# شماریات اور احتمال کا مختصر تعارف
| ](../../sketchnotes/04-Statistics-Probability.png)|
|:---:|
| شماریات اور احتمال - _Sketchnote by [@nitya](https://twitter.com/nitya)_ |
شماریات اور احتمال کا نظریہ ریاضی کے دو ایسے شعبے ہیں جو ڈیٹا سائنس کے لیے انتہائی اہم ہیں۔ ڈیٹا کے ساتھ کام کرنا ممکن ہے چاہے آپ کو ریاضی کی گہری سمجھ نہ ہو، لیکن کچھ بنیادی تصورات جاننا ہمیشہ بہتر ہوتا ہے۔ یہاں ہم ایک مختصر تعارف پیش کریں گے جو آپ کو آغاز کرنے میں مدد دے گا۔
[](https://youtu.be/Z5Zy85g4Yjw)
## [لیکچر سے پہلے کا کوئز](https://ff-quizzes.netlify.app/en/ds/quiz/6)
## احتمال اور بے ترتیب متغیرات
**احتمال** ایک ایسا عدد ہے جو 0 اور 1 کے درمیان ہوتا ہے اور کسی **واقعے** کے ہونے کے امکان کو ظاہر کرتا ہے۔ یہ مثبت نتائج (جو واقعے کی طرف لے جاتے ہیں) کی تعداد کو کل نتائج کی تعداد سے تقسیم کر کے نکالا جاتا ہے، بشرطیکہ تمام نتائج یکساں طور پر ممکن ہوں۔ مثال کے طور پر، جب ہم ایک ڈائس پھینکتے ہیں، تو جفت عدد آنے کا احتمال 3/6 = 0.5 ہے۔
جب ہم واقعات کی بات کرتے ہیں، تو ہم **بے ترتیب متغیرات** استعمال کرتے ہیں۔ مثال کے طور پر، وہ بے ترتیب متغیر جو ڈائس پھینکنے پر حاصل ہونے والے عدد کی نمائندگی کرتا ہے، وہ 1 سے 6 تک کے عدد لے سکتا ہے۔ 1 سے 6 تک کے اعداد کے مجموعے کو **نمونہ جگہ** کہا جاتا ہے۔ ہم بے ترتیب متغیر کے کسی خاص قدر لینے کے احتمال کے بارے میں بات کر سکتے ہیں، مثلاً P(X=3)=1/6۔
پچھلی مثال میں بے ترتیب متغیر کو **منقطع** کہا جاتا ہے، کیونکہ اس کی نمونہ جگہ گنی جا سکتی ہے، یعنی الگ الگ قدریں ہیں جنہیں شمار کیا جا سکتا ہے۔ کچھ صورتوں میں نمونہ جگہ حقیقی اعداد کے کسی وقفے یا پورے مجموعے پر مشتمل ہوتی ہے۔ ایسے متغیرات کو **مسلسل** کہا جاتا ہے۔ ایک اچھی مثال بس کے آنے کا وقت ہے۔
## احتمال کی تقسیم
منقطع بے ترتیب متغیرات کے معاملے میں، ہر واقعے کے احتمال کو ایک فنکشن P(X) کے ذریعے بیان کرنا آسان ہے۔ نمونہ جگہ *S* سے ہر قدر *s* کے لیے یہ 0 سے 1 کے درمیان ایک عدد دے گا، اس طرح کہ تمام واقعات کے لیے P(X=s) کی تمام قدروں کا مجموعہ 1 ہوگا۔
سب سے مشہور منقطع تقسیم **یکساں تقسیم** ہے، جس میں N عناصر کی نمونہ جگہ ہوتی ہے، اور ہر ایک کے لیے احتمال 1/N ہوتا ہے۔
مسلسل متغیر کی احتمال تقسیم کو بیان کرنا زیادہ مشکل ہے، جس کی قدریں کسی وقفے [a,b] یا حقیقی اعداد کے پورے مجموعے ℝ سے لی جاتی ہیں۔ بس کے آنے کے وقت کے معاملے پر غور کریں۔ حقیقت میں، کسی خاص وقت *t* پر بس کے بالکل اسی وقت آنے کا احتمال 0 ہے!
> اب آپ جانتے ہیں کہ 0 احتمال والے واقعات ہوتے ہیں، اور اکثر ہوتے ہیں! کم از کم ہر بار جب بس آتی ہے!
ہم صرف اس بات کے احتمال کے بارے میں بات کر سکتے ہیں کہ کوئی متغیر کسی دیے گئے وقفے میں آتا ہے، مثلاً P(t1≤X2)۔ اس صورت میں، احتمال کی تقسیم کو **احتمال کثافت فنکشن** p(x) کے ذریعے بیان کیا جاتا ہے، اس طرح کہ
 یہاں ہم **انٹر-چارٹائل رینج** IQR=Q3-Q1 اور نام نہاد **آؤٹ لائرز** کا بھی حساب لگاتے ہیں - وہ قدریں جو حدود [Q1-1.5*IQR,Q3+1.5*IQR] سے باہر ہوتی ہیں۔
اگر تقسیم محدود ہو اور ممکنہ قدروں کی تعداد کم ہو، تو ایک اچھی "عام" قدر وہ ہوتی ہے جو سب سے زیادہ بار ظاہر ہو، جسے **موڈ** کہا جاتا ہے۔ یہ اکثر زمرہ وار ڈیٹا پر لاگو ہوتا ہے، جیسے رنگ۔ فرض کریں کہ ہمارے پاس لوگوں کے دو گروپ ہیں - کچھ جو سرخ رنگ کو ترجیح دیتے ہیں، اور دوسرے جو نیلے رنگ کو ترجیح دیتے ہیں۔ اگر ہم رنگوں کو نمبروں سے کوڈ کریں، تو پسندیدہ رنگ کے لیے اوسط قدر کہیں نارنجی-سبز کے درمیان ہوگی، جو کسی بھی گروپ کی اصل ترجیح کی نشاندہی نہیں کرتی۔ تاہم، موڈ یا تو ایک رنگ ہوگا، یا دونوں رنگ، اگر ان کے لیے ووٹ دینے والے لوگوں کی تعداد برابر ہو (اس صورت میں ہم نمونے کو **ملٹی موڈل** کہتے ہیں)۔
## حقیقی دنیا کے ڈیٹا
جب ہم حقیقی زندگی کے ڈیٹا کا تجزیہ کرتے ہیں، تو وہ اکثر بے ترتیب متغیرات نہیں ہوتے، اس معنی میں کہ ہم نامعلوم نتائج کے ساتھ تجربات نہیں کر رہے ہوتے۔ مثال کے طور پر، بیس بال کھلاڑیوں کی ایک ٹیم پر غور کریں، اور ان کے جسمانی ڈیٹا جیسے قد، وزن اور عمر۔ یہ اعداد و شمار بالکل بے ترتیب نہیں ہیں، لیکن ہم پھر بھی وہی ریاضیاتی تصورات لاگو کر سکتے ہیں۔ مثال کے طور پر، لوگوں کے وزن کی ترتیب کو کسی بے ترتیب متغیر سے نکالی گئی قدروں کی ترتیب سمجھا جا سکتا ہے۔ نیچے بیس بال کے کھلاڑیوں کے وزن کی ترتیب دی گئی ہے، جو [میجر لیگ بیس بال](http://mlb.mlb.com/index.jsp) سے لی گئی ہے، اور [اس ڈیٹاسیٹ](http://wiki.stat.ucla.edu/socr/index.php/SOCR_Data_MLB_HeightsWeights) سے حاصل کی گئی ہے (آپ کی سہولت کے لیے، صرف پہلے 20 قدریں دکھائی گئی ہیں):
```
[180.0, 215.0, 210.0, 210.0, 188.0, 176.0, 209.0, 200.0, 231.0, 180.0, 188.0, 180.0, 185.0, 160.0, 180.0, 185.0, 197.0, 189.0, 185.0, 219.0]
