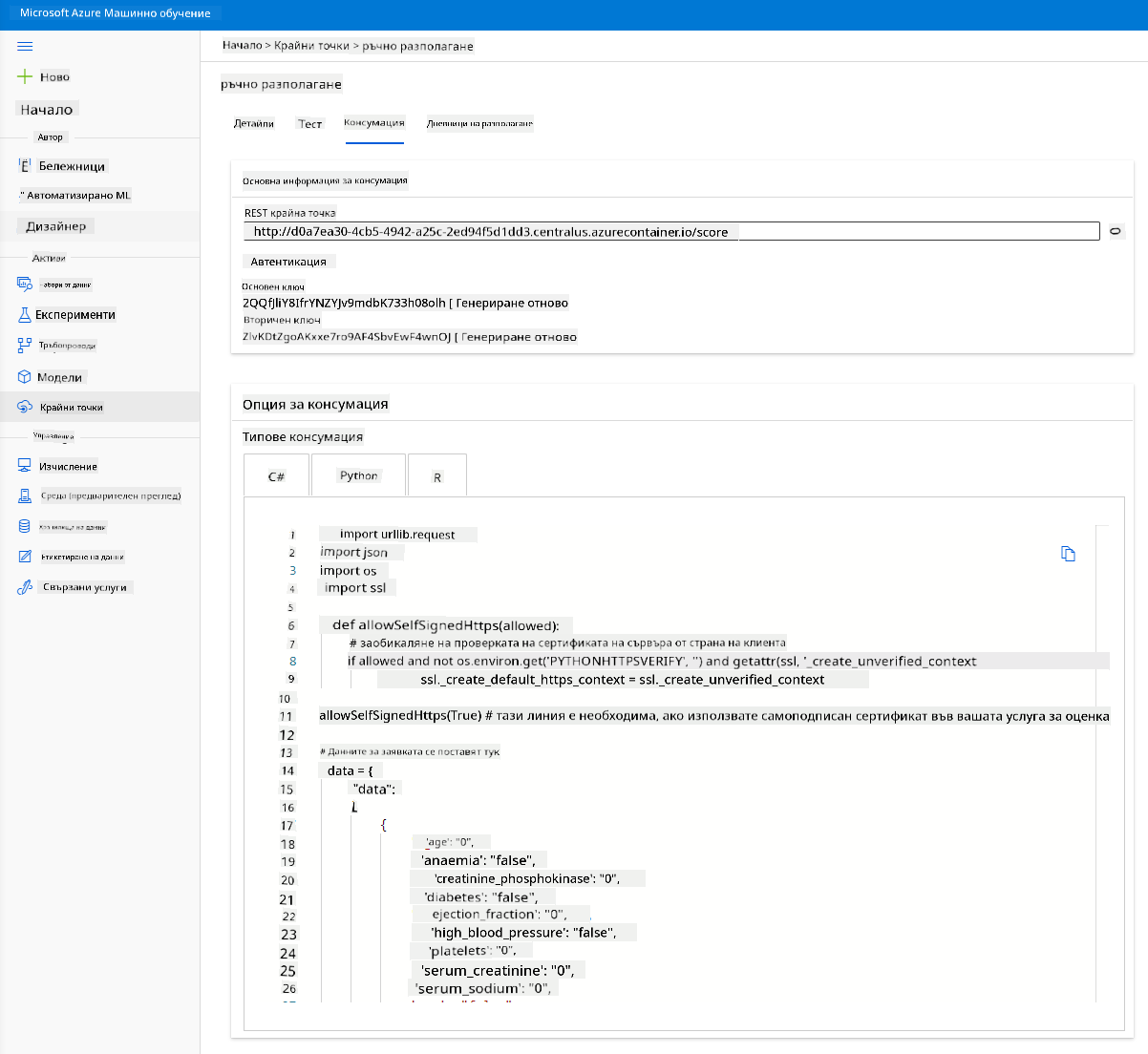
Отделете момент, за да разгледате тези два реда код:
url = 'http://98e3715f-xxxx-xxxx-xxxx-9ec22d57b796.centralus.azurecontainer.io/score'
api_key = '' # Replace this with the API key for the web service
Променливата url е REST крайната точка, намерена в таба "Consume", а променливата api_key е основният ключ, също намерен в таба "Consume" (само ако сте активирали автентикацията). Това е начинът, по който скриптът може да консумира крайната точка.
- Когато изпълните скрипта, трябва да видите следния изход:
b'"{\\"result\\": [true]}"'
Това означава, че прогнозата за сърдечна недостатъчност за дадените данни е вярна. Това има смисъл, защото ако погледнете по-отблизо данните, автоматично генерирани в скрипта, всичко е зададено на 0 и false по подразбиране. Можете да промените данните със следния примерен вход:
data = {
"data":
[
{
'age': "0",
'anaemia': "false",
'creatinine_phosphokinase': "0",
'diabetes': "false",
'ejection_fraction': "0",
'high_blood_pressure': "false",
'platelets': "0",
'serum_creatinine': "0",
'serum_sodium': "0",
'sex': "false",
'smoking': "false",
'time': "0",
},
{
'age': "60",
'anaemia': "false",
'creatinine_phosphokinase': "500",
'diabetes': "false",
'ejection_fraction': "38",
'high_blood_pressure': "false",
'platelets': "260000",
'serum_creatinine': "1.40",
'serum_sodium': "137",
'sex': "false",
'smoking': "false",
'time': "130",
},
],
}
Скриптът трябва да върне:
python b'"{\\"result\\": [true, false]}"'
Поздравления! Току-що консумирахте разположения модел и го обучихте в Azure ML!
ЗАБЕЛЕЖКА: След като приключите с проекта, не забравяйте да изтриете всички ресурси.
🚀 Предизвикателство
Разгледайте внимателно обясненията на модела и детайлите, които AutoML е генерирал за най-добрите модели. Опитайте се да разберете защо най-добрият модел е по-добър от останалите. Какви алгоритми са били сравнени? Какви са разликите между тях? Защо най-добрият модел се представя по-добре в този случай?
Тест след лекцията
Преглед и самостоятелно обучение
В този урок научихте как да обучите, разположите и консумирате модел за прогнозиране на риска от сърдечна недостатъчност с малко или без код в облака. Ако все още не сте го направили, задълбочете се в обясненията на модела, които AutoML е генерирал за най-добрите модели, и се опитайте да разберете защо най-добрият модел е по-добър от останалите.
Можете да се задълбочите в AutoML с малко или без код, като прочетете тази документация.
Задание
Проект за наука за данни с малко или без код в Azure ML
Отказ от отговорност:
Този документ е преведен с помощта на AI услуга за превод Co-op Translator. Въпреки че се стремим към точност, моля, имайте предвид, че автоматизираните преводи може да съдържат грешки или неточности. Оригиналният документ на неговия роден език трябва да се счита за авторитетен източник. За критична информация се препоръчва професионален човешки превод. Ние не носим отговорност за каквито и да е недоразумения или погрешни интерпретации, произтичащи от използването на този превод.