```
> **نوٹ**: اس ڈیٹاسیٹ کے ساتھ کام کرنے کی مثال دیکھنے کے لیے، [ساتھ والے نوٹ بک](notebook.ipynb) پر نظر ڈالیں۔ اس سبق کے دوران کئی چیلنجز بھی ہیں، اور آپ انہیں اس نوٹ بک میں کچھ کوڈ شامل کر کے مکمل کر سکتے ہیں۔ اگر آپ کو ڈیٹا پر کام کرنے کا طریقہ معلوم نہیں ہے، تو فکر نہ کریں - ہم بعد میں Python کا استعمال کرتے ہوئے ڈیٹا پر کام کرنے پر واپس آئیں گے۔ اگر آپ کو Jupyter Notebook میں کوڈ چلانے کا طریقہ معلوم نہیں ہے، تو [اس مضمون](https://soshnikov.com/education/how-to-execute-notebooks-from-github/) پر نظر ڈالیں۔
یہاں ہمارے ڈیٹا کے لیے اوسط، میڈین اور چارٹائلز کو ظاہر کرنے والا باکس پلاٹ ہے:
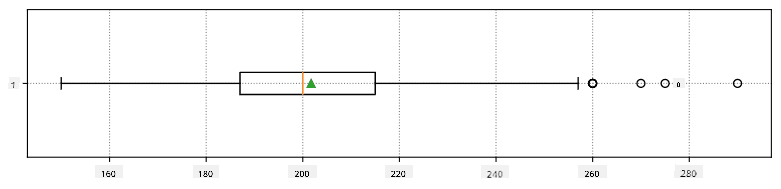
چونکہ ہمارے ڈیٹا میں مختلف کھلاڑیوں کے **کردار** کے بارے میں معلومات شامل ہیں، ہم کردار کے لحاظ سے بھی باکس پلاٹ بنا سکتے ہیں - یہ ہمیں یہ سمجھنے کی اجازت دے گا کہ کرداروں کے درمیان پیرامیٹرز کی قدریں کیسے مختلف ہیں۔ اس بار ہم قد پر غور کریں گے:
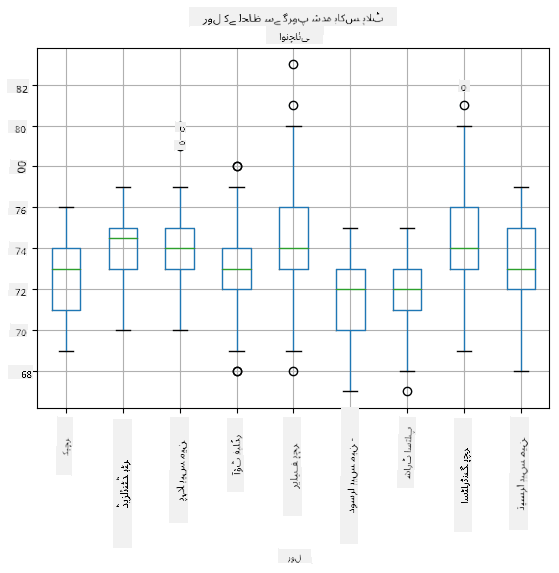
یہ ڈایاگرام ظاہر کرتا ہے کہ، اوسطاً، پہلے بیس مین کا قد دوسرے بیس مین کے قد سے زیادہ ہے۔ اس سبق کے بعد کے حصے میں ہم سیکھیں گے کہ ہم اس مفروضے کو مزید رسمی طور پر کیسے جانچ سکتے ہیں، اور یہ ظاہر کر سکتے ہیں کہ ہمارا ڈیٹا شماریاتی طور پر اہم ہے۔
> جب ہم حقیقی دنیا کے ڈیٹا پر کام کرتے ہیں، تو ہم فرض کرتے ہیں کہ تمام ڈیٹا پوائنٹس کسی احتمال تقسیم سے نکالے گئے نمونے ہیں۔ یہ مفروضہ ہمیں مشین لرننگ تکنیکوں کو لاگو کرنے اور کام کرنے والے پیش گوئی ماڈلز بنانے کی اجازت دیتا ہے۔
یہ دیکھنے کے لیے کہ ہمارے ڈیٹا کی تقسیم کیا ہے، ہم ایک گراف بنا سکتے ہیں جسے **ہسٹوگرام** کہا جاتا ہے۔ X-محور مختلف وزن کے وقفوں (نام نہاد **بِنز**) کی تعداد پر مشتمل ہوگا، اور عمودی محور یہ ظاہر کرے گا کہ ہمارے بے ترتیب متغیر کا نمونہ کسی دیے گئے وقفے میں کتنی بار آیا۔
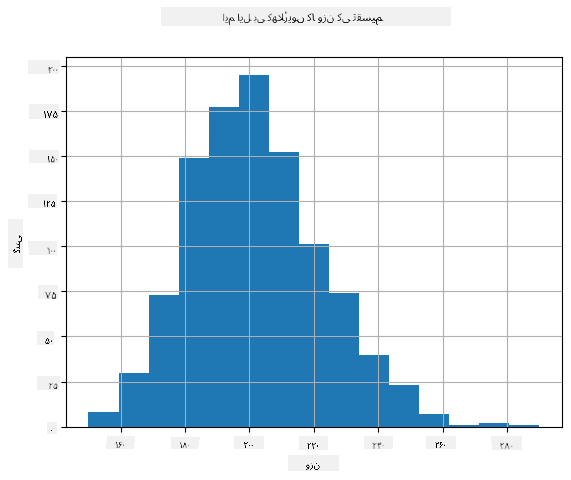
اس ہسٹوگرام سے آپ دیکھ سکتے ہیں کہ تمام قدریں ایک خاص اوسط وزن کے گرد مرکوز ہیں، اور جتنا ہم اس وزن سے دور جاتے ہیں - اتنے ہی کم وزن کی قدریں ملتی ہیں۔ یعنی، یہ بہت غیر ممکن ہے کہ کسی بیس بال کھلاڑی کا وزن اوسط وزن سے بہت مختلف ہو۔ وزن کا واریانس یہ ظاہر کرتا ہے کہ وزن اوسط سے کتنا مختلف ہو سکتا ہے۔
> اگر ہم دوسرے لوگوں کے وزن لیں، جو بیس بال لیگ سے نہیں ہیں، تو تقسیم مختلف ہونے کا امکان ہے۔ تاہم، تقسیم کی شکل وہی رہے گی، لیکن اوسط اور واریانس بدل جائیں گے۔ لہذا، اگر ہم اپنے ماڈل کو بیس بال کھلاڑیوں پر تربیت دیں، تو یہ یونیورسٹی کے طلباء پر لاگو ہونے پر غلط نتائج دے سکتا ہے، کیونکہ بنیادی تقسیم مختلف ہے۔
## معمولی تقسیم
وزن کی وہ تقسیم جو ہم نے اوپر دیکھی، وہ بہت عام ہے، اور حقیقی دنیا سے لی گئی بہت سی پیمائشیں اسی قسم کی تقسیم کی پیروی کرتی ہیں، لیکن مختلف اوسط اور واریانس کے ساتھ۔ اس تقسیم کو **معمولی تقسیم** کہا جاتا ہے، اور یہ شماریات میں بہت اہم کردار ادا کرتی ہے۔
معمولی تقسیم کا استعمال ممکنہ بیس بال کھلاڑیوں کے بے ترتیب وزن پیدا کرنے کا ایک درست طریقہ ہے۔ ایک بار جب ہم اوسط وزن `mean` اور معیاری انحراف `std` جان لیں، تو ہم 1000 وزن کے نمونے درج ذیل طریقے سے پیدا کر سکتے ہیں:
```python
samples = np.random.normal(mean,std,1000)
```
اگر ہم پیدا کیے گئے نمونوں کا ہسٹوگرام بنائیں، تو ہمیں اوپر دکھائی گئی تصویر سے بہت ملتی جلتی تصویر نظر آئے گی۔ اور اگر ہم نمونوں کی تعداد اور بِنز کی تعداد بڑھائیں، تو ہم معمولی تقسیم کی ایک تصویر بنا سکتے ہیں جو مثالی کے قریب ہو:
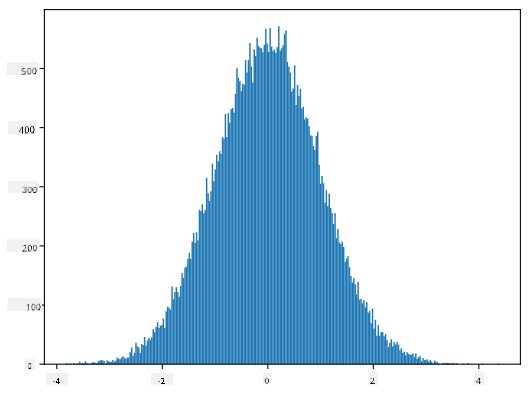
*معمولی تقسیم اوسط=0 اور معیاری انحراف=1 کے ساتھ*
## اعتماد کے وقفے
جب ہم بیس بال کھلاڑیوں کے وزن کی بات کرتے ہیں، تو ہم فرض کرتے ہیں کہ ایک خاص **بے ترتیب متغیر W** ہے جو تمام بیس بال کھلاڑیوں کے وزن کی مثالی احتمال تقسیم سے مطابقت رکھتا ہے (جسے **آبادی** کہا جاتا ہے)۔ ہمارے وزن کی ترتیب تمام بیس بال کھلاڑیوں کے ایک ذیلی مجموعے سے مطابقت رکھتی ہے جسے ہم **نمونہ** کہتے ہیں۔ ایک دلچسپ سوال یہ ہے کہ کیا ہم W کی تقسیم کے پیرامیٹرز، یعنی آبادی کی اوسط اور واریانس، جان سکتے ہیں؟
سب سے آسان جواب یہ ہوگا کہ ہمارے نمونے کی اوسط اور واریانس کا حساب لگایا جائے۔ تاہم، یہ ہو سکتا ہے کہ ہمارا بے ترتیب نمونہ مکمل آبادی کی درست نمائندگی نہ کرے۔ اس لیے **اعتماد کے وقفے** کے بارے میں بات کرنا معنی خیز ہے۔
> **اعتماد کا وقفہ** آبادی کی حقیقی اوسط کا تخمینہ ہے جو ہمارے نمونے کو مدنظر رکھتے ہوئے ایک خاص احتمال (یا **اعتماد کی سطح**) کے ساتھ درست ہے۔
فرض کریں کہ ہمارے پاس ایک نمونہ X...
<سب>
1, ..., Xn ہماری تقسیم سے۔ ہر بار جب ہم اپنی تقسیم سے ایک نمونہ نکالتے ہیں، تو ہمیں مختلف اوسط قدر μ ملے گی۔ اس طرح، μ کو ایک تصادفی متغیر سمجھا جا سکتا ہے۔ ایک **اعتماد وقفہ** اعتماد p کے ساتھ دو قدروں (Lp,Rp) کا جوڑا ہے، اس طرح کہ **P**(Lp≤μ≤Rp) = p، یعنی ماپی گئی اوسط قدر کے وقفے میں آنے کا امکان p کے برابر ہے۔
یہ ہمارے مختصر تعارف سے آگے بڑھتا ہے کہ ان اعتماد وقفوں کو تفصیل سے کیسے حساب کیا جاتا ہے۔ مزید تفصیلات [ویکیپیڈیا](https://en.wikipedia.org/wiki/Confidence_interval) پر دیکھی جا سکتی ہیں۔ مختصراً، ہم آبادی کی حقیقی اوسط کے مقابلے میں حساب شدہ نمونہ اوسط کی تقسیم کو بیان کرتے ہیں، جسے **اسٹوڈنٹ تقسیم** کہا جاتا ہے۔
> **دلچسپ حقیقت**: اسٹوڈنٹ تقسیم کا نام ریاضی دان ولیم سیلی گوسیٹ کے نام پر رکھا گیا ہے، جنہوں نے اپنا مقالہ "اسٹوڈنٹ" کے قلمی نام سے شائع کیا۔ وہ گنیز بریوری میں کام کرتے تھے، اور ایک روایت کے مطابق، ان کے آجر نہیں چاہتے تھے کہ عام عوام کو معلوم ہو کہ وہ خام مال کے معیار کا تعین کرنے کے لیے شماریاتی ٹیسٹ استعمال کر رہے ہیں۔
اگر ہم اپنی آبادی کی اوسط μ کو اعتماد p کے ساتھ اندازہ لگانا چاہتے ہیں، تو ہمیں اسٹوڈنٹ تقسیم A کے *(1-p)/2-ویں صدک* کو لینا ہوگا، جو یا تو جدولوں سے لیا جا سکتا ہے، یا شماریاتی سافٹ ویئر (مثلاً Python، R، وغیرہ) کے کچھ بلٹ ان فنکشنز کا استعمال کرتے ہوئے کمپیوٹر پر نکالا جا سکتا ہے۔ پھر μ کے لیے وقفہ X±A*D/√n ہوگا، جہاں X نمونے کی حاصل شدہ اوسط ہے، D معیاری انحراف ہے۔
> **نوٹ**: ہم [آزادی کی ڈگریاں](https://en.wikipedia.org/wiki/Degrees_of_freedom_(statistics)) کے ایک اہم تصور پر بحث کو بھی چھوڑ دیتے ہیں، جو اسٹوڈنٹ تقسیم کے حوالے سے اہم ہے۔ اس تصور کو گہرائی سے سمجھنے کے لیے آپ شماریات پر مزید مکمل کتابوں کا حوالہ دے سکتے ہیں۔
وزن اور قد کے لیے اعتماد وقفہ کا حساب لگانے کی ایک مثال [ساتھ دی گئی نوٹ بکس](notebook.ipynb) میں دی گئی ہے۔
| p | وزن کی اوسط |
|-----|-----------|
| 0.85 | 201.73±0.94 |
| 0.90 | 201.73±1.08 |
| 0.95 | 201.73±1.28 |
نوٹ کریں کہ جتنا زیادہ اعتماد کا امکان ہوگا، اتنا ہی وسیع اعتماد وقفہ ہوگا۔
## مفروضہ ٹیسٹنگ
ہمارے بیس بال کھلاڑیوں کے ڈیٹا سیٹ میں مختلف کھلاڑیوں کے کردار ہیں، جنہیں نیچے خلاصہ کیا جا سکتا ہے (دیکھیں [ساتھ دی گئی نوٹ بک](notebook.ipynb) کہ یہ جدول کیسے حساب کیا جا سکتا ہے):
| کردار | قد | وزن | تعداد |
|------|--------|--------|-------|
| کیچر | 72.723684 | 204.328947 | 76 |
| ڈیزگنیٹڈ ہٹر | 74.222222 | 220.888889 | 18 |
| فرسٹ بیس مین | 74.000000 | 213.109091 | 55 |
| آؤٹ فیلڈر | 73.010309 | 199.113402 | 194 |
| ریلیف پچر | 74.374603 | 203.517460 | 315 |
| سیکنڈ بیس مین | 71.362069 | 184.344828 | 58 |
| شارٹ اسٹاپ | 71.903846 | 182.923077 | 52 |
| اسٹارٹنگ پچر | 74.719457 | 205.163636 | 221 |
| تھرڈ بیس مین | 73.044444 | 200.955556 | 45 |
ہم دیکھ سکتے ہیں کہ فرسٹ بیس مین کی اوسط قد سیکنڈ بیس مین سے زیادہ ہے۔ اس طرح، ہم یہ نتیجہ اخذ کرنے کی طرف مائل ہو سکتے ہیں کہ **فرسٹ بیس مین سیکنڈ بیس مین سے لمبے ہیں**۔
> اس بیان کو **مفروضہ** کہا جاتا ہے، کیونکہ ہمیں معلوم نہیں کہ یہ حقیقتاً درست ہے یا نہیں۔
تاہم، یہ ہمیشہ واضح نہیں ہوتا کہ آیا ہم یہ نتیجہ اخذ کر سکتے ہیں۔ اوپر کی بحث سے ہم جانتے ہیں کہ ہر اوسط کے ساتھ ایک اعتماد وقفہ منسلک ہوتا ہے، اور اس طرح یہ فرق محض ایک شماریاتی غلطی ہو سکتا ہے۔ ہمیں اپنے مفروضے کو جانچنے کے لیے کچھ زیادہ رسمی طریقہ درکار ہے۔
آئیے فرسٹ اور سیکنڈ بیس مین کے قد کے لیے اعتماد وقفے الگ الگ حساب کرتے ہیں:
| اعتماد | فرسٹ بیس مین | سیکنڈ بیس مین |
|------------|---------------|----------------|
| 0.85 | 73.62..74.38 | 71.04..71.69 |
| 0.90 | 73.56..74.44 | 70.99..71.73 |
| 0.95 | 73.47..74.53 | 70.92..71.81 |
ہم دیکھ سکتے ہیں کہ کسی بھی اعتماد کے تحت وقفے اوورلیپ نہیں کرتے۔ یہ ہمارے مفروضے کو ثابت کرتا ہے کہ فرسٹ بیس مین سیکنڈ بیس مین سے لمبے ہیں۔
زیادہ رسمی طور پر، ہم جس مسئلے کو حل کر رہے ہیں وہ یہ دیکھنا ہے کہ **دو احتمال تقسیمات ایک جیسی ہیں**، یا کم از کم ان کے پیرامیٹرز ایک جیسے ہیں۔ تقسیم کے لحاظ سے، ہمیں اس کے لیے مختلف ٹیسٹ استعمال کرنے کی ضرورت ہے۔ اگر ہمیں معلوم ہو کہ ہماری تقسیمات نارمل ہیں، تو ہم **[اسٹوڈنٹ ٹی-ٹیسٹ](https://en.wikipedia.org/wiki/Student%27s_t-test)** کا اطلاق کر سکتے ہیں۔
اسٹوڈنٹ ٹی-ٹیسٹ میں، ہم نام نہاد **t-ویلیو** کا حساب لگاتے ہیں، جو اوسط کے فرق کو ظاہر کرتا ہے، تغیر کو مدنظر رکھتے ہوئے۔ یہ ظاہر کیا گیا ہے کہ t-ویلیو **اسٹوڈنٹ تقسیم** کی پیروی کرتی ہے، جو ہمیں دیے گئے اعتماد کی سطح **p** کے لیے حد قدر حاصل کرنے کی اجازت دیتی ہے (یہ حساب کیا جا سکتا ہے، یا عددی جدولوں میں دیکھا جا سکتا ہے)۔ ہم پھر t-ویلیو کا اس حد سے موازنہ کرتے ہیں تاکہ مفروضے کو منظور یا مسترد کریں۔
Python میں، ہم **SciPy** پیکج استعمال کر سکتے ہیں، جس میں `ttest_ind` فنکشن شامل ہے (بہت سے دیگر مفید شماریاتی فنکشنز کے علاوہ!)۔ یہ ہمارے لیے t-ویلیو کا حساب لگاتا ہے، اور اعتماد p-ویلیو کا ریورس لوک اپ بھی کرتا ہے، تاکہ ہم صرف اعتماد کو دیکھ کر نتیجہ اخذ کر سکیں۔
مثال کے طور پر، فرسٹ اور سیکنڈ بیس مین کے قد کے موازنے نے ہمیں درج ذیل نتائج دیے:
```python
from scipy.stats import ttest_ind
tval, pval = ttest_ind(df.loc[df['Role']=='First_Baseman',['Height']], df.loc[df['Role']=='Designated_Hitter',['Height']],equal_var=False)
print(f"T-value = {tval[0]:.2f}\nP-value: {pval[0]}")
```
```
T-value = 7.65
P-value: 9.137321189738925e-12
```
ہمارے معاملے میں، p-ویلیو بہت کم ہے، جس کا مطلب ہے کہ فرسٹ بیس مین کے لمبے ہونے کے حق میں مضبوط شواہد موجود ہیں۔
دیگر مختلف قسم کے مفروضے بھی ہیں جنہیں ہم جانچنا چاہتے ہیں، مثلاً:
* یہ ثابت کرنا کہ دیا گیا نمونہ کسی تقسیم کی پیروی کرتا ہے۔ ہمارے معاملے میں ہم نے فرض کیا ہے کہ قد نارمل تقسیم شدہ ہیں، لیکن اس کے لیے رسمی شماریاتی تصدیق کی ضرورت ہے۔
* یہ ثابت کرنا کہ نمونے کی اوسط قدر کسی پہلے سے متعین قدر کے مطابق ہے۔
* مختلف نمونوں کی اوسط کا موازنہ کرنا (مثلاً مختلف عمر کے گروپوں میں خوشی کی سطح میں کیا فرق ہے)۔
## بڑے نمبروں کا قانون اور مرکزی حد نظریہ
نارمل تقسیم اتنی اہم ہونے کی ایک وجہ نام نہاد **مرکزی حد نظریہ** ہے۔ فرض کریں کہ ہمارے پاس آزاد N قدروں X1, ..., XN کا ایک بڑا نمونہ ہے، جو کسی بھی تقسیم سے نمونہ لیا گیا ہے جس کی اوسط μ اور تغیر σ2 ہے۔ پھر، کافی بڑے N کے لیے (دوسرے الفاظ میں، جب N→∞)، اوسط ΣiXi نارمل تقسیم شدہ ہوگی، جس کی اوسط μ اور تغیر σ2/N ہوگی۔
> مرکزی حد نظریہ کی ایک اور تشریح یہ ہے کہ قطع نظر تقسیم کے، جب آپ کسی بھی تصادفی متغیر قدروں کے مجموعے کی اوسط کا حساب لگاتے ہیں تو آپ نارمل تقسیم کے ساتھ ختم ہوتے ہیں۔
مرکزی حد نظریہ سے یہ بھی معلوم ہوتا ہے کہ، جب N→∞، نمونے کی اوسط کے μ کے برابر ہونے کا امکان 1 بن جاتا ہے۔ اسے **بڑے نمبروں کا قانون** کہا جاتا ہے۔
## کوویریئنس اور تعلق
ڈیٹا سائنس کے کاموں میں سے ایک کام ڈیٹا کے درمیان تعلقات تلاش کرنا ہے۔ ہم کہتے ہیں کہ دو سلسلے **تعلق رکھتے ہیں** جب وہ ایک ہی وقت میں ایک جیسا رویہ ظاہر کرتے ہیں، یعنی وہ یا تو ایک ساتھ بڑھتے/گرتے ہیں، یا ایک سلسلہ بڑھتا ہے جب دوسرا گرتا ہے اور اس کے برعکس۔ دوسرے الفاظ میں، دو سلسلوں کے درمیان کچھ تعلق معلوم ہوتا ہے۔
> تعلق ضروری نہیں کہ دو سلسلوں کے درمیان سببی تعلق کی نشاندہی کرے؛ بعض اوقات دونوں متغیرات کسی بیرونی وجہ پر منحصر ہو سکتے ہیں، یا یہ محض اتفاقیہ ہو سکتا ہے کہ دونوں سلسلے تعلق رکھتے ہیں۔ تاہم، مضبوط ریاضیاتی تعلق اس بات کی اچھی نشاندہی ہے کہ دو متغیرات کسی نہ کسی طرح جڑے ہوئے ہیں۔
ریاضیاتی طور پر، دو تصادفی متغیرات کے درمیان تعلق ظاہر کرنے والا بنیادی تصور **کوویریئنس** ہے، جسے اس طرح حساب کیا جاتا ہے: Cov(X,Y) = **E**\[(X-**E**(X))(Y-**E**(Y))\]۔ ہم دونوں متغیرات کے ان کے اوسط قدروں سے انحراف کا حساب لگاتے ہیں، اور پھر ان انحرافات کی پیداوار۔ اگر دونوں متغیرات ایک ساتھ انحراف کرتے ہیں، تو پیداوار ہمیشہ ایک مثبت قدر ہوگی، جو مثبت کوویریئنس میں شامل ہوگی۔ اگر دونوں متغیرات غیر مطابقت سے انحراف کرتے ہیں (یعنی ایک اوسط سے نیچے گرتا ہے جب دوسرا اوسط سے اوپر بڑھتا ہے)، تو ہمیں ہمیشہ منفی نمبر ملیں گے، جو منفی کوویریئنس میں شامل ہوں گے۔ اگر انحرافات آزاد ہیں، تو وہ تقریباً صفر میں شامل ہوں گے۔
کوویریئنس کی مطلق قدر ہمیں یہ نہیں بتاتی کہ تعلق کتنا بڑا ہے، کیونکہ یہ اصل قدروں کی شدت پر منحصر ہے۔ اسے معمول پر لانے کے لیے، ہم کوویریئنس کو دونوں متغیرات کے معیاری انحراف سے تقسیم کر سکتے ہیں، تاکہ **تعلق** حاصل کیا جا سکے۔ اچھی بات یہ ہے کہ تعلق ہمیشہ [-1,1] کی حد میں ہوتا ہے، جہاں 1 قدروں کے درمیان مضبوط مثبت تعلق کی نشاندہی کرتا ہے، -1 - مضبوط منفی تعلق، اور 0 - بالکل کوئی تعلق نہیں (متغیرات آزاد ہیں)۔
**مثال**: ہم بیس بال کھلاڑیوں کے وزن اور قد کے درمیان تعلق کا حساب لگا سکتے ہیں جو اوپر ذکر کردہ ڈیٹا سیٹ سے ہے:
```python
print(np.corrcoef(weights,heights))
```
نتیجتاً، ہمیں **تعلق میٹرکس** اس طرح ملتا ہے:
```
array([[1. , 0.52959196],
[0.52959196, 1. ]])
```
> تعلق میٹرکس C کسی بھی تعداد کے ان پٹ سلسلوں S1, ..., Sn کے لیے حساب کیا جا سکتا ہے۔ Cij کی قدر Si اور Sj کے درمیان تعلق ہے، اور قطر کے عناصر ہمیشہ 1 ہوتے ہیں (جو Si کی خود تعلق بھی ہے)۔
ہمارے معاملے میں، قدر 0.53 اس بات کی نشاندہی کرتی ہے کہ کسی شخص کے وزن اور قد کے درمیان کچھ تعلق ہے۔ ہم ایک قدر کے دوسرے کے خلاف اسکیٹر پلاٹ بھی بنا سکتے ہیں تاکہ تعلق کو بصری طور پر دیکھا جا سکے:
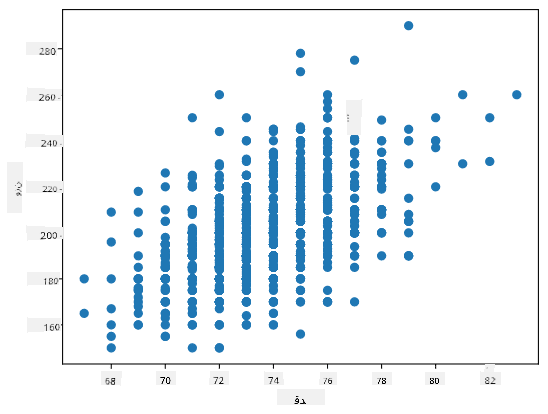
> تعلق اور کوویریئنس کی مزید مثالیں [ساتھ دی گئی نوٹ بک](notebook.ipynb) میں دیکھی جا سکتی ہیں۔
## نتیجہ
اس سیکشن میں، ہم نے سیکھا:
* ڈیٹا کی بنیادی شماریاتی خصوصیات، جیسے اوسط، تغیر، موڈ اور چوتھائی
* تصادفی متغیرات کی مختلف تقسیمات، بشمول نارمل تقسیم
* مختلف خصوصیات کے درمیان تعلق کیسے تلاش کریں
* کچھ مفروضوں کو ثابت کرنے کے لیے ریاضی اور شماریات کے مضبوط آلات کا استعمال کیسے کریں
* دیے گئے ڈیٹا نمونے کے لیے تصادفی متغیر کے اعتماد وقفے کا حساب کیسے کریں
جبکہ یہ احتمال اور شماریات کے اندر موجود موضوعات کی مکمل فہرست نہیں ہے، یہ اس کورس میں آپ کو ایک اچھی شروعات دینے کے لیے کافی ہونی چاہیے۔
## 🚀 چیلنج
نوٹ بک میں دیے گئے نمونہ کوڈ کا استعمال کرتے ہوئے دیگر مفروضوں کو جانچیں:
1. فرسٹ بیس مین سیکنڈ بیس مین سے بڑے ہیں۔
2. فرسٹ بیس مین تھرڈ بیس مین سے لمبے ہیں۔
3. شارٹ اسٹاپ سیکنڈ بیس مین سے لمبے ہیں۔
## [لیکچر کے بعد کا کوئز](https://ff-quizzes.netlify.app/en/ds/quiz/7)
## جائزہ اور خود مطالعہ
احتمال اور شماریات ایک اتنا وسیع موضوع ہے کہ یہ اپنے کورس کا مستحق ہے۔ اگر آپ نظریہ میں مزید گہرائی میں جانا چاہتے ہیں، تو آپ درج ذیل کتابوں میں سے کچھ پڑھنا جاری رکھ سکتے ہیں:
1. [کارلوس فرنینڈیز-گرانڈا](https://cims.nyu.edu/~cfgranda/) نیویارک یونیورسٹی سے، کے عظیم لیکچر نوٹس [Probability and Statistics for Data Science](https://cims.nyu.edu/~cfgranda/pages/stuff/probability_stats_for_DS.pdf) (آن لائن دستیاب)
1. [پیٹر اور اینڈریو بروس۔ ڈیٹا سائنسدانوں کے لیے عملی شماریات۔](https://www.oreilly.com/library/view/practical-statistics-for/9781491952955/) [[R میں نمونہ کوڈ](https://github.com/andrewgbruce/statistics-for-data-scientists)]۔
1. [جیمز ڈی. ملر۔ ڈیٹا سائنس کے لیے شماریات](https://www.packtpub.com/product/statistics-for-data-science/9781788290678) [[R میں نمونہ کوڈ](https://github.com/PacktPublishing/Statistics-for-Data-Science)]۔
## اسائنمنٹ
[چھوٹا ذیابیطس مطالعہ](assignment.md)
## کریڈٹس
یہ سبق [دمیتری سوشنیکوف](http://soshnikov.com) کے ذریعہ ♥️ کے ساتھ تحریر کیا گیا ہے۔
---
**ڈسکلیمر**:
یہ دستاویز AI ترجمہ سروس [Co-op Translator](https://github.com/Azure/co-op-translator) کا استعمال کرتے ہوئے ترجمہ کی گئی ہے۔ ہم درستگی کے لیے کوشش کرتے ہیں، لیکن براہ کرم آگاہ رہیں کہ خودکار ترجمے میں غلطیاں یا خامیاں ہو سکتی ہیں۔ اصل دستاویز کو اس کی اصل زبان میں مستند ذریعہ سمجھا جانا چاہیے۔ اہم معلومات کے لیے، پیشہ ور انسانی ترجمہ کی سفارش کی جاتی ہے۔ اس ترجمے کے استعمال سے پیدا ہونے والی کسی بھی غلط فہمی یا غلط تشریح کے لیے ہم ذمہ دار نہیں ہیں۔
یہاں ہم **انٹر-چارٹائل رینج** IQR=Q3-Q1 اور نام نہاد **آؤٹ لائرز** کا بھی حساب لگاتے ہیں - وہ قدریں جو حدود [Q1-1.5*IQR,Q3+1.5*IQR] سے باہر ہوتی ہیں۔
اگر تقسیم محدود ہو اور ممکنہ قدروں کی تعداد کم ہو، تو ایک اچھی "عام" قدر وہ ہوتی ہے جو سب سے زیادہ بار ظاہر ہو، جسے **موڈ** کہا جاتا ہے۔ یہ اکثر زمرہ وار ڈیٹا پر لاگو ہوتا ہے، جیسے رنگ۔ فرض کریں کہ ہمارے پاس لوگوں کے دو گروپ ہیں - کچھ جو سرخ رنگ کو ترجیح دیتے ہیں، اور دوسرے جو نیلے رنگ کو ترجیح دیتے ہیں۔ اگر ہم رنگوں کو نمبروں سے کوڈ کریں، تو پسندیدہ رنگ کے لیے اوسط قدر کہیں نارنجی-سبز کے درمیان ہوگی، جو کسی بھی گروپ کی اصل ترجیح کی نشاندہی نہیں کرتی۔ تاہم، موڈ یا تو ایک رنگ ہوگا، یا دونوں رنگ، اگر ان کے لیے ووٹ دینے والے لوگوں کی تعداد برابر ہو (اس صورت میں ہم نمونے کو **ملٹی موڈل** کہتے ہیں)۔
## حقیقی دنیا کے ڈیٹا
جب ہم حقیقی زندگی کے ڈیٹا کا تجزیہ کرتے ہیں، تو وہ اکثر بے ترتیب متغیرات نہیں ہوتے، اس معنی میں کہ ہم نامعلوم نتائج کے ساتھ تجربات نہیں کر رہے ہوتے۔ مثال کے طور پر، بیس بال کھلاڑیوں کی ایک ٹیم پر غور کریں، اور ان کے جسمانی ڈیٹا جیسے قد، وزن اور عمر۔ یہ اعداد و شمار بالکل بے ترتیب نہیں ہیں، لیکن ہم پھر بھی وہی ریاضیاتی تصورات لاگو کر سکتے ہیں۔ مثال کے طور پر، لوگوں کے وزن کی ترتیب کو کسی بے ترتیب متغیر سے نکالی گئی قدروں کی ترتیب سمجھا جا سکتا ہے۔ نیچے بیس بال کے کھلاڑیوں کے وزن کی ترتیب دی گئی ہے، جو [میجر لیگ بیس بال](http://mlb.mlb.com/index.jsp) سے لی گئی ہے، اور [اس ڈیٹاسیٹ](http://wiki.stat.ucla.edu/socr/index.php/SOCR_Data_MLB_HeightsWeights) سے حاصل کی گئی ہے (آپ کی سہولت کے لیے، صرف پہلے 20 قدریں دکھائی گئی ہیں):
```
[180.0, 215.0, 210.0, 210.0, 188.0, 176.0, 209.0, 200.0, 231.0, 180.0, 188.0, 180.0, 185.0, 160.0, 180.0, 185.0, 197.0, 189.0, 185.0, 219.0]
```
> **نوٹ**: اس ڈیٹاسیٹ کے ساتھ کام کرنے کی مثال دیکھنے کے لیے، [ساتھ والے نوٹ بک](notebook.ipynb) پر نظر ڈالیں۔ اس سبق کے دوران کئی چیلنجز بھی ہیں، اور آپ انہیں اس نوٹ بک میں کچھ کوڈ شامل کر کے مکمل کر سکتے ہیں۔ اگر آپ کو ڈیٹا پر کام کرنے کا طریقہ معلوم نہیں ہے، تو فکر نہ کریں - ہم بعد میں Python کا استعمال کرتے ہوئے ڈیٹا پر کام کرنے پر واپس آئیں گے۔ اگر آپ کو Jupyter Notebook میں کوڈ چلانے کا طریقہ معلوم نہیں ہے، تو [اس مضمون](https://soshnikov.com/education/how-to-execute-notebooks-from-github/) پر نظر ڈالیں۔
یہاں ہمارے ڈیٹا کے لیے اوسط، میڈین اور چارٹائلز کو ظاہر کرنے والا باکس پلاٹ ہے:

چونکہ ہمارے ڈیٹا میں مختلف کھلاڑیوں کے **کردار** کے بارے میں معلومات شامل ہیں، ہم کردار کے لحاظ سے بھی باکس پلاٹ بنا سکتے ہیں - یہ ہمیں یہ سمجھنے کی اجازت دے گا کہ کرداروں کے درمیان پیرامیٹرز کی قدریں کیسے مختلف ہیں۔ اس بار ہم قد پر غور کریں گے:

یہ ڈایاگرام ظاہر کرتا ہے کہ، اوسطاً، پہلے بیس مین کا قد دوسرے بیس مین کے قد سے زیادہ ہے۔ اس سبق کے بعد کے حصے میں ہم سیکھیں گے کہ ہم اس مفروضے کو مزید رسمی طور پر کیسے جانچ سکتے ہیں، اور یہ ظاہر کر سکتے ہیں کہ ہمارا ڈیٹا شماریاتی طور پر اہم ہے۔
> جب ہم حقیقی دنیا کے ڈیٹا پر کام کرتے ہیں، تو ہم فرض کرتے ہیں کہ تمام ڈیٹا پوائنٹس کسی احتمال تقسیم سے نکالے گئے نمونے ہیں۔ یہ مفروضہ ہمیں مشین لرننگ تکنیکوں کو لاگو کرنے اور کام کرنے والے پیش گوئی ماڈلز بنانے کی اجازت دیتا ہے۔
یہ دیکھنے کے لیے کہ ہمارے ڈیٹا کی تقسیم کیا ہے، ہم ایک گراف بنا سکتے ہیں جسے **ہسٹوگرام** کہا جاتا ہے۔ X-محور مختلف وزن کے وقفوں (نام نہاد **بِنز**) کی تعداد پر مشتمل ہوگا، اور عمودی محور یہ ظاہر کرے گا کہ ہمارے بے ترتیب متغیر کا نمونہ کسی دیے گئے وقفے میں کتنی بار آیا۔

اس ہسٹوگرام سے آپ دیکھ سکتے ہیں کہ تمام قدریں ایک خاص اوسط وزن کے گرد مرکوز ہیں، اور جتنا ہم اس وزن سے دور جاتے ہیں - اتنے ہی کم وزن کی قدریں ملتی ہیں۔ یعنی، یہ بہت غیر ممکن ہے کہ کسی بیس بال کھلاڑی کا وزن اوسط وزن سے بہت مختلف ہو۔ وزن کا واریانس یہ ظاہر کرتا ہے کہ وزن اوسط سے کتنا مختلف ہو سکتا ہے۔
> اگر ہم دوسرے لوگوں کے وزن لیں، جو بیس بال لیگ سے نہیں ہیں، تو تقسیم مختلف ہونے کا امکان ہے۔ تاہم، تقسیم کی شکل وہی رہے گی، لیکن اوسط اور واریانس بدل جائیں گے۔ لہذا، اگر ہم اپنے ماڈل کو بیس بال کھلاڑیوں پر تربیت دیں، تو یہ یونیورسٹی کے طلباء پر لاگو ہونے پر غلط نتائج دے سکتا ہے، کیونکہ بنیادی تقسیم مختلف ہے۔
## معمولی تقسیم
وزن کی وہ تقسیم جو ہم نے اوپر دیکھی، وہ بہت عام ہے، اور حقیقی دنیا سے لی گئی بہت سی پیمائشیں اسی قسم کی تقسیم کی پیروی کرتی ہیں، لیکن مختلف اوسط اور واریانس کے ساتھ۔ اس تقسیم کو **معمولی تقسیم** کہا جاتا ہے، اور یہ شماریات میں بہت اہم کردار ادا کرتی ہے۔
معمولی تقسیم کا استعمال ممکنہ بیس بال کھلاڑیوں کے بے ترتیب وزن پیدا کرنے کا ایک درست طریقہ ہے۔ ایک بار جب ہم اوسط وزن `mean` اور معیاری انحراف `std` جان لیں، تو ہم 1000 وزن کے نمونے درج ذیل طریقے سے پیدا کر سکتے ہیں:
```python
samples = np.random.normal(mean,std,1000)
```
اگر ہم پیدا کیے گئے نمونوں کا ہسٹوگرام بنائیں، تو ہمیں اوپر دکھائی گئی تصویر سے بہت ملتی جلتی تصویر نظر آئے گی۔ اور اگر ہم نمونوں کی تعداد اور بِنز کی تعداد بڑھائیں، تو ہم معمولی تقسیم کی ایک تصویر بنا سکتے ہیں جو مثالی کے قریب ہو:

*معمولی تقسیم اوسط=0 اور معیاری انحراف=1 کے ساتھ*
## اعتماد کے وقفے
جب ہم بیس بال کھلاڑیوں کے وزن کی بات کرتے ہیں، تو ہم فرض کرتے ہیں کہ ایک خاص **بے ترتیب متغیر W** ہے جو تمام بیس بال کھلاڑیوں کے وزن کی مثالی احتمال تقسیم سے مطابقت رکھتا ہے (جسے **آبادی** کہا جاتا ہے)۔ ہمارے وزن کی ترتیب تمام بیس بال کھلاڑیوں کے ایک ذیلی مجموعے سے مطابقت رکھتی ہے جسے ہم **نمونہ** کہتے ہیں۔ ایک دلچسپ سوال یہ ہے کہ کیا ہم W کی تقسیم کے پیرامیٹرز، یعنی آبادی کی اوسط اور واریانس، جان سکتے ہیں؟
سب سے آسان جواب یہ ہوگا کہ ہمارے نمونے کی اوسط اور واریانس کا حساب لگایا جائے۔ تاہم، یہ ہو سکتا ہے کہ ہمارا بے ترتیب نمونہ مکمل آبادی کی درست نمائندگی نہ کرے۔ اس لیے **اعتماد کے وقفے** کے بارے میں بات کرنا معنی خیز ہے۔
> **اعتماد کا وقفہ** آبادی کی حقیقی اوسط کا تخمینہ ہے جو ہمارے نمونے کو مدنظر رکھتے ہوئے ایک خاص احتمال (یا **اعتماد کی سطح**) کے ساتھ درست ہے۔
فرض کریں کہ ہمارے پاس ایک نمونہ X...
<سب>
1, ..., Xn ہماری تقسیم سے۔ ہر بار جب ہم اپنی تقسیم سے ایک نمونہ نکالتے ہیں، تو ہمیں مختلف اوسط قدر μ ملے گی۔ اس طرح، μ کو ایک تصادفی متغیر سمجھا جا سکتا ہے۔ ایک **اعتماد وقفہ** اعتماد p کے ساتھ دو قدروں (Lp,Rp) کا جوڑا ہے، اس طرح کہ **P**(Lp≤μ≤Rp) = p، یعنی ماپی گئی اوسط قدر کے وقفے میں آنے کا امکان p کے برابر ہے۔
یہ ہمارے مختصر تعارف سے آگے بڑھتا ہے کہ ان اعتماد وقفوں کو تفصیل سے کیسے حساب کیا جاتا ہے۔ مزید تفصیلات [ویکیپیڈیا](https://en.wikipedia.org/wiki/Confidence_interval) پر دیکھی جا سکتی ہیں۔ مختصراً، ہم آبادی کی حقیقی اوسط کے مقابلے میں حساب شدہ نمونہ اوسط کی تقسیم کو بیان کرتے ہیں، جسے **اسٹوڈنٹ تقسیم** کہا جاتا ہے۔
> **دلچسپ حقیقت**: اسٹوڈنٹ تقسیم کا نام ریاضی دان ولیم سیلی گوسیٹ کے نام پر رکھا گیا ہے، جنہوں نے اپنا مقالہ "اسٹوڈنٹ" کے قلمی نام سے شائع کیا۔ وہ گنیز بریوری میں کام کرتے تھے، اور ایک روایت کے مطابق، ان کے آجر نہیں چاہتے تھے کہ عام عوام کو معلوم ہو کہ وہ خام مال کے معیار کا تعین کرنے کے لیے شماریاتی ٹیسٹ استعمال کر رہے ہیں۔
اگر ہم اپنی آبادی کی اوسط μ کو اعتماد p کے ساتھ اندازہ لگانا چاہتے ہیں، تو ہمیں اسٹوڈنٹ تقسیم A کے *(1-p)/2-ویں صدک* کو لینا ہوگا، جو یا تو جدولوں سے لیا جا سکتا ہے، یا شماریاتی سافٹ ویئر (مثلاً Python، R، وغیرہ) کے کچھ بلٹ ان فنکشنز کا استعمال کرتے ہوئے کمپیوٹر پر نکالا جا سکتا ہے۔ پھر μ کے لیے وقفہ X±A*D/√n ہوگا، جہاں X نمونے کی حاصل شدہ اوسط ہے، D معیاری انحراف ہے۔
> **نوٹ**: ہم [آزادی کی ڈگریاں](https://en.wikipedia.org/wiki/Degrees_of_freedom_(statistics)) کے ایک اہم تصور پر بحث کو بھی چھوڑ دیتے ہیں، جو اسٹوڈنٹ تقسیم کے حوالے سے اہم ہے۔ اس تصور کو گہرائی سے سمجھنے کے لیے آپ شماریات پر مزید مکمل کتابوں کا حوالہ دے سکتے ہیں۔
وزن اور قد کے لیے اعتماد وقفہ کا حساب لگانے کی ایک مثال [ساتھ دی گئی نوٹ بکس](notebook.ipynb) میں دی گئی ہے۔
| p | وزن کی اوسط |
|-----|-----------|
| 0.85 | 201.73±0.94 |
| 0.90 | 201.73±1.08 |
| 0.95 | 201.73±1.28 |
نوٹ کریں کہ جتنا زیادہ اعتماد کا امکان ہوگا، اتنا ہی وسیع اعتماد وقفہ ہوگا۔
## مفروضہ ٹیسٹنگ
ہمارے بیس بال کھلاڑیوں کے ڈیٹا سیٹ میں مختلف کھلاڑیوں کے کردار ہیں، جنہیں نیچے خلاصہ کیا جا سکتا ہے (دیکھیں [ساتھ دی گئی نوٹ بک](notebook.ipynb) کہ یہ جدول کیسے حساب کیا جا سکتا ہے):
| کردار | قد | وزن | تعداد |
|------|--------|--------|-------|
| کیچر | 72.723684 | 204.328947 | 76 |
| ڈیزگنیٹڈ ہٹر | 74.222222 | 220.888889 | 18 |
| فرسٹ بیس مین | 74.000000 | 213.109091 | 55 |
| آؤٹ فیلڈر | 73.010309 | 199.113402 | 194 |
| ریلیف پچر | 74.374603 | 203.517460 | 315 |
| سیکنڈ بیس مین | 71.362069 | 184.344828 | 58 |
| شارٹ اسٹاپ | 71.903846 | 182.923077 | 52 |
| اسٹارٹنگ پچر | 74.719457 | 205.163636 | 221 |
| تھرڈ بیس مین | 73.044444 | 200.955556 | 45 |
ہم دیکھ سکتے ہیں کہ فرسٹ بیس مین کی اوسط قد سیکنڈ بیس مین سے زیادہ ہے۔ اس طرح، ہم یہ نتیجہ اخذ کرنے کی طرف مائل ہو سکتے ہیں کہ **فرسٹ بیس مین سیکنڈ بیس مین سے لمبے ہیں**۔
> اس بیان کو **مفروضہ** کہا جاتا ہے، کیونکہ ہمیں معلوم نہیں کہ یہ حقیقتاً درست ہے یا نہیں۔
تاہم، یہ ہمیشہ واضح نہیں ہوتا کہ آیا ہم یہ نتیجہ اخذ کر سکتے ہیں۔ اوپر کی بحث سے ہم جانتے ہیں کہ ہر اوسط کے ساتھ ایک اعتماد وقفہ منسلک ہوتا ہے، اور اس طرح یہ فرق محض ایک شماریاتی غلطی ہو سکتا ہے۔ ہمیں اپنے مفروضے کو جانچنے کے لیے کچھ زیادہ رسمی طریقہ درکار ہے۔
آئیے فرسٹ اور سیکنڈ بیس مین کے قد کے لیے اعتماد وقفے الگ الگ حساب کرتے ہیں:
| اعتماد | فرسٹ بیس مین | سیکنڈ بیس مین |
|------------|---------------|----------------|
| 0.85 | 73.62..74.38 | 71.04..71.69 |
| 0.90 | 73.56..74.44 | 70.99..71.73 |
| 0.95 | 73.47..74.53 | 70.92..71.81 |
ہم دیکھ سکتے ہیں کہ کسی بھی اعتماد کے تحت وقفے اوورلیپ نہیں کرتے۔ یہ ہمارے مفروضے کو ثابت کرتا ہے کہ فرسٹ بیس مین سیکنڈ بیس مین سے لمبے ہیں۔
زیادہ رسمی طور پر، ہم جس مسئلے کو حل کر رہے ہیں وہ یہ دیکھنا ہے کہ **دو احتمال تقسیمات ایک جیسی ہیں**، یا کم از کم ان کے پیرامیٹرز ایک جیسے ہیں۔ تقسیم کے لحاظ سے، ہمیں اس کے لیے مختلف ٹیسٹ استعمال کرنے کی ضرورت ہے۔ اگر ہمیں معلوم ہو کہ ہماری تقسیمات نارمل ہیں، تو ہم **[اسٹوڈنٹ ٹی-ٹیسٹ](https://en.wikipedia.org/wiki/Student%27s_t-test)** کا اطلاق کر سکتے ہیں۔
اسٹوڈنٹ ٹی-ٹیسٹ میں، ہم نام نہاد **t-ویلیو** کا حساب لگاتے ہیں، جو اوسط کے فرق کو ظاہر کرتا ہے، تغیر کو مدنظر رکھتے ہوئے۔ یہ ظاہر کیا گیا ہے کہ t-ویلیو **اسٹوڈنٹ تقسیم** کی پیروی کرتی ہے، جو ہمیں دیے گئے اعتماد کی سطح **p** کے لیے حد قدر حاصل کرنے کی اجازت دیتی ہے (یہ حساب کیا جا سکتا ہے، یا عددی جدولوں میں دیکھا جا سکتا ہے)۔ ہم پھر t-ویلیو کا اس حد سے موازنہ کرتے ہیں تاکہ مفروضے کو منظور یا مسترد کریں۔
Python میں، ہم **SciPy** پیکج استعمال کر سکتے ہیں، جس میں `ttest_ind` فنکشن شامل ہے (بہت سے دیگر مفید شماریاتی فنکشنز کے علاوہ!)۔ یہ ہمارے لیے t-ویلیو کا حساب لگاتا ہے، اور اعتماد p-ویلیو کا ریورس لوک اپ بھی کرتا ہے، تاکہ ہم صرف اعتماد کو دیکھ کر نتیجہ اخذ کر سکیں۔
مثال کے طور پر، فرسٹ اور سیکنڈ بیس مین کے قد کے موازنے نے ہمیں درج ذیل نتائج دیے:
```python
from scipy.stats import ttest_ind
tval, pval = ttest_ind(df.loc[df['Role']=='First_Baseman',['Height']], df.loc[df['Role']=='Designated_Hitter',['Height']],equal_var=False)
print(f"T-value = {tval[0]:.2f}\nP-value: {pval[0]}")
```
```
T-value = 7.65
P-value: 9.137321189738925e-12
```
ہمارے معاملے میں، p-ویلیو بہت کم ہے، جس کا مطلب ہے کہ فرسٹ بیس مین کے لمبے ہونے کے حق میں مضبوط شواہد موجود ہیں۔
دیگر مختلف قسم کے مفروضے بھی ہیں جنہیں ہم جانچنا چاہتے ہیں، مثلاً:
* یہ ثابت کرنا کہ دیا گیا نمونہ کسی تقسیم کی پیروی کرتا ہے۔ ہمارے معاملے میں ہم نے فرض کیا ہے کہ قد نارمل تقسیم شدہ ہیں، لیکن اس کے لیے رسمی شماریاتی تصدیق کی ضرورت ہے۔
* یہ ثابت کرنا کہ نمونے کی اوسط قدر کسی پہلے سے متعین قدر کے مطابق ہے۔
* مختلف نمونوں کی اوسط کا موازنہ کرنا (مثلاً مختلف عمر کے گروپوں میں خوشی کی سطح میں کیا فرق ہے)۔
## بڑے نمبروں کا قانون اور مرکزی حد نظریہ
نارمل تقسیم اتنی اہم ہونے کی ایک وجہ نام نہاد **مرکزی حد نظریہ** ہے۔ فرض کریں کہ ہمارے پاس آزاد N قدروں X1, ..., XN کا ایک بڑا نمونہ ہے، جو کسی بھی تقسیم سے نمونہ لیا گیا ہے جس کی اوسط μ اور تغیر σ2 ہے۔ پھر، کافی بڑے N کے لیے (دوسرے الفاظ میں، جب N→∞)، اوسط ΣiXi نارمل تقسیم شدہ ہوگی، جس کی اوسط μ اور تغیر σ2/N ہوگی۔
> مرکزی حد نظریہ کی ایک اور تشریح یہ ہے کہ قطع نظر تقسیم کے، جب آپ کسی بھی تصادفی متغیر قدروں کے مجموعے کی اوسط کا حساب لگاتے ہیں تو آپ نارمل تقسیم کے ساتھ ختم ہوتے ہیں۔
مرکزی حد نظریہ سے یہ بھی معلوم ہوتا ہے کہ، جب N→∞، نمونے کی اوسط کے μ کے برابر ہونے کا امکان 1 بن جاتا ہے۔ اسے **بڑے نمبروں کا قانون** کہا جاتا ہے۔
## کوویریئنس اور تعلق
ڈیٹا سائنس کے کاموں میں سے ایک کام ڈیٹا کے درمیان تعلقات تلاش کرنا ہے۔ ہم کہتے ہیں کہ دو سلسلے **تعلق رکھتے ہیں** جب وہ ایک ہی وقت میں ایک جیسا رویہ ظاہر کرتے ہیں، یعنی وہ یا تو ایک ساتھ بڑھتے/گرتے ہیں، یا ایک سلسلہ بڑھتا ہے جب دوسرا گرتا ہے اور اس کے برعکس۔ دوسرے الفاظ میں، دو سلسلوں کے درمیان کچھ تعلق معلوم ہوتا ہے۔
> تعلق ضروری نہیں کہ دو سلسلوں کے درمیان سببی تعلق کی نشاندہی کرے؛ بعض اوقات دونوں متغیرات کسی بیرونی وجہ پر منحصر ہو سکتے ہیں، یا یہ محض اتفاقیہ ہو سکتا ہے کہ دونوں سلسلے تعلق رکھتے ہیں۔ تاہم، مضبوط ریاضیاتی تعلق اس بات کی اچھی نشاندہی ہے کہ دو متغیرات کسی نہ کسی طرح جڑے ہوئے ہیں۔
ریاضیاتی طور پر، دو تصادفی متغیرات کے درمیان تعلق ظاہر کرنے والا بنیادی تصور **کوویریئنس** ہے، جسے اس طرح حساب کیا جاتا ہے: Cov(X,Y) = **E**\[(X-**E**(X))(Y-**E**(Y))\]۔ ہم دونوں متغیرات کے ان کے اوسط قدروں سے انحراف کا حساب لگاتے ہیں، اور پھر ان انحرافات کی پیداوار۔ اگر دونوں متغیرات ایک ساتھ انحراف کرتے ہیں، تو پیداوار ہمیشہ ایک مثبت قدر ہوگی، جو مثبت کوویریئنس میں شامل ہوگی۔ اگر دونوں متغیرات غیر مطابقت سے انحراف کرتے ہیں (یعنی ایک اوسط سے نیچے گرتا ہے جب دوسرا اوسط سے اوپر بڑھتا ہے)، تو ہمیں ہمیشہ منفی نمبر ملیں گے، جو منفی کوویریئنس میں شامل ہوں گے۔ اگر انحرافات آزاد ہیں، تو وہ تقریباً صفر میں شامل ہوں گے۔
کوویریئنس کی مطلق قدر ہمیں یہ نہیں بتاتی کہ تعلق کتنا بڑا ہے، کیونکہ یہ اصل قدروں کی شدت پر منحصر ہے۔ اسے معمول پر لانے کے لیے، ہم کوویریئنس کو دونوں متغیرات کے معیاری انحراف سے تقسیم کر سکتے ہیں، تاکہ **تعلق** حاصل کیا جا سکے۔ اچھی بات یہ ہے کہ تعلق ہمیشہ [-1,1] کی حد میں ہوتا ہے، جہاں 1 قدروں کے درمیان مضبوط مثبت تعلق کی نشاندہی کرتا ہے، -1 - مضبوط منفی تعلق، اور 0 - بالکل کوئی تعلق نہیں (متغیرات آزاد ہیں)۔
**مثال**: ہم بیس بال کھلاڑیوں کے وزن اور قد کے درمیان تعلق کا حساب لگا سکتے ہیں جو اوپر ذکر کردہ ڈیٹا سیٹ سے ہے:
```python
print(np.corrcoef(weights,heights))
```
نتیجتاً، ہمیں **تعلق میٹرکس** اس طرح ملتا ہے:
```
array([[1. , 0.52959196],
[0.52959196, 1. ]])
```
> تعلق میٹرکس C کسی بھی تعداد کے ان پٹ سلسلوں S1, ..., Sn کے لیے حساب کیا جا سکتا ہے۔ Cij کی قدر Si اور Sj کے درمیان تعلق ہے، اور قطر کے عناصر ہمیشہ 1 ہوتے ہیں (جو Si کی خود تعلق بھی ہے)۔
ہمارے معاملے میں، قدر 0.53 اس بات کی نشاندہی کرتی ہے کہ کسی شخص کے وزن اور قد کے درمیان کچھ تعلق ہے۔ ہم ایک قدر کے دوسرے کے خلاف اسکیٹر پلاٹ بھی بنا سکتے ہیں تاکہ تعلق کو بصری طور پر دیکھا جا سکے:

> تعلق اور کوویریئنس کی مزید مثالیں [ساتھ دی گئی نوٹ بک](notebook.ipynb) میں دیکھی جا سکتی ہیں۔
## نتیجہ
اس سیکشن میں، ہم نے سیکھا:
* ڈیٹا کی بنیادی شماریاتی خصوصیات، جیسے اوسط، تغیر، موڈ اور چوتھائی
* تصادفی متغیرات کی مختلف تقسیمات، بشمول نارمل تقسیم
* مختلف خصوصیات کے درمیان تعلق کیسے تلاش کریں
* کچھ مفروضوں کو ثابت کرنے کے لیے ریاضی اور شماریات کے مضبوط آلات کا استعمال کیسے کریں
* دیے گئے ڈیٹا نمونے کے لیے تصادفی متغیر کے اعتماد وقفے کا حساب کیسے کریں
جبکہ یہ احتمال اور شماریات کے اندر موجود موضوعات کی مکمل فہرست نہیں ہے، یہ اس کورس میں آپ کو ایک اچھی شروعات دینے کے لیے کافی ہونی چاہیے۔
## 🚀 چیلنج
نوٹ بک میں دیے گئے نمونہ کوڈ کا استعمال کرتے ہوئے دیگر مفروضوں کو جانچیں:
1. فرسٹ بیس مین سیکنڈ بیس مین سے بڑے ہیں۔
2. فرسٹ بیس مین تھرڈ بیس مین سے لمبے ہیں۔
3. شارٹ اسٹاپ سیکنڈ بیس مین سے لمبے ہیں۔
## [لیکچر کے بعد کا کوئز](https://ff-quizzes.netlify.app/en/ds/quiz/7)
## جائزہ اور خود مطالعہ
احتمال اور شماریات ایک اتنا وسیع موضوع ہے کہ یہ اپنے کورس کا مستحق ہے۔ اگر آپ نظریہ میں مزید گہرائی میں جانا چاہتے ہیں، تو آپ درج ذیل کتابوں میں سے کچھ پڑھنا جاری رکھ سکتے ہیں:
1. [کارلوس فرنینڈیز-گرانڈا](https://cims.nyu.edu/~cfgranda/) نیویارک یونیورسٹی سے، کے عظیم لیکچر نوٹس [Probability and Statistics for Data Science](https://cims.nyu.edu/~cfgranda/pages/stuff/probability_stats_for_DS.pdf) (آن لائن دستیاب)
1. [پیٹر اور اینڈریو بروس۔ ڈیٹا سائنسدانوں کے لیے عملی شماریات۔](https://www.oreilly.com/library/view/practical-statistics-for/9781491952955/) [[R میں نمونہ کوڈ](https://github.com/andrewgbruce/statistics-for-data-scientists)]۔
1. [جیمز ڈی. ملر۔ ڈیٹا سائنس کے لیے شماریات](https://www.packtpub.com/product/statistics-for-data-science/9781788290678) [[R میں نمونہ کوڈ](https://github.com/PacktPublishing/Statistics-for-Data-Science)]۔
## اسائنمنٹ
[چھوٹا ذیابیطس مطالعہ](assignment.md)
## کریڈٹس
یہ سبق [دمیتری سوشنیکوف](http://soshnikov.com) کے ذریعہ ♥️ کے ساتھ تحریر کیا گیا ہے۔
---
**ڈسکلیمر**:
یہ دستاویز AI ترجمہ سروس [Co-op Translator](https://github.com/Azure/co-op-translator) کا استعمال کرتے ہوئے ترجمہ کی گئی ہے۔ ہم درستگی کے لیے کوشش کرتے ہیں، لیکن براہ کرم آگاہ رہیں کہ خودکار ترجمے میں غلطیاں یا خامیاں ہو سکتی ہیں۔ اصل دستاویز کو اس کی اصل زبان میں مستند ذریعہ سمجھا جانا چاہیے۔ اہم معلومات کے لیے، پیشہ ور انسانی ترجمہ کی سفارش کی جاتی ہے۔ اس ترجمے کے استعمال سے پیدا ہونے والی کسی بھی غلط فہمی یا غلط تشریح کے لیے ہم ذمہ دار نہیں ہیں۔